Machine Heart Released
Author: Zhang Xiaofan
On June 5, 2019, the second “Low Power Object Detection System Design Challenge” hosted by the top electronic automation design conference DAC concluded in Las Vegas (Machine Heart reported on the first competition last year). This competition aimed to design high-precision and energy-efficient object detection systems for terminal devices, attracting 110 teams from well-known research institutions worldwide (including 52 teams in the GPU group and 58 teams in the FPGA group), making the competition very fierce. A team from the University of Illinois at Urbana-Champaign (UIUC) stood out, winning both the GPU and FPGA groups.

This competition inherited the essence of the last edition, including challenging hardware-software co-design tasks: participating teams needed to design high-precision algorithms to complete tasks such as small object detection, occluded object detection, and distinguishing similar targets, while also considering hardware factors such as detection speed and power consumption after deploying the algorithms on target platforms. This competition was sponsored by Nvidia, Xilinx, and DJI, with participants able to choose Nvidia TX2 GPU or Xilinx Ultra96 FPGA as the target platform, using images collected by drones provided by DJI as training data. Machine Heart invited Zhang Xiaofan, a PhD student from the dual championship-winning UIUC team, to provide an in-depth interpretation of the award-winning designs.
In this competition, UIUC’s C3SR AI research center collaborated with researchers from IBM, Inspirit IoT, Inc, and Singapore’s ADSC to form two teams (iSmart3-SkyNet and iSmart3), participating in both the GPU and FPGA competitions. In both groups, we adopted our self-designed DNN model SkyNet. Thanks to the newly designed streamlined network structure, we won championships in both events. The participants included:
-
iSmart3-SkyNet (GPU): Xiaofan Zhang*, Haoming Lu*, Jiachen Li, Cong Hao, Yuchen Fan, Yuhong Li, Sitao Huang, Bowen Cheng, Yunchao Wei, Thomas Huang, Jinjun Xiong, Honghui Shi, Wen-mei Hwu, and Deming Chen.
-
iSmart3 (FPGA): Cong Hao*, Xiaofan Zhang*, Yuhong Li, Yao Chen, Xingheng Liu, Sitao Huang, Kyle Rupnow, Jinjun Xiong, Wen-mei Hwu, and Deming Chen.
(* equal contributors)

Figure 1: The conference chair and vice-chair present the championship certificates for the Low Power Object Detection System Design Challenge to the UIUC team (from left: conference chair Robert Aitken, postdoctoral researcher Cong Hao, PhD student Zhang Xiaofan, Professor Chen Deming, C3SR AI research center director Xiong Jinjun, Professor Hu Wenmei, and conference vice-chair Li Zhuo)
Mainstream Practices?Or Taking a Different Path?
After studying the top three award-winning designs from last year’s GPU and FPGA groups, we found that they all adopted a top-down DNN design approach (Figure 2): first selecting a primitive DNN model that meets task requirements (such as the YOLO and SSD network models commonly seen in object detection competitions), and then optimizing the algorithm and hardware layers, compressing the DNN to deploy it on terminal devices with scarce hardware resources.
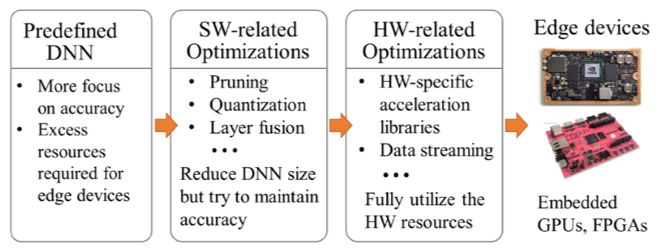
Figure 2: The widely adopted top-down DNN design process, which can optimize the network through compression and hardware-software layer optimization, deploying the DNN to resource-constrained terminal devices
We also summarized the primitive DNN models and optimization strategies used in last year’s award-winning designs (Table 1). All GPU award-winning teams selected YOLO as their original network model, and their final results were very close (detection accuracy IoU close to 0.7, with a throughput of about 25 FPS on the TX2 GPU). In the FPGA category, due to the more limited hardware resources, the compression strategies adopted by the participating teams were more aggressive, with a lot of network pruning and ultra-low bit quantization schemes (such as BNN), but in terms of both IoU and FPS performance metrics, they still lagged behind the GPU designs of the same year.
