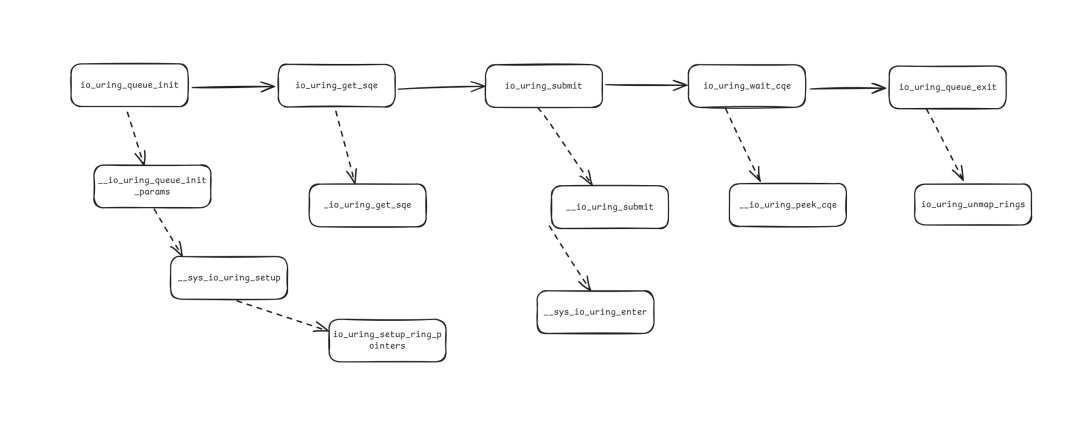
1. Network IO
The following diagram illustrates the IO process of a socket in a UDP connection:
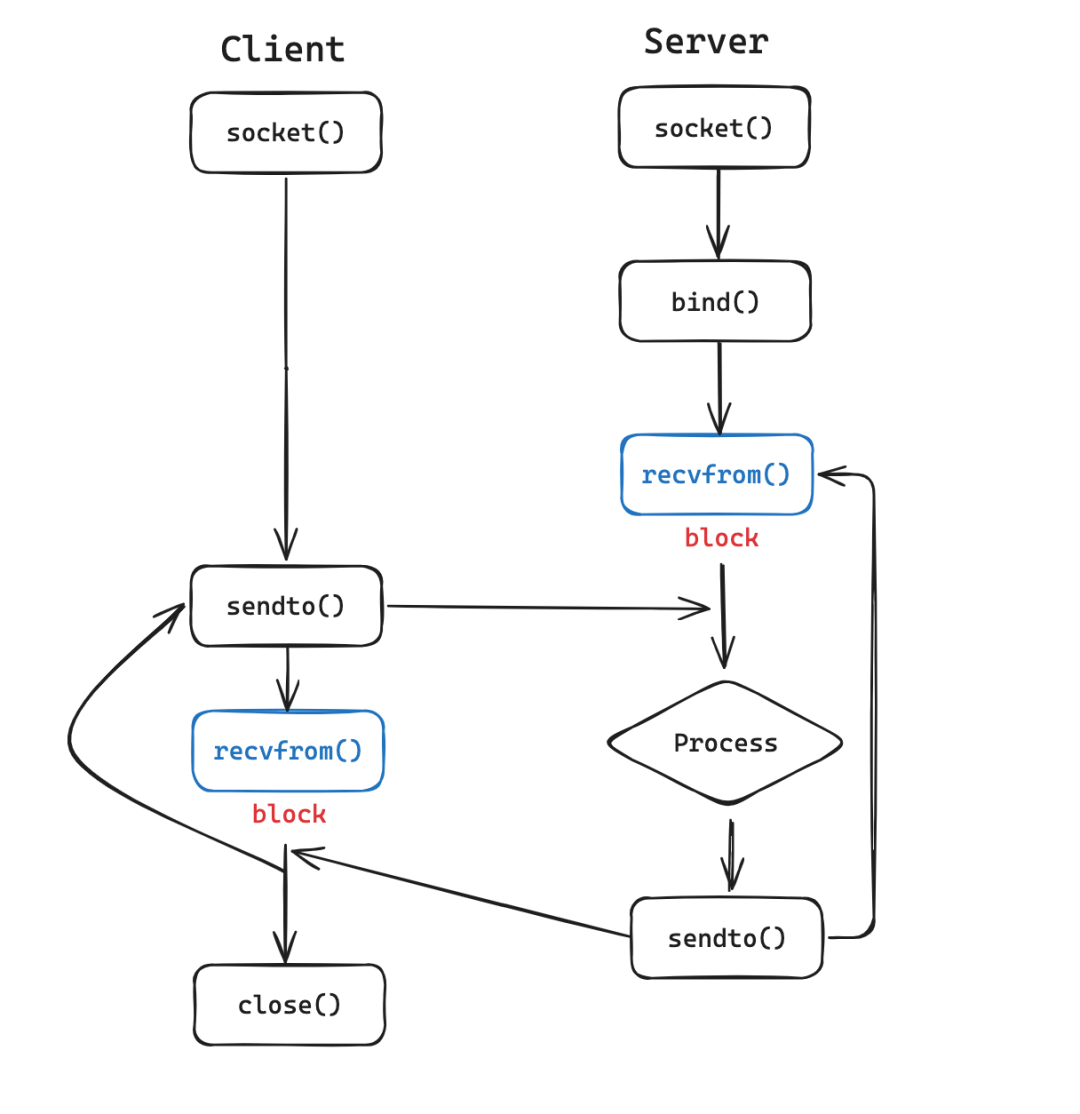
As can be seen, during each call to recvfrom, due to the latency of network data transmission, both the Client and Server need to wait to some extent. If no special handling is done, the process will block, forcing it to give up the CPU while the kernel schedules other processes to run. The more specific IO process in the kernel is as follows:
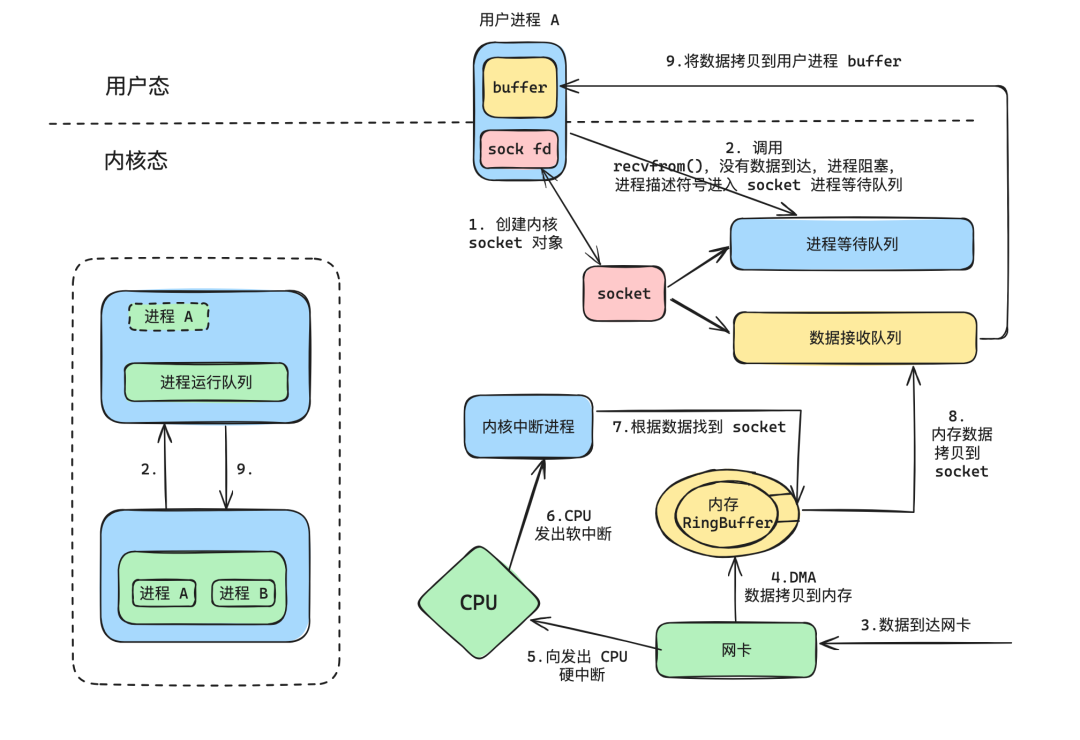
- The user process creates a socket through the socket system call.
- After configuring the process socket, it initiates a recvfrom system call, which traps into the kernel. At this point, since the socket’s data reception queue has no data, the kernel blocks the user process and adds the process descriptor to the process wait queue, then schedules other processes to execute.
- During the execution of other processes, data arrives at the network card.
- The network card uses DMA to copy the data to the memory ring buffer.
- The network card then issues a hardware interrupt to the CPU.
- The CPU sends a soft interrupt to the kernel interrupt process.
- The interrupt process first finds the corresponding socket through the data in the RingBuffer (IP + port).
- It copies the data from the RingBuffer to the socket’s reception queue and wakes up the user process.
- The user process enters the run queue and continues executing from the previously blocked recvfrom, at which point the reception queue has data, and it copies the data into the user space buffer.
From the above process, it can be seen that during a single network IO execution by the Client/Server, two waits are required:
- When calling recvfrom and trapping into the kernel, since the socket’s reception queue has no data, it needs to wait for data to enter the socket’s reception queue from the network card.
- After the socket’s reception queue is ready with data, the original user process is awakened, and it still needs to wait for the data to be copied from the kernel’s socket reception queue into user space.
Based on whether the first wait occurs, IO can be divided into blocking IO and non-blocking IO.
1. Blocking IO (BIO)
The above clearly demonstrates the blocking IO model. When the process calls recvfrom, since the data in the socket is empty, the process blocks. Only when the kernel prepares the data and copies it to user space can the process continue execution, and the recvfrom system call returns.
