From Specialized to Generalized: Trends and Prospects in AI
MLNLP community is a well-known machine learning and natural language processing community both domestically and internationally, covering audiences including NLP graduate students, university professors, and corporate researchers.The Vision of the Community is to promote communication and progress between the academia and industry of natural language processing and machine learning, especially for the advancement of beginners.Reprinted from | ZhuanzhiAuthor丨Sang Jitao, Professor at Beijing Jiaotong University
Introduction
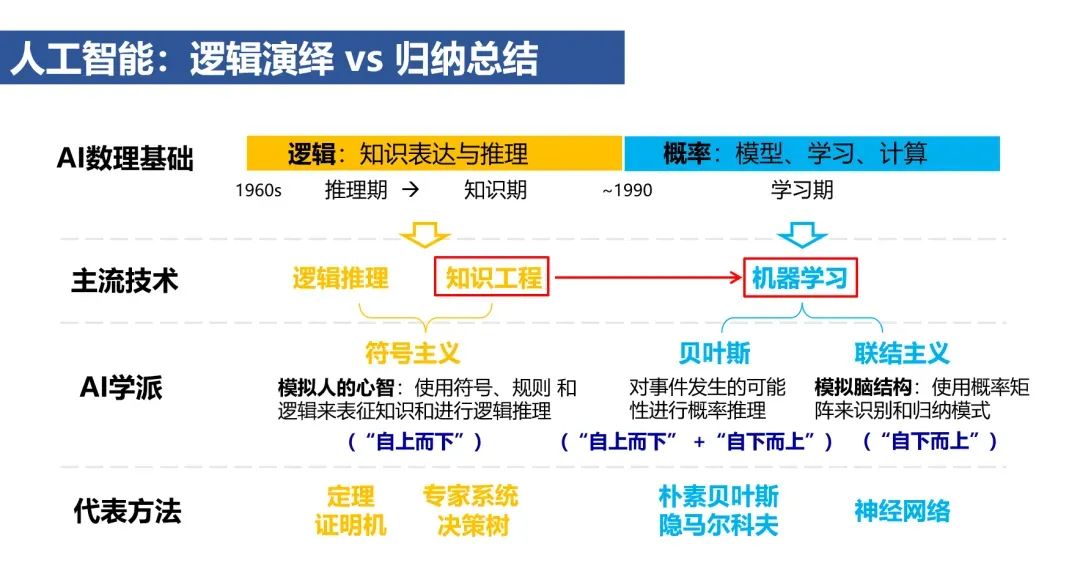
The 1956 Dartmouth Conference defined “artificial intelligence” as “a set of artificial programs or systems that enable machines to simulate human perception, cognition, decision-making, and execution.” This definition gave rise to two approaches to imitating human intelligence – logical deduction and inductive summary, which inspired two important phases in the development of artificial intelligence: (1) from 1960 to 1990, knowledge engineering methods based on logic, focusing on knowledge representation and reasoning; (2) after 1990, machine learning methods based on probability, emphasizing model construction, learning, and computation.Knowledge Engineering: Logical Deduction vs. Machine Learning: Inductive SummaryAfter more than 30 years of development, machine learning methods have roughly gone through three stages: traditional machine learning relying on manually designed features from 1990 to 2010, (traditional) deep learning from 2010 to 2020 focusing on supervised representation learning from low to high levels, and self-supervised learning with pre-trained large models based on large-scale unlabeled data after 2020. Centered around the third generation of machine learning with pre-trained large models, the following discusses three trends in the development of artificial intelligence and four prospects for the future.Pre-trained Large Models: The Third Generation of Machine Learning
Trend One: From Specialized to Generalized – Pre-trained Large Models and Intelligent Agents
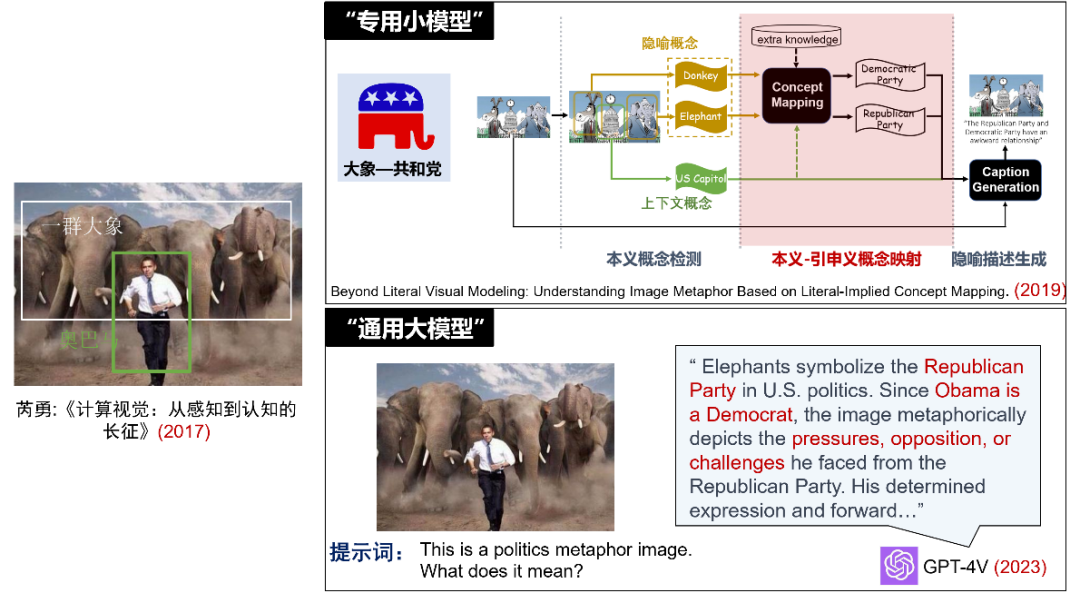
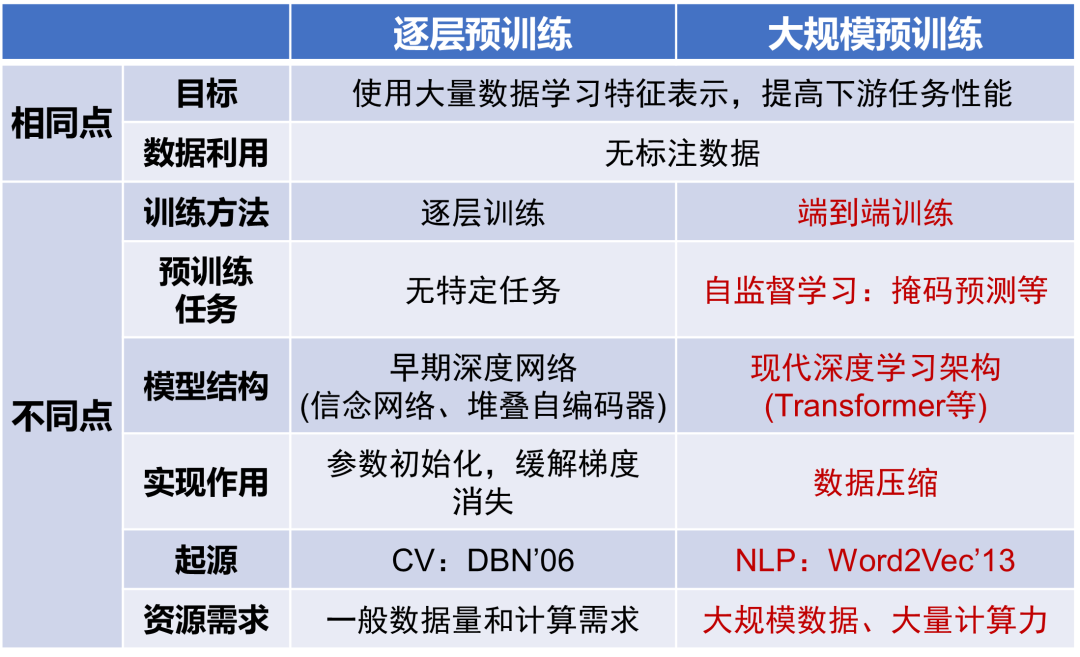
Taking the Chinese-English translation task as an example, knowledge engineering methods require linguists to write rule libraries, while traditional machine learning and deep learning learn probability models or fine-tune models based on corpora. These methods are all designed for specific machine translation tasks. However, today’s same large language model can not only translate dozens of languages but also handle various natural language understanding and generation tasks such as question answering, summarization, and writing. Combining my research experience, Professor Rui Yong proposed the cognitive challenge of metaphorical image understanding in 2017 (linking “elephant” to “Republican” to understand the image discussing American politics). In 2019, we attempted to solve it through a pipeline of several specialized small models (literal concept detection – literal extended concept mapping – metaphorical description generation). By 2023, with just a brief prompt, GPT-4V can accurately understand the political metaphor behind the image.Small Models’ “Specialized” vs. Large Models’ “Generalized” Pre-trained large models adopt large-scale pre-training technology, which, although both learn feature representations based on unlabeled data, differ significantly in training methods, pre-training tasks, model architectures, functional implementations, origins, and resource requirements. From an origin perspective, layer-wise pre-training technology was initially applied in the field of computer vision to learn visual feature representations. In contrast, large-scale pre-training technology originated from language models NNLM and Word2Vec in the field of natural language processing.Layer-wise Pre-training vs. Large-scale Pre-training
(1) Pre-trained Language Models
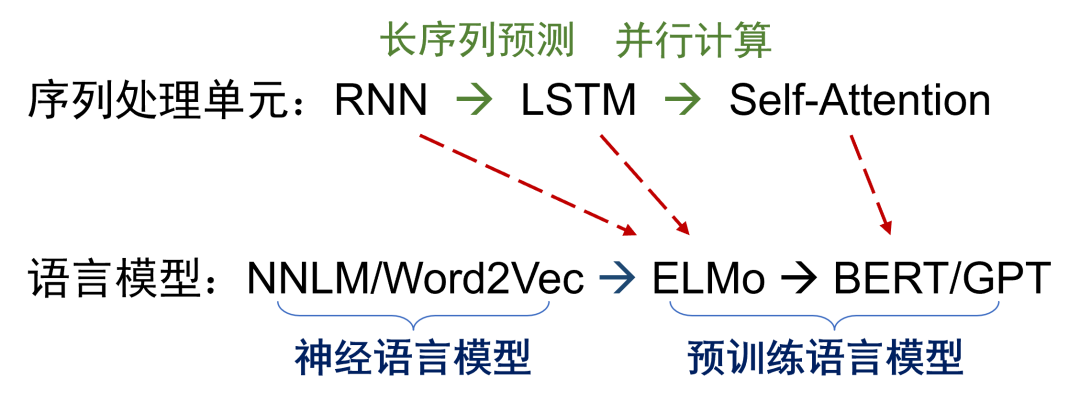
The core of language models is to calculate the probability of a sequence of text appearing, which has roughly gone through several development stages: statistical language models, neural language models, and pre-trained language models. Unlike neural language models (like Word2Vec) based on static word vectors, pre-trained language models began to learn dynamic word representations that can perceive context since the ELMo model, allowing for more accurate predictions of text sequence probabilities. In the development of sequence processing units, from RNN to LSTM, and then to Self-Attention, issues of long sequence prediction and parallel computing have been gradually addressed. Therefore, pre-trained language models can efficiently learn on large-scale unlabeled samples. According to the scaling law relating computational power, data volume, and model scale, the performance improvement of current pre-trained language models has not yet hit a ceiling.Development of Sequence Processing Units and Language Models