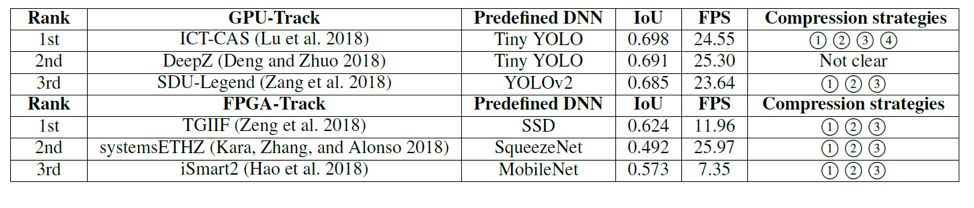
Table 1: Analysis of the top three design schemes in the 2018 Low Power Object Detection System Design Challenge.All designs adopted a top-down DNN design method, selecting existing networks (predefined DNN) for model compression (Compression) to fit the target hardware platform.These designs employed methods such as 1 input resizing, 2 network pruning, 3 low-precision data quantization, and 4 TensorRT.
We attempted to further improve detection accuracy and throughput, such as breaking 0.7 IoU on the same GPU or significantly increasing FPS. Given that YOLO had been used by multiple teams, we selected another popular detection network SSD as the original network and used VGG16 and MobileNet as backbone networks for object detection. Unfortunately, these two versions of the SSD network could only achieve IoUs of 0.70 and 0.66, with throughput on desktop GPUs (1080Ti) reaching only 15 and 24 FPS. To continue using the top-down DNN design scheme, we needed to do a lot of network compression and optimization work to have a chance to deploy the design on the TX2 GPU or Ultra96 FPGA. At this point, we found that when using the top-down design approach, we would inevitably encounter two difficulties that severely hindered the deployment of high-precision, high-throughput DNNs on terminal devices. These two difficulties include:
-
Different DNN compression schemes can enhance the hardware performance during DNN deployment, but while improving performance, they can easily cause significant differences in inference accuracy.
-
It is difficult to simply determine the inference accuracy range based on the original DNN for known tasks.
Regarding the first point, the fundamental reason is that different DNN parameter settings have different sensitivities to inference accuracy and hardware performance after deployment. Several examples we mentioned in this year’s ICML workshop paper reflect this issue (see Figure 3) [1]. The first example, as shown in the left part of Figure 3, we quantified and compressed the weight parameters and feature maps of AlexNet and plotted the trend of decreasing network inference accuracy. In this example, the original uncompressed network used 32-bit floating-point representation (Float32); while the compressed network was identified by a 5-digit number (such as 8-8218), corresponding to the quantization bit widths used for different network layers: the first digit represents the quantization bit width for feature maps, the second and third digits represent the quantization bit widths for the first convolution layer and the remaining convolution layers’ weight parameters, while the last two digits represent the quantization bit widths for the first two fully connected layers and the last fully connected layer’s weight parameters. Although similar network compression ratios were adopted, compressing feature maps leads to more inference accuracy loss than compressing weight parameters. The second example, as shown in the right part of Figure 3: introducing a slight change in DNN design that does not affect inference accuracy (such as changing the input scale factor from 0.9 to 0.88) can save a lot of hardware resources, thus resulting in considerable hardware performance improvement. The above examples illustrate that different parameter settings of DNNs have different sensitivities to inference accuracy and hardware performance after deployment. To avoid design difficulties caused by different sensitivities, we must first deeply understand the potential impacts of different DNN configurations at both software and hardware levels when using the top-down DNN design scheme.
The second point causing trouble when using the top-down scheme is: it is difficult for us to select the so-called “most suitable” original DNN for a specific application and infer the inference accuracy range after compression, optimization, and deployment. To find a suitable original DNN, network designers inevitably have to conduct extensive research and evaluate various DNNs on the target dataset. Moreover, the originally best-performing DNN may not guarantee a higher inference accuracy after multiple compressions than networks compressed from other DNNs.
Given the difficulties mentioned above, we believe that DNNs designed through the top-down approach will find it challenging to significantly outperform last year’s award-winning models when deployed on the same hardware platform. Therefore, we decided to take a different path and explore a new DNN design scheme.