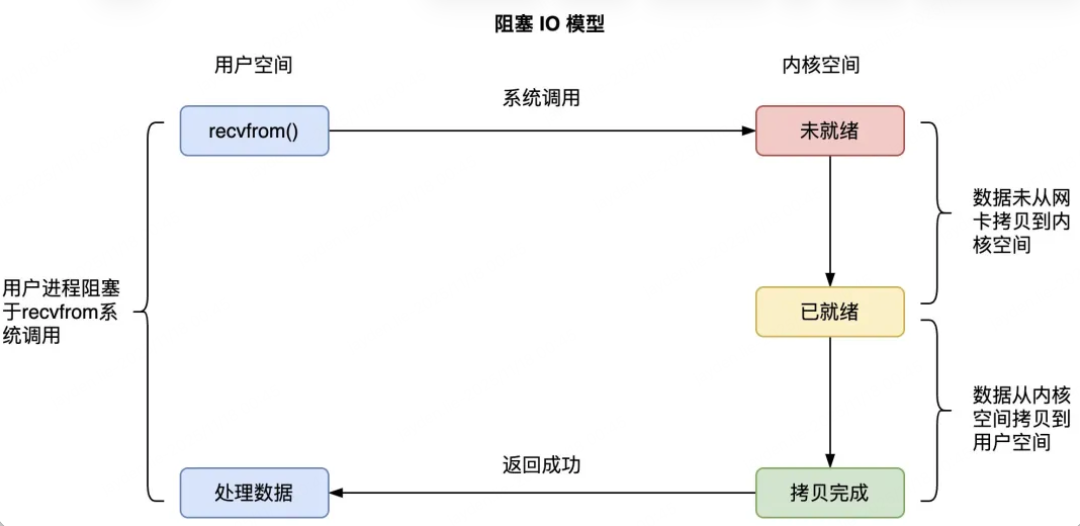
In blocking IO, when calling recvfrom, blocking occurs, leading to process switching, and data needs to undergo two conversions: from the network card to the kernel, and from the kernel to user space. Each process switch or data copy can lead to significant unnecessary CPU overhead.
2. Non-blocking IO (NIO)
Non-blocking IO means that there is no blocking during network IO. Linux implements a non-blocking option for sockets, so when calling recvfrom, if the socket reception queue is not ready with data, the process does not block, and there is no context switch; it simply returns. Therefore, polling is required to check if data is ready, as shown in the following diagram:
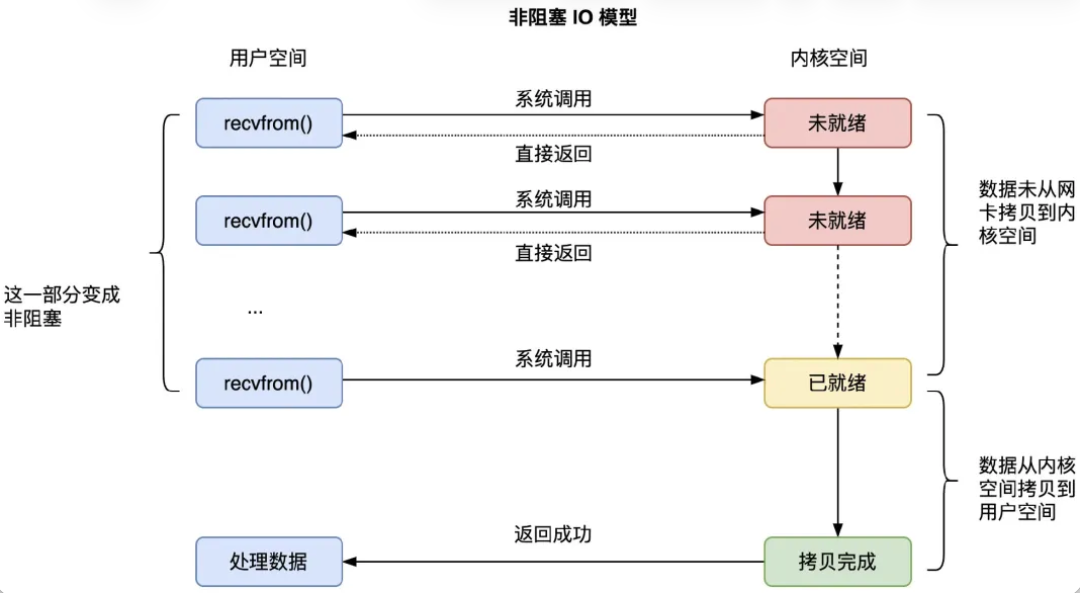
Although blocking does not occur, when data has already arrived in the kernel space’s socket reception queue, the user process still has to wait for the recvfrom() function to copy the data from kernel space to user space before returning from the recvfrom() system call.
Summary:
- NIO solves the process blocking and context switching issues of BIO, but requires frequent system calls, consuming system resources.
- In both NIO and BIO, two data copies are required: one from the network card to kernel space, and one from kernel space to user space. Even for NIO, when the data in the socket is ready, it still needs to wait for the data to be copied from the kernel to the user, which is a synchronous process for the data, thus both are synchronous IO.
