Table of Contents
-
1.1 Starting with Hello World
-
1.2 The Essence Remains Unchanged
-
1.3 The Higher You Stand, The Further You See
-
1.4 What the Operating System Does
-
1.4.1 Don’t Let the CPU Doze Off
-
1.5 What to Do When Memory is Insufficient
-
1.5.1 About Isolation
-
1.5.2 Segmentation
-
1.5.3 Paging
-
1.6 Many Hands Make Light Work
-
1.6.1 Basics of Threads
-
1.6.2 Thread Safety
-
1.6.3 Internal Situation of Multithreading
1.1 Starting with Hello World
Objective: To understand the basic flow of program execution on a computer, from basic compilation, static linking, how the operating system loads programs, dynamic linking, implementation of runtime libraries and standard libraries, and some operating system mechanisms.
1.2 The Essence Remains Unchanged
The three key components of a computer: CPU, memory, I/O control chips.
-
Early computers: No complex graphical functions, CPU and memory operate at the same frequency and are connected on the same bus.
-
CPU frequency increase: Memory cannot keep up with the CPU, leading to a system bus with memory frequency consistency, where the CPU communicates with the bus using frequency multiplication.
-
The emergence of graphical interfaces: Graphics chips require extensive data exchange with memory and CPU, and the slow I/O bus cannot meet the enormous demands of graphical devices. To efficiently process data, a high-speed northbridge chip was designed. Later, a southbridge chip was designed for low-speed processing devices, connecting disks, USBs, and keyboards to the southbridge, which aggregates them to the northbridge.
Northbridge
-
Northbridge left side CPU and cache: CPU is responsible for all control and calculations.
-
Northbridge below PCI bus
-
Northbridge right side memory
SMP and Multi-core
Currently, CPU has reached physical limits, capped at 4GHz, thus increasing the number of CPUs to enhance computer speed. Symmetric Multi-Processing (SMP): The most common form. Each CPU in the system has the same status and function, being symmetrical. However, when processing programs, we cannot split them into unrelated subproblems, which leads to actual speed improvements being less than theoretically expected. For independent problems, multiprocessors can exert their maximum performance (e.g., large databases, network services). Due to high costs, processors are mainly used in commercial computers, while personal computers mainly use multi-core processors. Multi-core processors are essentially a simplified version of SMP, combining multiple processors into a single package that shares expensive cache components while retaining multiple cores. Logically, they are identical to SMP.
1.3 The Higher You Stand, The Further You See
System Software: Generally used to manage local computer software.
Divided into two main categories:
-
Platform-based: Operating system kernel, drivers, runtime libraries.
-
Program development: Compilers, assemblers, linkers.
The architecture of computer system software adopts a layered structure. Each layer needs to communicate with each other, which involves communication protocols, referred to as interfaces. The lower layer is the provider, defining the interface, while the upper layer is the user, utilizing the interface to achieve desired functions. Apart from hardware and applications, all others are intermediate layers, each being a wrapper and extension of the layer below. They keep applications relatively independent from hardware. From the overall hierarchical structure, development tools and applications belong to the same level, as they use the same interface—the operating system Application Programming Interface (API). The provider of application programming interfaces is the runtime library, which provides various interfaces. The Windows runtime library provides Windows API, while the Glibc library under Linux provides POSIX API. The runtime library uses the system call interface provided by the operating system. The system call interface is often implemented using software interrupts. The operating system kernel layer acts as the user of the hardware interface, while the hardware is the interface’s definition provider. This interface is called hardware specification.
1.4 What the Operating System Does
One function of the operating system is to provide abstract interfaces, and another major function is to manage hardware resources. Resources in a computer are mainly divided into CPU, memory (including RAM and disk), and I/O devices. Below, we will explore how to excavate these resources from these three aspects.
1.4.1 Don’t Let the CPU Doze Off
Multiprogramming: Compiling a monitoring program that starts other programs waiting for CPU when the CPU is idle. However, its downside is that it does not prioritize tasks, and sometimes an interactive operation may wait for tens of minutes. Improved to time-sharing systems: After a CPU runs for a period, it voluntarily yields to other CPUs. The complete form of the operating system begins to emerge at this time. But when a program crashes and cannot yield the CPU, the entire system becomes unresponsive. Currently, the operating system adopts a multi-tasking system: The operating system takes over all hardware resources and runs at a level protected by hardware. All applications run at a level lower than the operating system, each with its own independent address space, isolating the address spaces of different processes. The CPU is uniformly allocated by the operating system, and each process has a chance to obtain CPU resources based on its priority. However, if it runs for too long, the CPU will allocate resources to other processes. This CPU allocation method is preemptive. If the operating system allocates very short time slices to each process, it may create the illusion that many processes are running simultaneously, known as macro parallelism, micro serialism.