(2) Visual and Multimodal Pre-training
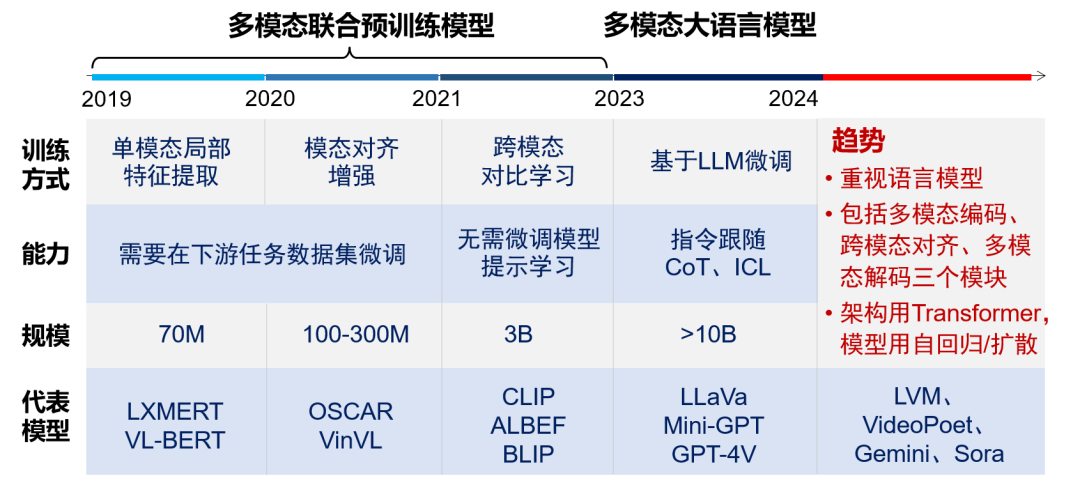
The success of pre-trained language models has brought two inspirations to the field of computer vision: first, using unlabeled samples for self-supervised learning, and second, learning general representations that can adapt to various tasks. From iGPT, Vision Transformer, BEiT, MAE to Swin Transformer, issues such as the computational resource consumption of self-attention mechanisms and the retention of local structural information have been gradually resolved, promoting the development of visual pre-training models.Multimodal pre-training simulates the multimodal process through which humans understand the physical world. Comparing large language models to the brain of machines, multimodality provides the eyes and ears to perceive the physical world, significantly expanding the machine’s perception and understanding range. The core issue of multimodal pre-training is how to effectively achieve alignment between different modalities. Depending on the modality alignment strategies, multimodal pre-training has roughly gone through two stages: multimodal joint pre-training models and multimodal large language models. Early models pre-trained by parallel processing of data from different modalities primarily included techniques such as single-modality local feature extraction, modality alignment enhancement, and cross-modal contrastive learning. Among them, CLIP successfully bridged the language and visual modalities through contrastive learning on 400 million image-text pairs. Since 2023, models like LLaVa, Mini-GPT, and GPT-4V have built upon large language models, integrating other modality data through fine-tuning, inheriting rich world knowledge and excellent interaction capabilities from language models. Google’s Gemini model has re-adopted a joint pre-training multimodal architecture. Recently, with the emergence of new models like LVM, VideoPoet, and Sora, multimodal pre-training has shown the following trends: (1) emphasis on the role of language models in multimodal understanding and generation; (2) typically includes three key modules: multimodal encoding, cross-modal alignment, and multimodal decoding; (3) cross-modal alignment tends to adopt Transformer architecture, with models employing autoregressive (VideoPoet) or diffusion (Sora) methods.Evolution of Multimodal Pre-training Model Architecture
(3) Applications of Pre-trained Models
According to Leslie Valiant’s perspective[1], large-scale pre-training can be likened to the innate structural priors formed by biological neural networks through billions of years of data accumulation, namely, group genes or physiological evolution. The application of pre-trained models is similar to individuals fine-tuning in the face of small data. Following the development of the GPT series, we can clearly see the changes in the capabilities of pre-trained models and their corresponding application methods: from the parameter fine-tuning of the pre-trained model in GPT-1 (full fine-tuning/parameter-efficient fine-tuning) to prompt engineering after GPT-2 demonstrated zero-shot capabilities, to example design after GPT-3 exhibited contextual learning abilities, and finally to directly guiding the model through task descriptions after task emergence in GPT-3.5. The success of OpenAI largely stems from its leading cognition and consistent commitment to promoting intelligence towards a more generalized direction by increasing data and model scale.Evolution of Pre-trained Model Application MethodsThe transition from specialized models to generalized models has brought about the following four specific changes:
From Closed Set to Open Set: Pre-trained models learn general knowledge from large-scale data, breaking the limitation of task solutions confined to specific categories. For example, CLIP can handle zero-shot visual understanding tasks by establishing associations between language and visual modalities; SAM can effectively segment unseen objects and scenes.
