This article mainly introduces some improvements and new features of HTTP2 compared to HTTP1.1.
1. Shortcomings of HTTP1.1
The HTTP protocol adopts a “request-response” model. When using the normal mode, i.e., non-KeepAlive mode, a new connection must be established for each request/response between the client and server, and the connection is immediately closed after completion (HTTP protocol is a connectionless protocol). For a complex page, there are generally multiple resources to be fetched. If a separate TCP connection is established for each resource, three-way handshakes must be performed each time to establish the connection for communication, which is very resource-intensive.
Subsequently, Keep-Alive emerged. The core issue that Keep-Alive solves is that within a certain period, multiple requests for data to the same domain name only establish one HTTP request, and other requests can reuse the established connection channel to improve request efficiency. The certain period mentioned here is generally configurable. When using Keep-Alive mode (also known as persistent connections or connection reuse), the Keep-Alive function keeps the connection from the client to the server valid for a period of time, avoiding the need to establish or re-establish connections for subsequent requests to the server.
In HTTP1.1, Keep-Alive is enabled by default. Although it solves the problem of multiple connections, there are still two serious issues:
•Serial Transmission: Under the premise of single-channel transmission, if 10 files need to be transmitted, they can only be transmitted one by one in sequence; the second cannot be transmitted until the first is finished, and so on;•Connection Count Issue: Although HTTP/1.1 enables keep-alive by default to reuse some connections, multiple connections are still required in cases like domain sharding, consuming resources and putting performance pressure on the server.
As a connection of HTTP/1.x, requests are serialized. Even if they are originally unordered, they cannot be optimized without sufficiently large available bandwidth. One solution is for browsers to establish multiple connections for each domain name to achieve concurrent requests. The default number of connections used to be 2 to 3, but the commonly used concurrent connection number has now increased to 6. If attempts exceed this number, there is a risk of triggering server DoS protection. If the server wants to respond to the website or application requests more quickly, it can force the client to establish more connections. For example, instead of fetching all resources under the same domain name, if a domain name is
