
Background

-
Task Scheduling Background
-
Design of Billion-Level Task Scheduling Framework for Observability Platforms
-
Large-Scale Application of Task Scheduling Framework in Log Service
-
Outlook
General Scheduling
-
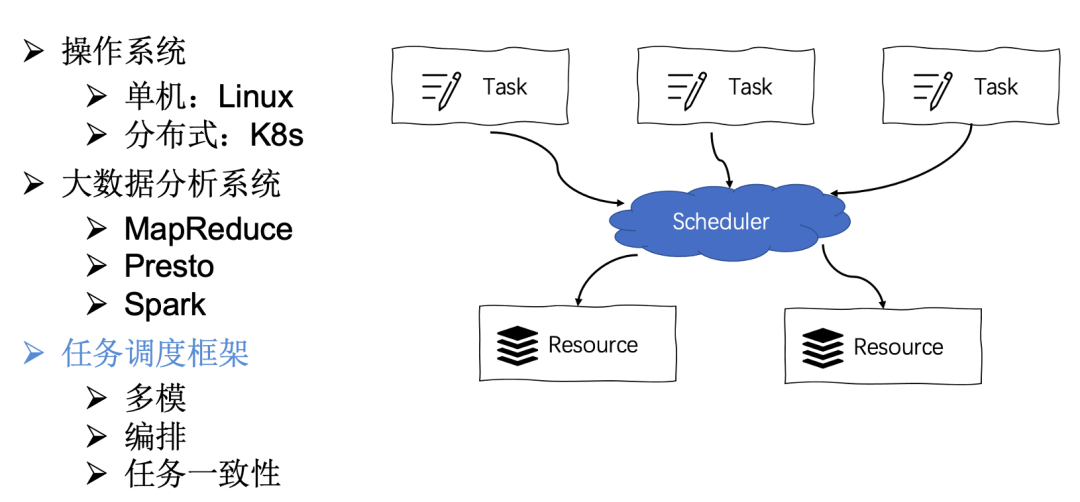
Operating System: From the perspective of single-machine operating systems like Linux, the kernel controls the execution time of processes on the processor through time slicing, where the priority of processes is linked to time slices. In simple terms, the execution of processes on a single CPU or a specific CPU is managed by the scheduler; K8s is referred to as the operating system of the distributed era. After a Pod is created, K8s’s control plane scheduler scores and ranks nodes to ultimately select suitable nodes to run the Pods.
-
Big Data Analysis Systems: From the earliest MapReduce using fair schedulers to support job priorities and preemption, to SQL computing engines like Presto that allocate tasks in execution plans to suitable workers via the Coordinator’s scheduler, Spark splits tasks into stages through DAGScheduler, and TaskScheduler finally schedules the TaskSet corresponding to the stages to suitable workers for execution.
-
Task Scheduling Framework: Common ETL processing tasks and scheduled tasks in data processing exhibit multi-modal characteristics: scheduled execution, continuous operation, one-time execution, etc. During task execution, considerations for task orchestration and state consistency are essential.
Task Scheduling
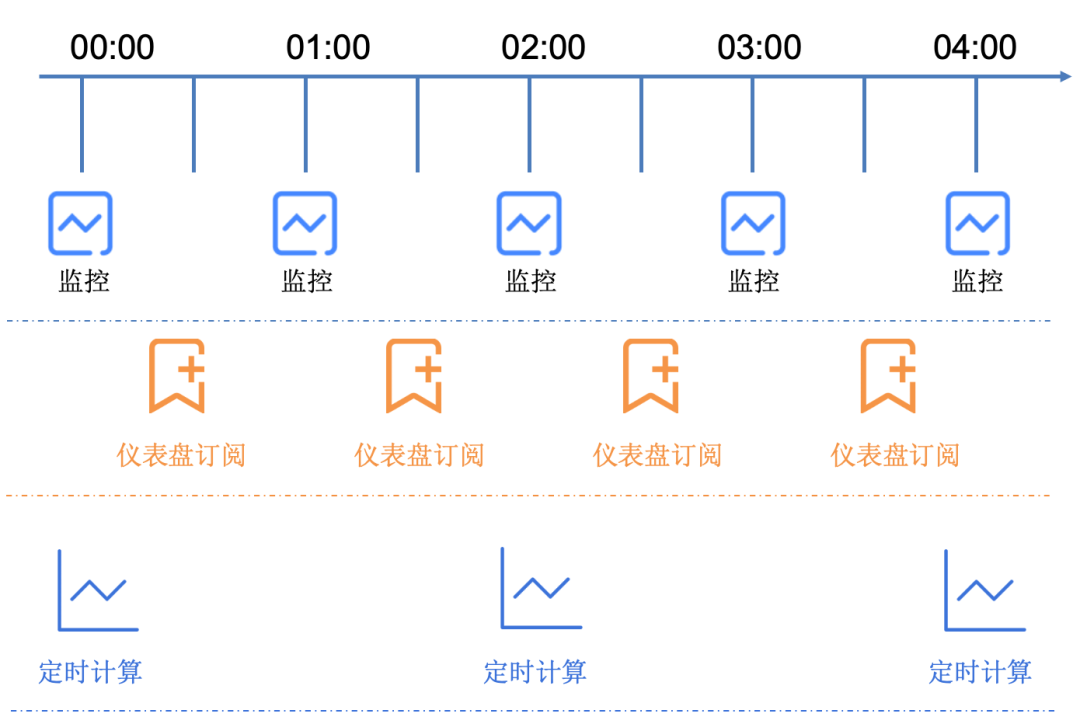
Scheduled Tasks
Task Scheduling Application: The Adventure of a Log
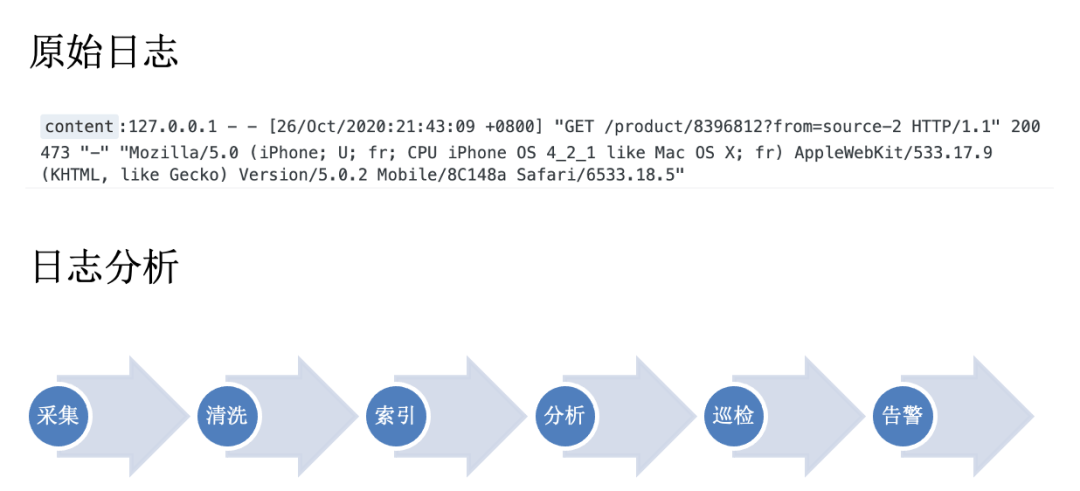
cat nginx_access.log |awk '{print $7}'| sort|uniq -c| sort -rn| head -10 | moreselect url, count(1) as cnt from log group by url order by cnt desc limit 10