Old Problems, New Understandings: The evolution of model application methods also provides us with a new perspective on understanding traditional problems. For instance, small sample learning has shifted from relying on labeled samples during the training phase to injecting example contexts through prompts during the inference phase; zero-shot learning has gradually transformed into an open vocabulary learning problem due to the widespread existence of implicit knowledge bases like CLIP.
Marginalization of Intermediate Tasks: The importance of intermediate tasks such as tokenization, part-of-speech tagging, and NER in the field of natural language processing is decreasing. Classical natural language processing borrowed from computational linguistics, where intermediate tasks are mostly human-designed. For instance, traditional dialogue systems are designed to include three modules: natural language understanding, dialogue management, and natural language generation, with each module further subdivided into several intermediate tasks. However, as the pre-training data reaches a certain scale through autoregressive methods, these intermediate tasks and modules have been unified into a problem of predicting the next token. From the aforementioned example of metaphorical image understanding, we can also observe similar changes in the visual and multimedia fields.
Blurring of Domain Boundaries: The boundaries between computer vision (CV) and natural language processing (NLP) are becoming increasingly blurred. In the traditional machine learning era, CV borrowed foundational Bag-of-Words representation methods from NLP; during the early deep learning phase, NLP introduced network structures such as MLP and ResNet from CV, as well as training and optimization techniques like dropout and batch normalization. In the era of pre-trained large models, CV first borrowed the self-supervised pre-training and self-attention mechanisms from NLP, and with the launch of visual GPT and video-generating GPT models such as LVM and VideoPoet, the two fields are developing towards a unified direction of multimodal encoding and autoregressive modular structures.
Mutual Borrowing Between NLP and CV in Different Machine Learning Stages
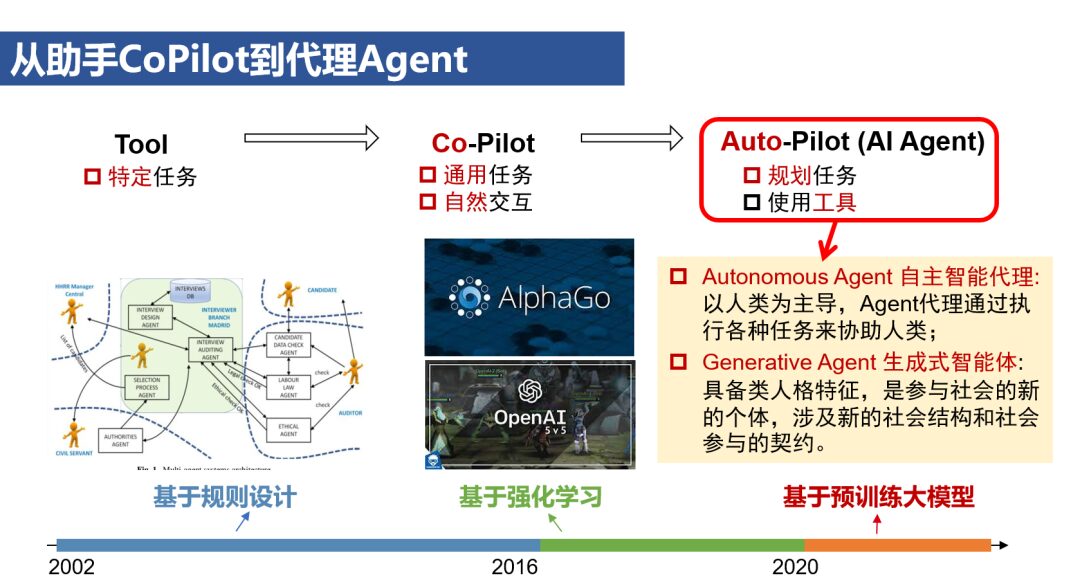
(4) AI Agents
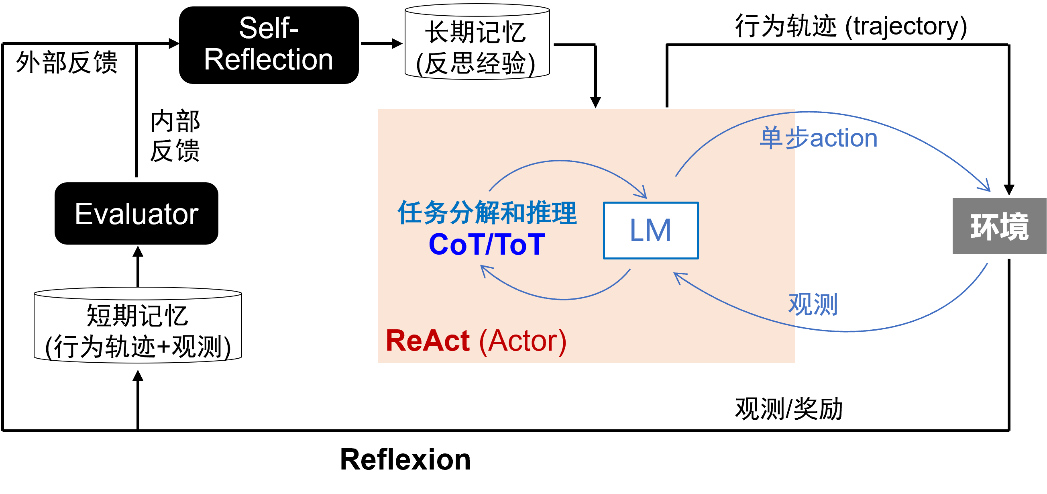
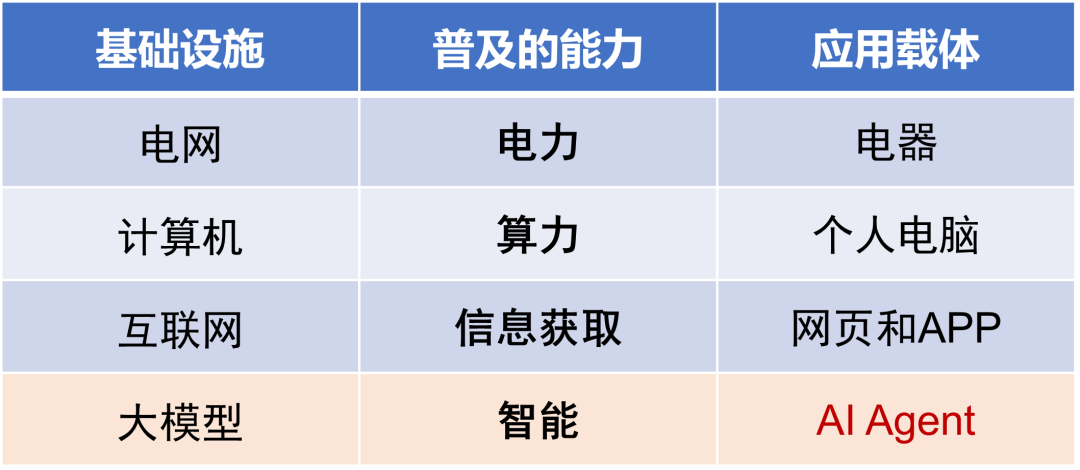
The generality of pre-trained large models is reflected not only in content understanding and generation but also extends to thinking and decision-making capabilities. AI systems that handle general tasks and possess natural interaction abilities, such as Jasper and Midjourney, can be classified as CoPilot, while AI systems with planning tasks and tool usage capabilities can be referred to as AutoPilot, i.e., AI Agents. In the CoPilot model, AI acts as an assistant to humans, collaboratively participating in workflows; in the AI Agent model, AI acts as an agent for humans, independently taking on most of the work, with humans only responsible for setting task goals and evaluating results.It is worth noting that the concept of AI Agents has existed since the early days of artificial intelligence, having undergone two stages before the advent of pre-trained large models: rule-based design and reinforcement learning. The current discussion of AI Agents, more accurately, refers to AI Agents based on pre-trained large models. In contrast to the AI Agents of the previous two stages designed for specific tasks and scenarios, the core characteristic of AI Agents based on pre-trained large models lies in their adaptability to general tasks and scenarios.AI Agents Based on Pre-trained Large ModelsThe main architecture of AI Agents includes Perception, Planning, Action, and Memory. In the action phase, AI Agents can rely on their large model capabilities or invoke external APIs or other models and tools to execute tasks. The planning process involves both task decomposition and continuous optimization based on feedback. Task decomposition currently mainly employs methods such as chain-of-thought and thought trees, which mimic the human system two