3. IO Multiplexing
To address the frequent system call issue of non-blocking IO, the IO multiplexing mechanism is introduced to manage multiple connections’ IO at once. We do not need to make frequent system calls but can handle multiple connections non-blockingly. However, when no connections are ready, we still need to block the process to wait, and data still requires two rounds of copying. Since IO multiplexing is not the focus of this article, detailed introduction is omitted; please refer to the illustration on how epoll is implemented.
4. Asynchronous IO (AIO)
In the previous IO models, when data is ready in kernel mode, there is still a brief blocking wait during the process of copying data to user mode. The use of AIO is to avoid this: the kernel handles the copying of data to user mode, rather than the user thread. Thus, when data is ready in kernel mode, the process can directly read and process the data in user mode without additional wait time.
Asynchronous IO frameworks have existed in previous versions of Linux, AIO, which has been well applied in the database field. However, AIO still has some issues:
- Only supports direct IO. When using AIO, only O_DIRECT can be used, and it cannot leverage the filesystem cache to cache the current IO request. There are also size alignment restrictions (directly operating on the disk, the number of memory blocks written must be a multiple of the filesystem block size and aligned with the memory page size), which directly affects the use of AIO in many scenarios. It is almost useless for conventional non-database applications;
- Still may be blocked. Incomplete semantics.
- High copy overhead. Each IO submission requires copying 64+8 bytes, and each IO completion requires copying 32 bytes, totaling 104 bytes of copying. Whether this copy overhead is bearable depends on the size of the single IO: if the IO to be sent is large, this overhead can be ignored; however, in scenarios with many small IOs, such copying has a significant impact.
- **Unfriendly API.** Each IO requires at least two system calls to complete (submit and wait-for-completion), and care must be taken to use completion events to avoid losing events.
- High system call overhead. Because of the previous point, io_submit/io_getevents cause significant system call overhead. On machines with spectre/meltdown (CPU meltdown ghost vulnerability, CVE-2017-5754), to avoid vulnerability issues, system call performance will drop significantly. Therefore, in storage scenarios, the performance impact of high-frequency system calls is significant.
It is precisely for these reasons that a new asynchronous IO framework, IO_Uring, was designed.
2. IO_Uring Framework Structure
From the previous introduction, it can be seen that the main issues affecting performance in synchronous IO are:
- Multiple data copies (from the network card to the kernel, from the kernel to the user)
- Frequent system calls (solved by using special mechanisms: IO multiplexing)
To solve the data copying from kernel to user, the most natural idea is to share a block of memory between the kernel and user space while using a synchronization mechanism to utilize it. However, without system calls, the kernel and user space cannot share locking mechanisms, and system calls affect performance. Therefore, IO_Uring adopts a single producer single consumer ring buffer, implementing IO operations through memory ordering and memory barriers instead of shared locks. For an asynchronous interface, there are two basic operations: submitting requests and completing events. For the IO submission operation: the application is the producer, and the kernel is the consumer; for the IO completion event: the application is the consumer, and the kernel is the producer. Therefore, a pair of channels is needed for communication between the application and the kernel: submission queue (SQ) and completion queue (CQ). The general architecture is as follows:
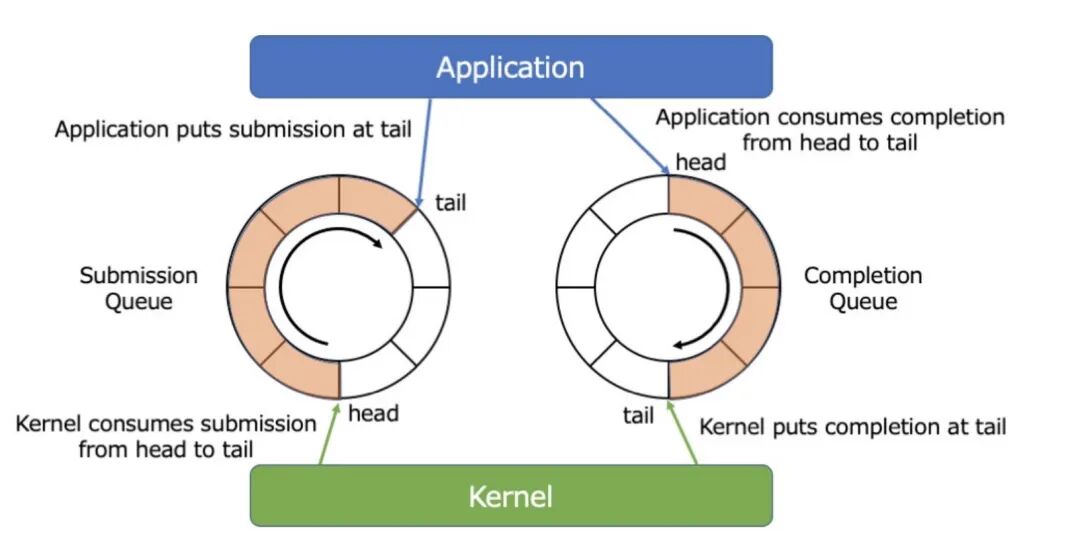
1. SQ & CQ
This section details the data structure design of SQ and CQ.