Device Drivers
The operating system, as the upper layer of the hardware layer, manages and abstracts the hardware. For the runtime libraries and applications above the operating system, they only wish to see a unified hardware access model. As mature operating systems emerge, hardware gradually becomes an abstract concept. In UNIX, hardware device access is similar to accessing ordinary files. In Windows, graphic hardware is abstracted as GDI, while sound and multimedia devices are abstracted as DirectX objects, and disks are abstracted as ordinary file systems. These cumbersome hardware details are handled by hardware drivers in the operating system. The file system manages the storage method of disks. Disk Structure: A hard disk often has multiple platters, each platter divided into two sides, each side divided into several tracks, and each track divided into several sectors, with each sector typically being 512 bytes. LBA: All sectors on the hard disk are numbered from 0 to the last sector, and this sector number is called Logical Block Addressing (LBA). The file system maintains the storage structure of these files and ensures that the disk’s sectors can be effectively organized and utilized.
1.5 What to Do When Memory is Insufficient
In early computers, programs ran directly in physical memory, accessing physical addresses. How to allocate limited addresses in the computer for multiple programs? Directly allocating physical memory can lead to many issues:
-
No Address Space Isolation: All programs access physical addresses directly, leading to non-isolated physical addresses, allowing malicious programs to easily modify other programs’ memory data.
-
Low Memory Utilization Efficiency: Without an effective memory management mechanism, a monitoring program usually has to load the entire program into memory during execution. When memory is insufficient, it must first unload the program from memory to the hard disk before loading the program that needs to run. This causes a lot of data swapping.
-
Uncertain Program Running Address: Each time a program runs, it requires a sufficiently large memory space, making this address uncertain. However, during program writing, the data accessed and the target addresses for instruction jumps are fixed, which involves the issue of program relocation.
A solution: Intermediate Layer: Using an indirect address access method, we treat the addresses provided by the program as virtual addresses. Virtual addresses are mappings of physical addresses, and if this process is handled properly, it can achieve isolation.
1.5.1 About Isolation
Ordinary programs only need a simple execution environment, a single address space, and their own CPU. Address space is quite abstract; if we imagine it as an array where each element is one byte, the size of the array is the length of the address space. In a 32-bit address space, the size is 2^32=4294967296 bytes, which is 4G, with valid address space from 0x00000000 to 0xFFFFFFFF. Address space is divided into two types: Physical Space: This is the physical memory. In a 32-bit machine, there are 32 address lines, meaning a physical space of 4G, but if it has 512M of memory, the actual effective address space is 0x00000000 to 0x1FFFFFFF, while the rest are invalid. Virtual Space: Each process has its own independent virtual space, and each process can only access its own space address, effectively achieving process isolation.
1.5.2 Segmentation
Basic idea: Map a segment of virtual space of the required memory size corresponding to a certain address space. Each byte in the virtual space corresponds to each byte in the physical space. This mapping process is completed by software. Segmentation can solve the first (no address space isolation) and third problems (uncertain program running address), but the second problem of low memory utilization efficiency remains unsolved.
1.5.3 Paging
Basic method: Artificially divide the address space into fixed-size pages, with the page size determined by hardware or supported in multiple sizes by hardware, decided by the operating system. Currently, almost all PC operating systems use a page size of 4KB. We partition the process’s virtual address space by pages, loading commonly used data and code pages into memory while keeping less frequently used code and data on disk, retrieving them from disk when needed. Virtual pages in virtual space are called Virtual Pages (VP), pages in physical memory are called Physical Pages, and pages on disk are called Disk Pages. Some pages in virtual space can be mapped to the same physical page, enabling memory sharing. When a process needs a page that is a disk page, the hardware captures this message, known as a page fault, and then the operating system takes over the process, responsible for reading the content from the disk into memory, and then establishing a mapping relationship between memory and this page. Protection is also one of the purposes of page mapping; each page can have permission attributes set, and only the operating system can modify these attributes, allowing it to protect itself and the processes. The implementation of virtual storage relies on hardware support, with all hardware using a component called MMU for page mapping. The CPU issues a virtual address that is converted into a physical address by the MMU, which is usually integrated within the CPU.