www.example.com, it can be split into several domain names:www1.example.com,www2.example.com,www3.example.com. All these domain names point to the same server, and the browser will establish 6 connections for each domain name (in this example, the total connection count will reach 18). This technique is called domain sharding.
Data transmission in HTTP1.1 is based on text, which requires that the transmission must occur in the original order of the text. One major drawback of sequential transmission is that parallel transmission is impossible. For example, a Hello can only be transmitted letter by letter in order. If transmitted in parallel, the order in which the letters arrive may not match the order in the text, and the letters themselves have no order numbers, making it impossible to sort them. This can easily lead to content disorder, and Hello could become leloH.
2. Features of HTTP2
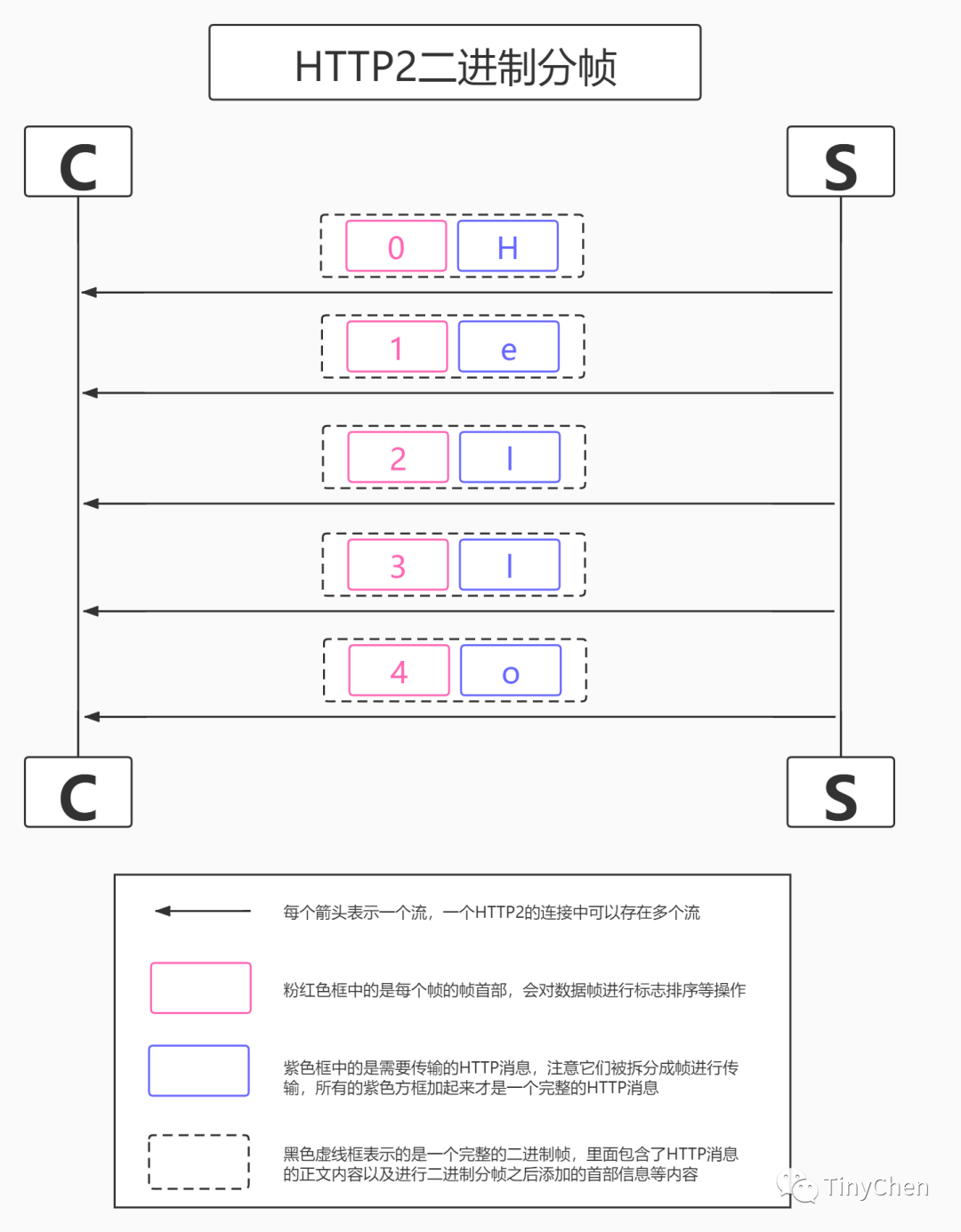
2.1 Binary Framing
HTTP2 uses binary format to transmit data, unlike the text format of HTTP 1.x, making binary protocols more efficient to parse. HTTP/1’s request and response messages consist of a start line, headers, and an optional entity body, with parts separated by text line breaks. HTTP/2 splits request and response data into smaller frames, and they are encoded in binary. In HTTP/2, all communication under the same domain name is completed on a single connection, which can carry any number of bidirectional data streams. Each data stream is sent in the form of messages, which consist of one or more frames. Multiple frames can be sent out of order, and can be reassembled based on the stream identifier in the frame header.
•Stream: A stream is a virtual channel in the connection that can carry bidirectional messages; each stream has a unique integer identifier (1, 2…N);•Message: Refers to a logical HTTP message, such as a request or response, composed of one or more frames.•Frame: The smallest unit of communication in HTTP 2.0, each frame contains a frame header, which at least identifies the stream to which the current frame belongs, carrying specific types of data, such as HTTP headers, payload, etc.
The concept of binary data frames and streams introduced by HTTP/2 allows frames to sequentially identify data. Thus, when the browser receives data, it can merge the data in sequence without causing disorder after merging. Because of the sequence, the server can transmit data in parallel, which is what streams do.