SQE
The kernel acts as a consumer, consuming SQE in SQ, while the application generates SQE with new data and submits it to SQ:
struct io_uring_sqe {
__u8 opcode;
__u8 flags;
__u16 ioprio;
__s32 fd;
__u64 off;
__u64 addr;
__u32 len;
union {
__kernel_rwf_t rw_flags;
__u32 fsync_flags;
__u16 poll_events;
__u32 sync_range_flags;
__u32 msg_flags;
};
__u64 user_data;
union {
__u16 buf_index;
__u64 __pad2[3];
};
};
- opcode: Operation code, e.g., IORING_OP_READV, representing vector read.
- flags: Set of flags.
- ioprio: Priority of the request; for normal read/write, specific definitions can refer to ioprio_set(2).
- fd: File descriptor related to this request.
- off: Offset of the operation.
- addr: Address where this IO operation is executed. If the operation code opcode describes a data transfer operation, this operation is vector-based, and addr points to the start address of the struct iovec array; if not vector-based, addr must directly contain an address, and len here (in non-vector scenarios) indicates the length of this buffer, while in vector scenarios, it indicates the number of iovec.
- Next is a union representing a series of flags for specific operation codes. For the previously mentioned IORING_OP_READV, the subsequent flags follow the preadv2 system call.
- user_data: Common for all operation codes; the kernel will not attempt to touch it.
- The last part of the structure is for memory alignment, aligned to 64 bytes. For richer features, this request structure is expected to contain more content in the future.
CQE
The application acts as a consumer, consuming CQE in CQ, while the kernel produces it in kernel space. Its data structure is:
struct io_uring_cqe {
__u64 user_data;
__s32 res;
__u32 flags;
};
- user_data: Comes from the SQE corresponding to this CQE; the kernel will not modify its data. A common application is to serve as a pointer to the original request.
- res: Result after the request is completed. For successful requests: it is the number of bytes transferred; if failed: it is a negative error value.
- flags: Set of flags. In https://kernel.dk/io_uring.pdf, it has not been used yet, but some use cases already exist in the man page.
Communication Channel
With the known data structures of SQE and CQE, this section introduces the usage of SQ and CQ. Although SQ and CQ are symmetrical in principle relative to the user process, one acts as a producer and the other as a consumer, there are still differences in indexing. Starting with the slightly simpler CQ:
unsigned head;
head = cqring→head;
read_barrier();
if (head != cqring→tail) {
struct io_uring_cqe *cqe;
unsigned index;
index = head & (cqring→mask);
cqe = & cqring→cqes[index];
/* process completed cqe here */
...
/* we've now consumed this entry */
head++;
}
cqring→head = head;
write_barrier();
For CQ, the application is the consumer and will start retrieving the corresponding CQE from head. When <span>head != cqring→tail</span>, it indicates that the CQ ring is not empty. CQE is stored internally in CQ in an array form, indexed by the CQ’s head.
Why is it necessary to create an index here with
<span>index = head & (cqring→mask)</span>?This is key to why CQ is designed as a ring buffer. Here, both head and tail are 32-bit unsigned integers, and the IO_Uring framework does not maintain the accumulation overflow of head and tail. Once they exceed the memory’s representable range, head and tail will automatically start accumulating from 0 again. By using
<span>index = head & (cqring→mask)</span>, the index’s range can be limited within the mask. For example, when the mask’s original code is 1111, regardless of how large head and tail are, the resulting index will fall within the range of 0 to 1111, and with the circular iteration of head and tail, the index is also circular. Of course, the mask is limited to 2^n – 1. In the IO_Uring framework, the mask is set to ring_entries – 1, which also requires the ring size to be a power of 2.
The usage of SQ is slightly different:
struct io_uring_sqe *sqe;
unsigned tail, index;
tail = sqring→tail;
index = tail & (*sqring→ring_mask);
sqe = & sqring→sqes[index];
/* this call fills in the sqe entries for this IO */
init_io(sqe);
/* fill the sqe index into the SQ ring array */
sqring→array[index] = index;
tail++;
write_barrier();
sqring→tail = tail;
write_barrier();
Unlike CQ, which directly indexes CQE through shared memory, SQ adds an additional layer of array in between. What is the purpose of this array?
- The application may need to submit multiple SQE at once.
- The kernel can know how many SQE need to be added through the index array.
Next, we introduce the three main system calls of IO_Uring.
2. io_uring_setup
The application sets up an instance of io_uring through <span>io_uring_setup(unsigned entries, struct io_uring_params *params);</span>. Entries indicate the expected number of SQE in the SQ ring, which must be a power of 2 ([1..4096]). The params structure is as follows:
struct io_uring_params {
__u32 sq_entries;
__u32 cq_entries;
__u32 flags;
__u32 sq_thread_cpu;
__u32 sq_thread_idle;
__u32 resv[5];
struct io_sqring_offsets sq_off;
struct io_cqring_offsets cq_off;
};
Params are read and written by the kernel, where:
- sq_entries indicates the number of SQE supported by the SQ ring.
