Introduction Compared to traditional LLM inference frameworks (such as HuggingFace Transformers, TensorRT-LLM, etc.), vLLM demonstrates significant advantages in performance, memory management, and concurrency capabilities, specifically reflected in the following five core dimensions:1. Revolutionary Improvement in Memory Utilization By utilizing Paged Attention technology (inspired by the memory paging mechanism of operating systems), the KV Cache (Key-Value Cache) is divided into fixed-size blocks, dynamically allocated and reclaimed as needed. This innovation addresses the 60%-80% waste issue caused by pre-allocated memory in traditional frameworks, increasing memory utilization to nearly 96%, with actual tests showing memory waste below 4%. For example, when generating a sequence of 512 tokens, traditional frameworks may pre-allocate all space but only use 200 tokens, while vLLM allocates only the necessary blocks, significantly reducing memory redundancy.2. Breakthrough in Throughput and Concurrency By adopting Continuous Batching and Prefill/Decode Separation Strategy, vLLM dynamically merges the inference processes of multiple requests, bringing GPU utilization close to saturation. Benchmark tests show that vLLM’s throughput can reach 24 times that of HuggingFace Transformers, maintaining a generation rate of 700 tokens per second even on the Llama3-70B model. Additionally, its distributed inference supports multi-GPU tensor parallelism (such as a 4-card A100 cluster), capable of serving thousands of concurrent users.3. Balance of Low Latency and High Throughput In terms of Time to First Token (TTFT), vLLM performs optimally, maintaining low latency even in high-concurrency scenarios. For instance, with 100 concurrent users, the first token latency for Llama3-8B is below 200ms, significantly better than MLC-LLM (which sees latency spike to over 6 seconds). This advantage makes it suitable for real-time interaction scenarios (such as chatbots) while also meeting high throughput demands (such as batch text generation).4. Flexible Model and Quantization Support– Multi-Model Compatibility: Supports all FP16/BF16 models from HuggingFace and can load LoRA fine-tuning adapters for dynamic model customization.– Quantization Scalability: Although quantization tools are not directly integrated natively, INT8/INT4 quantization can be achieved through external tools like bitsandbytes, balancing performance and accuracy.– Long Context Handling: Supports 32K-128K token contexts through paging mechanisms, far exceeding Ollama’s 4K-8K limitations, making it suitable for long text tasks such as legal document analysis.5. Enterprise-Level Deployment and Ecosystem Integration– API Service: Provides an OpenAI-compatible REST API, supporting streaming responses, and can be seamlessly integrated into ecosystems like LangChain and FastChat.– Resource Isolation and Monitoring: Supports multi-model deployment, request log tracking, and permission management, adapting to enterprise privatization scenarios.– Elastic Scaling: Deployable via Docker/Kubernetes containerization, combined with dynamic resource scheduling, suitable for hybrid cloud-edge architectures.Limitations Compared to Traditional Frameworks Although vLLM excels in performance and resource efficiency, its reliance on GPU deployment (such as A10/A100 graphics cards) and complex environment configurations (CUDA/Python dependencies) make it unsuitable for edge devices or lightweight single-machine scenarios. In contrast, frameworks like Ollama are known for running on CPU/M-series chips with zero configuration but sacrifice concurrency capabilities and long context support. Therefore, vLLM is more suitable for high-concurrency, low-latency enterprise-level services, while traditional frameworks may be better suited for prototyping or edge computing scenarios.SetupSingle Node Installation (a follow-up article will cover distributed deployment solutions) It is recommended to use Anaconda for installation:
conda create --name vllm -y python=3.10
conda activate vllm
pip install --upgrade pip -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
pip install bitsandbytes -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
pip install transformers -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
pip install flash-attn --no-build-isolation -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
pip install accelerate -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
# Currently, 0.8.5 is the latest stable version; if you need to use other versions, you can update it yourself.
pip install vllm==0.8.5 -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
Model Download:
pip install modelscope -i https://mirrors.aliyun.com/pypi/simple/This will download to the current directory; if you need to use a specified directory, modify the directory address after local_dir:
modelscope download --model Qwen/Qwen3-32B --local_dir /opt/Qwen3-32BModel Deployment The current model deployment environment is (single card 3090):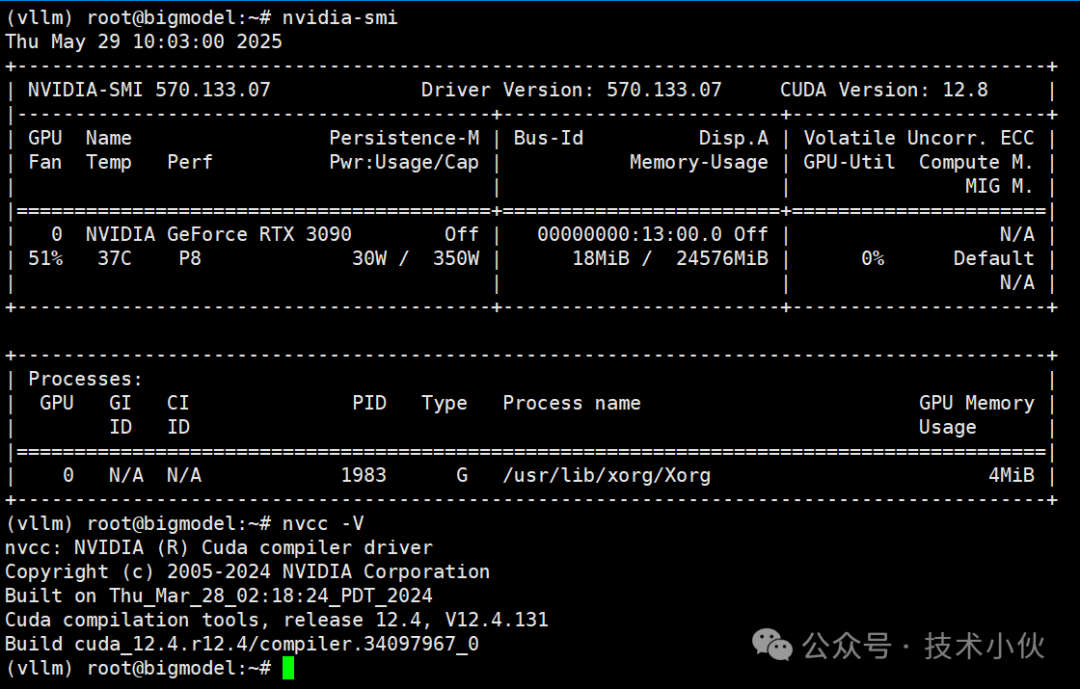 The model submission command is (you can copy it directly):
The model submission command is (you can copy it directly):
conda activate vllm
vllm serve /opt/Qwen3-32B \
--max-num-batched-tokens 1024 \
--max-model-len 3096 \
--tensor-parallel-size 1 \
--served-model-name qwen3-32B \
--max-num-seqs 5 \
--enable-chunked-prefill \
--gpu-memory-utilization 0.85 \
--enable-auto-tool-choice \
--tool-call-parser hermes \
--load_format bitsandbytes \
--quantization bitsandbytes \
--swap-space 32 \
--port 8008
Access Method:
curl http://127.0.0.1:8008/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{ "model": "qwen3-32B", "messages": [ {"role": "user", "content": "Please use 500 words to introduce what big data is"} ], "stream":false }'
Execution Efficiency: Response Effect:
Response Effect: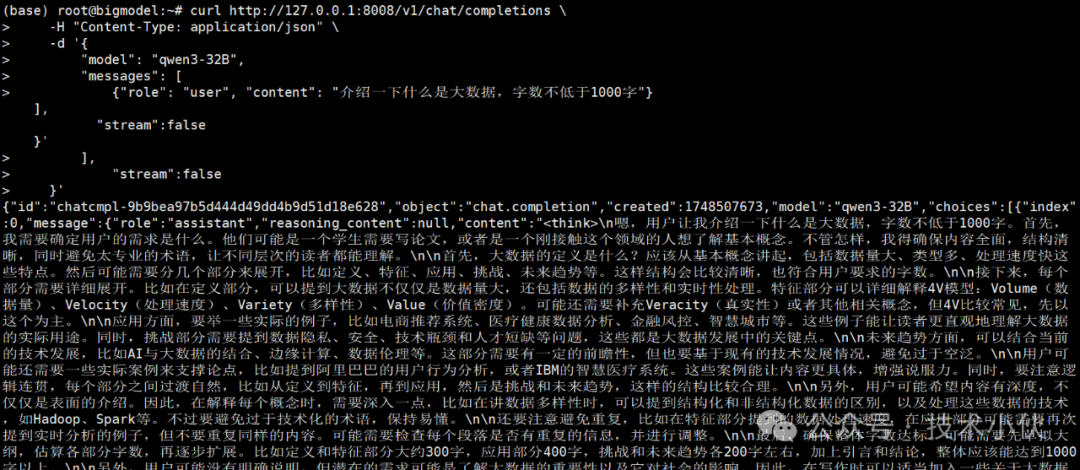
| Parameter | Description | Default Value/Example |
|---|---|---|
<span>--model</span> |
Specify the model path or Hugging Face model name | <span>/opt/Qwen3-32B</span> |
<span>--max-num-batched-tokens</span> |
Maximum number of tokens processed in each iteration, affecting throughput and latency | <span>1024</span> |
<span>--max-model-len</span> |
Maximum context length of the model (in tokens), exceeding this will be truncated | <span>3096</span> |
<span>--tensor-parallel-size</span> |
Tensor parallelism (must match the number of GPUs during multi-GPU distributed inference) | <span>1</span> (single card) |
<span>--served-model-name</span> |
Model alias used in the API | <span>qwen3-32B</span> |
<span>--max-num-seqs</span> |
Limit on the number of sequences processed in each iteration to avoid high concurrency memory overflow | <span>5</span> (default 256) |
<span>--enable-chunked-prefill</span> |
Enable chunked prefill requests to improve generation latency (TBT) under high concurrency | No default value (must be explicitly enabled) |
<span>--gpu-memory-utilization</span> |
GPU memory utilization (0-1), too high may lead to OOM | <span>0.85</span> (default 0.9) |
<span>--enable-auto-tool-choice</span> |
Enable automatic tool selection feature, allowing the model to call bound tools | No default value |
<span>--tool-call-parser</span> |
Specify the tool call parser style (e.g., Hermes compatible with Qwen series) | <span>hermes</span> |
<span>--load_format</span> |
Model weight loading format (<span>bitsandbytes</span> supports 4/8-bit quantization) |
<span>bitsandbytes</span> |
<span>--quantization</span> |
Quantization method (e.g., <span>bitsandbytes</span> to reduce memory usage) |
<span>bitsandbytes</span> |
<span>--swap-space</span> |
CPU swap space size for each GPU (GiB), alleviating memory pressure | <span>32</span> (default 4) |
<span>--port</span> |
Service listening port | <span>8008</span> (default 8000) |