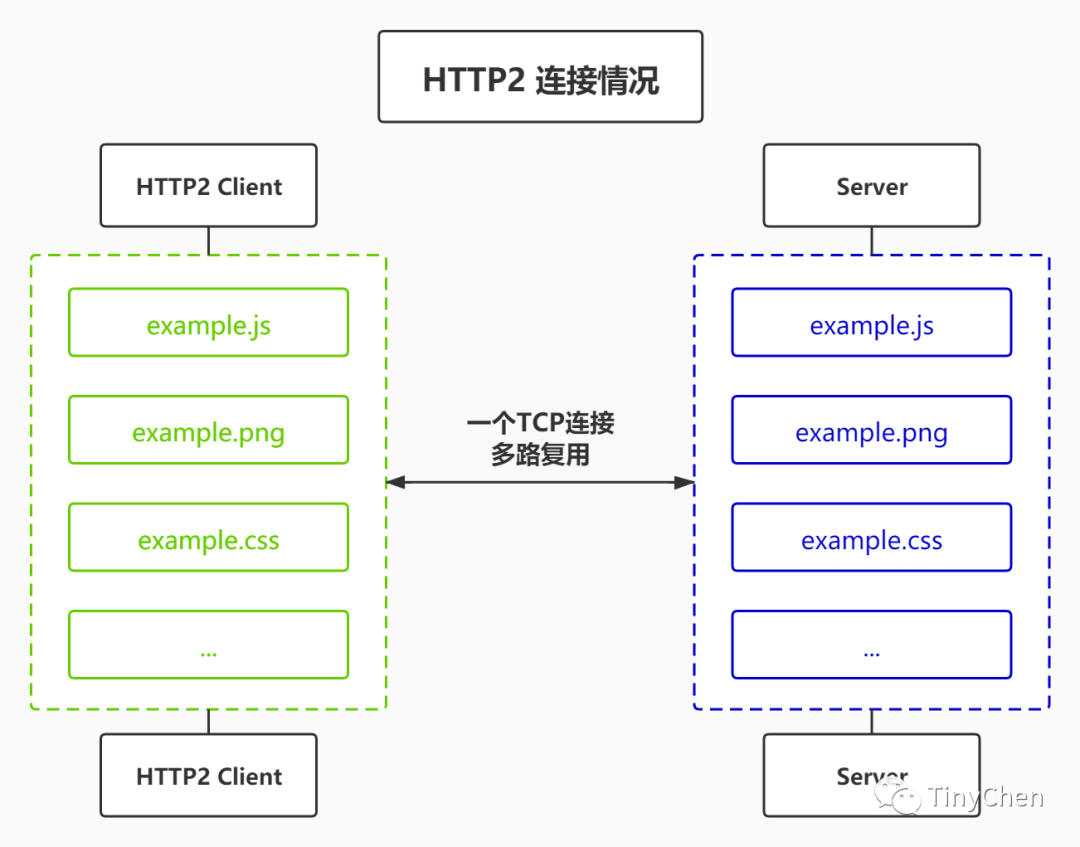
We can understand this from the following two images:

Multiplexing
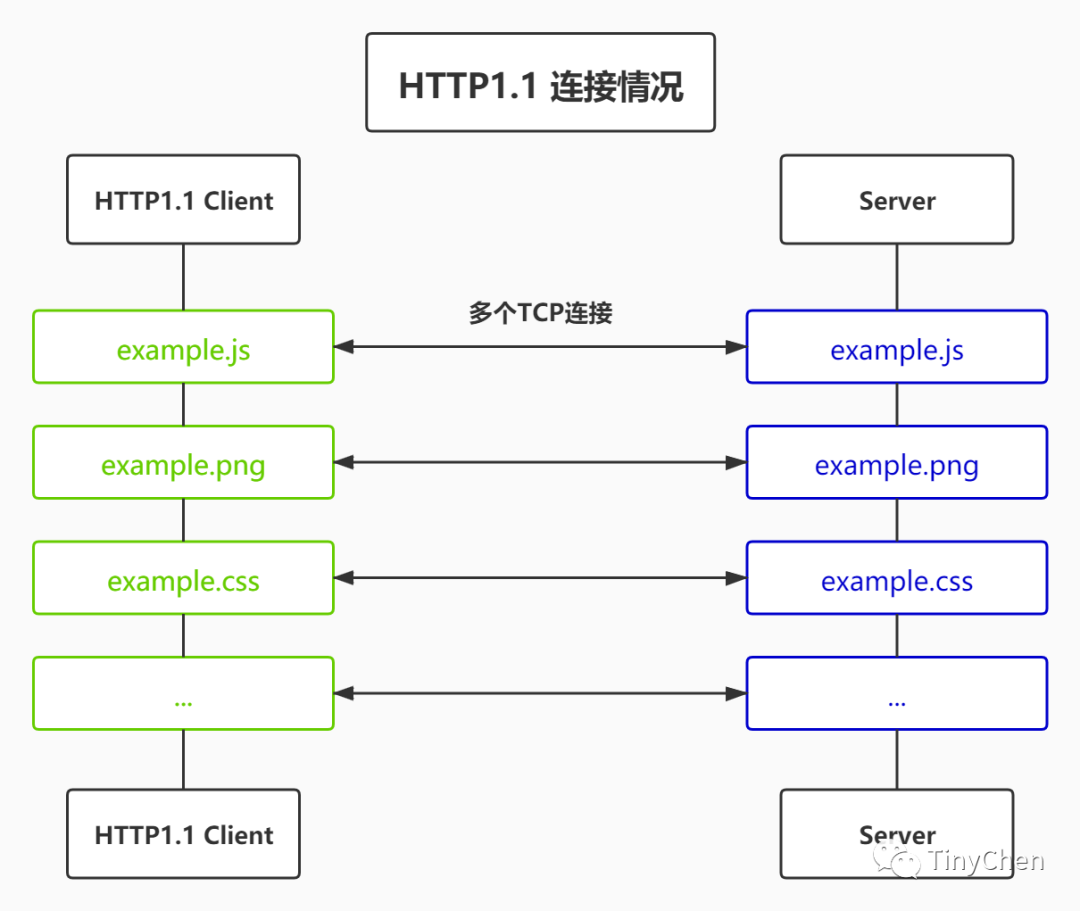
In the HTTP/2 protocol, Connection and Keep-Alive are ignored; multiplexing is mainly used for connection management. In HTTP/2, with binary framing, HTTP/2 no longer relies on TCP connections to achieve multiple streams in parallel. In HTTP/2:
•All communication under the same domain name is completed on a single connection•A single connection can carry any number of bidirectional data streams•Data streams are sent in the form of messages, which consist of one or more frames, and multiple frames can be sent out of order because they can be reassembled based on the stream identifier in the frame header.
This feature significantly enhances performance:
•Only one TCP connection is required for the same domain, using one connection to send multiple requests and responses in parallel, eliminating the delays and memory consumption caused by multiple TCP connections•Multiple requests and responses can be sent in parallel and interleaved, without affecting each other•In HTTP/2, each request can carry a 31-bit priority value, with 0 indicating the highest priority, and higher values indicating lower priority. With this priority value, clients and servers can adopt different strategies when processing different streams, sending streams, messages, and frames in the most optimal way.
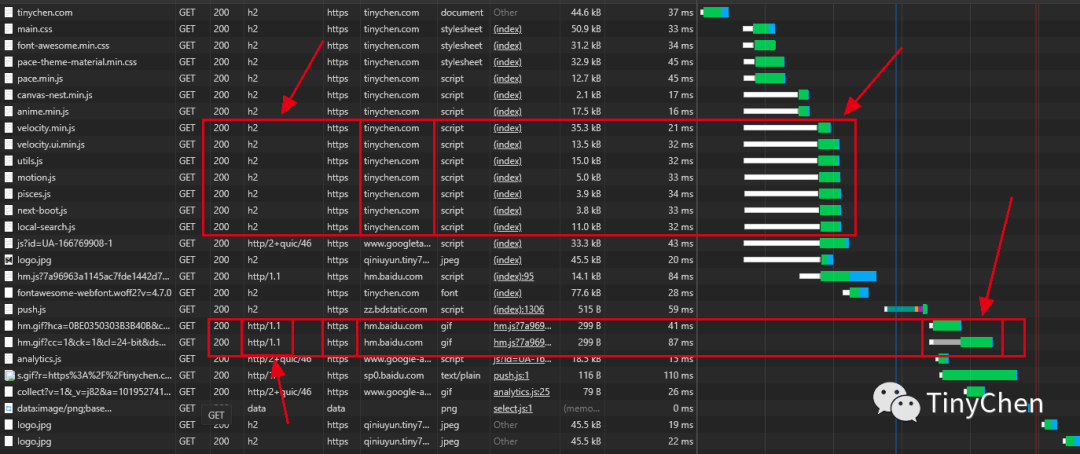
Using the browser’s developer mode to view the loading status of relevant resources, you can see that the corresponding HTTP2 resources use multiplexing during loading, allowing the client to request multiple resources simultaneously; meanwhile, HTTP1.1 shows waiting conditions when requesting resources.
