
Produced by | Zhixitong Open Course
Lecturer | Wang Haitao Co-founder of OPEN AI LAB and Chief Architect of Tengine
Reminder | Click the blue text above to follow us, and reply with the keyword “AI Framework” to obtain the courseware.
Introduction:
On the evening of April 8, Zhixitong Open Course launched a special session on the embedded AI framework OPEN AI LAB, hosted by Wang Haitao, co-founder of OPEN AI LAB and chief architect of Tengine, with the theme “Tengine – Challenges and Practices of Embedded AI Framework”.
In this special session, Mr. Wang analyzed the challenges faced by embedded AI and Tengine’s solutions, providing a comprehensive breakdown of Tengine’s architecture and the components of its inference API. Finally, Mr. Wang will guide you through customizing personalized operators using Tengine and performing inference on CPU/GPU/NPU/DLA.
This article is a compilation of the visual and textual content from the main presentation of this special session.
Hello everyone, I am Wang Haitao. Today, I will share with you the topic “Tengine – Challenges and Practices of Embedded AI Framework”, which is divided into the following parts:
1. Challenges faced by embedded AI and Tengine’s solutions
2. Analysis of Tengine architecture
3. Introduction to Tengine API
4. Practice 1: Extending, customizing, and adding operators in Tengine
5. Practice 2: Inference of Tengine on CPU/GPU/NPU/DLA
Tengine is an embedded AI computing framework and a core product of our company. It has made significant advancements at the computational power level by establishing deep partnerships with numerous domestic chip manufacturers and employing various technical solutions to fully leverage hardware computational performance. Hence, we are committed to building an AI computational ecosystem platform, hoping that Tengine will facilitate easy access to the underlying chip’s computational power. Additionally, it will provide a series of products and toolkits to address various issues that arise when algorithms are deployed on the edge, offering a standard and rapid approach to solve these problems and accelerate the entire AI industry’s deployment. This is one of our goals; therefore, in the future, Tengine will evolve into a development and deployment platform for AIoT, rather than just an inference framework.
Challenges Faced by Embedded AI and Tengine’s Solutions

Currently, what issues exist in embedded AI? Firstly, we can observe that AI’s penetration into daily life is becoming increasingly profound; it can be said that AI, like electricity, will be everywhere. This trend is primarily driven by two factors: first, the enhancement of edge computing power, namely the evolution of CPUs and the emergence of various NPUs; second, the advancement of algorithms themselves. We can see that from the early VGG to Inception v1, v2, v3, to EfficientNet, the algorithms are continuously being lightweighted, allowing AI applications that previously could only run on servers to now operate on the edge. Another issue is the growing concern over data security and privacy, leading to an increasing number of people wishing for AI computations to occur locally, avoiding cloud-based processing as much as possible. For edge AI, 2016 marked the beginning, and it remains in a rapid explosion phase to this day.
The above mainly describes the application demands at the frontend. What is the situation in the industrial chain? Currently, the industrial situation is very unfriendly. The first manifestation is the diversity of hardware; the AIoT market inherently possesses diverse hardware, and the emergence of various AI-accelerating IPs exacerbates this diversity. Moreover, with the further application of AI, hardware that was previously deemed unlikely to run AI, such as MCUs, can now also execute some AI algorithms, resulting in increasing hardware platform diversity.
The second manifestation is the diversity of software. There are many training frameworks, and the models trained by these frameworks are currently in a flourishing state when deployed on embedded platforms. There are various frameworks, some are native while others are developed by third parties. Therefore, for application developers, the process of deploying an algorithm onto a platform is still very lengthy.
Above is the situation for application developers; for algorithm developers, this is also a serious problem. A trained model must be deployed onto a computationally limited embedded platform, which may require adjustments to the model, reducing its scale, and performing quantization along with many other tasks before it can be effectively deployed. If one wishes to utilize the acceleration chips on the embedded platform, certain adjustments must also be made for the chip, as some operators may not be supported and need to be replaced, or there may be discrepancies in definitions. Thus, the entire ecosystem is very unfriendly.
In this diverse environment, we can see that the efficiency of the entire AI industrial chain is very low. For chip companies, they excel at enhancing computational power but find that if they only produce chips and simple drivers, many AI developers are unable to utilize them. Therefore, they need to invest a significant amount of resources into developing upper-level development platforms and environments. For instance, Huawei in China has developed an entire industrial chain from chips to ID environments to deployment environments.