1.6 Many Hands Make Light Work
1.6.1 Basics of Threads
Multithreading has become an important method for achieving concurrent execution of software, gaining increasing importance.
What is a Thread?
Thread is sometimes referred to as a lightweight process and is the smallest unit of program execution flow.
Composition:
-
Thread ID
-
Current instruction pointer
-
Set of registers
-
Stack space (code segment, data segment, heap)
-
Process-level resources (open files and signals)
Relationship between threads and processes:
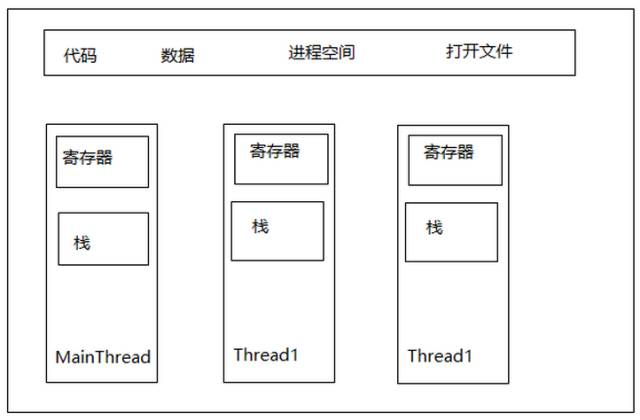
Multithreading can execute concurrently without interference and share global variables and heap data of the process. The reasons for using multithreading include:
-
Some operations may fall into long waiting states, and waiting threads will enter sleep states, unable to continue execution.
-
Some operations may consume a lot of time; if there is only one thread, the interaction between the program and the user will be interrupted.
-
The program logic itself requires concurrent operations.
-
Multi-CPU or multi-core computers inherently have the ability to execute multiple threads simultaneously.
-
Compared to multi-process applications, multithreading is much more efficient in terms of data sharing.
Thread Access Rights
Thread access is very free; it can access all data in the process’s memory, including the stack of other threads (if the address is known, which is rare). The private storage space of a thread includes:
-
Stack (completely inaccessible to other threads)
-
Thread-local storage. Some operating systems provide private space for threads, but with limited capacity.
-
Registers. Basic data for execution flow, for private use of the thread.
| Thread Private | Shared Between Threads (Process-wide) |
|---|---|
| Local variables | Global variables |
| Function parameters | Heap data |
| TLS data | Static variables in functions |
| Program code | |
| Open files, files opened by Thread A can be read by Thread B |
Thread Scheduling and Priority
Whether on multiprocessor or single processor systems, threads are “concurrent”. When the number of threads is less than the number of processors, it is true concurrency. Under a single processor, concurrency is simulated; the operating system allows these multithreaded programs to execute in turn, executing only a small segment of time each time, known as thread scheduling. In thread scheduling, threads have three states:
-
Running: The thread is executing
-
Ready: The thread can run immediately, but the CPU is occupied
-
Waiting: The thread is waiting for an event to occur and cannot execute immediately.
A running thread has a segment of time it can execute, known as time slice. When the time slice runs out, the process enters the ready state. If it begins waiting for an event before the time slice runs out, it enters the waiting state. Each time a thread leaves the running state, the scheduling system selects another ready thread to continue execution.