- cq_entries indicates the size supported by the CQ ring.
- sq_off and cq_off describe the offsets of the SQ and CQ pointers in mmap.
- Other structure members involve advanced usage:
- flags are used to set the current flags for the entire io_uring, determining whether to start sq_thread, whether to use iopoll mode, etc.
- sq_thread_cpu and sq_thread_idle are also set by the user to specify the CPU and idle time for the io_sq_thread kernel thread.
For io_sqring_offsets, its structure is as follows:
struct io_sqring_offsets {
__u32 head; /* offset of ring head */
__u32 tail; /* offset of ring tail */
__u32 ring_mask; /* ring mask value */
__u32 ring_entries; /* entries in ring */
__u32 flags; /* ring flags */
__u32 dropped; /* number of sqes not submitted */
__u32 array; /* sqe index array */
__u32 resv1;
__u64 resv2;
};
To access the corresponding address of shared memory, the application must also use mmap to map the corresponding memory to user space. Since the kernel needs to map to the same address space as the application, the mmap offsets are fixed:
#define IORING_OFF_SQ_RING 0ULL
#define IORING_OFF_CQ_RING 0x8000000ULL
#define IORING_OFF_SQES 0x10000000ULL
A simple user function to set up io_uring initialization is as follows (from the man page):
int app_setup_uring(void) {
struct io_uring_params p;
void *sq_ptr, *cq_ptr;
/* See io_uring_setup(2) for io_uring_params.flags you can set */
memset(&p, 0, sizeof(p));
ring_fd = io_uring_setup(QUEUE_DEPTH, &p);
if (ring_fd < 0) {
perror("io_uring_setup");
return 1;
}
/*
* io_uring communication happens via 2 shared kernel-user space ring
* buffers, which can be jointly mapped with a single mmap() call in
* kernels >= 5.4.
*/
int sring_sz = p.sq_off.array + p.sq_entries * sizeof(unsigned);
int cring_sz = p.cq_off.cqes + p.cq_entries * sizeof(struct io_uring_cqe);
/* Rather than check for kernel version, the recommended way is to
* check the features field of the io_uring_params structure, which is a
* bitmask. If IORING_FEAT_SINGLE_MMAP is set, we can do away with the
* second mmap() call to map in the completion ring separately.
*/
if (p.features & IORING_FEAT_SINGLE_MMAP) {
if (cring_sz > sring_sz)
sring_sz = cring_sz;
cring_sz = sring_sz;
}
/* Map in the submission and completion queue ring buffers.
* Kernels < 5.4 only map in the submission queue, though.
*/
sq_ptr = mmap(0, sring_sz, PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_POPULATE,
ring_fd, IORING_OFF_SQ_RING);
if (sq_ptr == MAP_FAILED) {
perror("mmap");
return 1;
}
if (p.features & IORING_FEAT_SINGLE_MMAP) {
cq_ptr = sq_ptr;
} else {
/* Map in the completion queue ring buffer in older kernels separately */
cq_ptr = mmap(0, cring_sz, PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_POPULATE,
ring_fd, IORING_OFF_CQ_RING);
if (cq_ptr == MAP_FAILED) {
perror("mmap");
return 1;
}
}
/* Save useful fields for later easy reference */
sring_tail = sq_ptr + p.sq_off.tail;
sring_mask = sq_ptr + p.sq_off.ring_mask;
sring_array = sq_ptr + p.sq_off.array;
/* Map in the submission queue entries array */
sqes = mmap(0, p.sq_entries * sizeof(struct io_uring_sqe),
PROT_READ | PROT_WRITE, MAP_SHARED | MAP_POPULATE,
ring_fd, IORING_OFF_SQES);
if (sqes == MAP_FAILED) {
perror("mmap");
return 1;
}
/* Save useful fields for later easy reference */
cring_head = cq_ptr + p.cq_off.head;
cring_tail = cq_ptr + p.cq_off.tail;
cring_mask = cq_ptr + p.cq_off.ring_mask;
cqes = cq_ptr + p.cq_off.cqes;
return 0;
}
After setting up the IO_Uring instance, IO submissions and processing can be performed for SQ and CQ, including submitting new SQE requests to SQ and processing CQE events from CQ. Meanwhile, IO_Uring also provides some other interfaces for use.
3. io_uring_enter
The function prototype is:
int io_uring_enter(unsigned int fd, unsigned int to_submit, unsigned int min_complete, unsigned int flags, sigset_t sig);
- fd indicates the IO_Uring descriptor (returned by setup).
- to_submit specifies the number of I/O submitted in the SQ.
- Depending on the mode:
- In default mode, if
<span>min_complete</span>is specified, it will wait for this number of I/O events to complete before returning; - If io_uring is in polling mode, i.e., the flags include
<span>IORING_ENTER_GETEVENTS</span>, this parameter indicates: if events are completed, the kernel will still return immediately; if no completion events, the kernel will poll, waiting for the specified number to complete or until this process’s time slice runs out.