In addition to logs, the system also has Trace data and Metric data, which are the three pillars of the observability system. This process is also applicable to observability service platforms. Next, we will look at the composition of a typical observability service platform’s data flow.
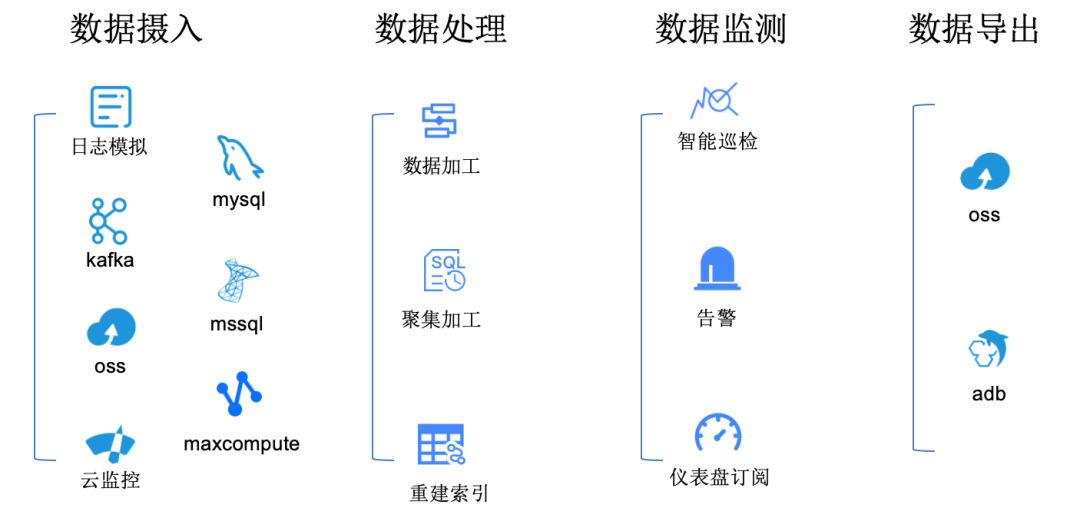
-
Data Ingestion: In the observability service platform, it is necessary to expand data sources first. Data sources may include various logs, message queues like Kafka, storage OSS, cloud monitoring data, etc., as well as various database data. By enriching the data sources, we can achieve comprehensive observability of the system.
-
Data Processing: After data is ingested into the platform, it needs to be cleaned and processed. This process is collectively referred to as data processing. Data processing can be understood as various transformations and enrichments of the data. Aggregation processing supports timed rolling up operations, such as calculating summary data for the past day every day, providing data with higher information density.
-
Data Monitoring: Observability data itself reflects the operational state of the system. The system exposes specific metrics for each component to reveal the health level of the component. Intelligent inspection algorithms can monitor abnormal metrics, such as a sharp increase or decrease in QPS or Latency. When anomalies occur, alerts can notify relevant operations personnel. Based on the metrics, various operational or operational dashboards can be created. Sending dashboards to groups daily is also a scenario requirement.
-
Data Export: The value of observability data often diminishes over time. Therefore, for long-term log data retention, it can be exported to other platforms.
-
Business complexity and diverse task types: Data ingestion alone may involve dozens or even hundreds of data sources.