2.2 Header Compression
In the same HTTP page, many resources’ headers are highly similar, but before HTTP2, they were not compressed, leading to wasted resources in repeated unnecessary operations during multiple transmissions.
In HTTP, header fields are key-value pairs, and all header fields form a header field list. In HTTP/1.x, header fields are represented as strings, with each line forming a header field list. In the header compression HPACK algorithm of HTTP/2, a different representation method is used.
The specific details of the HPACK algorithm can be found in RFC7541[1].
The objects represented by the HPACK algorithm mainly include integer values and strings of raw data types, header fields, and header field lists.
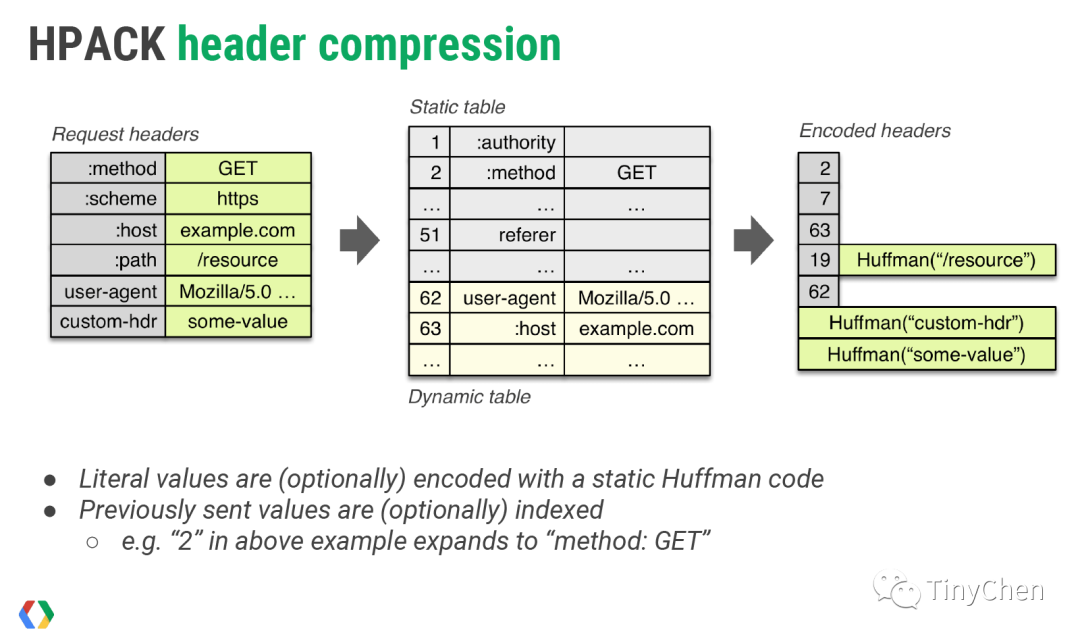
Header compression needs to be maintained between browsers and servers that support HTTP/2:
•Maintain a common static dictionary[2] that includes common header names and particularly common combinations of header names and values. Its main purpose has two aspects: for completely matching header key-value pairs, such as :method: GET, a single character can be used to represent it; for header name matching key-value pairs, such as cookie: xxxxxxx, the name cookie can be represented by a single character.•Maintain a common dynamic dictionary (Dynamic Table) that can dynamically add content. For content like cookie: xxxxxxx, it can be added to the dynamic dictionary, and thereafter the entire key-value pair can be represented by the character replaced in the field. It is important to note that the dynamic dictionary is context-related and requires maintaining different dictionaries for each HTTP/2 connection.•Support Huffman coding based on static Huffman tables;
Using dictionaries can greatly enhance compression effectiveness, with static dictionaries being usable in the initial request. For content not present in static or dynamic dictionaries, Huffman coding can be employed to reduce size. HTTP/2 uses a static Huffman table[3], which also needs to be built into both client and server.