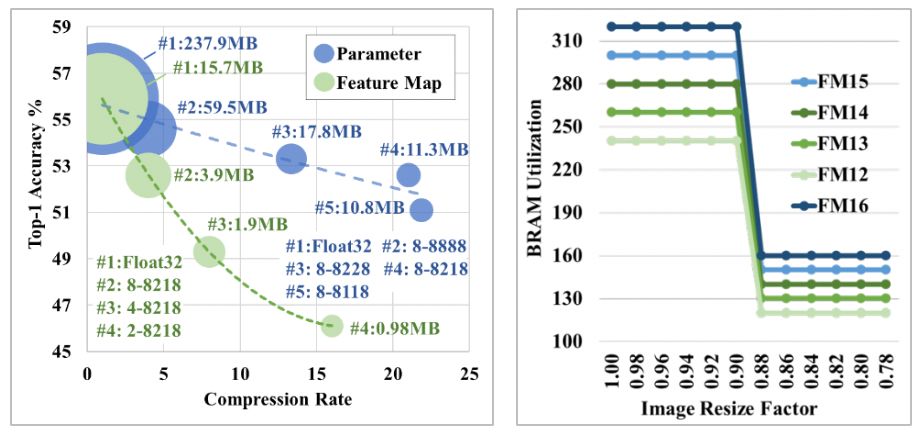
Figure 3: Left: Quantizing the weight parameters (parameter) and feature maps (feature map) of AlexNet with different bit widths can cause huge differences in inference accuracy with similar compression ratios (the compressed network models are fully trained on ImageNet); Right: The corresponding on-chip memory resource overhead when quantizing the feature maps of a specified DNN using 12~16 bit widths and scaling inputs. When deploying this DNN to FPGA, reducing the scaling factor from 0.90 to 0.88 can significantly save hardware resources, but the network inference accuracy remains almost unchanged [1].
New Ideas:Bottom-Up DNN Design Scheme
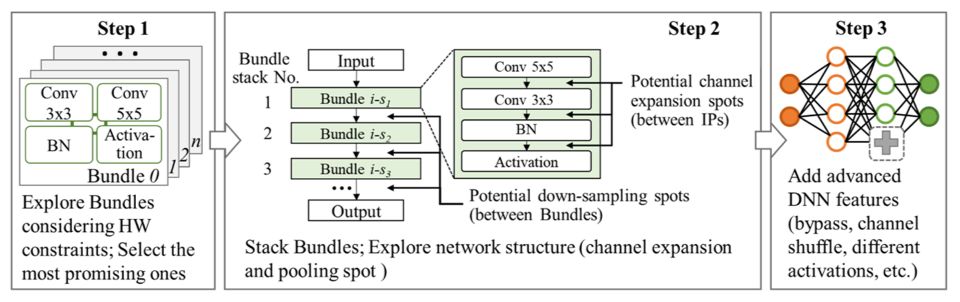
Figure 4: We proposed a bottom-up DNN design scheme and used this scheme to design the competition model SkyNet.This scheme does not rely on any original DNN and can generate the target DNN in just three steps: 1) Select Bundle, 2) Search Network Structure, 3) Manually Add Network Features.
Ultimately, we adopted a bottom-up DNN design scheme, aiming to generate a DNN model that fully understands hardware resource limitations and can be efficiently deployed on terminal devices (Figure 4). The first step of this method is to generate and select the most suitable DNN basic building blocks, “Bundle.” By enumerating commonly used modules in DNN (such as different convolution layers, pooling layers, and activation functions), we combine them into multiple Bundles with different characteristics (such as different computation delays, hardware resource overheads, and inference accuracy characteristics). Subsequently, we evaluate the hardware performance of each Bundle based on known hardware resources, filtering out those that require excessive hardware resources. To obtain inference accuracy information for Bundles on the target dataset, we stack each Bundle, build its corresponding simple DNN, and conduct short-term training on the target dataset. The Bundles that meet hardware performance standards and exhibit the best accuracy will be selected and output to the next step of network structure search.
In the second step of the bottom-up design scheme, we perform network structure search to generate a DNN that meets latency targets, has reasonable resource consumption, and high inference accuracy. Since the first step has already conducted part of the search task (Bundle filtering), the second step’s search task will not be overly complex. To further accelerate the network structure search process, we narrowed the design space of the generated network, retaining only three design variables: the number of stacked Bundles, the number of down-sampling times, and the insertion positions and channel expansion factors. A smaller design space facilitates faster convergence of the search algorithm and can generate more organized DNN structures. Such organized DNNs are also easier to deploy and operate efficiently on terminal devices with scarce hardware resources. In the final step of the scheme, we add additional features to the generated DNN to better adapt to the target task. More detailed introductions to the bottom-up design scheme and network structure search algorithms can be found in papers [2] and [3].