-
Large user base and numerous tasks: As a cloud business, each customer has a substantial demand for task creation.
-
High SLA requirements: High service availability is required, and backend service upgrades and migrations must not affect the execution of users’ existing tasks.
-
Multi-tenancy: In cloud business, customers must not directly affect each other.
Design Goals for Task Scheduling in Observability Platforms

-
Support heterogeneous tasks: Alerts, dashboard subscriptions, data processing, and aggregation processing each have different characteristics. For example, alerts are scheduled tasks, data processing is persistent tasks, and dashboard preview subscriptions are one-time tasks.
-
Massive task scheduling: For a single alert task, if it executes once per minute, there will be 1,440 scheduling instances in a day. This number multiplied by the number of users and tasks will result in massive task scheduling. Our goal is to ensure that an increase in the number of tasks does not overwhelm machine performance, especially achieving horizontal scaling, where an increase in task count or scheduling instances only requires a linear increase in machines.
-
High availability: As a cloud business, we need to ensure that backend service upgrades, restarts, or even crashes do not affect user task execution. Both the user side and the backend service side need to have monitoring capabilities for task execution.
-
Simple and efficient operations: The backend service should provide a visual operation dashboard that intuitively displays service issues. Additionally, it should allow for alert configuration, enabling as much automation as possible during service upgrades and releases.
-
Multi-tenancy: The cloud environment naturally has multi-tenancy scenarios, and resources between tenants must be strictly isolated, with no resource or performance dependencies.
-
Scalability: In response to customers’ new requirements, future support for more task types is needed. For example, if there are already import tasks for MySQL and SQL Server, more database imports will be needed in the future. In this case, we need to modify only the plugin without changing the task scheduling framework.
-
API-driven: In addition to the above requirements, we also need to achieve API-driven management of tasks. Many overseas customers use APIs and Terraform to manage cloud resources, so task management needs to be API-driven.
Overall Overview of the Task Scheduling Framework for Observability Platforms
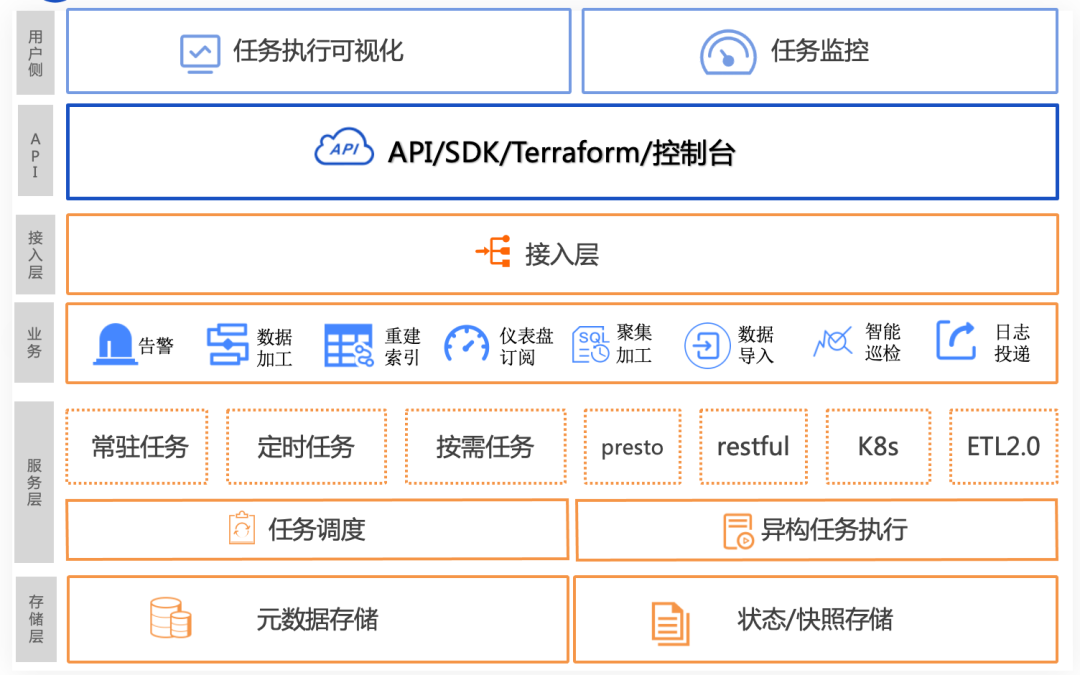
-
Storage Layer: This mainly includes the storage of task metadata and the runtime state and snapshot storage of tasks. Task metadata mainly includes task types, task configurations, and task scheduling information, all stored in a relational database; the running state and snapshots of tasks are stored in a distributed file system.
-
Service Layer: This provides the core functionalities of task scheduling, mainly including task scheduling and task execution, corresponding to the previously mentioned task orchestration and execution modules. Task scheduling mainly targets three types of tasks, including persistent tasks, scheduled tasks, and on-demand tasks. Task execution supports multiple execution engines, including Presto, RESTful interfaces, K8s engines, and an internally developed ETL 2.0 system.
-
Business Layer: The business layer includes functionalities that users can directly use in the console, such as alert monitoring, data processing, index rebuilding, dashboard subscriptions, aggregation processing, various data source imports, intelligent inspection tasks, and log delivery.
-
Access Layer: The access layer uses Nginx and CGI to provide services externally, featuring high availability and regional deployment.