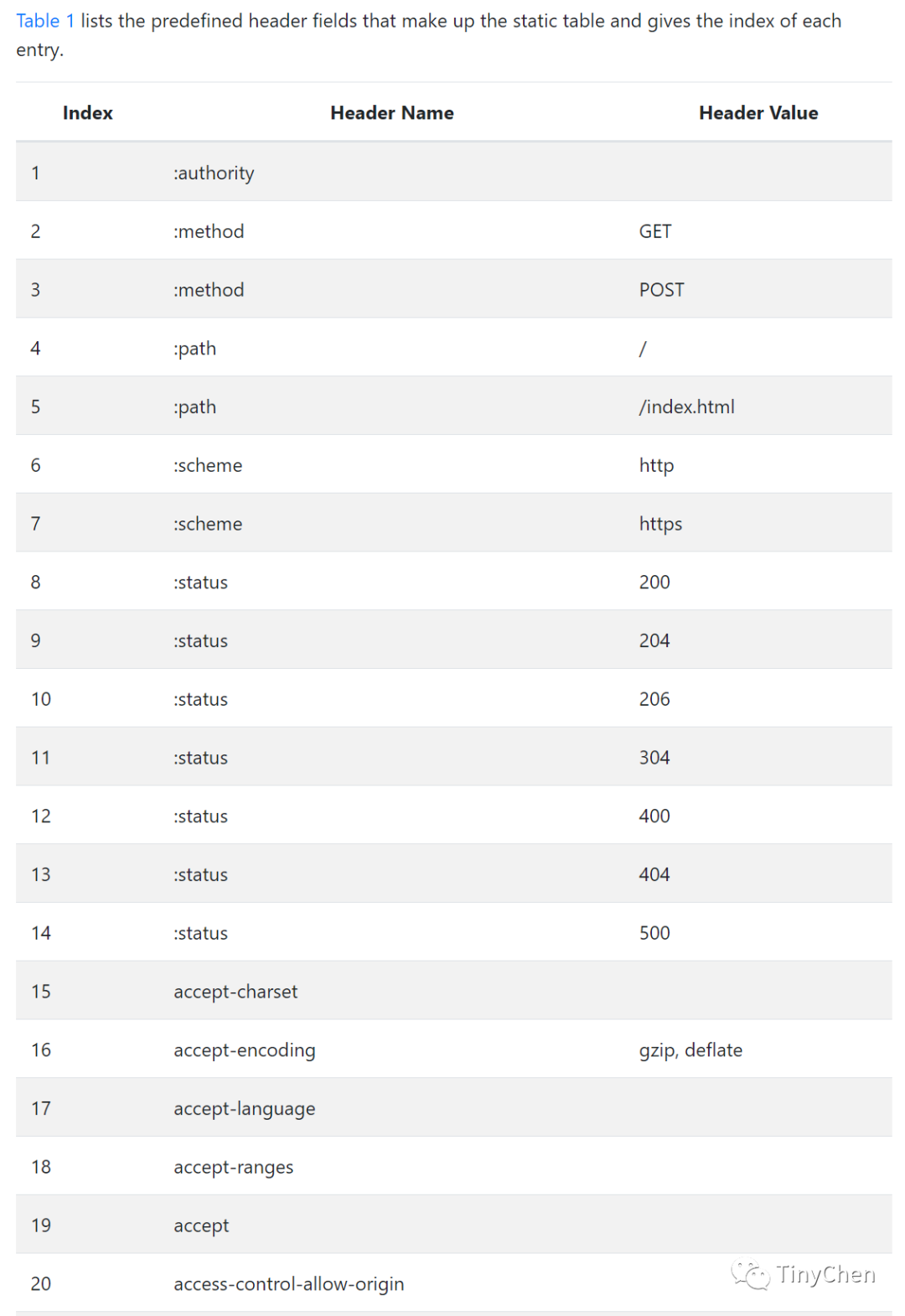
The table below captures part of the static dictionary content:
2.3 Server Push
Server Push means the server can proactively push the content needed by the client in advance, also known as “cache push.” This new feature somewhat subverts the traditional HTTP model, as the traditional HTTP model has the client requesting (request) resources, and then the server returns (response) the corresponding resources, while Server Push involves the server actively pushing resources to the client.