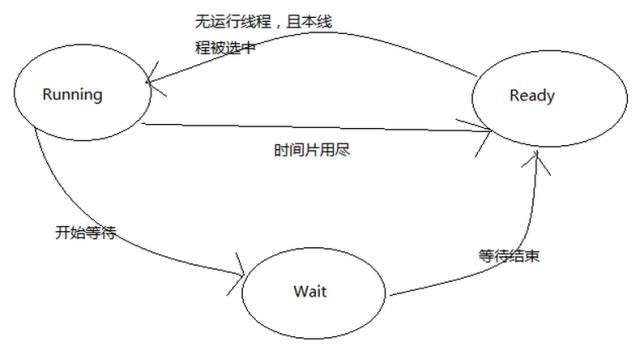
Current mainstream scheduling methods, although different, generally include priority scheduling and round-robin scheduling. Round-robin scheduling: Each thread executes in turn for a period. Priority scheduling: Threads are executed in turn according to their priority; each thread has its own priority. In Windows and Linux, thread priorities can be manually set by users, and the system can also automatically adjust priorities based on the performance of different threads. Threads that frequently wait are referred to as I/O-bound threads, while those that wait infrequently are called CPU-bound threads. Under priority scheduling, there is a phenomenon known as starvation. Starvation: Low-priority threads are always preempted by higher-priority threads, preventing them from executing. When a CPU-bound thread gains a higher priority, many low-priority threads may starve. To avoid starvation, operating systems often gradually elevate the priority of threads that have been waiting too long. Thread priority changes generally occur in three ways:
-
User-specified priority
-
Increasing or decreasing priority based on how frequently it enters the waiting state
-
Increasing priority after a long wait for execution
Preemptive and Non-Preemptive Threads
Preemption: After a thread exhausts its time slice, it is forcibly stripped of its right to continue executing and enters the ready state. In early systems, threads were non-preemptive; threads had to voluntarily enter the ready state. In non-preemptive threads, the two main ways a thread voluntarily gives up execution are:
-
When the thread attempts to wait for an event (I/O)
-
The thread voluntarily gives up its time slice
Non-preemptive threads have the advantage that thread scheduling only occurs when a thread voluntarily gives up execution or waits for an event, thus avoiding some issues related to uncertain timing in preemptive threads.
Multithreading in Linux
In the Linux kernel, there is no true concept of threads. All execution entities in Linux (threads and processes) are referred to as tasks, each conceptually similar to a single-threaded process, possessing memory space, execution entities, file resources, etc. Linux tasks can choose to share memory space, effectively forming a process with multiple tasks in the same memory space, which are the threads within the process.
| System Call | Function |
|---|---|
| fork | Duplicate the current thread |
| exec | Overwrite the current executable image with a new one |
| clone | Create a child process and start execution from a specified location |
The speed of task creation with fork is very fast because fork does not copy the original task’s memory space but shares a copy-on-write memory space with the original task.
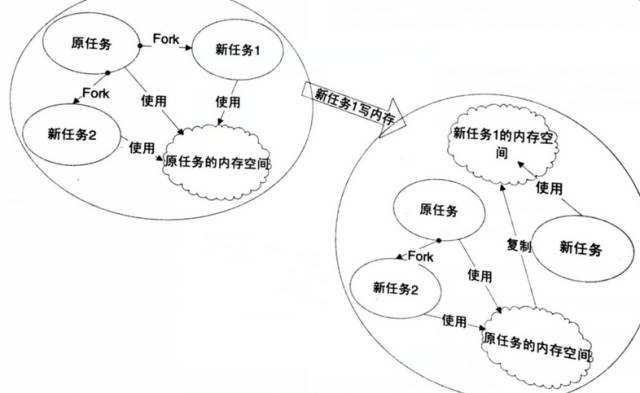
Copy-on-write: Two tasks can freely read memory simultaneously; when either task attempts to modify the memory, a separate copy is made available for the modifying task. Fork can only produce a mirror of the current task, thus needing to be used in conjunction with exec to start a new task. To create a new thread, use clone. Clone can create a new task, start execution from a specified location, and share the current process’s memory space and files, effectively producing a thread.
1.6.2 Thread Safety
Multithreaded programs operate in a variable environment, where accessible global variables and heap data can be altered by other threads at any time. Therefore, data consistency becomes very important in concurrent multithreaded programs.
Competition and Atomic Operations
Implementation of ++i:
-
Read i into a register X
-
X++
-
Store X’s content back to i
- Single instruction operations are referred to as atomic; the execution of a single instruction will not be interrupted. In Windows, there is a set of APIs specifically for performing atomic operations, called the Interlocked API.
Synchronization and Locks
To prevent multiple threads from reading the same data and producing unpredictable results, we synchronize access to data by each thread. Synchronization: When one thread finishes accessing a data item, other threads cannot access the same data. Access to the data is made atomic. Lock: A lock is a non-mandatory mechanism; each thread will first acquire a lock before accessing data or resources, and will release the lock after access. When trying to acquire a lock that is occupied, the thread will wait until the lock becomes available. Binary semaphore: The simplest type of lock, suitable for resources that can only be exclusively accessed by one thread, with two states:
-
Non-occupied state: The first thread to acquire the binary semaphore will obtain the lock, setting the binary semaphore to occupied state, while all other threads accessing this binary semaphore will wait.