-
API/SDK/Terraform/Console: On the user side, the console can be used to manage various tasks, providing customized interfaces and monitoring for different tasks. Additionally, APIs, SDKs, and Terraform can be used to perform CRUD operations on tasks.
-
Task Visualization: In the console, we provide visualizations of task execution and monitoring. Through the console, users can see the execution status and history of tasks, and also enable built-in alerts to monitor tasks.
Key Design Points of the Task Scheduling Framework
-
Heterogeneous Task Model Abstraction
-
Scheduling Service Framework
-
Support for Large-Scale Tasks
-
High Availability Design for Services
-
Stability Construction
Task Model Abstraction

-
For tasks that require scheduled execution, such as alert monitoring, dashboard subscriptions, and aggregation processing, they are abstracted as scheduled tasks, supporting scheduled and Cron expression settings.
-
For tasks that require continuous operation, such as data processing, index rebuilding, and data imports, they are abstracted as persistent tasks. These tasks often only need to run once and may or may not have an end state.
-
For preview features of data processing and dashboard subscriptions, tasks are created only when users click, and they exit after execution without needing to save the task state. These tasks are abstracted as DryRun types or on-demand tasks.
Scheduling Service Framework
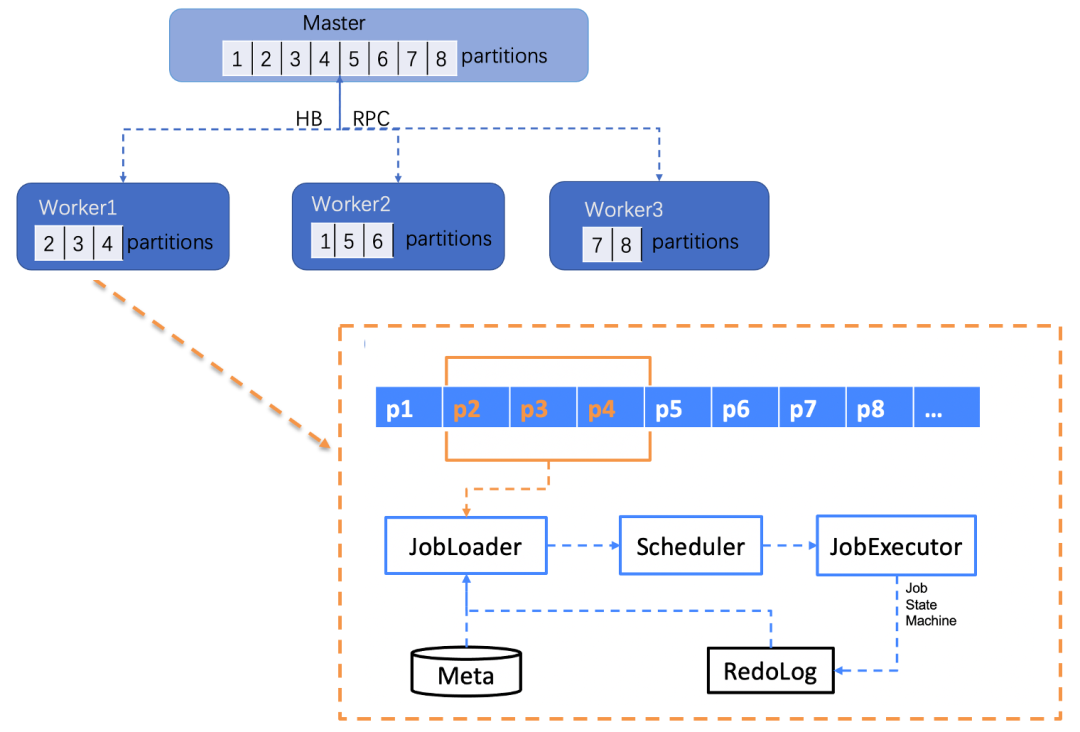
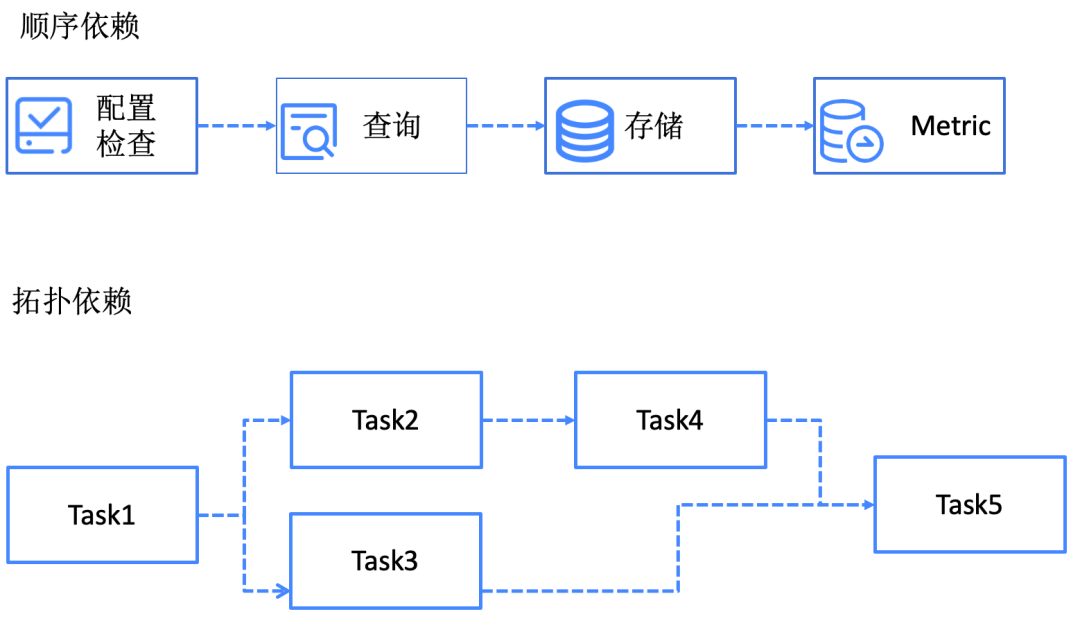
Task scheduling is mainly implemented at the Worker level, where each Worker is responsible for pulling tasks corresponding to its partitions. It then loads tasks through JobLoader. Note: It only loads the task list corresponding to the current Worker’s partitions. The Scheduler orchestrates tasks, involving the scheduling of persistent tasks, scheduled tasks, and on-demand tasks. The Scheduler sends the orchestrated tasks to the JobExecutor for execution, where the JobExecutor needs to persistently save the task status in the RedoLog during execution. When the Worker restarts or upgrades, it loads the task status from the RedoLog to ensure the accuracy of the task status.