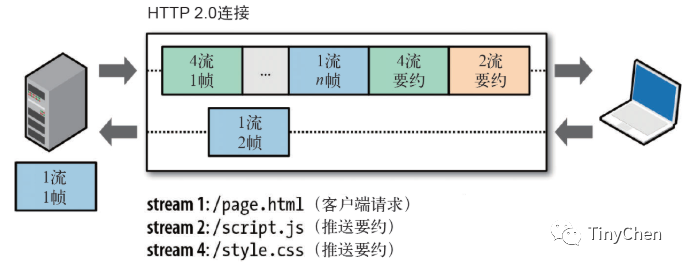
Imagine a situation where certain resources are guaranteed to be requested by the client; the server can use the server push technology to proactively push necessary resources to the client, thus reducing some latency. For example, the server can actively push JS and CSS files to the client without requiring the client to send requests for these files when parsing HTML.
The server can proactively push, and the client also has the right to choose whether to accept. If the pushed resources have already been cached by the browser, the browser can refuse to accept them by sending an RST_STREAM frame. In practice, servers should avoid pushing resources that have already been cached by the client, generally determined by examining cache-related fields in the request. Proactive pushing also adheres to the same-origin policy; in other words, the server cannot arbitrarily push third-party resources to the client without mutual confirmation.
Additionally, using server push can effectively enhance page loading speed by pushing the necessary resources to the client in advance:
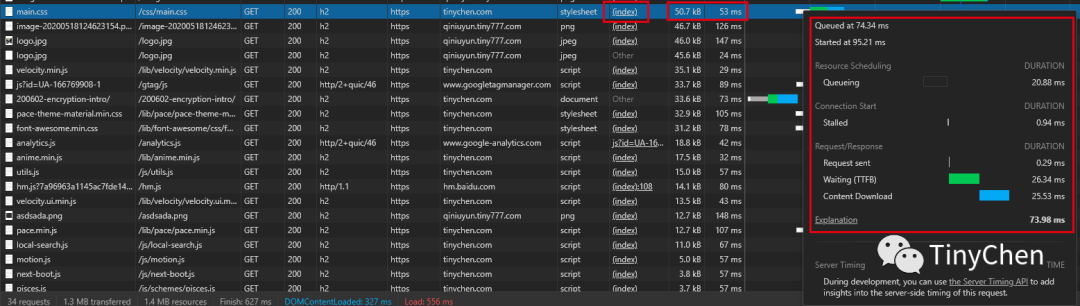
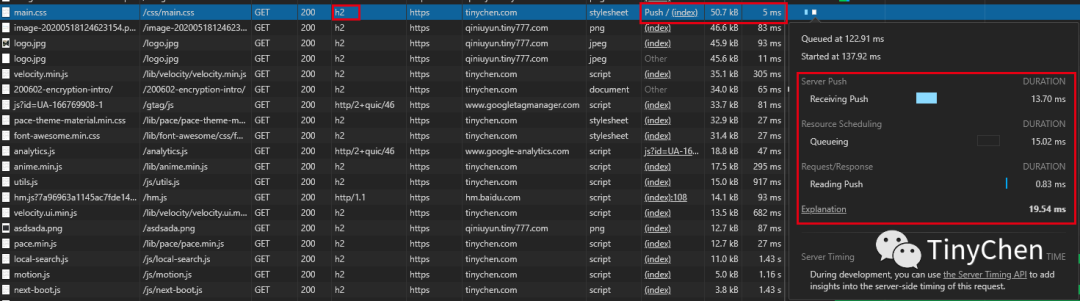
From the comparison of the above two images, we can see that the loading time of a main.css file of about 50KB has decreased from 73.98ms to 19.54ms after using the server push feature.