reasoning process by structurally organizing and refining thoughts to address complex problems. Feedback-based corrections are primarily achieved through two methods: one is ReAct, which combines reasoning and action within a single round, embodying the principle that “acting without thinking leads to confusion, while thinking without acting leads to danger”; the other is Reflexion, which can be seen as a language-based online reinforcement learning method that allows for multi-round reflection from errors.Task Planning: CoT/ToT vs. ReAct vs. ReflexionAs large models gradually become the infrastructure of future society, similar to how the power grid, computers, and the internet became the infrastructure that popularized electricity, computing power, and information access capabilities, the cost of intelligent services will also significantly decrease. AI Agents, as the application carriers of intelligent service proliferation, will drive the transformation of AI-native technologies.AI Agents: The Application Carrier of IntelligenceFrom the C-end perspective, AI Agents will become the information entry point in the intelligent era: users will no longer need to log into different websites/apps to complete various tasks but will interact with various services through AI Agents in a unified manner. AI-native applications, operating systems, and even hardware will surpass the current graphical user interface (GUI), integrating more with natural language user interfaces (LUI), providing a more intuitive and convenient interaction experience.From the B-end perspective, Machine Learning as a Service (MaaS) offers machine learning models as services, achieving an intelligent upgrade of cloud services compared to SaaS. Meanwhile, Agent as a Service (AaaS) further provides intelligent agents as services, promoting further automation upgrades of cloud services. Some believe that software production will enter a 2.0 era similar to 3D printing, characterized by (1) AI-native – naturally designed language interfaces for AI use, (2) solving complex tasks – planning and executing task chains, (3) personalization – meeting long-tail demands. In this trend, software aimed at enterprises may no longer merely serve as tools to assist employees but will act as digital employees, replacing part of the basic and repetitive work.However, AI Agents based on pre-trained large models still face several technical challenges:
The complexity of mechanism engineering design and application generalization: Currently, the tool invocation and task planning of AI Agents usually involve complex mechanism engineering, i.e., writing heuristic methods that contain logical structures and reasoning rules in the prompt framework. This manual design approach is difficult to adapt to the constantly changing environment and user needs. According to the development law from manual design to data-driven learning, mechanism learning aimed at AI Agents is a possible solution to achieve more flexible and adaptive intelligent agent behavior.
Mechanism Learning for AI Agents
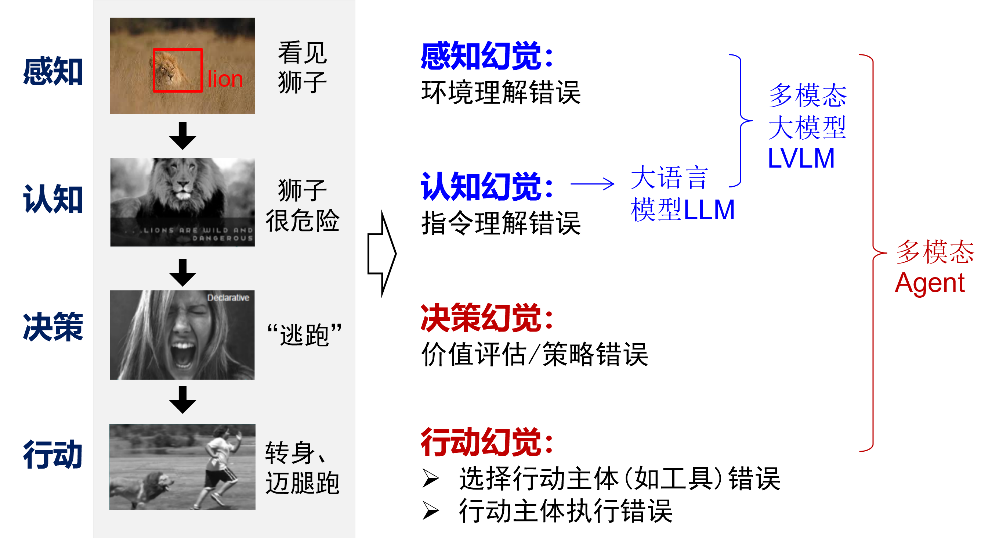
Trust and Alignment: With the addition of memory, execution, planning, and other aspects, trust and alignment for AI Agents present new issues to be solved. For example, in terms of adversarial robustness, we must not only focus on the model’s own resistance to attacks but also consider the safety of memory carriers, toolsets, planning processes, etc.; when addressing hallucination issues, we must consider not only the hallucinations in the perception and cognition stages but also those in the decision-making and action stages.
Consistency in Long Context Planning and Reasoning: When dealing with long dialogues or complex tasks, Agents need to maintain coherence in context, ensuring that their planning and reasoning processes align with the user’s long-term goals and historical interactions.
Reliability of Natural Language Interfaces: Compared to the strict grammar and structure of computer languages, natural language has ambiguity and vagueness, which may lead to errors in understanding and executing instructions.