Algorithm and application companies have also discovered that if they do not complete the adaptation to the underlying hardware, a model that performs very well during training may either have very slow performance or very poor accuracy once deployed onto the platform. Therefore, they need to personally adapt and optimize the model for it to be effectively applied and deployed. We believe that the division of labor across the entire industrial chain is very unclear and inefficient, which is also an issue we are attempting to improve and solve.
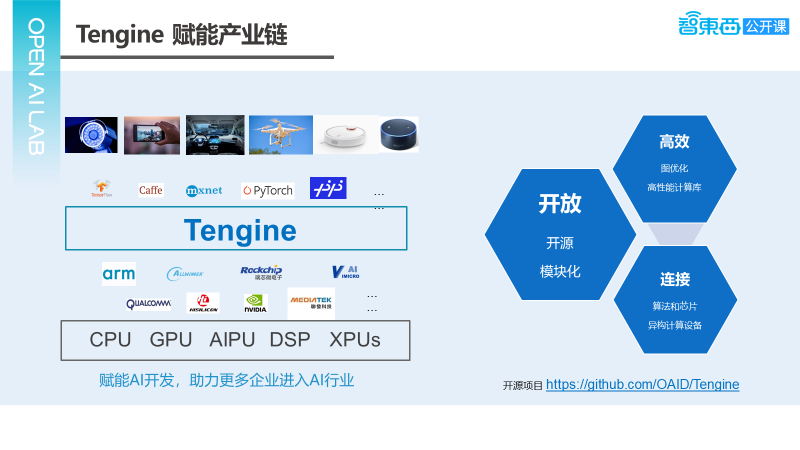
How does Tengine empower the industrial chain? First, it connects algorithms and chips, regardless of which framework the model is trained with, Tengine can accept it and call the underlying computational platform, ensuring that it runs very well on the underlying computational platform. Second, it provides some toolkits and standard processes to assist in effectively migrating models to SOC platforms. Tengine aims to achieve this from three directions:
1) Openness, which focuses on two points. First is open-source, as we hope more people will use Tengine, thus we adopt an open-source approach. Second is modularity, as the entire AI software and hardware are still rapidly developing, we need to provide a good way to support newly emerging algorithms, models, and hardware, thus building the entire software in a modular manner.
2) Efficiency, since computational power is always a bottleneck on SOC platforms, optimizing algorithms to run quickly and effectively on the platform is essential. We focus on two levels of optimization: first, optimizing at the graph level; second, implementing high-performance computing libraries that are entirely self-owned intellectual property.
3) Connectivity, first connecting algorithms and chips, minimizing the intermediate docking costs regardless of whether algorithms or chips change. Next, we need to consider supporting multiple computing devices, enabling the scheduling and utilization of multiple devices to be interconnected. These are the three tasks Tengine performs as an inference framework to empower the industry.
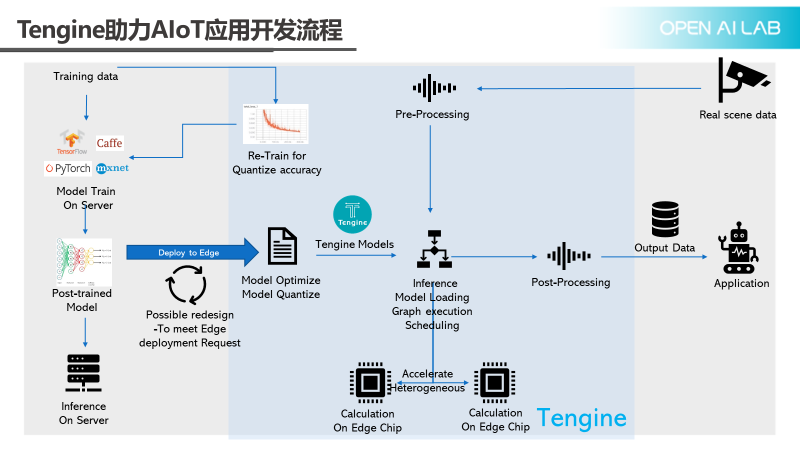
How does Tengine assist in AIoT application development? The above figure illustrates a standard process for algorithm deployment. The far left shows algorithm training, followed by providing a standard workflow from the inference server. When deployment on SoC is required, the first step is to optimize the model, followed by quantizing the model. At this point, there may be a decline in accuracy and speed, necessitating some modifications to the original model, which may involve several iterations. Once completed, it can be placed onto a specific inference engine and executed on the chip.