3. HTTP2 Negotiation Mechanism
Since not all clients and servers currently support HTTP2, there will inevitably be a negotiation process during the establishment of the HTTP connection. The specific negotiation process is as follows:
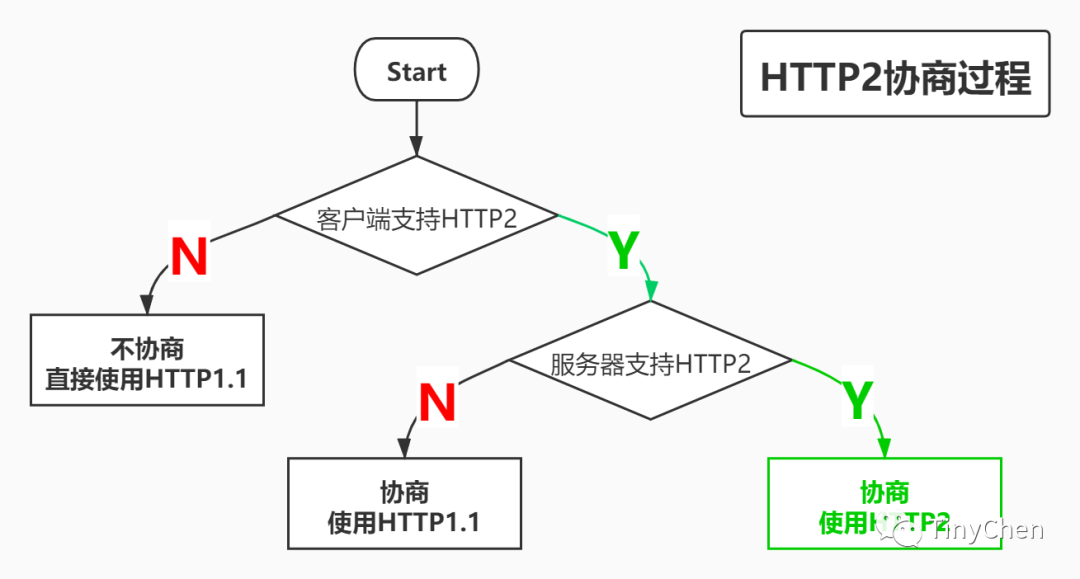
4. Shortcomings of HTTP2
In my personal view, HTTP2 has already exerted its full performance in protocol design, and unless some astonishing compression algorithms emerge, it is difficult to have further significant improvements (in fact, the performance improvement of HTTP2 compared to HTTP1.1 in practical applications is not particularly large). However, since the transport layer of the HTTP protocol still uses TCP, this may lead to some TCP-related issues.
For example, in the case of multiplexing, generally only one TCP connection is needed for the same domain. But when there is packet loss in this connection, the characteristics of TCP will require retransmission, meaning all requests must be retransmitted once, which can lead to HTTP/2 performing worse than HTTP/1.1. Because in the event of packet loss, the entire TCP connection must start waiting for retransmission, causing all subsequent data to be blocked. However, for HTTP/1.1, multiple TCP connections can be opened, and this situation will only affect one connection, while the remaining TCP connections can still transmit data normally. This situation is somewhat similar to head-of-line blocking, but this situation for HTTP2 generally occurs in poor network conditions, meaning HTTP2 tends to have a fast gets faster, slow gets slower tendency.
Head-Of-Line Blocking (HOLB): This leads to bandwidth not being fully utilized and subsequent healthy requests being blocked. HOLB[4] refers to a series of packets being blocked because the first packet is blocked; when many resources are needed on a page, HOLB can cause remaining resources to wait for other resource requests to complete before they can be initiated.
References
[1] RFC7541: https://tools.ietf.org/html/rfc7541[2] Static Dictionary: https://httpwg.org/specs/rfc7541.html#static.table.definition[3] Static Huffman Table: https://httpwg.github.io/specs/rfc7541.html#huffman.code[4] HOLB: http://stackoverflow.com/questions/25221954/spdy-head-of-line-blocking