-
Occupied state
Semaphore: Allows multiple threads to concurrently access resources. A semaphore initialized to N allows N threads to access concurrently. Operations are as follows:
-
Decrement the semaphore value by 1
-
If the semaphore value is less than 0, enter the waiting state.
After accessing the resource, the thread releases the semaphore:
-
Increment the semaphore by 1
-
If the semaphore value is less than 1, wake up one waiting thread.
Mutex: Similar to binary semaphore, but unlike semaphore, in a system, a mutex can only be acquired or released by the thread that acquired it; other threads’ releases are invalid. Critical section: A stricter means of locking. Acquiring a lock for a critical section is referred to as entering the critical section, while releasing the lock is referred to as exiting the critical section. The scope of the critical section is limited to the current thread, meaning other threads cannot acquire it. Other properties are similar to mutex.
Read-write lock: Aimed at specific synchronization scenarios. Using previously mentioned semaphore, mutex, or critical section for synchronization in cases where reads are frequent but writes are rare can be very inefficient. Read-write locks can avoid this issue. For the same lock, read-write locks have two acquisition methods:
Summary of read-write locks
| Read-write Lock State | Acquire in Shared Mode | Acquire in Exclusive Mode |
|---|---|---|
| Free | Success | Success |
| Shared | Success | Waiting |
| Exclusive | Waiting | Waiting |
Condition Variable: Acts as a synchronization tool, functioning like a barrier. For condition variables, threads have two operations:
-
A thread can wait on a condition variable; multiple threads can wait on a single condition variable
-
A thread can signal a condition variable; at this point, one or all threads waiting on this condition variable will be awakened and continue execution
Using condition variables allows many threads to wait for an event to occur; when the event occurs, all threads can resume execution together.
Reentrancy and Thread Safety
A function is reentrant if it can be entered again before its execution is complete due to external factors or internal calls. A function must meet the following conditions to be reentrant:
-
Not use any (local) static or global non-const variables
-
Not return pointers to any (local) static or global non-const variables
-
Only depend on parameters provided by the caller
-
Not rely on locks for any single resource
-
Not call any non-reentrant functions
Reentrancy is a strong guarantee of concurrency safety, allowing a reentrant function to be used in a multi-program environment.
Excessive Optimization
Sometimes, even reasonable use of locks does not guarantee thread safety.
1 x=0;
2 lock();
3 x++;
4 unlock();
5 //Thread2
6 x=0;
7 lock();
8 x++;
9 unlock();
The value of X should be 2, but if the compiler optimizes for speed and places X in a register, different threads’ registers are independent. Thus, if Thread1 acquires the lock first, the program execution may unfold as follows: [Thread1] reads the value of x into a register R1 (R1=0); [Thread1] R1++ (since it may access x later, Thread1 temporarily does not write R1 back to x); [Thread2] reads the value of x into a register R2 (R2=0); [Thread2] R2++ (R2=1); [Thread2] writes R2 back to x (x=1); [Thread1] (much later) writes R1 back to x (x=1); In this case, even with locking, thread safety is not guaranteed.
x=y=0;
//Thread1
x=1;
r1=y;
//Thread2
y=1;
r2=x;
The above code may result in r1=r2=0. CPU Dynamic Scheduling: During program execution, to improve efficiency, the order of instructions may be swapped. The compiler may also swap the execution order of two unrelated adjacent instructions for efficiency. The execution order of the above code may be as follows:
x=y=0;
[Thread1]
r1=y;
x=1;
[Thread2]
y=1;
r2=x;
Using the volatile keyword can prevent excessive optimization. Volatile can do two things:
-
Prevent the compiler from caching a variable into a register without writing it back for speed improvement
-
Prevent the compiler from rearranging the order of operations on volatile variables
However, volatile cannot prevent CPU dynamic scheduling from reordering. In C++, singleton pattern.