Trend Two: From Capability Alignment to Value Alignment – Trust and Alignment
From the definition of artificial intelligence, we can see its original intention to align with humans. Whether through knowledge engineering methods based on logical deduction or statistical machine learning methods based on inductive summary, the goal is to achieve alignment with humans. Taking machine learning methods as an example, under the supervised learning paradigm, humans label training datasets (X, Y), and models learn the mapping f() from input X to output Y, which can be seen as a form of human knowledge distillation; under the unsupervised and self-supervised paradigms, the similarity metrics and proxy tasks defined by humans (for example, generative proxy tasks aim to reconstruct human language or natural images) also transmit human knowledge to the model. By aligning the training objective function with humans, the model has passed the Turing test on a series of tasks representing different human capabilities, achieving a certain degree of alignment with human capabilities.AI and Human Capability AlignmentHowever, in certain strong human-machine interactions and fields with strict safety requirements, AI models still struggle to achieve industrial-grade large-scale applications due to issues of robustness, fairness, interpretability, and data privacy protection.AI and Human Value AlignmentCurrently, there is no consensus on the standards for achieving AGI. If we view human-machine alignment as a standard for achieving AGI, then beyond capability alignment at the goal level, we must also consider value alignment at the behavioral level. Capability alignment and value alignment can be likened to results and processes: just as reaching a destination is the result, the mode of transportation and the chosen route can vary in process.Human-Machine Alignment: Capability Alignment + Value Alignment
(1) Trust: Value Alignment in the Era of Small Models
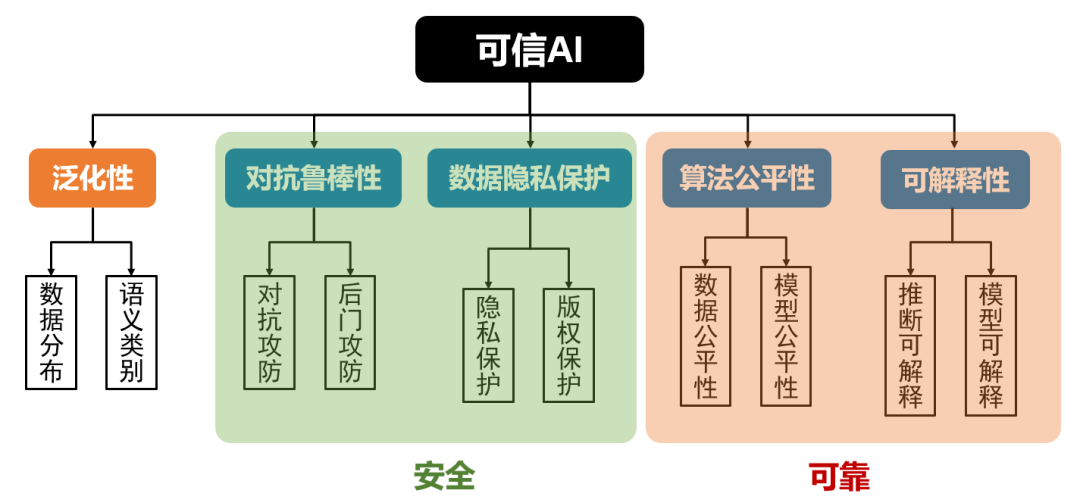
It can be observed that the robustness against adversarial attacks[3], algorithmic fairness[4], interpretability[5], and data privacy protection[6] required by value alignment constitute the four core dimensions of classic trustworthy AI. Trustworthy AI is built on the foundation of generalization, which also corresponds to capability alignment being a prerequisite for value alignment. Conceptually, we can view value alignment as the extension of trustworthy AI, encompassing not only technical-level alignment but also broader ethical and social responsibilities.The Connotation of Trustworthy AI
(2) Value Alignment in the Era of Large Models
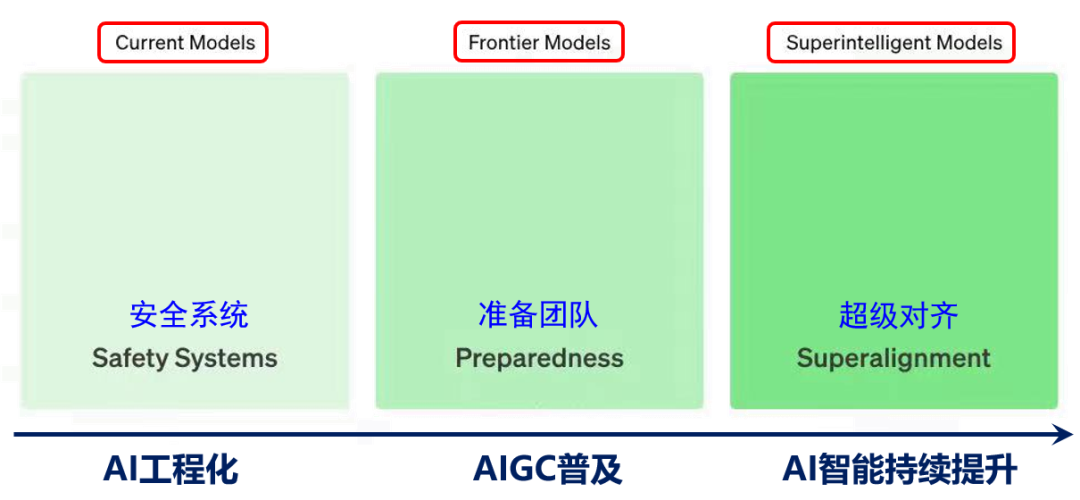
In the era of pre-trained large models, as AI capabilities continue to improve, both the breadth and depth of applications will significantly increase. The greater the capability, the greater the responsibility. While people enjoy the convenience and productivity improvements brought by AI, their attitude towards AI will gradually shift from adaptation to reliance. As people begin to rely on AI to replace their own learning, thinking, and even decision-making, higher demands for trust and value alignment with AI will arise. Beyond simply migrating the research objects of classic trust issues from specialized small models to pre-trained large models[7,8,9], we also face a series of new trust and value alignment challenges.Anthropic proposed the “3H Principles[10]” for human-machine alignment, where Helpful corresponds to the requirement for accuracy in capability alignment; while Honest and Harmless roughly correspond to the requirements for reliability and safety in value alignment. The framework proposed by Professor Qin Bing from Harbin Institute of Technology[11] sets universal and diverse value alignment goals from the dimensions of factual correctness, legality, emotional appropriateness, and cultural alignment. Compared to the issues in classic trustworthy AI, under the new value alignment framework, especially considering the characteristics of generative AI, new value alignment issues such as authenticity[12], non-harmfulness[13], and contextual adaptability[14] require more attention.New Value Alignment Issues in the Era of Large ModelsBased on different time frames, OpenAI has established three alignment and safety teams, targeting current cutting-edge models, transitional models, and future super models. Based on this setup, we will discuss three stages of value alignment research in the era of large models, combining our research examples.Three Stages of Value Alignment Research in the Era of Large Models
AI Engineering: Trustworthy Large Model Testing, Diagnosis, and Repair
The construction of an application ecosystem is a sign of technological maturity. Taking the development from software science to software engineering as an example, by establishing testing environments, toolchains, development platforms, and other infrastructures, and improving key DevOps aspects such as software construction, deployment, and maintenance, a complete software development cycle has been formed. The construction of an AI engineering application ecosystem involves managing the entire intelligent lifecycle. The software ecosystem AIOps/LMOps provides the necessary tools and services to ensure the efficient and stable development, testing, deployment, and operation of models. Research on trust and value alignment needs to delve into the construction and implementation of AI application ecosystems, shifting from conceptual and framework research to more practical technical practices, and supporting model development and application developers with solutions in the form of tools and integrated modules.Supporting AI Engineering Application Ecosystem ConstructionUsing software engineering as an example, the core of its application ecosystem lies in constructing a complete testing-debugging closed-loop system, including performance evaluation, defect identification and localization, and regression testing. The implementation of a testing-debugging closed loop can improve the reliability of software, reducing failure rates and safety risks. Due to the black box problem brought by data-driven methods, machine learning models cannot be debugged directly like software. By using interpretability methods to diagnose pre-trained models, problematic modules or model parameters can be located, followed by targeted repair measures. The process of model testing, diagnosis, and repair can be likened to the examination, questioning, and treatment stages of visiting a hospital. After completing model repairs, retesting is required to confirm that the problem has been resolved and no new issues have been introduced, thus forming a testing-debugging closed loop.Model Testing-Diagnosis-Repair vs. Hospital Examination-Treatment-QuestioningTesting, diagnosis, and repair technologies should support large model research and downstream application development in a modular or tool form:
Support for Model Development: Testing and debugging technologies should be integrated into modules, embedded within existing research and development processes. These modules need to be custom-designed for the characteristics of pre-trained models, enabling developers to quickly assess model performance, accurately locate issues, and implement effective optimization measures.