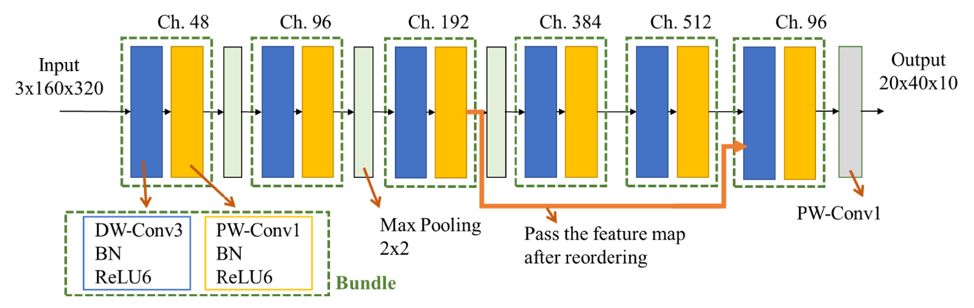
Figure 5: SkyNet Network Structure
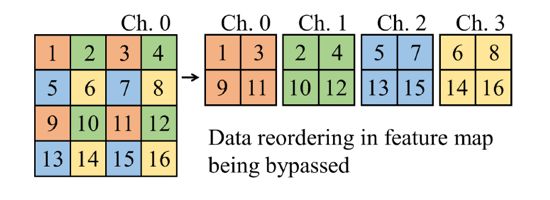
Figure 6: Feature Map Rearrangement Scheme
Lightweight Detection Network SkyNet
According to the bottom-up design scheme, we designed SkyNet as the competition model (Figure 5). During the design process, the selected Bundles included four main elements: DW-CONV3x3, CONV1x1, BN, and ReLU6. After stacking Bundles and generating the initial DNN using the network search algorithm, we made slight modifications to the initial network, adding a bypass (bypass, the orange line in Figure 5) for transmitting feature maps. The reason for setting the bypass is that we found that 91% of the tested objects had a ratio of less than 9% compared to the input image size, and 31% of the tested objects had a ratio of less than 1% (as shown in the examples in Figure 7) [2]. In other words, this competition task belongs to small object detection tasks. Therefore, we added a bypass for transmitting shallow feature maps to deep convolutions (directly inputting the output of the third Bundle into the last Bundle), reducing the chances of losing small object features after passing through the pooling layer. Since the bypass crosses the pooling layer, the feature maps transmitted through the bypass do not match the original input feature map size. We used feature map rearrangement (reordering, Figure 6) to solve this problem: rearranging the feature maps transmitted through the bypass to reduce their width and height while increasing the number of channels, and mixing features from different channels. Compared to using pooling layers, the advantage of rearrangement is that it can match the bypass and the original input feature map size without losing feature data.

Figure 7: Instances of small objects that need to be detected in the competition
SkyNet Terminal Deployment Results
In this competition, both our GPU (iSmart3-SkyNet) and FPGA (iSmart3) designs used SkyNet as the backbone network and employed a streamlined YOLO backend (removing object classification output, retaining only 2 anchors) for bounding box regression calculations. In terms of data type selection, thanks to the streamlined network design, we did not need further optimization for GPU deployment and directly used 32-bit floating-point data for network inference. In FPGA, we used 9-bit and 11-bit fixed-point data types to represent feature maps and network weight parameters. More details about the FPGA deployment design can be found in our paper presented at DAC 2019 [3]. According to the committee’s tests, the object detection accuracy (IoU) of our design was 0.731 (GPU) and 0.716 (FPGA), with throughput of 67.33 FPS (GPU) and 25.05 FPS (FPGA).
In comparison, we summarized the results of the last two competitions and listed the inference accuracy and throughput of the top three designs in the GPU and FPGA categories in Figure 8. Under the premise of using the same hardware device (TX2 GPU), the design submitted by iSmart3-SkyNet achieved a significant throughput improvement compared to other GPU participating teams (2.3 times higher than the second place). We also surpassed other competitors in accuracy and overall score. In the FPGA category, due to the hardware platform change (from Pynq-Z1 to the more resource-rich Ultra96), award-winning designs achieved better inference accuracy and throughput than previous years. The FPGA design submitted by iSmart3 significantly exceeded the second-place design in the FPGA group in terms of accuracy (improving by 10.5% IoU), and also achieved real-time processing requirements in throughput. It is worth mentioning that our design deployed on Ultra96 FPGA (with peak computational performance less than a quarter of the TX2 GPU) still achieved accuracy and throughput very close to the runner-up and third-place designs in this year’s GPU group. More detailed comparisons can be found in Tables 2 and 3.
