Reported by Machine Heart
Machine Heart Editorial Team
Is a “turning point” in the smart speaker field about to arrive with the support of large language models?
During the years when smart speakers were all the rage, many people hoped to have deep conversations with their speakers.Unfortunately, the reality fell short, as the conversational abilities of smart speakers clearly did not meet human expectations.Now, the market dividend period for smart speakers has passed, and the once-glorious aura has faded, gradually becoming less talked about.A Bilibili UP master named “GPTHunt” also shared that he is a “light enthusiast” of smart voice speakers. However, after too many disappointments, he no longer holds out hope.For example, he bought an Amazon Alexa speaker but found his English skills insufficient; moreover, the product design was not localized enough, leading him to abandon it after a trial period.He also purchased a NetEase Sanyin speaker, which was good for listening to music and setting alarms, but “could not be relied upon for questions that required thinking.” Additionally, this speaker had some “quirky” moments, such as suddenly responding while he was on a call or unexpectedly making noise during a movie…Apple’s Siri is similar; you can command it to set alarms or ask about the time and weather, but it cannot engage in deeper discussions.All these frustrations can be attributed to the inadequacy of AI’s conversational abilities. However, the recent emergence of the large language model ChatGPT has given this UP master new hope.One day, he suddenly thought, why not use ChatGPT to transform a speaker and create a smart and powerful voice assistant?

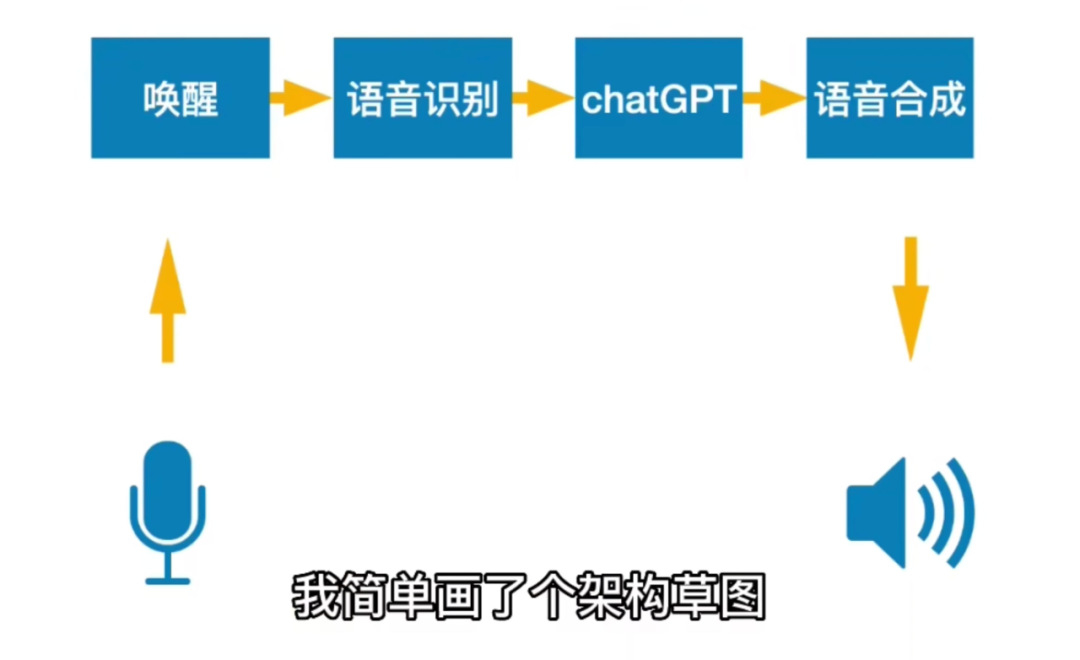
Video link: https://www.bilibili.com/video/BV11M411F7Ww/DIY ProcessThe architecture sketch designed by the author is as follows, divided into four main steps from voice input to speaker response: wake word, speech recognition, ChatGPT, and speech synthesis.