Support for Downstream Application Development: For downstream application development based on large models, testing and debugging tools can be provided as cloud services on large model platforms. This way, developers can conduct detailed assessments and adjustments to models based on specific application scenarios, thereby simplifying model deployment and operation processes, enhancing the reliability and safety of downstream applications.
AIGC Proliferation: OOD Issues of Natural-Synthetic Data
From ChatGPT, Midjourney to Sora and Suno, the quality of AI-generated content in text, images, videos, and music is continuously improving, making it increasingly difficult for humans to distinguish. The high authenticity of AIGC content has already confused human judgment, with the foremost challenge being digital forensics and forgery detection, raising concerns about misinformation. On the other hand, as AI generation serves as a tangible productivity tool, the trend of AIGC being ubiquitous is likely unstoppable. Recently, the fully AI-generated trailer “Barbie x Oppenheimer” sparked viral spread and heated discussions, with Gartner predicting that by 2030, the proportion of AI-generated content in major film works will rise from 0% in 2022 to 90%.AI-generated Trailer “Barbie x Oppenheimer”As society gradually adapts to and accepts AI-generated content, especially in scenarios where AI replaces humans, many AI tools will interact with AI-generated content. This will introduce a new issue: currently, these models, from training data, structures to training methods, are designed for natural data, but what problems will arise when applied to AI-generated content? For instance, AI-generated text and images may introduce biases in information retrieval[15], amplifying these biases in retrieval loops[16]; compared to natural images, AI-generated images are more prone to hallucinations[17]. It seems that AIGC not only confuses humans but also confuses AI itself.With the increasing prevalence of AI-generated data, we may encounter the following situations:
Traditional Generalization Issues: Training with natural data and applying to natural data. This has been the main focus of research over the past few decades, and many tasks have been solved well under laboratory conditions.
Natural to Synthetic Data Generalization: Training with natural data and applying to synthetic data. This is the situation discussed in the previous work[15,16,17].
Synthetic to Natural Data Generalization: Training with synthetic data and applying to natural data. For example, the ShareGPT dataset is widely used in training large language models, and Sora may use game engines to synthesize training data. Synthetic data can compensate for the deficiencies of natural data, promoting continuous improvement in model capabilities. This situation is expected to continue to grow.
Synthetic to Synthetic Data Generalization: Training with synthetic data and applying to synthetic data, which is an internal generalization issue of synthetic data.
Situations 2 and 3 can be viewed as a generalized OOD issue, termed “Natural-Synthetic OOD.” In fact, even situation 4 should consider mixing natural and synthetic data in some way for model training. A deep understanding of the differences between natural and synthetic data, beyond application in authenticity verification, is also crucial for effectively using synthetic data for training in the future and for interacting with synthetic data in applications.Natural-Synthetic OOD
Continuous Improvement of AI Intelligence: Super Alignment
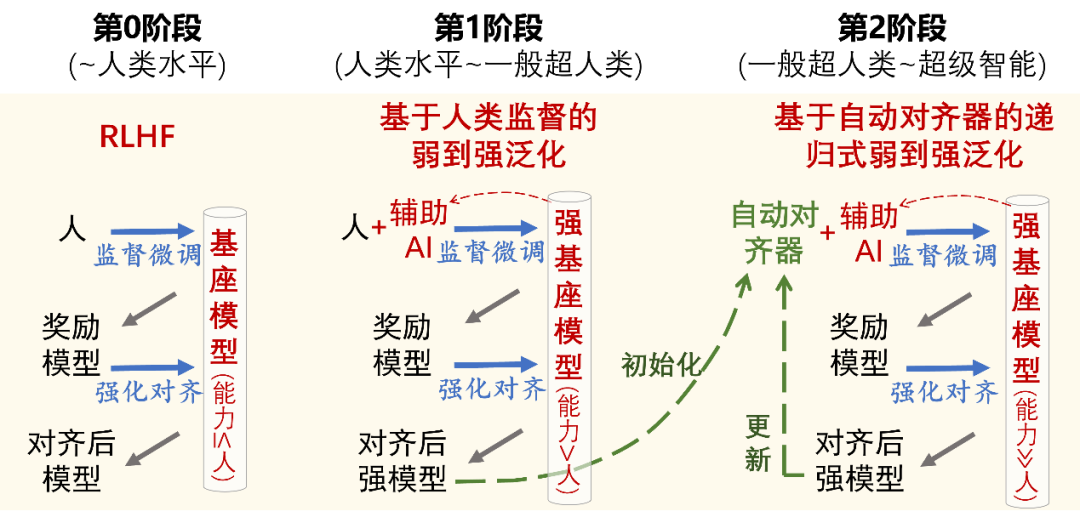
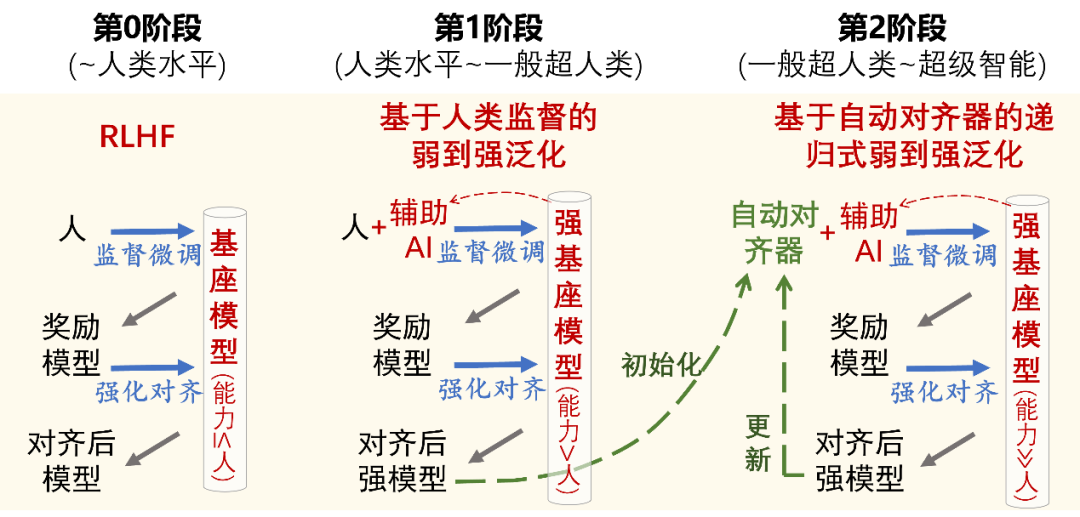
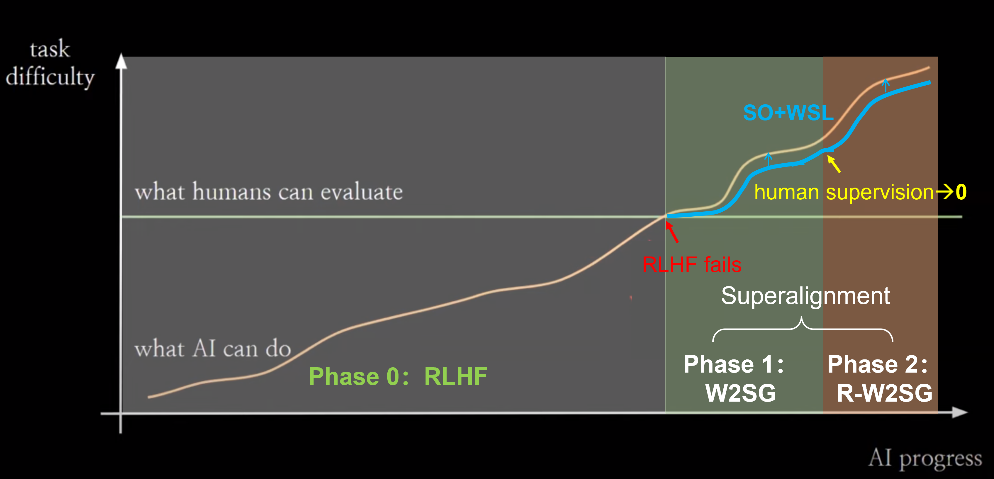
The mainstream method for achieving value alignment currently is Reinforcement Learning from Human Feedback (RLHF). RLHF is very effective when human evaluators can provide high-quality feedback signals. However, on the timescale of AI capability evolution, the evaluative capacity of humans is relatively fixed. From a certain critical point onward, humans will no longer be able to provide effective feedback signals for aligning AI systems. The core issue of super alignment is how to enable weak supervisors to control models that are much smarter than they are when this situation occurs.The Weak-to-Strong Generalization (W2SG) framework proposed by OpenAI’s super alignment team[18] provides a