Support for Large-Scale Tasks
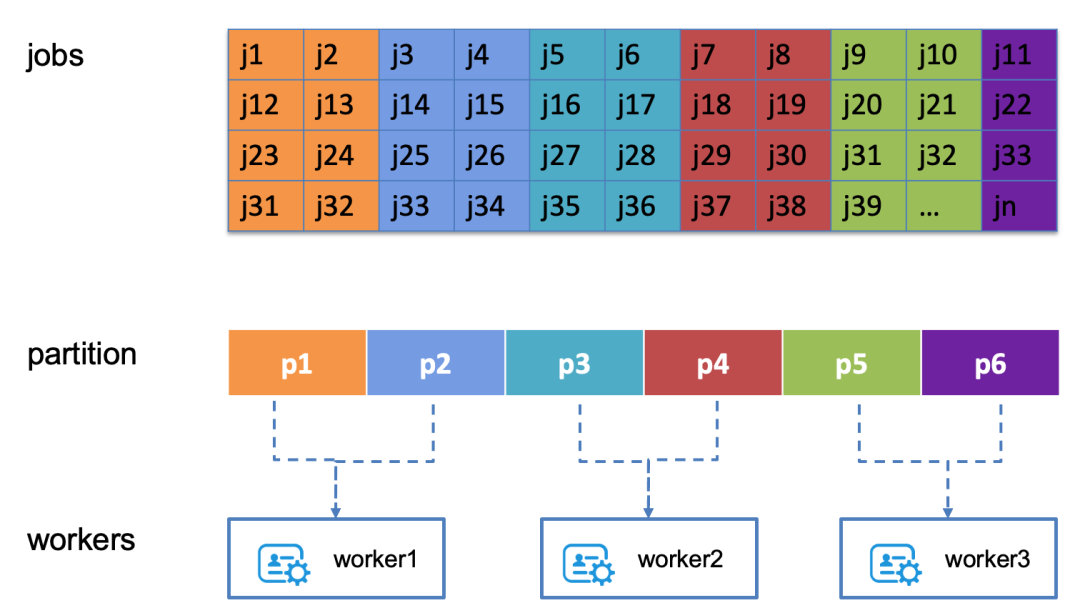
-
The correspondence between Workers and partitions is not fixed; it is a dynamic mapping. When a Worker restarts or is under high load, its corresponding partitions may migrate to other Workers, so Workers need to implement partition migration operations.
-
When the number of tasks increases, the presence of partitions allows for the addition of Workers to meet the growing task demand, achieving horizontal scaling. After adding new Workers, they can share more partitions.
High Availability Design for Services
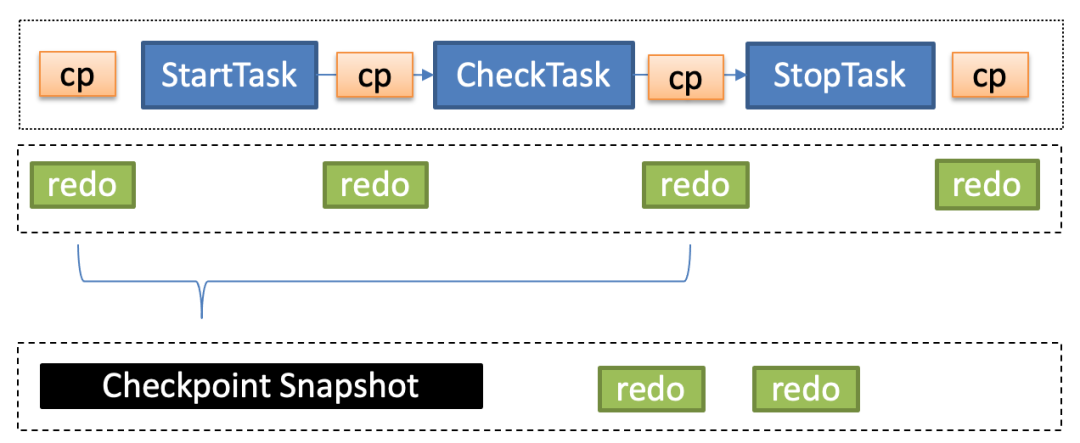
-
Release Process:
-
From compilation to release, all web-side operations are white-screened, with template-based releases. Each version can be tracked and rolled back.