volatile T* pInst=0;
T* GetInstance()
{
if(pInst==NULL)
{
LOCK();
if(pInst==NULL)
pInst=new T;
unlock();
}
return pInst;
}
CPU’s out-of-order execution may affect the above code. In C++, new consists of two steps:
-
Allocate memory
-
Call the constructor
Thus, pInst=new T consists of three steps:
-
Allocate memory
-
Call the constructor at the memory location
-
Assign the memory address to pInst
Among these three steps, steps 2 and 3 can be swapped, potentially leading to a scenario where pInst contains a non-NULL value, but the object is not yet constructed. To prevent CPU reordering, a specific instruction, often referred to as a barrier, can be called: It prevents the CPU from swapping instructions before the barrier with those after it. Many CPU architectures provide barrier instructions, although their names vary. For example, the instruction provided by POWERPC is called lwsync. Thus, we can ensure thread safety as follows:
#define barrier() __asm__ volatile ("lwsync")
volatile T* pInst=0;
T* GetInstance()
{
if(pInst==NULL)
{
LOCK();
if(pInst==NULL)
{
T* temp=new T;
barrier();
pInst=temp;
}
unlock();
}
return pInst;
}
1.6.3 Internal Situation of Multithreading
The concurrent execution of threads is achieved through multiprocessors or scheduling by the operating system. Both Windows and Linux provide thread support in their kernels, achieving concurrency through multiprocessors or scheduling. Users actually use user threads that do not necessarily correspond to an equal number of kernel threads in the operating system. For users, if three threads execute simultaneously, there may be only one thread in the kernel.
One-to-One Model
For systems that directly support threads, the one-to-one model is always the simplest. A user thread corresponds uniquely to a kernel thread. However, a kernel thread may not necessarily correspond to a user thread in user mode.
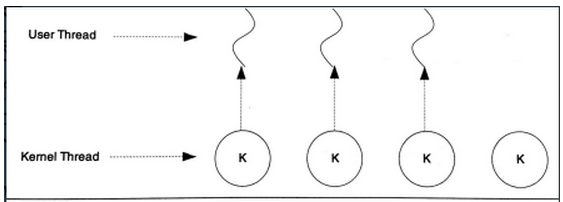
In the one-to-one model, concurrency between threads is true concurrency; if one thread blocks for some reason, it does not affect other threads. The one-to-one model also allows multithreaded programs to perform better on multiprocessor systems. Generally, threads created using APIs or system calls are one-to-one threads. Two disadvantages of one-to-one threads:
-
Many operating systems limit the number of kernel threads, so one-to-one threads can limit the number of user threads.
-
Many operating systems have high overhead for context switching of kernel thread scheduling, leading to decreased execution efficiency of user threads.
Many-to-One Model
The many-to-one model maps multiple user threads to a single kernel thread, with thread switching performed by user-mode code, making it much faster than the one-to-one model.
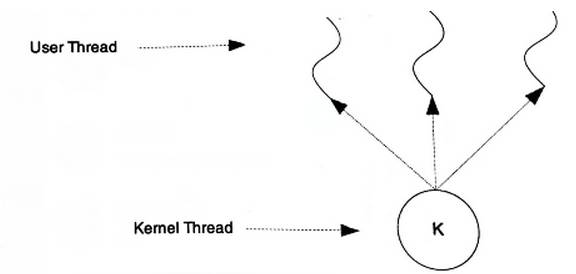
The problem with the many-to-one model is that if one user thread blocks, all threads will be unable to execute. In multiprocessor systems, increasing the number of processors does not significantly improve the performance of many-to-one model threads. The benefits of the many-to-one model are efficient context switching and nearly unlimited thread count.
Many-to-Many Model
The many-to-many model combines the features of both many-to-one and one-to-one, mapping multiple user threads to a few, but not just one, kernel threads.
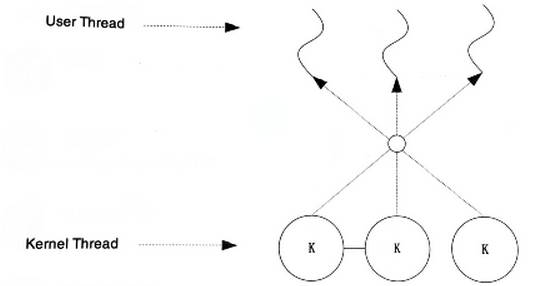
A blocking user thread does not cause all user threads to block. Additionally, there are no limits on the number of user threads; the many-to-many model can achieve some performance improvements on multiprocessor systems, although the improvement is not as high as in the one-to-one model.
Source: http://www.cnblogs.com/Tan-sir/p/7272652.html
Author: Tan-sir