The above description pertains only to the algorithm model portion. A true AI application also includes data recording and result output. The figure also highlights preprocessing and post-processing steps; whether data comes from a camera or a sensor, it requires preprocessing before being sent to the inference engine, and the results from the inference engine also require post-processing before being handed over to the application for further analysis and processing. During the quantization process, there may be some loss of accuracy, which needs to be avoided in scenarios with high accuracy requirements, such as facial recognition or payment scenarios; thus, retraining for quantization is necessary.
To accelerate the deployment process of AIoT, Tengine works on the aspects highlighted in the blue box in the above figure. For common mainstream training frameworks, we provide a quantization retraining toolkit, and we also offer dedicated algorithm libraries for preprocessing and post-processing to expedite these processes.
Analysis of Tengine Architecture
Next, we will provide a brief introduction to the inference engine section of Tengine. It is mainly divided into the following parts: first, a simple introduction to the overall architecture; then, an overview of the support for training frameworks, as this part is crucial for deployment; lastly, the execution of computational graphs, high-performance computing libraries, and supporting tools.

– Tengine Product Architecture
The Tengine product architecture is illustrated in the above figure. At the top are the API interfaces, which we have studied thoroughly since we believe that constructing a Tengine AI application ecosystem relies heavily on the stability of the API, ensuring that the entire ecosystem can develop sustainably.
Below is the model conversion layer, which can convert various mainstream training framework models into Tengine models for execution on the edge. We also provide some supporting tools, including graph compilation, compression, tuning, and simulation tools, along with commonly used algorithm libraries for preprocessing, post-processing, and algorithms tailored for specific domains.
Next, we have the execution layer, which includes graph execution, NNIR, where NNIR serves as a representation of Tengine’s graph, incorporating memory optimization, scheduling, and encryption. Below that is the operating system adaptation; Tengine currently supports RTOS and Bare-Metal scenarios, all aimed at supporting particularly low-end CPUs. In the heterogeneous computing layer, we can now support CPUs, GPUs, MCUs, NPUs, etc., and will also introduce usage on GPUs and DLAs today.
– Training Framework and OS Adaptation
Currently, we support training frameworks such as TensorFlow, PyTorch, and MXNet; for mainstream operating systems, we can generally support a series of Linux distributions, and RTOS is also supported. In the future, we will add support for iOS and Windows.
– Model Conversion Solutions
The model conversion solution essentially converts models from other frameworks into Tengine models. We have two methods for model conversion: the first is to use the conversion tool provided by Tengine for automatic conversion; the second requires users to write some code, essentially using Python scripts to extract all parameters and data from the original model, and then constructing a Tengine NNIR graph via the Tengine interface before saving it as a Tengine model. Thus, our model conversion solution differs from others. The first step is to parse all models into Tengine’s NNIR format, and the second step is to save it as a Tengine model. Theoretically, Tengine NNIR can also be executed directly without issues. This method allows for additional functionalities, such as saving Tengine NNIR as a Caffe model, effectively making Tengine a tool for model conversion between different frameworks. Creating a good model conversion tool is quite challenging; we encountered numerous compatibility issues between frameworks while defining Tengine NNIR, and while various conversion tools exist on the market, they all come with their own pitfalls.
– Tengine Model Visualization Tool
After converting the Tengine model, it is essential to verify whether the conversion results meet expectations. We have collaborated with the open-source community’s model visualization tool, Netron, to implement support for Tengine models. If you download the latest version of Netron, it will have excellent support for Tengine.

As illustrated in the above example, it shows the initial layers of SqueezeNet. The attributes of the first Convolution layer are shown on the right; its input is data, and it has a filter and a bias. It can be seen that Tengine optimizes the graph, so the attributes include an additional activation. An activation of 0 indicates a ReLU activation, effectively merging Convolution and ReLU together. This tool is excellent for displaying the results of the model transformation process after Tengine’s model conversion, and it is a very useful tool.
– Computational Graph Execution
For executing computational graphs, as mentioned earlier, all models, whether from other frameworks or Tengine models, will be converted into Tengine NNIR, which needs to mask the differences between various frameworks and ensure compatibility. Once we obtain Tengine NNIR, we must determine which device will execute these nodes. If the system has only one device, the problem is relatively easy to solve. However, when the system has multiple computing devices, complications arise. The first issue is that the characteristics of the two computing devices may differ; for instance, one may have higher performance but lack support for certain operators, while another may have lower performance but better support for operators. What strategy should be employed? Should we distribute the workload across multiple devices or concentrate it on one? This is the static case; the dynamic case is even more complex.
Assuming device A appears idle, but when I prepare to assign a task to it, it may become very busy. Thus far, there has not been a particularly good solution. Here, we are closer to the OpenVX scheme, where all computing devices need to prioritize based on your requirements. After obtaining a computational graph, the graph queries the underlying devices to see if they can support this node. If one device responds, that node will not be allocated to other devices. Our solution is similar; however, we allow the computational graph to be viewed by all computing devices instead of stopping at one.
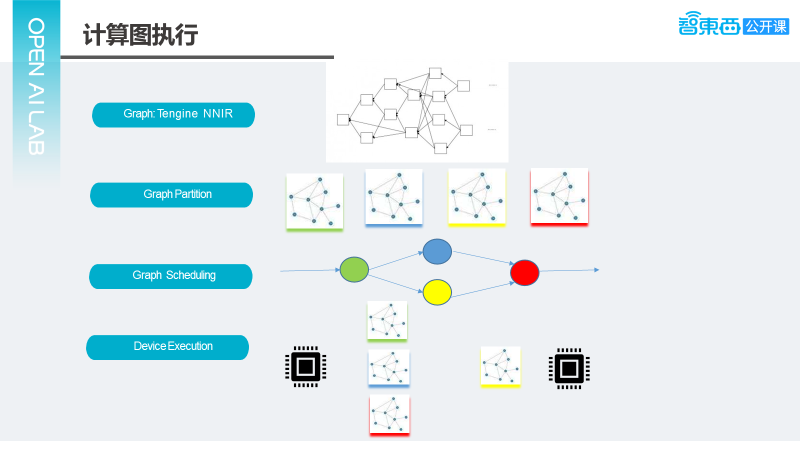
Through this approach, we can determine which node of the graph will be executed on which device. Once established, the graph can be partitioned into different segments based on device allocation. The diagram above illustrates an example where the graph is divided into four segments; these segments will have certain dependencies, with some segments able to execute in parallel while others cannot. Assuming the yellow and blue segments can execute in parallel, they form an execution graph, which is then scheduled to each device for execution. As illustrated, the yellow and blue computational graphs can run simultaneously on two devices; this is roughly the entire computational process.
– Maximizing Hardware Performance in Computation
When running on devices, it is essential to maximize computational power. We have conducted extensive optimizations on the computing library, focusing primarily on the most time-consuming operators within the entire neural network, including convolution, fully connected layers, and pooling. Depending on the parameters, we have implemented various computational modes for convolution, such as GEMM-based, Direct, and Winograd. Generally, our library can achieve a two-way speedup of 175% and a four-thread speedup of 300%, with even better performance for some networks, reaching nearly 400% for four threads.
For optimization, we specifically targeted the microarchitecture of CPUs. In a complete network operation, we can achieve a convolution MAC utilization of up to 70%, effectively utilizing the hardware’s performance, and we have made excellent adaptations for the entire series of Arm products.
The computing library not only provides excellent support for FP32 but also optimizes INT8, allowing us to fully exploit the hardware’s computational power. It can be observed that INT8 can speed up computations by 50-90% compared to FP32. However, it should be noted that INT8 may introduce some accuracy loss; thus, the computing library also supports mixed-precision computation modes, where layers with significant accuracy loss can utilize FP32, while others can use INT8. This approach allows for a balance between accuracy and speed. The performance of the open-source version of FP32 is quite impressive, with SqueezeNet taking less than 60 milliseconds.
– Quantization Retraining Tool
As previously mentioned, INT8 is now essentially a requirement for edge inference. However, the issue of INT8’s accuracy has long troubled many. Looking at the current mainstream training frameworks, aside from TensorFlow having TensorFlow.Net, other frameworks currently lack a comprehensive quantization retraining solution. To address this issue, we have developed a quantization retraining tool and made improvements specifically for NPU, as NPU chip manufacturers are not particularly familiar with training. Thus, we hope to assist them in improving quantization accuracy when running on NPU, enabling more applications to run on NPU.

The image on the right illustrates the results of quantization retraining, demonstrating very positive outcomes. Notably, for MxNet_MobileNet, the accuracy can increase by two percentage points after retraining.
In addition to the entire suite of tools and quantization retraining offered by Tengine, significant work has also been done in preprocessing and post-processing. In fact, there is a module called HCL.Vision, which is a computing library designed for CV applications. This library differs from other CV computing libraries in that if there is some image processing acceleration available on the hardware platform, it will call the underlying hardware platform interface for processing; if not, we will provide an optimized CPU implementation, offering a unified interface for ease of application development. With the interface remaining unchanged, hardware acceleration can be achieved on a platform with hardware acceleration.
Introduction to Tengine API
Next, we will enter the section on Tengine API, first introducing our thoughts on API design, followed by some applications of the current API.
– Overview
When we first developed Tengine, we placed significant importance on the API, while also learning from and referencing some excellent software solutions and frameworks in the industry. We primarily referenced the design principles and ideas of Android NN, OpenVX, TensorRT, TensorFlow, and MXNet interfaces, ultimately leaning towards OpenVX.
We have two principles: the first is that the definition and implementation of interfaces are completely unrelated. This consideration is based on the rapid development of AI software and hardware. If interface definitions bind certain implementations, it will create a significant burden when refactoring code or supporting new features, so we completely separate interface definitions from implementations.
The second principle emphasizes the stability and flexibility of interfaces. Stability is crucial for all APIs. Why is flexibility particularly emphasized? Similar to the above, we cannot predict the future, so we aim to reserve some interfaces to support future functionalities and provide applications with more control over the underlying layers, which will be more conducive to the stability and long-term development of the Tengine application ecosystem.
Concerning hardware, we have always considered how to better support Tengine. Running trained models on the edge is an observable trend; thus, the interface must support model training. Essentially, Tengine connects algorithms and chips, providing a standard interface to offer the chip’s computational power to applications. This is also valuable for us to implement and train solutions. Finally, let’s look at the results. We use C as the core API, then wrap some more user-friendly APIs based on C, such as C++ API or Python API, both of which have been implemented, with plans for JS API and Java API in the pipeline, all based on the C API. This outlines our entire API system.

– Multi-chip and Software Backend Support
As we enter the AIoT market, we recognize that there will certainly be a variety of AI acceleration chips and AI IPs emerging in the future. The goal is to minimize the workload when migrating applications across different chips or AI acceleration IPs. Our solution allows applications to call various computational powers through a single interface. As shown on the far left, inference usage can be implemented on an RK3288 or Raspberry Pi Linux by invoking the Tengine model; the first line on the right represents an MCU platform that may only require a different model, switching to a tiny model instead of a Tengine model. If it is an NPU, only the intermediate model format needs to be changed, with little to no modifications required elsewhere. This greatly reduces both the maintenance of applications and the learning curve for developers.
Based on our API, developers will find that it significantly reduces complexity. For example, an application that needs to run on both Android and Linux can call the Tengine interface and effectively utilize the underlying hardware’s computational power. On Android, this may be more complex due to Google’s introduction of the Android NN API, which did not exist previously. If an application wants to call this interface but is not on the Android NN platform, what can be done?
In practice, we can implement a middle solution by still calling the Android NN API while re-implementing the Android NN Runtime to let Tengine access the underlying computational power, ensuring that your application does not need to worry about switching interfaces across different platforms. The scenarios above illustrate the maximum value for chip companies, as they only need to adapt Tengine to provide computational capabilities effectively for various scenarios.
– C++ API and Python API
Next, we will introduce the C++ API and Python API, which are designed for quick and simple usage, stripping away many functions from the C API. A typical usage example involves four steps: first, loading the model; second, setting the input data; third, running the model; and fourth, retrieving an interface. The entire process is straightforward and easy to understand, with almost no learning costs.
The Python API is similar to the C++ API, allowing for similar functionalities within a Python structure, and will not be elaborated further.

The C API is relatively more complex, divided into several major categories. The first category includes Tengine’s initialization and destruction, followed by concepts corresponding to Tengine’s entire NNIR, which include Graph, Node, and Tensor concepts. This part is more akin to TensorFlow. For Graph, it includes creating the Graph and creating Nodes, allowing for the creation of a graph through the Tengine interface, which is also a consideration for supporting model conversion and training functionalities. Next are the execution interfaces for graphs, including Prerun and Postrun, along with various miscellaneous interfaces, such as setting log redirection and binding execution devices to graphs and nodes. More details can be found in the links below, with each API being well-commented and relatively clear.
Next, we will introduce the typical process of performing inference using the C API, which is similar to what was discussed earlier. The only additional step is to actively call a prerun interface, which binds the computational graph to a device and allocates the necessary resources for computation on the device. Next, we set the tensor buffer and then run the model.
– Creating Graphs and Nodes with C API
First, we create an empty graph, which represents nothing and does not originate from any framework. Next, we need to create an input node, which requires creating two elements: the Node and the Tensor, setting the Tensor as the output Tensor of the node. This approach aligns closely with TensorFlow’s method. Next, we create a Convolution node, similar to the input node, where we first create a node and specify that the operation of this node is a Convolution. Following that, we need to create the output Tensor of this node. We then set the input tensors, such as 0, 1, and 2, which correspond to input_tensor, w_tensor, and b_tensor, forming the components of this node. Convolution has many parameters, such as kernel size, stride, and padding settings. We provide an interface to set the properties of the node directly through the program.
Practice 1: Extending, Customizing, and Adding Operators in Tengine
Having introduced the interface, we will now demonstrate how to extend and customize operators with specific code examples.
– Custom Kernel for Tengine Operators
If Tengine already implements an operator but differs from the current implementation framework, or you desire a better implementation, or if your platform has hardware that can accelerate the operator, and you prefer not to use the existing implementation, there are two ways to address this. The first is to replace it using the custom kernel interface in the C API, specifying which node to apply this replacement to. This method may have a lower learning curve as it does not require understanding the entire process of adding a new operator to Tengine; it only requires performing the computation.
The second option is to implement a Plugin, which allows for an external module to redefine the operator. When registering, you can elevate the priority of the implementation. Once completed, all implementations of this type of operator will utilize your custom operator.
Next, we will introduce how to replace using the Tengine C API, while the Plugin method will be illustrated in a subsequent example.

The Tengine C API includes a custom kernel interface, which is crucially defined by custom_kernel_ops, detailing the contents that the custom kernel needs to implement. Its data structure is illustrated in the above image. The first is the operation (op), indicating whether to perform a convolution or pooling. Following that are two parameters: kernel_param and kernel_param_size, which are for our own use. The three critical functions are prerun, run, and postrun, where the first parameter is the ops itself, followed by the input_tensor and output_tensor. Other parameters can be found in the kernel_param.
Once this is set up, we can call set_custom_kernel to replace the implementation on the device. Now, let’s take a look at the code.
– Adding New Operators in Tengine
Adding new operators is also crucial for inference frameworks, especially regarding TensorFlow, where operators are numerous and complex. When encountering unsupported operators, we recommend first implementing them using the plugin mode outside the Tengine repository. Once stable, you can submit a PR to merge it into the repository.
Taking TensorFlow’s new operator Ceil as an example, there are several steps involved: first, register a new operator definition in Tengine NNIR; second, register the operator’s model loading in Tengine’s TensorFlow Serializer; lastly, implement the operator in Tengine Executor, as illustrated in the following code.
Practice 2: Inference of Tengine on CPU/GPU/NPU/DLA
Next, we will explore how to perform inference, using MobilenetSSD as an example with three scenarios: first, running solely on CPU; second, a combination of CPU and GPU; and third, a multi-device scenario, exemplified by MSSD. Initially, we will examine the operation on CPU and GPU, and then see how to utilize NPU or DLA.
As demonstrated above, invoking NPU is quite straightforward, significantly enhancing learning costs and application development speed.
Obtain Courseware👇👇
Reply “AI Framework” in the background of this public account 【Zhixitong】 to access the complete presentation of this session.
END
Live Broadcast Preview
On June 12 at 7 PM, the Aishu Wisdom Special Session will officially commence! Chief Data Scientist of Aishu Wisdom, Jia Yanming, will discuss the challenges of AI model training from a data perspective.
Scan the QR code in the poster below for quick registration👇👇👇

Every “look” from you is regarded as a like
▼