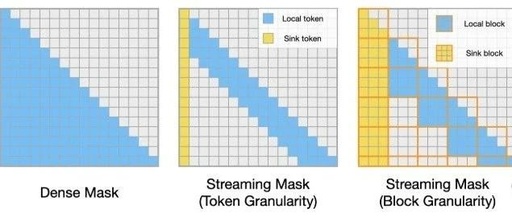
Traditional Attention, Multi-Query Attention, and FlashAttention Overview

Issues with Traditional Attention Problems with Traditional Attention There are constraints on context length. It is slow and consumes a lot of memory. Optimization Directions for Attention Increase context length. Speed up and reduce memory usage. Variants of Attention Sparse Attention: Introduces sparse biases to reduce complexity. Linearized Attention: Unrolls the attention matrix and kernel … Read more