In terms of hardware, the natural choice for geeks is:Raspberry Pi.The author dug out a Raspberry Pi 3 Model B that had been gathering dust for years, only to find it did not come with a microphone. He had to quickly order one online while debugging with his computer.

Next comes the system setup work.The first task is to implement wake word detection.
The wake word is a special word or phrase used to activate the device when spoken, allowing the device to sleep when not in use; it is also known as a “hot word” or “trigger word”.
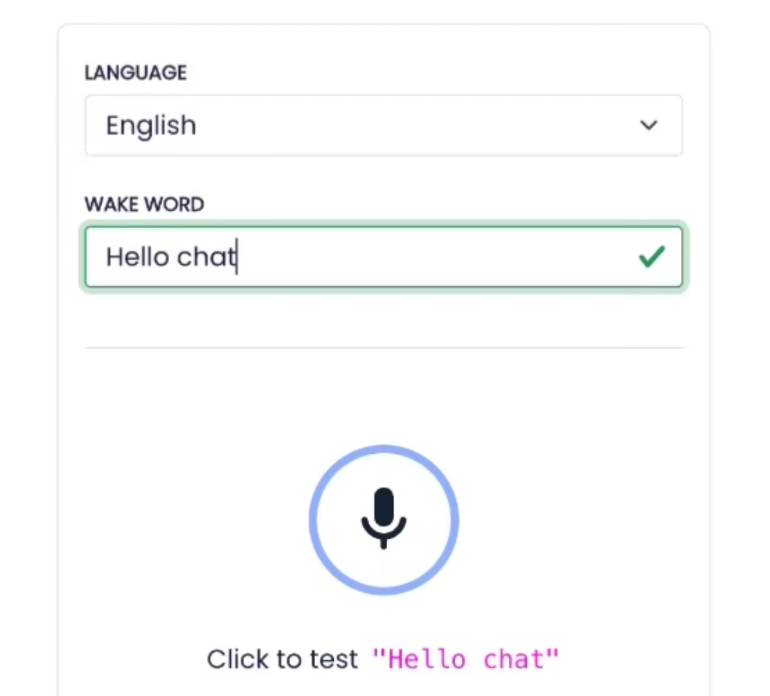
There is an implicit rule here: the device must not listen before being activated. However, in reality, we cannot confirm whether the speaker is listening, so the only way to ensure it does not listen before activation is to use open-source code.Many of you have probably heard some common wake words, such as “Hey Siri”, “Xiao Ai Tong Xue”, and “Xiao Du Xiao Du”. Custom wake words must also follow certain rules: first, avoid using overly short words to prevent false positives; second, for user experience, the wake word should be as short as possible; third, try to choose words with distinct pronunciations, as combinations with more obvious features are less likely to cause false positives.The detection framework used by the author here is Porcupine, which is free for non-commercial use and supports multiple words; the only regret is that it currently does not support Chinese.Ultimately, the wake word chosen by the author is “Hello Chat”. After online recording and training, he obtained a downloadable model. The author wrote a script to run the wake word detection, which responds with a “Hmm” after detection.
After activation, the author used the Python-based audio processing library “PyAudio” to record sound. If you do not want to delve into project documentation at this point, you can directly ask ChatGPT for example code and make minor adjustments.The second step is speech recognition; the author chose Microsoft’s Azure online ASR, which is quite accurate and fast. This feature provides silence detection, and of course, you can also use the cobra silence detection feature provided by Porcupine to determine when the voice input ends.The third step is to send the recognition results from Azure to ChatGPT, and after receiving a response, perform speech synthesis (TTS) to play it through the speaker.After some debugging, the microphone ordered online also arrived, and the entire system was migrated to the Raspberry Pi, successfully completed.Effect DemonstrationTypically, what questions do you ask a smart speaker?First, the author asked a philosophical question: “Answer the meaning of life in 10 words.” The speaker perfectly answered this question with five words: “Explore, Grow, Share, Appreciate, Grateful,” which is exactly ten characters long.