new solution for super alignment by simulating human supervisors with weak teacher models and strong student models that exceed human capabilities, making empirical research on super alignment possible. Scalable Oversight (SO) aims to enhance the oversight system, and combining scalable oversight can reduce the capability gap between weak supervisors and strong students, better exploring the potential of the weak-to-strong generalization framework [19]. Furthermore, weak supervision learning shares similar problem settings with weak-to-strong generalization: how to better leverage incomplete and flawed supervisory signals. Therefore, integrating scalable oversight and weak supervision learning within the weak-to-strong generalization framework can stimulate the capabilities of stronger models from the perspectives of enhancing supervisory signals and optimizing the use of supervisory signals.Super Alignment Based on Weak-to-Strong Generalization: Scalable Oversight vs. Weak Supervision LearningAs AI capabilities further improve, a second critical point may be reached: the role of human supervision gradually diminishes to zero. At this point, the already aligned strongest student model can replace humans, becoming an automated alignment evaluator, continuing to supervise even stronger student models as a new weak teacher model. The automated aligner can undergo recursive updates (Recursive W2SG, abbreviated as R-W2SG): using the supervised aligned strong student model to update the automated aligner, achieving the next generation of weak-to-strong generalization, ensuring that there exists only a generational capability gap between the weak teacher model and the strong student model.Two-Stage Super Alignment Based on Weak-to-Strong Generalization
Trend Three: From Design Objectives to Learning Objectives – Pre-training + Reinforcement Learning
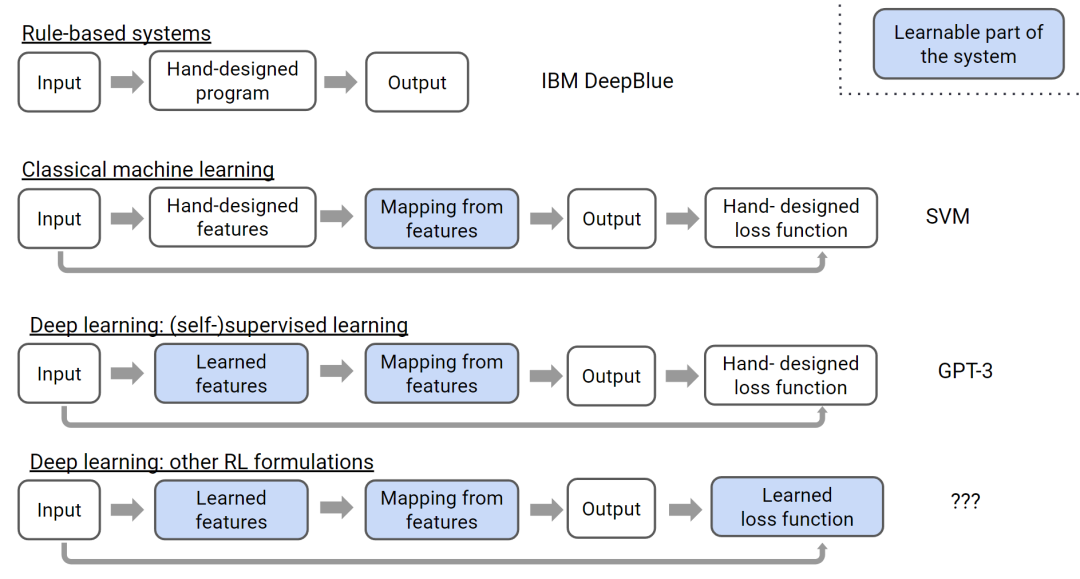
OpenAI researcher Hyung Won Chung summarized the development of artificial intelligence from expert systems, traditional machine learning, deep (supervised) learning to deep reinforcement learning from the perspective of changes in manually designed and automatically learned modules[20]. In traditional machine learning and deep learning, the objective function needs to be manually designed, focusing on learning feature representations and mappings from features to objectives. Reinforcement learning treats the objective function as a learnable module, capable of solving tasks where direct definition of objectives is challenging.Manual Design and Learnable Modules in Different Methods[20]Comparing the recent major development nodes in machine learning, deep learning and large-scale pre-training correspond to the transformation of model structures and data labeling requirements, while reinforcement learning focuses on the transformation of objective functions: learning through interaction with the environment in the absence of clear objective guidance. Combining pre-training with reinforcement learning is a research direction with great potential: pre-training compresses existing human knowledge and experience, but is constrained by probabilistic modeling, making it difficult to create unknown knowledge through low-probability events; reinforcement learning, by balancing the use of existing information and exploring unknown knowledge, introduces randomness, providing opportunities to break the limitations of pre-trained models that rely on human design, achieving a higher level of intelligence.Deep Learning vs Pre-training vs Reinforcement Learning
Currently, the training of large models typically follows three main steps: pre-training, supervised fine-tuning, and feedback-based reinforcement learning. The pre-training phase learns semantic and grammatical foundational abilities through large amounts of unlabeled data. Supervised fine-tuning enhances the model’s instruction-following capabilities through high-quality prompt-answer pairs, ensuring that the output format of answers meets expectations. The third step aims to align the model’s output with human preferences and values. Due to the complexity of human values, direct definition is very challenging. Therefore, in RLHF, a reward model is first learned as a proxy for human preferences; then, through interaction with the environment (i.e., the reward model), the model learns and gradually aligns with human values.