4. Advanced Features
Fixed File and Buffer
Each time a fd is filled into SQE and submitted to the kernel, the kernel must acquire a reference to that file. Once the IO operation is completed, the kernel releases that file reference. Since this file reference operation is atomic, it may lead to significant performance degradation in high IOPS (Input/Output Operations Per Second) workloads. To mitigate this issue, io_uring provides a method to pre-register a set of files for the io_uring instance. This way, the overhead of acquiring and releasing file references for each IO operation can be reduced. The system call for this is:
int io_uring_register(unsigned int fd, unsigned int opcode, void *arg, unsigned int nr_args);
- fd: IO_Uring instance fd.
- opcode: Operation code indicating the type of registration, e.g.,
<span>IORING_REGISTER_FILES</span>, indicating registration of a fd_set. - arg: Pointer to the array of fds that the application has opened and wants to register.
- nr_args: Number of fds in the fd_set.
Once registered successfully, the application can use its index in this arg in the fd of SQE, and needs to set the flags in SQE to <span>IOSQE_FIXED_FILE</span> to indicate that this fd is an index of a fd_set. These registered fd_sets will be released when IO_Uring is destroyed, or this interface can also be called with the opcode set to <span>IORING_UNREGISTER_FILES</span> to unregister them. Similarly, user buffers can also be registered. By registering files or user buffers, the kernel can hold onto the internal data structure reference of that file for a long time, or create long-term mappings of application memory, further improving IO performance.
Polled IO
If the application pursues very low latency performance, IO_Uring provides a polling IO mechanism for files. Here, polling means that events are no longer signaled by hardware interrupts but rather by the application continuously requesting the submission of IO status to determine if events are completed. The implementation is done by setting the <span>IORING_SETUP_IOPOLL</span> flags in <span>io_uring_setup</span>. When using polling IO, the application cannot directly check CQ to determine if IO is complete, because there will be no hardware-side completion events automatically triggering submissions to CQ; instead, it needs to first use the io_uring_enter system call and pass in the flags set to <span>IORING_ENTER_GETEVENTS</span>, and then check CQ.
Kernel Side Polling
IO_Uring has initiated and completed more requests with fewer system calls, but there are still cases where further reducing the number of system calls required to execute IO can improve efficiency. This is known as kernel-side polling. Once this feature is enabled in IO_Uring, the application no longer needs to call <span>io_uring_enter</span> to submit IO. When the application updates SQ and fills in new SQE, the kernel will automatically detect the new entries and submit them. This is done by a kernel thread specific to that io_uring.
Specific usage is as follows:
- Set the flags in the params during setup to include
<span>IORING_SETUP_SQPOLL</span>. - Additionally, by adding
<span>IORING_SETUP_SQ_AFF</span>, CPU affinity can be set, specifying the sq_thread_cpu in params as the affinity CPU. - However, this is a privileged feature that requires the application to have sufficient permissions; otherwise, it will fail.
Since the kernel thread will occupy the CPU continuously, to prevent resource waste when there is no time to complete for a long time, the process will enter sleep, and the SQ’s flags will be set to <span>IORING_SQ_NEED_WAKEUP</span>. At this point, the kernel can no longer check CQ, and a piece of code like the following is needed:
/* fills in new sqe entries */
add_more_io();
/*
* need to call io_uring_enter() to make the kernel notice the new IO
* if polled and the thread is now sleeping.
*/
if ((*sqring→flags) & IORING_SQ_NEED_WAKEUP)
io_uring_enter(ring_fd, to_submit, to_wait, IORING_ENTER_SQ_WAKEUP);
Meanwhile, the default sleep time for the kernel process is one second, but it can be set in params with the parameter sq_thread_idle. To obtain the completion IO events in kernel-side polling mode, directly check the head of CQ.
5. Memory Ordering
An important aspect of safe and effective communication in an io_uring instance is the correct use of memory ordering primitives. This is crucial when directly using the raw interfaces of io_uring. For simplicity, the documentation of io_uring simplifies the used primitives into two types:
<span>read_barrier()</span>: Ensures that previous writes are visible (completed) during read sub-operations.<span>writer_barrier()</span>: Ensures that the current write is ordered after previous writes.