Then, the author asked a question related to the tech industry:“Who is more impressive, Musk or Jobs?”The smart speaker’s response first stated, “This question has no definite answer; both individuals have achieved great success in different fields,” and then introduced the achievements of both Musk and Jobs.

Of course, besides asking questions, you can also greet this smart speaker; it acts like a little assistant by your side:

Additionally, building your own smart speaker has the advantage of being able to view the code executed by the speaker during operation and analyze the resources used by the program.
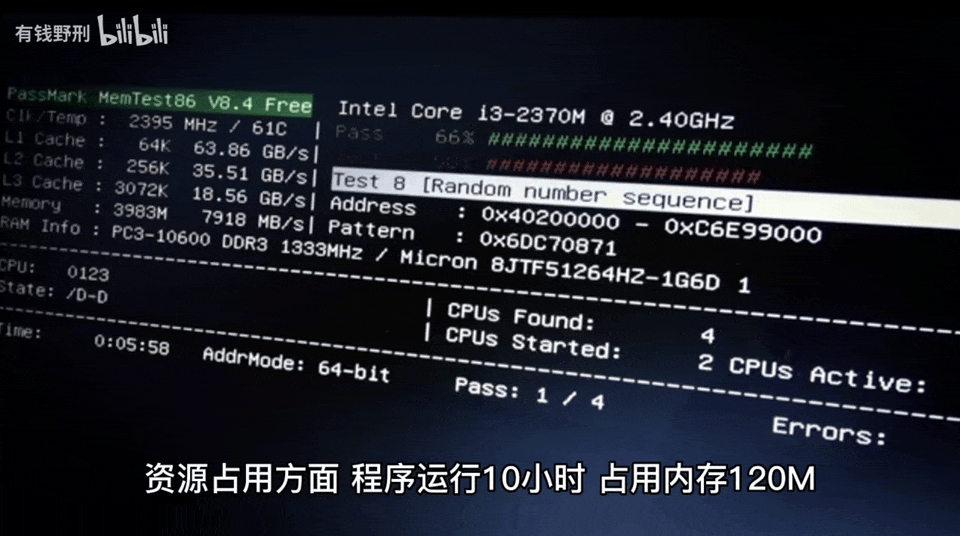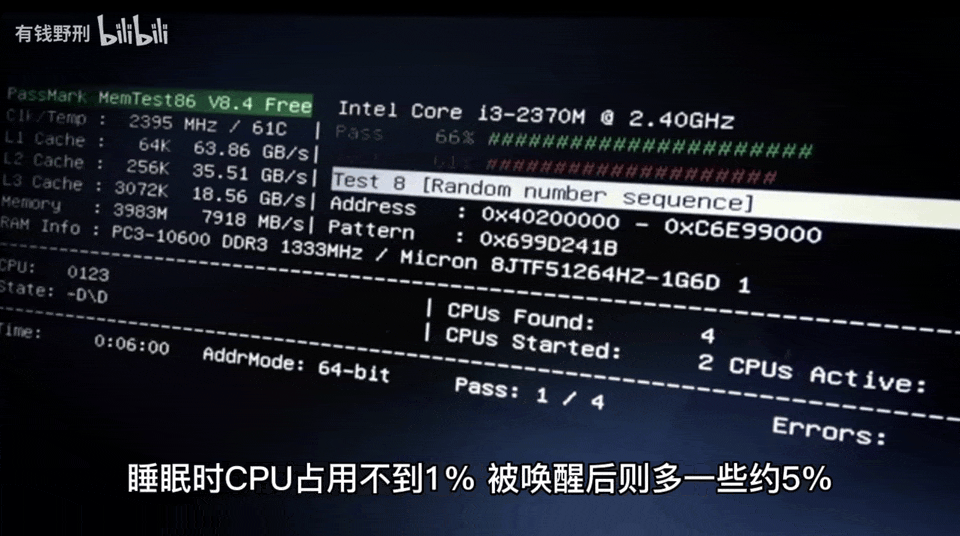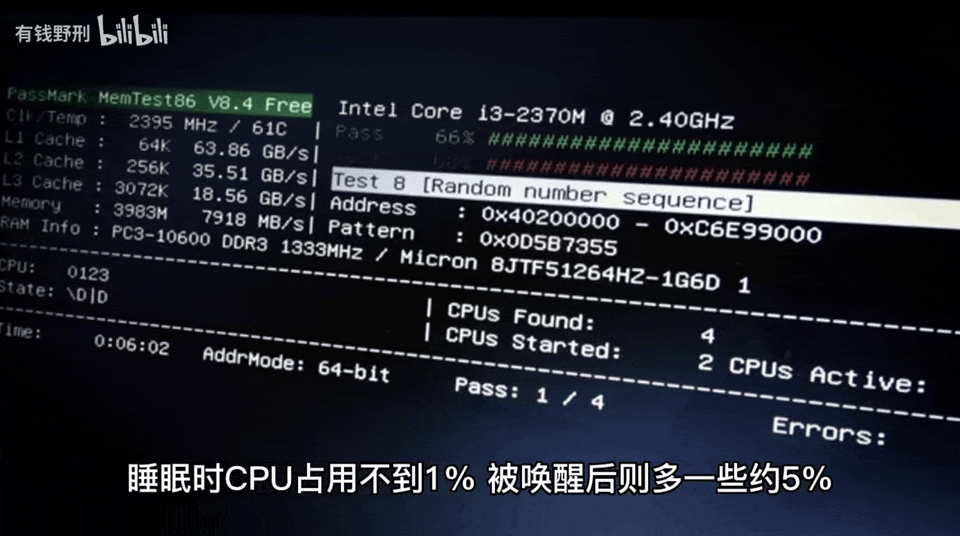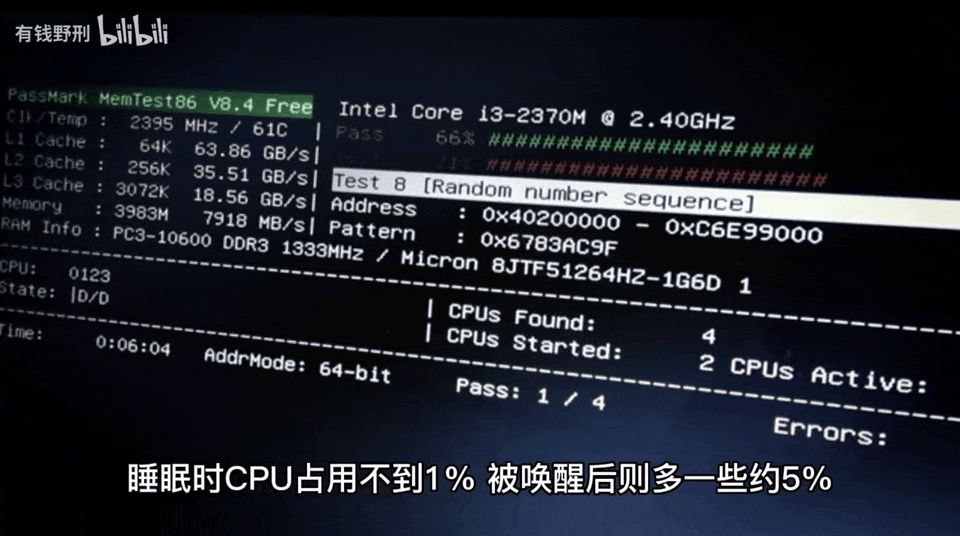
Most importantly, the author can test the speaker’s response speed and make improvements.The first version of the smart speaker took 10-20 seconds to respond to a question, while the improved second version only takes 4-6 seconds, mainly due to the network and computation time overhead of ChatGPT.Furthermore, the author mentioned that the functions of this smart speaker can be seamlessly migrated to other platforms.Finally, the author posed a question: how will ChatGPT’s capabilities in continuous, contextually relevant conversations enhance the intelligence level of the speaker?
© THE END
For reprints, please contact this public account for authorization
Submissions or inquiries: [email protected]