AlphaGo’s training involved both imitation learning and self-play reinforcement, exploring strategies that exceeded human experience; in contrast, current pre-trained large models rely solely on imitation learning, learning from corpora that reflect human activities, mimicking existing human knowledge and expressions. Referencing AlphaGo’s reward design approach for reinforcement learning, designing a self-play task for language modeling similar to winning or losing in Go may break the limitations of human knowledge. Of course, the complexity and diversity of language make defining what constitutes a “victory” challenging; a possible approach is to assign different roles or positions to the pre-trained model, enhancing capabilities through competitive or cooperative game tasks[20].Demis Hassabis believes that creativity consists of three levels: interpolation, extrapolation, and invention. According to this classification, pre-trained large models currently remain at the first level: interpolating and combining existing knowledge, but they have evidently reached a top-level standard. The 37th move in the second game between AlphaGo and Lee Sedol represents the second level of extrapolation: a strategy that human players had never seen. By combining pre-training with reinforcement learning to break the limitations of human supervision, it can be seen as an exploration of the second level of intelligence for large models. Regarding the third level, Hassabis believes it focuses on “not making a good move in Go but inventing a new game.” Correspondingly, for large models, it may need to discover new mathematical conjectures or theorems. Reflecting on AlphaGo Zero, which abandoned imitation learning from human games and independently learned from zero under only win-lose rules, could a similar approach for language, letting models explore from scratch, break the constraints of human grammar, or even develop their own language, be a solution for achieving third-level intelligence?
Prospects
(1) “True” Multimodality: Returning from Fine-tuning to Pre-training
Although the success of large language models over the past year has prompted many multimodal models to choose fine-tuning visual and speech encoders based on existing large language models, in the long run, the development of multimodal large models tends to jointly pre-train various modal data from scratch. While language is the key that distinguishes human intelligence from other animals, from the evolutionary process of the human brain, language capabilities began developing only about 500,000 years ago. The evolution of the human visual system has taken hundreds of millions of years, completing long before language capabilities formed. Moreover, educational experiences also indicate that coordinating multimodal perception aids in children’s intellectual development.Currently, we have seen some models, like Gemini, re-adopting the joint pre-training approach. Meanwhile, many predict that the next generation of multimodal large models, such as GPT-5, especially when incorporating video generation capabilities, will more likely adopt a unified joint pre-training approach. Joint pre-training can more comprehensively understand and integrate information from different modalities from the ground up, establishing deeper connections and collaborations.
(2) System One vs. System Two
While AI Agents force models into system two slow reasoning through complex prompt designs, the system one-style processing of corpora during the pre-training phase limits their complex reasoning capabilities. It is rumored that DeepMind and OpenAI are planning to enhance the utilization of training data by incorporating strategies like tree search, fundamentally guiding models to learn in a system two manner during the training phase. This training method is expected to enable models to better leverage their system two capabilities during reasoning.An interesting question arises: if system two learning is employed during the training phase while system one quick responses are used during reasoning, what effect will that produce? Reflecting on MuZero, which used MCTS self-play during training but did not perform online MCTS search during reasoning, especially in scenarios requiring rapid responses, it directly utilized the trained strategy network for decision-making. This can be understood as the model acquiring complex reasoning capabilities through system two reinforcement training and solidifying these abilities into system one intuition. This could represent a more ideal application scenario: models deeply learn and master complex reasoning capabilities during training but apply these abilities in a more direct and straightforward manner during application.
(3) Interactive Understanding and Learning
Li Feifei once pointed out that the North Star task of AI from 2020 to 2030 is to achieve active perception and interaction with the real world. If statistical methods acquire intelligence by mimicking the results of intelligence, interaction can be viewed as a pathway to acquiring intelligence through simulation. Compared to the formal expressions and automated implementations of logical deduction and inductive summary, causality may provide an important solution to achieving intelligence through interaction. Causality is expected to address the limitations of statistical machine learning in data assumptions, optimization objectives, and learning mechanisms through interventions, uncertain inference, and counterfactual reasoning.Causality: Understanding Based on InteractionInteractive learning, especially under the framework of combining pre-training and reinforcement learning, provides new perspectives for the development of artificial intelligence. For example, placing multimodal pre-training models within the framework of embodied intelligence allows them to learn and self-enhance through interaction with their environment. By interacting with physical and social environments, models can enhance their understanding and adaptability to common sense in the physical world[21] and social interactions[22].
(4) Super Intelligence vs. Super Alignment
The OpenAI palace intrigue has brought the concepts of “super intelligence” and “super alignment” into public view. As the technical leader of OpenAI, Ilya Sutskever has long been committed to enhancing the level of AI intelligence continuously. With the establishment of the super alignment team, and his personal role as team leader, his focus has shifted to alignment and safety issues.Super intelligence and super alignment represent a major thread in the future development of artificial intelligence: one explores the limits of capabilities, while the other ensures the safety baseline, one for crafting the sharpest spear, the other for constructing the sturdiest shield.References:[1] Leslie Valiant: “Evolution as Learning.” Talk @Theory-Fest 2019-2020: Evolution.[2] Mobile-Agent: Autonomous Multi-Modal Mobile Device Agent with Visual Perception. 2024.[3] Benign Adversarial Attack: Tricking Models for Goodness. 2022.[4] Towards Accuracy-Fairness Paradox: Adversarial Example-based Data Augmentation for Visual Debiasing. 2020.[5] Overview of Interpretability Research for Deep Models in Image Classification. 2022.[6] Adversarial Privacy-Preserving Filter. 2020.[7] Towards Adversarial Attack on Vision-Language Pre-training Models. 2022.[8] Counterfactually Measuring and Eliminating Social Bias in Vision-Language Pre-training Models. 2022.[9] Exploring the Privacy Protection Capabilities of Chinese Large Language Models. 2024.[10] Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback. 2022.[11] Qin Bing. “Safety Testing of Large Language Models and Human Value Alignment” Report, 2023.[12] An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation. 2024.[13] CValues: Measuring the Values of Chinese Large Language Models from Safety to Responsibility. 2024.[14] CDEval: A Benchmark for Measuring the Cultural Dimensions of Large Language Models. 2024.[15] LLMs may dominate information access: Neural retrievers are biased towards LLM generated texts. 2024.[16] AI-Generated Images Introduce Invisible Relevance Bias to Text-Image Retrieval. 2024[17] AIGCs Confuse AI Too: Investigating and Explaining Synthetic Image-induced Hallucinations in Large Vision-Language Models. 2024.[18] Weak-to-Strong Generalization: Eliciting Strong Capabilities With Weak Supervision. 2023[19] Improving Weak-to-Strong Generalization with Scalable Oversight and Ensemble Learning. 2024 WeChat Public Account Article: “Super Intelligence is the Spear, Super Alignment is the Shield.”[20] WeChat Public Account Article: “Two Guesses about Q*(Q-star).” [21] A Reconfigurable Data Glove for Reconstructing Physical and Virtual Grasps. 2023.[22] Emergent Tool Use from Multi-Agent Interaction. 2020Technical Exchange Group Invitation
△ Long press to add assistant
Scan the QR code to add the assistant on WeChat
Please note: Name – School/Company – Research Direction(e.g., Xiao Zhang – Harbin Institute of Technology – Dialogue Systems)to apply to join Natural Language Processing/Pytorch and other technical exchange groups
About Us
MLNLP Community is a civil academic community jointly constructed by scholars in machine learning and natural language processing from both domestic and international backgrounds. It has developed into a well-known machine learning and natural language processing community, aiming to promote progress among academia, industry, and enthusiasts in machine learning and natural language processing.The community can provide an open communication platform for relevant practitioners’ further education, employment, and research. Everyone is welcome to follow and join us.