-
Support for gray control at the cluster and task type levels, allowing for small-scale verification before full release.
-
Operations Process:
-
Providing internal operation APIs and web-side operations for repairing and handling abnormal jobs, reducing manual intervention in operations.
-
On-Call:
-
Internally, we have developed an inspection function to find abnormal tasks, such as those with excessively long start or stop times, which will log exceptions for tracking and monitoring.
-
Using alerting from log services based on exception logs, we can timely notify operations personnel when issues arise.
-
Task Monitoring:
-
User Side: In the console, we provide monitoring dashboards and built-in alert configurations for various tasks.
-
Service Side: In the backend, we can see the running status of cluster-level tasks, facilitating monitoring by backend operations personnel.
-
Additionally, the execution status and history of tasks are stored in a specific log database for tracing and diagnosis in case of issues.
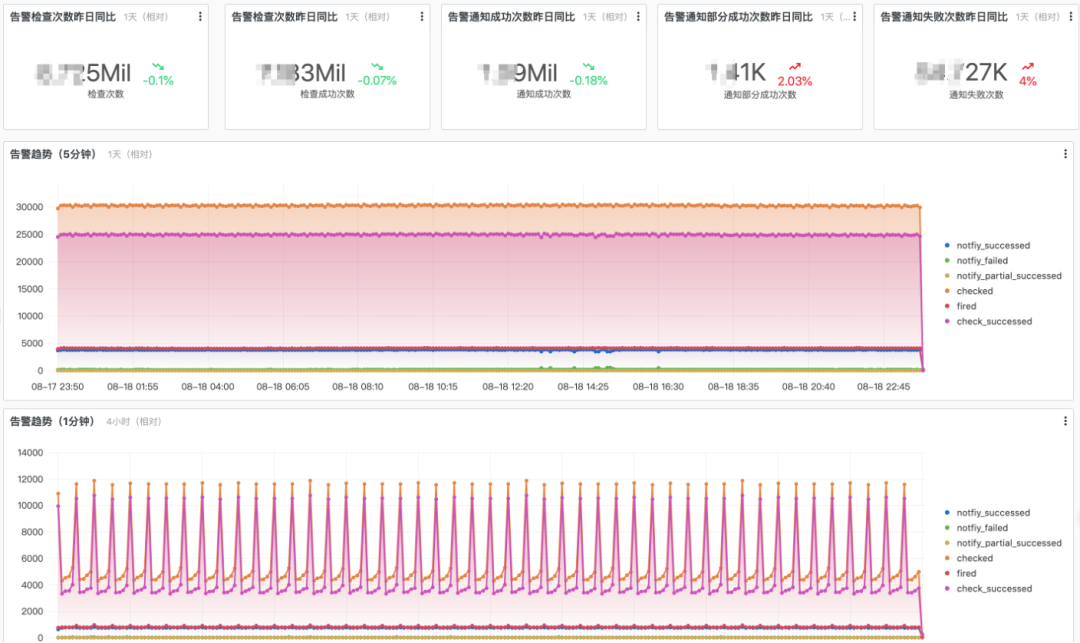