Depending on the architecture, one or both of these may be no-ops. However, this is not important; what matters is that in some cases we need them, and the application needs to know what to do next. A <span>writer_barrier()</span> needs to ensure the order of writes. We say an application wants to fill in an sqe and notify the kernel that this sqe is ready to be consumed; this can actually be divided into two stages: the first stage is that some sqe has been filled and the index is stored in the array, and the second stage is that the tail of SQ is updated to inform the kernel that a new entry is available. Without any memory ordering guarantees, to optimize better, the processor will aggressively reorder these operations. Let’s look at an example:
1: sqe→opcode = IORING_OP_READV;
2: sqe→fd = fd;
3: sqe→off = 0;
4: sqe→addr = &iovec;
5: sqe→len = 1;
6: sqe→user_data = some_value;
7: sqring→tail = sqring→tail + 1;
For operation 7, which makes sqe visible to the kernel, without any memory ordering guarantees, it may occur in the middle of the previous write operation, causing the kernel to see a partially written sqe. Therefore, regardless of how sqe is filled, it must ensure that previous writes are visible before updating tail to notify the kernel. So, see the following code:
1: sqe→opcode = IORING_OP_READV;
2: sqe→fd = fd;
3: sqe→off = 0;
4: sqe→addr = &iovec;
5: sqe→len = 1;
6: sqe→user_data = some_value;
writer_barrier(); /* ensure previous writes are seen before tail write */
7: sqring→tail = sqring→tail + 1;
writer_barrier(); /* ensure tail write is seen */
Meanwhile, the kernel will also add a <span>read_barrier()</span> before reading the tail of SQ to ensure that previous write operations are visible. The same logic applies to the CQ ring, but the kernel and application are reversed.
Although memory ordering has been summarized into two specific types, the implementation of this architecture can vary depending on the machine running the code. An example from the manpage is as follows:
/* Macros for barriers needed by io_uring */
#define io_uring_smp_store_release(p, v) \
atomic_store_explicit((_Atomic typeof(*(p)) *)(p), (v), \
memory_order_release)
#define io_uring_smp_load_acquire(p) \
atomic_load_explicit((_Atomic typeof(*(p)) *)(p), \
memory_order_acquire)
int read_from_cq() {
struct io_uring_cqe *cqe;
unsigned head;
/* Read barrier */
head = io_uring_smp_load_acquire(cring_head);
/*
* Remember, this is a ring buffer. If head == tail, it means that the
* buffer is empty.
* */
if (head == *cring_tail)
return -1;
/* Get the entry */
cqe = &cqes[head & (*cring_mask)];
if (cqe->res < 0)
fprintf(stderr, "Error: %s\n", strerror(abs(cqe->res)));
head++;
/* Write barrier so that update to the head are made visible */
io_uring_smp_store_release(cring_head, head);
return cqe->res;
}
int submit_to_sq(int fd, int op) {
unsigned index, tail;
/* Add our submission queue entry to the tail of the SQE ring buffer */
tail = *sring_tail;
index = tail & *sring_mask;
struct io_uring_sqe *sqe = &sqes[index];
/* Fill in the parameters required for the read or write operation */
sqe->opcode = op;
sqe->fd = fd;
sqe->addr = (unsigned long) buff;
if (op == IORING_OP_READ) {
memset(buff, 0, sizeof(buff));
sqe->len = BLOCK_SZ;
}
else {
sqe->len = strlen(buff);
}
sqe->off = offset;
sring_array[index] = index;
tail++;
/* Update the tail */
io_uring_smp_store_release(sring_tail, tail);
/*
* Tell the kernel we have submitted events with the io_uring_enter()
* system call. We also pass in the IOURING_ENTER_GETEVENTS flag which
* causes the io_uring_enter() call to wait until min_complete
* (the 3rd param) events complete.
* */
int ret = io_uring_enter(ring_fd, 1,1,
IORING_ENTER_GETEVENTS);
if(ret < 0) {
perror("io_uring_enter");
return -1;
}
return ret;
}
3. Learning liburing
liburing is the officially supported library for io_uring. Here, we will briefly learn about the encapsulation it provides for io_uring.
1. Data Structures
In liburing, the core structures are io_uring, io_uring_sq, and io_uring_cq.
/*
* Library interface to io_uring
*/
struct io_uring_sq {
unsigned *khead;
unsigned *ktail;
// Deprecated: use `ring_mask` instead of `*kring_mask`
unsigned *kring_mask;
// Deprecated: use `ring_entries` instead of `*kring_entries`
unsigned *kring_entries;
unsigned *kflags;
unsigned *kdropped;
unsigned *array;
struct io_uring_sqe *sqes;
unsigned sqe_head;
unsigned sqe_tail;
size_t ring_sz;
void *ring_ptr;
unsigned ring_mask;
unsigned ring_entries;
unsigned pad[2];
};
struct io_uring_cq {
unsigned *khead;
unsigned *ktail;
// Deprecated: use `ring_mask` instead of `*kring_mask`
unsigned *kring_mask;
// Deprecated: use `ring_entries` instead of `*kring_entries`
unsigned *kring_entries;
unsigned *kflags;
unsigned *koverflow;
struct io_uring_cqe *cqes;
size_t ring_sz;
void *ring_ptr;
unsigned ring_mask;
unsigned ring_entries;
unsigned pad[2];
};
struct io_uring {
struct io_uring_sq sq;
struct io_uring_cq cq;
unsigned flags;
int ring_fd;
unsigned features;
int enter_ring_fd;
__u8 int_flags;
__u8 pad[3];
unsigned pad2;
};
2. Main Interfaces
A simple overview of <span>/liburing/examples/io_uring-test.c</span> demonstrates a simple usage of an IO_Uring function call chain: