
Produced by | Zhixiaodong Open Class
Instructor | Richard Li, CTO of Xiaogong Technology
Reminder | FollowZhixiaodong Open Class or Zhixiaodong WeChat official account, and reply with the keyword Embedded 05 to obtain the course materials.
Introduction:
On June 22, Dr. Richard Li, CTO of Xiaogong Technology, conducted a live lecture on the fifth session of the Embedded AI series in the Zhixiaodong Open Class, with the theme “Development Practices of 3D Vision Applications Based on Embedded AI Modules”.
In this lecture, Richard provided a systematic explanation from the current application status of 3D vision in embedded devices, the design of high-precision 3D facial recognition algorithms, to the development of applications combining Xiaogong Technology’s embedded AI visual module and 3D facial recognition.
This article records the main points of the lecture:
Hello everyone, I am Richard Li, CTO of Xiaogong Technology. I am glad to share today’s topic with you in the Zhixiaodong Open Class. The theme I am sharing today is “Development Practices of 3D Vision Applications Based on Embedded AI Modules”, which is mainly divided into the following four parts:
1. Current status and challenges of 3D vision in embedded devices
2. Design of high-precision 3D facial recognition algorithms for embedded devices
3. Detailed explanation of the AlphaLook embedded AI visual module
4. Development practices of 3D facial recognition applications based on embedded AI modules
Current Status and Challenges of 3D Vision in Embedded Devices
First, let’s look at what 3D vision is. 3D vision adds depth information based on 2D vision, breaking through the technical bottleneck of 2D vision. 3D vision mainly uses 3D point cloud data as input to extract the three-dimensional features of images, thereby implementing 3D vision algorithms. Compared to 2D recognition algorithms, it has stronger differentiation and lower false recognition rates. Common 3D vision algorithms include 3D liveness detection, 3D facial recognition algorithms, 3D head detection, 3D posture recognition, 3D gesture recognition, 3D body measurement, 3D measurement, and 3D scene reconstruction.
3D vision enables machines to have three-dimensional perception capabilities like humans. What advantages does 3D have over 2D? We can distinguish them from six aspects:
1. From planarity, 3D can distinguish between flat and three-dimensional, while 2D can only see flat images without perceiving three-dimensional information.
2. 3D can measure objects related to shape, including depth, flatness, thickness, surface angles, volume, etc.
3. 3D can measure the contrast of objects because 2D relies on lighting, color, and grayscale changes to distinguish images. However, 3D, due to its depth information, is unaffected by different lighting, colors, and contrasts, so the contrast of 3D is also unaffected; it does not change with variations in light color.
4. 3D can easily distinguish between two touching objects, such as head detection algorithms and human detection algorithms. If two very close people are present, the bounding box of the 2D algorithm will generally frame them into one box, making it difficult to distinguish. However, because 3D has depth information, it can easily distinguish the edges between two objects, thus differentiating the two touching objects.
5. 3D can distinguish objects of the same color from the background.
6. Precision and repeatability; because 2D recognition algorithms rely on 2D cameras, they perform poorly in terms of precision repeatability. The same algorithm may have different precision performances on different cameras. 3D algorithms often pair with custom 3D cameras, achieving good precision and repeatability.
Now let’s look at the current status of 3D vision applications in embedded devices. Thanks to the depth perception and high precision characteristics of 3D technology, the application proportion of 3D facial recognition in some device terminals is increasing. For example, it accounted for only 32% in 2017, and it is expected to reach 58% in 2020. This includes facial payment, such as the facial payment machines used in Alipay and WeChat, which adopt 3D facial recognition algorithms. This sufficiently shows that 3D vision is increasingly popular in the application sector and is gaining market acceptance.
So how is Xiaogong’s 3D technology? Let’s compare it. Currently, there are three main types of 3D technology on the market: the first is called binocular imaging, which is stereoscopic; the second is 3D structured light; the third is ToF, which stands for Time of Flight.
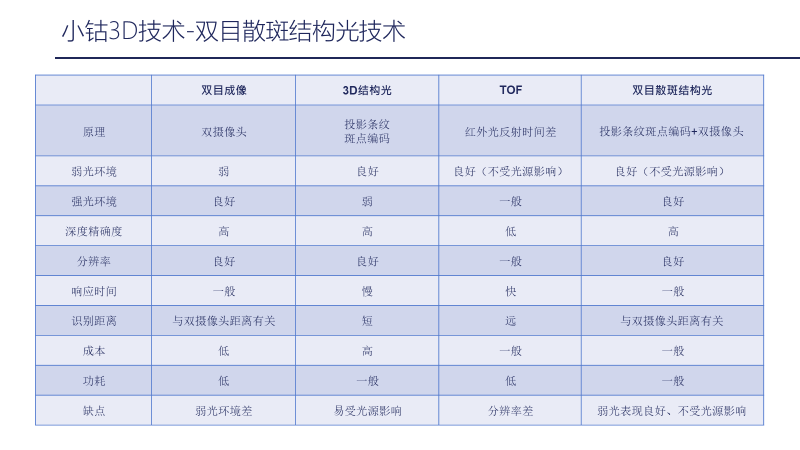
Xiaogong Technology uses binocular speckle structured light, which is distinct from the three types of 3D technology mentioned above. We will compare them in terms of principles, performance in low light environments, strong light environments, depth accuracy, resolution, response time, recognition distance, cost, and power consumption.
The principle of binocular imaging is that dual cameras imitate the three-dimensional reflection of human eyes to present depth information. The principle of 3D structured light is to project 3D structured light with stripe coding, which projects a certain coded light that, when hitting the surface of an object, presents a grid-like feature. These grids, when encountering uneven objects, will show distinctions in height and width, and then the receiver can distinguish these coded lights to detect changes on different objects, thus probing the depth information of the entire object’s surface. ToF uses the time difference of infrared light reflection; the total time taken for light to reflect off the object’s surface and return is divided by 2 to detect the depth of the entire object’s surface.
Generally, binocular imaging performs poorly in low light, which is a major drawback. However, it performs well in strong light environments. 3D structured light performs very well in low light but is very weak in strong light, especially outdoors. ToF is basically unaffected by light sources and is relatively stable. Both binocular imaging and 3D structured light have high precision in depth, while ToF’s precision is relatively low, mainly due to the production process of ToF.
In terms of resolution, binocular imaging and 3D structured light have better resolution, while ToF’s resolution is relatively low. In response time, binocular imaging has average speed, while ToF is the fastest, and structured light is slower due to the need for coding and computation. In terms of recognition distance, the closer the distance between binocular cameras, the shorter the recognition distance; structured light has a relatively short recognition distance, while ToF can recognize distances from 1-3 meters, even up to 5 meters, while structured light is generally within 1 meter. In terms of cost, binocular imaging is relatively low, structured light is average, while ToF is relatively high due to the immaturity of its components and the lack of strong mass production conditions. In terms of power consumption, binocular imaging is low, 3D structured light is average, and ToF is also low.
In summary, the disadvantage of binocular imaging is its poor performance in low light environments, but it has relatively good accuracy. The disadvantage of structured light is its susceptibility to light sources, especially outdoor lighting, while ToF’s biggest drawback is its poor resolution and high cost.
Xiaogong Technology uses binocular speckle structured light technology, which combines the characteristics of both binocular imaging and 3D structured light. This technology uses dual cameras along with speckle coding, which is not coded structured light. Therefore, speckle structured light compensates for the depth of binocular imaging and enhances performance in low light conditions.
Currently, what is the status of 3D vision applications in embedded devices? Taking the products made by Xiaogong Technology in the industry as an example, our 3D vision technology has been applied in various embedded devices, such as 3D home locks, 3D glass locks, 3D facial payment machines, 3D attendance access control machines, 3D smart doors, 3D smart storage cabinets, and 3D cash registers. All of these are equipped with Xiaogong’s 3D facial recognition and 3D liveness detection algorithms. 3D recognition has penetrated various aspects of our lives, covering consumption, access, payment, etc.
What challenges does 3D vision face in embedded device applications? There are several key aspects:
– 3D data is difficult to obtain; it is not as easily accessible as 2D data;
– 3D algorithms require compatible 3D camera modules;
– 3D algorithms require depth information, so the chip must support depth value calculations;
– 3D models are difficult to train;
– 3D algorithms have a large computational load, requiring strong computing power from the chip;
– 3D algorithms also have robustness requirements regarding lighting, height, posture, and accessories.
So how can we solve these problems?
Design of High-Precision 3D Facial Recognition Algorithms for Embedded Devices
Xiaogong Technology uses high-precision 3D acquisition devices and our self-produced 3D cameras, and has collected a large amount of 3D data. This data is collected from different angles, distances, lighting, and accessories to obtain 3D images and point cloud information from various angles, including depth information from the camera. We also have some 3D simulators to generate millions of 3D images, as well as depth information and point cloud information based on the collected data.
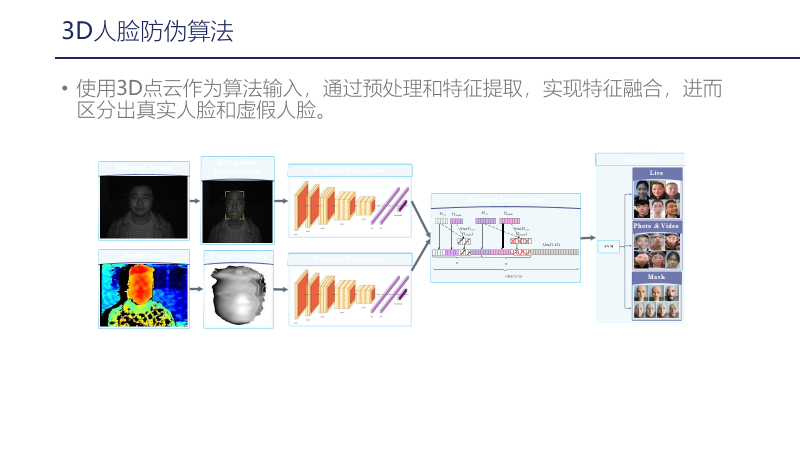
Combining this information and data, we train the 3D liveness detection algorithm, which mainly uses 3D point cloud data as algorithm input. Through preprocessing and feature extraction, we achieve feature fusion. As shown in the image above, the upper part is infrared, and the lower part is depth; both undergo face key point extraction and preprocessing, followed by feature extraction. A network is then used to achieve feature fusion, which is classified through a classification network to differentiate between real and fake faces. A large amount of data is used for training, including known fake and real faces, allowing us to differentiate many situations.
The 3D liveness algorithm developed by Xiaogong Technology can currently prevent attacks from printed photos, smartphone photos, 3D printed masks, and even silicone masks. We have also developed a 3D facial recognition algorithm that uses 3D point cloud data as input to extract three-dimensional facial features, implementing a 3D facial recognition algorithm with higher differentiation and lower false recognition rates. In algorithm development, we usually adopt a combination of 2D and 3D methods, first modeling 3D facial data entry, calculating the deflection angle, rotating projections, and then entering the face while extracting features. Additionally, we combine depth information for feature extraction, feature fusion, and calculation, ultimately comparing similarity.
This is significantly different from ordinary 2D facial recognition, which mainly relies on a single facial image for feature extraction. In contrast, 3D facial recognition incorporates point cloud information throughout the process, considering different angles, textures, and feature point positioning during the point cloud information fusion process, thus making the algorithm more robust and differentiated.
Currently, the false recognition rate achievable by the facial recognition algorithm is 1:1 million, with a recognition angle of ±15 degrees. Thanks to the binocular speckle structured light technology, the 3D facial recognition algorithm can be used indoors and outdoors, regardless of various lighting conditions and angles, and can also achieve unobstructed recognition for accessories such as glasses, scarves, and hats.
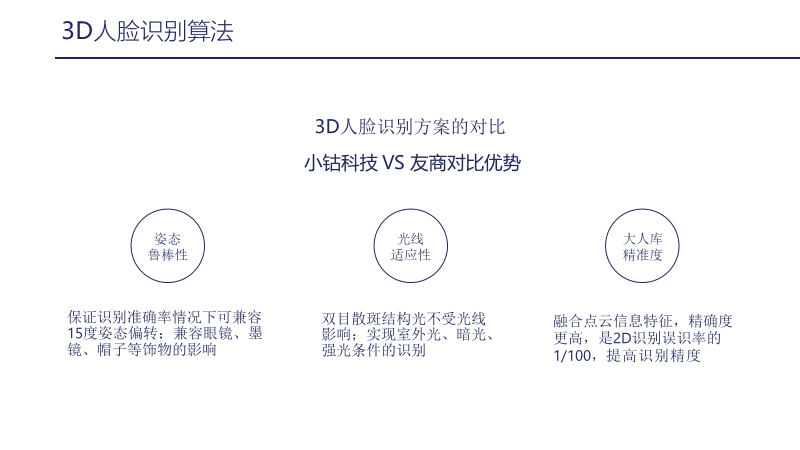
Now let’s look at the comparison of 3D facial recognition solutions. Where does Xiaogong Technology stand out compared to competitors? It mainly reflects in three aspects: first, robustness to posture; ensuring recognition accuracy while allowing for a 15-degree posture deviation, and accommodating the influence of accessories like glasses, sunglasses, and hats; second, adaptability to lighting conditions, which benefits from binocular speckle structured light technology, allowing recognition without being affected by lighting, achieving recognition in outdoor, dim, and bright conditions; third, the precision of a large facial database, as 3D facial recognition incorporates point cloud feature information and depth features as part of the recognition features, resulting in higher precision, achieving a false recognition rate of 1% compared to 2D.
Detailed Explanation of the AlphaLook Embedded AI Visual Module
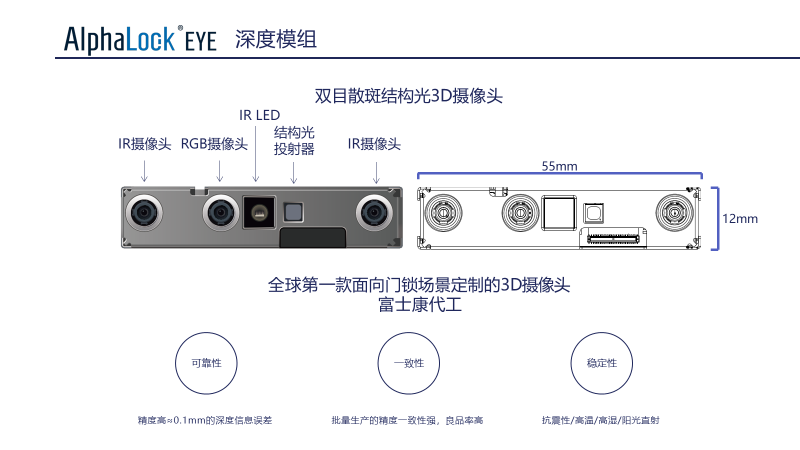
Next, let’s introduce the AlphaLook embedded AI visual module. First, let’s talk about the binocular speckle structured light 3D camera. As shown in the image above, the camera mainly consists of three lenses and two LED lights. The leftmost and rightmost are two infrared cameras that complete binocular stereoscopic estimation, while the middle RGB camera is not used for algorithm collection but only for image display, and possibly for scenarios like payments where 2D visible light facial recognition is required. The infrared LEDs are used for infrared supplementary lighting, and next to it is the structured light projector, which is the speckle structured light projector used for effective depth compensation in low light conditions.
On the right side is a door lock scenario, which requires the entire width to be narrow enough, so the defined width is 55 millimeters, and the height is 12 millimeters, ensuring it can fit into a lock.
Due to the use of binocular speckle structured light technology, the camera can handle various lighting conditions, including strong light, dim light, backlight, side light, and top light. Since this camera is designed for the door lock industry, it addresses the issue of height differences in families, ensuring that a lock can meet the height requirements of all family members, allowing them to enter easily.
Our camera can recognize individuals from a height range of 1.2m to 1.9m with a vertical field of view of 78 degrees, achieving recognition at around 40-50 cm. At 50 cm, it can achieve an automatic calibration of 0.1 millimeters. Under different vibration conditions, the accuracy of the lock may be compromised, but automatic calibration can compensate for depth loss.
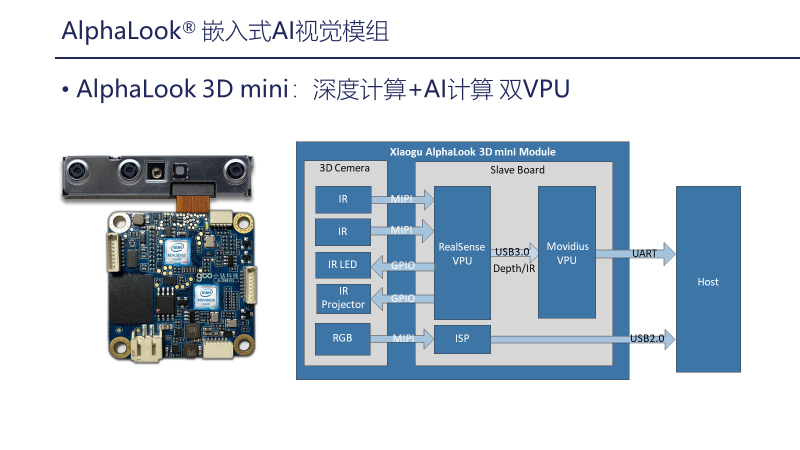
Next, let’s introduce the entire module solution, called AlphaLook 3D mini. The architectural diagram on the right shows that it uses two Intel VPUs: one is the Intel RealSense VPU, and the second is the Intel Movidius VPU for AI computation. The RealSense VPU is used for binocular stereoscopic depth, IR LED control, IR project control, depth compensation, switch control, and includes components such as the camera’s current and startup. The Movidius VPU is mainly used for the transplantation of 3D algorithms, including 3D liveness detection, 3D quality assessment, and 3D facial recognition feature extraction. The RGB camera performs image processing through ISP, and the processed image is output via USB2.0, which can be used for image preview and facial recognition in 3D payment scenarios.
By using both RealSense and Movidius dual chips, we achieve facial recognition algorithms and depth calculations. The 3D facial recognition algorithm operates at a recognition speed of around 700 milliseconds, while employing a low power design, with the overall power consumption of the device being around 2-3W. When not in use, it can be completely powered off, with a startup time of about two seconds from power off to completion. In terms of the facial database, the cloud is equipped with a cloud algorithm library for 3D facial recognition, capable of supporting 100,000 individuals, while locally supporting local feature extraction for 1,000 individuals. This is achieved through a cloud-edge combined approach for larger scenarios of 3D facial recognition. Hardware interfaces include serial ports and USB2.0, with USB2.0 used for RGB image preview, while the serial port serves as a protocol interface for the 3D algorithm in Movidius.
Based on the AlphaLook 3D mini module, customers can quickly develop cloud-edge combined AIoT solutions, such as local image capture, depth calculation, facial liveness detection, 3D feature extraction, feature matching, and 3D content entry. Additionally, algorithm APIs and video streams can be accessed through serial ports and USB2.0.
On the main control side, Intel, ARM, or ATM32 microcontrollers can be used to implement the entire network control for facial feature uploads and downloads. In the cloud, it can support feature comparison for 100,000 individuals, database management, and feature uploads and downloads. On the mobile side, user management, record management, system configuration, and firmware upgrades can be achieved. Currently, our cloud-edge combined solution has applications in various scenarios, including home locks, hotel locks, and glass locks.

Xiaogong Technology has not only developed the AlphaLook 3D mini module but has also created various 3D modules tailored to different scene requirements, such as 3D payment cameras, 3D wide dynamic payment cameras, as well as integrated solutions with screens and peepholes (3D plus). We have also developed 3D mini2 for higher-level computations of 3D algorithms, which will have larger models and more application scenarios, such as 3D posture recognition, 3D gesture recognition, and 3D head detection algorithms. Lastly, there is 3D mini3, a purely binocular 3D solution, which implements the entire 3D recognition algorithm with a single chip.
Practical Development of 3D Facial Recognition Applications Based on Embedded AI Modules
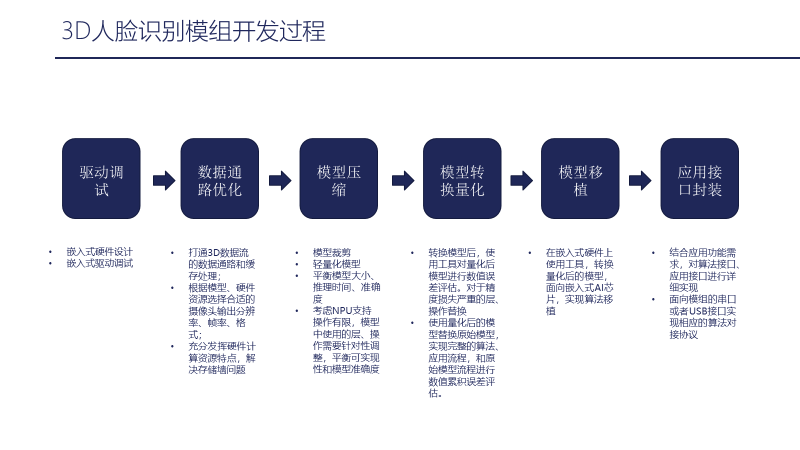
Next, we will focus on two aspects. The first aspect is the development process of the 3D facial recognition module, which can be summarized in six steps:
1. Debugging of embedded hardware drivers;
2. Optimization of data pathways; establishing the data pathways and cache processing for the 3D data stream, and then selecting appropriate camera output resolution, frame rate, and format based on the hardware resources of the model, fully utilizing the characteristics of hardware computing resources to solve storage wall issues;
3. Model compression, such as model pruning or directly using lightweight models, while balancing model size, inference time, and accuracy, ensuring the model is suitable for the entire scene application, and making compromises for embedded AI chips to ensure the model fits in memory, and the inference time and accuracy are acceptable in real-world scenarios. Consideration must be given to NPU support, and layers and operations used in the model need targeted adjustments to balance feasibility and model accuracy;
4. Model conversion and quantization; after converting the model, use tools to assess numerical error for the quantized model. For layers and operations with severe precision loss, replacements are made. After replacing some quantized models, the complete algorithm application process needs to be implemented in the scene. After running through the process, the cumulative error of the model is evaluated. If the cumulative error is high, it may be necessary to retrain the model. If the error is low, alternative layers can be swapped out to achieve a balance between speed, model size, and final accuracy;
5. Model transplantation; after determining, compressing, and converting the model, use tools for direct transplantation, which can run immediately after transplantation;
6. Proper application interface encapsulation; based on application functional requirements, implement detailed algorithm and application interface protocols for module serial or USB interfaces.
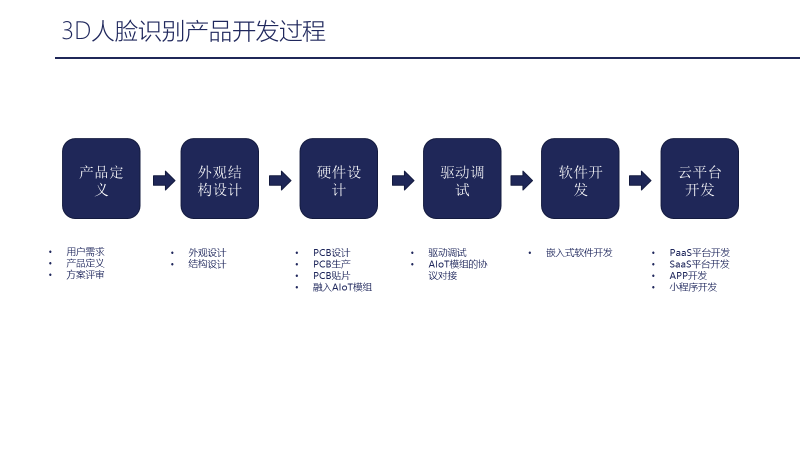
The second part is the product development process of the 3D facial recognition algorithm. First, we define the product, researching user needs and conducting proper definitions and reviews. The second step involves structural design based on these definitions, followed by internal structural design. The third step focuses on hardware design based on the structure, including PCB design, production, and assembly. The fourth step involves driver debugging, including the camera and peripheral devices. After debugging the drivers, we proceed with the protocol docking of the embedded module to activate the algorithm, followed by software development. The final step involves cloud platform development, integrating with our platform, such as connecting to the PaaS layer for social connections and the SaaS layer defined by the scenario; both layers need to be docked, and some users require entry points for smart home and smart park device applications, which may need to operate on an app or mini-program.




END
Live Preview
On September 14 at 8 PM, the 17th lecture of the CV Frontier Lecture Series will officially start online! Xiaoyang Xiao, a PhD student at Paris Tech, will explain “Target Detection and 3D Pose Estimation in Non-Specific Scenes”.
Scan the QR code in the poster below for quick registration👇👇👇

Your every “Like” is appreciated
▼