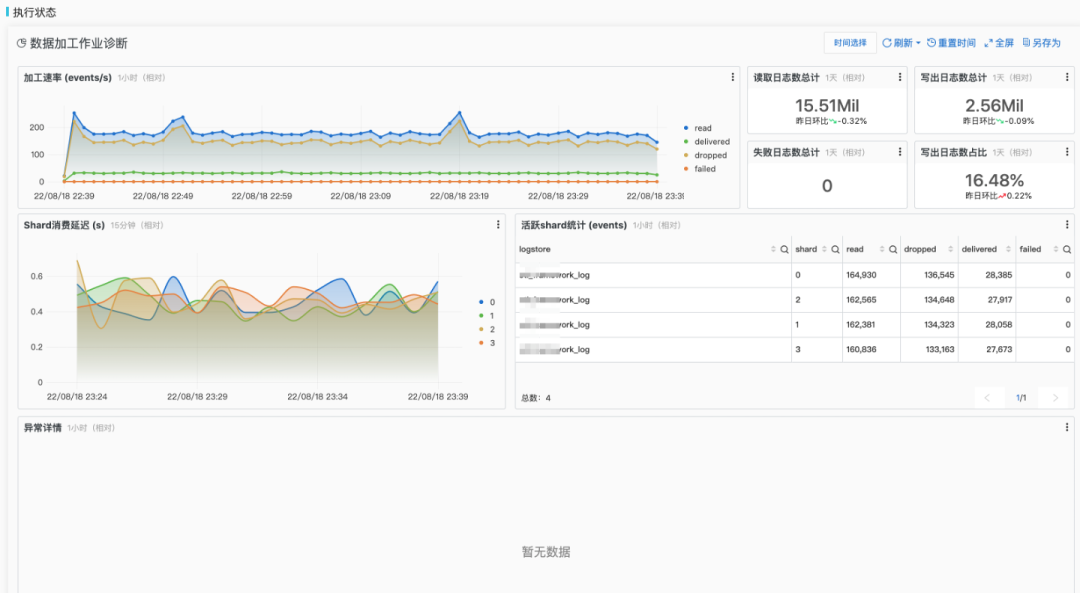
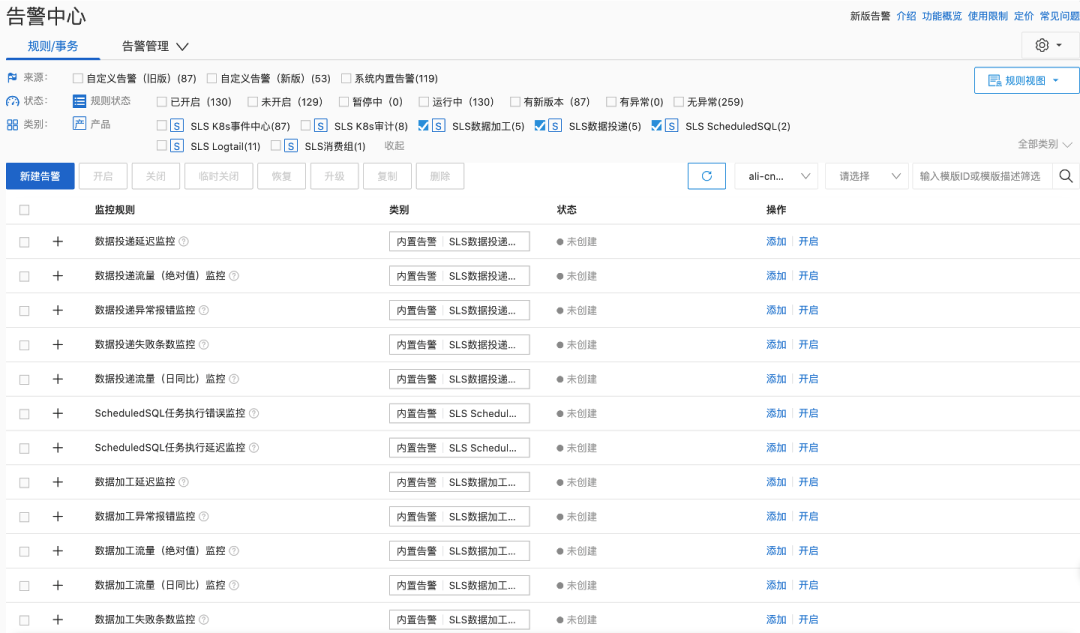
Large-Scale Applications
Typical Task: Aggregation Processing
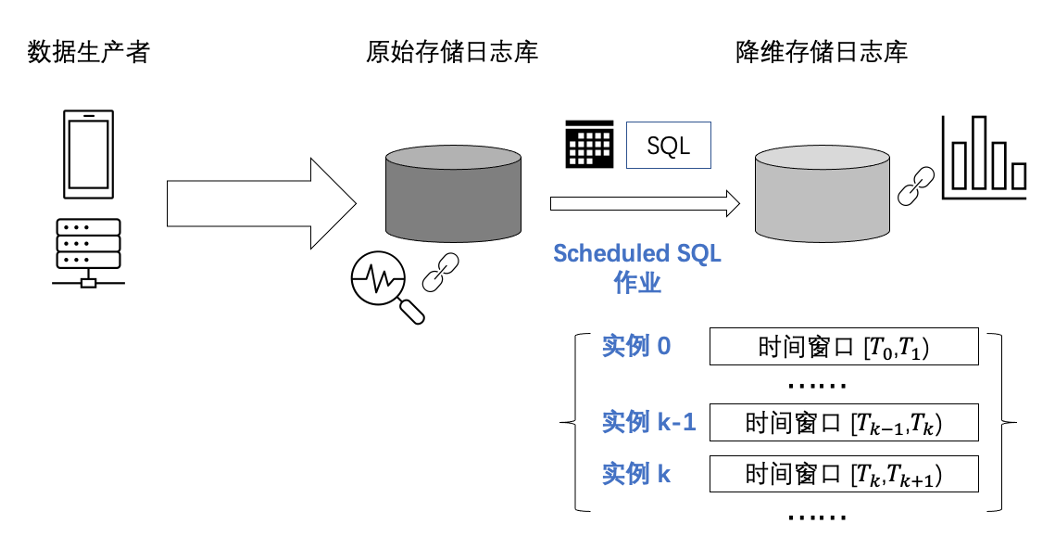
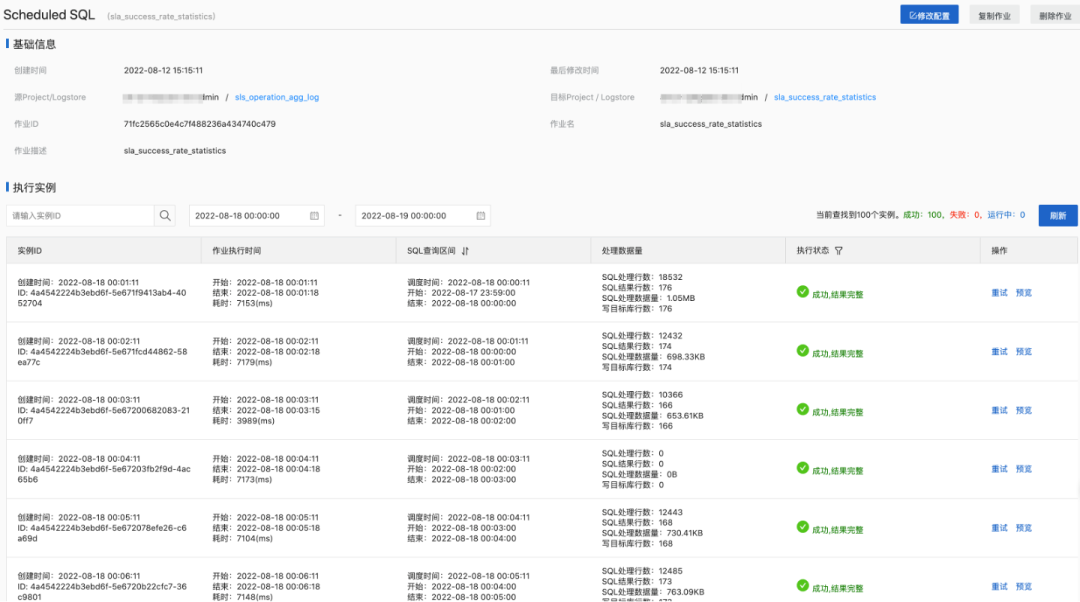
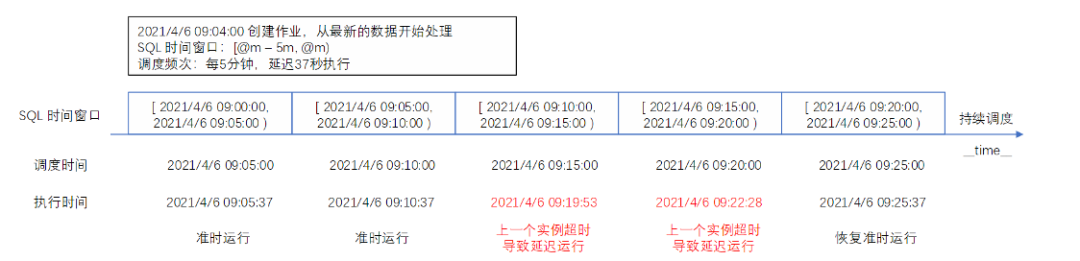
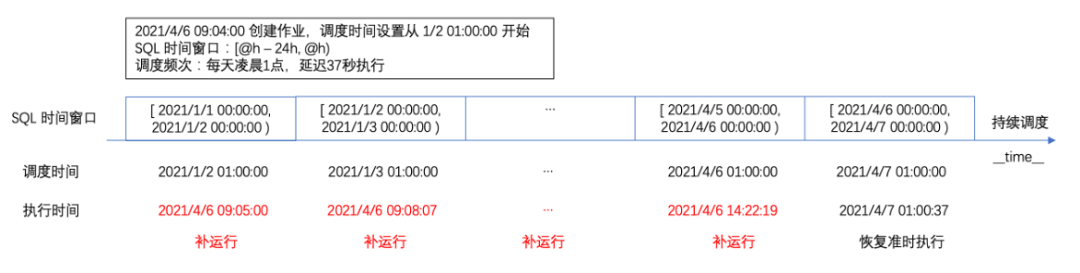

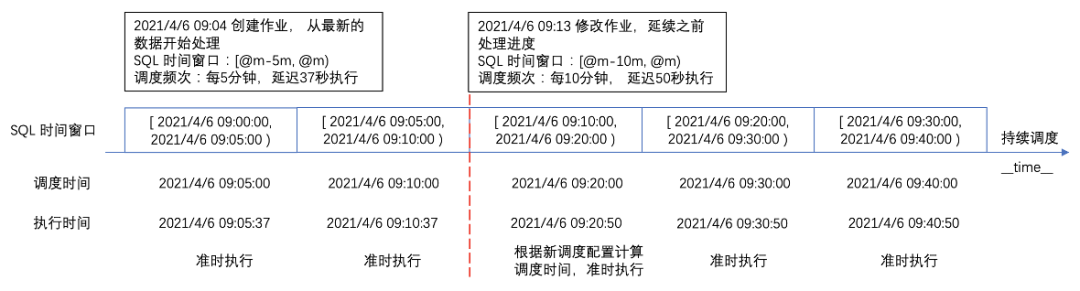
-
Automatic Retry
-
If an instance fails (e.g., due to insufficient permissions, nonexistent source or target databases, or invalid SQL syntax), the system supports automatic retries.
-
Manual Retry
-
If the retry count exceeds the maximum configured retry count or the retry time exceeds the maximum configured runtime, the retry ends, and the instance status is marked as failed, allowing the system to continue executing the next instance.
-
Dynamic Task Types: Increase support for dynamic task types, such as more complex task scheduling with inter-task dependencies.
-
Multi-tenancy Optimization: Currently, task usage is limited to simple quota restrictions. In the future, further refinement of QoS for multi-tenancy to support larger quota settings is needed.
-
API Optimization and Improvement: The current task types are rapidly evolving, and the iteration speed of task APIs needs enhancement to allow for the addition of new task types without modifying or with minimal updates to the APIs.
Recommended Reading
1.How to Write a Good Technical Proposal?
2.Ten Years of Experience at Alibaba: Architectural Design Methods in Technical Practice
3.How to Implement Defensive Coding?
The GTS Cloud Smart Wind Rider Essay Contest is Live!
Cloud Smart is the embodiment of the “modular application” concept, helping everyone improve delivery speed, enhance delivery quality, and reduce labor costs. Participating in the Cloud Smart Essay Contest not only allows you to be evaluated by a professional mentor team but also gives you a chance to win an 888 RMB Cat Supermarket Card and a Tmall Genie Sound! The first 100 participants will receive a 38 RMB Tmall Supermarket Card, available on a first-come, first-served basis!
Click to read the original text for details.