
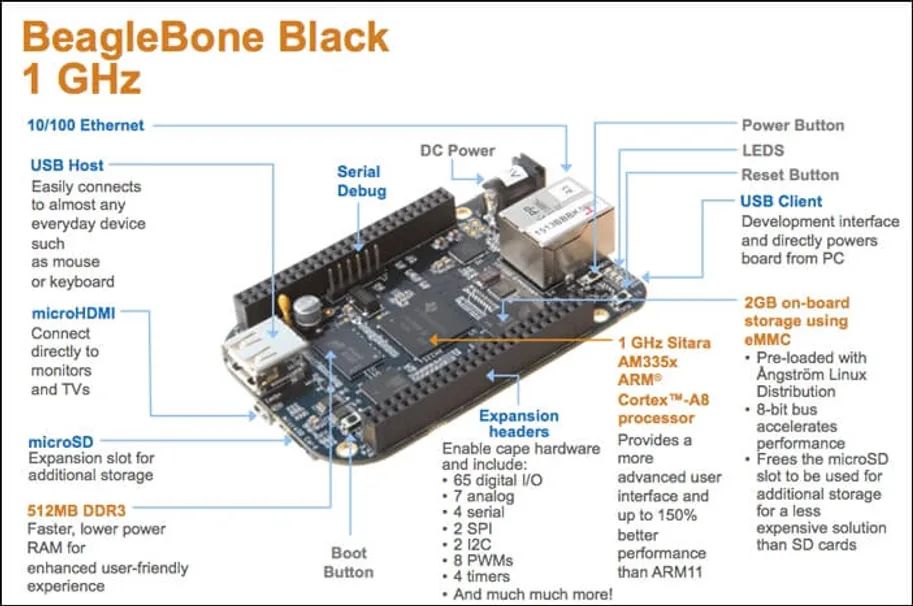
The development board is cool, and the BeagleBone® Black (BBB) is one of the most interesting development boards. This widely used microcontroller board costs around £35 and boots Linux in just 10 seconds, allowing any interested developer to get started quickly.
To this end, Imagination has been collaborating with the BeagleBoard.org® Foundation to enable users to benefit from the BBB. The main processor on the BeagleBone® Black (BBB) board is the Arm® Cortex® A8 with the PowerVR SGX™ 530 Graphics Processing Unit (GPU). From an educational perspective, developers can better develop applications using standard OpenGL® ES 2.0 and Open CL TM 1.1 ABI.
Running OpenCL on PowerVR SGX530—Is It Real?
The PowerVR SGX530 is one of Imagination’s most successful GPU designs and is still widely used today. However, the SGX530 is a design from 10 years ago and was developed before Open CL became a standard. Nevertheless, Imagination has provided support for OpenCL 1.1 on the PowerVR SGX530, and given the widespread use of the BeagleBone Black, we have restarted this work and present it here.
Using OpenGL ES2.0
There is a specific BBB image AM3358 Debian 9.12 2020-04-06 4GB SD ImgTec that comes with the TI SGX graphics driver and PowerVR SDK pre-installed. This serves as a foundation for exploring OpenGL and OpenCL.
The PowerVR SDK provides several examples, starting from drawing a triangle as the most basic graphic element (Figure 1) to generating more complex images using vertex and fragment shaders (Figure 2). This can be used for self-study. Alternatively, the BBB can also serve as a development platform for a mobile graphics introductory course.


Understanding OpenCL 1.1
The OpenCL package can be downloaded from the Imagination Technology University project website (https://university.imgtec.com/). This package includes a build script that will install the OpenCL library and patch the PowerVR SDK, allowing only the OpenCL 1.1 matrix example to be built for the BBB.
The OpenCL matrix multiplication example is for educational purposes, to understand how OpenCL runs on embedded platforms like the BBB. The key point to understand is the overhead implied in passing data buffers between the Arm A8 and the PowerVR SGX530 and managing data cache consistency between them. During this overhead time, no useful processing work is done, so it can be considered “wasted” time. Compared to the overhead, the processing time shown in Figure 3 is very large, for example, when the A8 is freed to perform other tasks while the SGX is processing, OpenCL on the BBB becomes very useful.
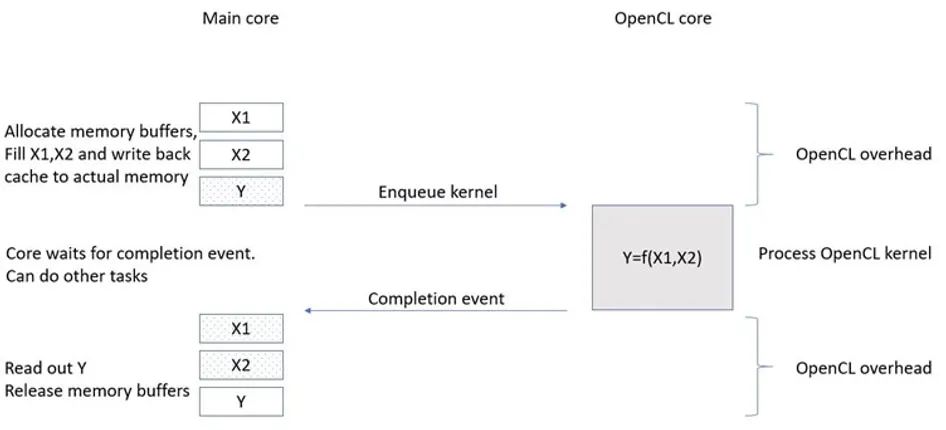
Figure 3: OpenCL Overhead and Processing Time
Using multiple OpenCL cores illustrates how to improve SGX processing performance using single instruction multiple data (SIMD) instructions on float4 types (four packed 32-bit data values).
Using OpenCL 1.1
The matrix multiplication example helps in understanding OpenCL. The next step is to use OpenCL in a real example that has the right combination of high processing and relaxed latency. The selected example is the ALSA sample rate converter (SRC) used in an audio player application. The high processing requirement comes from upsampling from 44.1kHz to 48kHz, and in fact, it is a player, which means latency requirements can be relaxed. The OpenCL implementation fits the ALSA software, as shown in Figure 4, modifying the libspeexdsp layer to call OpenCL.
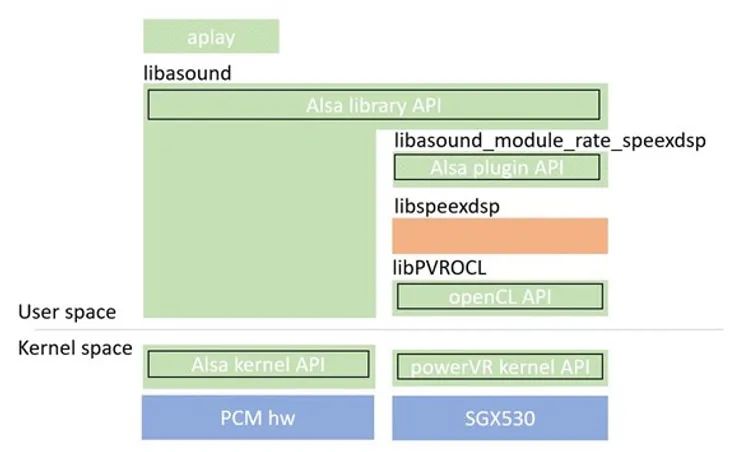
Figure 4: ALSA Software Architecture with libspeexdsp Modified to Call OpenCL
This example is built by running a script that will download and patch the ALSA package. The OpenCL library is provided as a C++ library, so ALSA needs to be compiled with g++ to ensure that the OpenCL constructor/destructor is called correctly. The g++ compiler is stricter than GCC, so most patches are to correct type conversions on pointers, ensuring that initialized structures are fully initialized and in the correct order.
To leverage OpenCL, the algorithm used must be fully parallel, with the same operation performed on each output sample. The SRC algorithm in libspeexdsp does not actually do this, as the index values calculated in the inner loop will be used for the next iteration of the outer loop. This means that the ALSA-SRC algorithm needs to be restructured so that the index calculation step can be extracted from the processing loop and prioritized, allowing the processing loop to be the same in each iteration.
Since aplay is just a playback application, latency requirements can be relaxed. It turns out this is necessary, as the overhead of processing the standard input audio buffer size of 160 samples prevents real-time execution of the OpenCL calls. A buffer size of 640 or more samples achieves reliable operation. With a 1600 sample buffer, the A8 load when running SRC on A8 drops from 55% to 20%. This CPU offloading is the main advantage of using OpenCL on the BBB, and we hope the community can find other use cases that can improve performance based on BBB systems.
The documentation in the OpenCL download package is more detailed to help readers understand how OpenCL operates and how to use it effectively.

Imagination and Peking University Jointly Launch “Introduction to Mobile Graphics” Course on XueTang Online

END