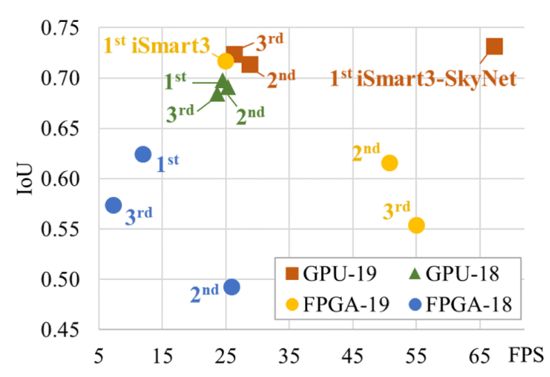
Figure 8: Comparison of results from the last two DAC Low Power Object Detection System Design Challenges (IoU vs. FPS)
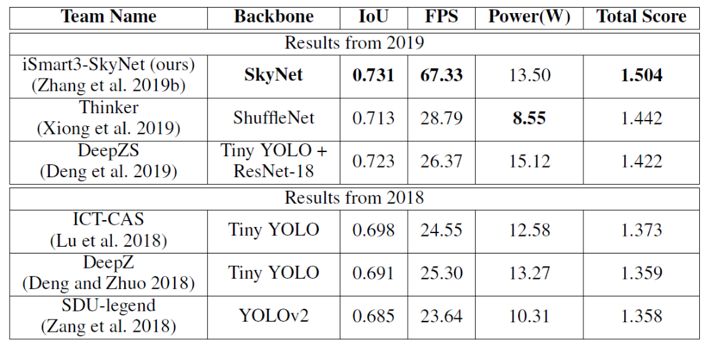
Table 2: Comparison of the top three designs in the last two GPU competitions and their deployment performance on TX2
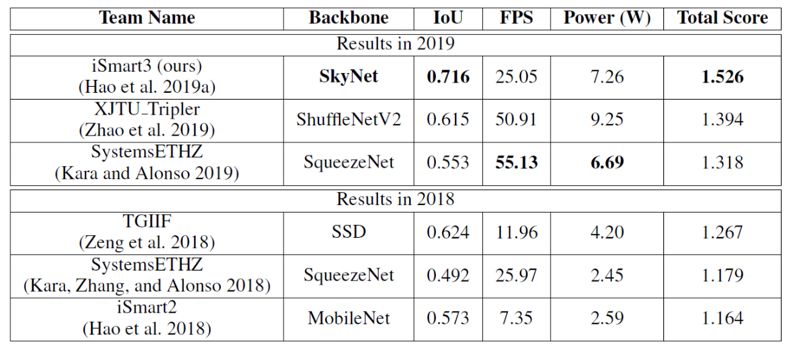
Table 3: Comparison of the top three designs in the last two FPGA competitions and their deployment performance on Pynq-Z1 (2018) and Ultra96 (2019)
Relevant Papers Organized
To participate in this competition, we prepared three papers, detailing the motivation for the bottom-up DNN design method [1], the design ideas of SkyNet [2], and the FPGA/DNN co-design strategy for terminal devices [3]. Among them, paper [1] won the best poster award at this year’s ICML ODML-CDNNR workshop, and paper [3] was fully included in the IEEE/ACM Design Automation Conference and reported by Machine Heart [4].
[1] Xiaofan Zhang, Cong Hao, Yuhong Li, Yao Chen, Jinjun Xiong, Wen-mei Hwu, Deming Chen. A Bi-Directional Co-Design Approach to Enable Deep Learning on IoT Devices, ICML Workshop on ODML-CDNNR, Long Beach, CA, June 2019.
https://arxiv.org/abs/1905.08369
[2] Xiaofan Zhang, Yuhong Li, Cong Hao, Kyle Rupnow, Jinjun Xiong, Wen-mei Hwu, Deming Chen. SkyNet: A Champion Model for DAC-SDC on Low Power Object Detection, arXiv preprint: 1906.10327, June. 2019.
https://arxiv.org/abs/1906.10327
[3] Cong Hao*, Xiaofan Zhang*, Yuhong Li, Sitao Huang, Jinjun Xiong, Kyle Rupnow, Wen-mei Hwu, Deming Chen, FPGA/DNN Co-Design: An Efficient Design Methodology for IoT Intelligence on the Edge, IEEE/ACM Design Automation Conference (DAC), Las Vegas, NV, June 2019. (*equal contributors)
https://arxiv.org/abs/1904.04421
[4] “UIUC Joins IBM and Inspirit IoT to Launch the Latest DNN/FPGA Co-Design Solution to Support AI Applications for IoT Terminal Devices” Machine Heart.
For more related information, please visit the author’s personal homepage: https://zhangxf218.wixsite.com/mysite
Previously, we reported on the design scheme of the runner-up team, see: Xi’an Jiaotong University won the DAC19 system design competition FPGA track runner-up, here is their design scheme 
This article is published by Machine Heart, please contact this public account for authorization.
✄————————————————
Join Machine Heart (Full-time reporters / Interns): [email protected]
Submissions or seeking coverage: content@jiqizhixin.com
Advertising & Business Cooperation: [email protected]