
Click the blue text to follow us
1
Background and Objectives
We previously evaluated using SeaTunnel for CDC lake validation: SeaTunnel-CDC lake practice. These scenarios are all cases where a direct connection to the database is possible. However, business requirements often arise where a direct connection to the database for CDC data synchronization is not feasible. In such cases, APIs are needed for data integration, and Apache DolphinScheduler can be used for scheduled data synchronization.
For example:
- Synchronizing inventory data from ERP (SAP) into the lake warehouse for inventory analysis
At the same time, the goal is for other colleagues to replicate this process so that they can independently complete the integration of HTTP interfaces to the lake warehouse in the future, rather than needing to rely on coding for each integration requirement.
2
Preparation Work
- seatunnel 2.3.10
First, you need to add the connector name in the <span><span>${SEATUNNEL_HOME}/config/plugin_config</span></span> file, then execute the command to install the connector, ensuring that the connector is in the ${SEATUNNEL_HOME}/connectors/ directory.
In this example, we will use:<span><span>connector-jdbc</span></span>, <span><span>connector-paimon</span></span>
Writing to StarRocks can also use <span><span>connector-starrocks</span></span>, but the scenario in this example is more suitable for using <span><span>connector-jdbc</span></span>, so we will use <span><span>connector-jdbc</span></span>.
# Configure connector names
--connectors-v2--
connector-jdbc
connector-starrocks
connector-paimon
--end--
# Install connector
sh bin/install-plugin.sh 2.3.10
3
SeaTunnel Task
We first ensure that we can complete the SeaTunnel task locally before integrating with Apache DolphinScheduler.
- http to starRocks
<span><span>example/http2starrocks</span></span>
env {
parallelism = 1
job.mode = "BATCH"
}
source {
Http {
plugin_output = "stock"
url = "https://ip/http/prd/query_sap_stock"
method = "POST"
headers {
Authorization = "Basic XXX"
Content-Type = "application/json"
}
body = """{"IT_WERKS": [{"VALUE": "1080"}]}}"""
format = "json"
content_field = "$.ET_RETURN.*"
schema {
fields {
MATNR = "string"
MAKTX = "string"
WERKS = "string"
NAME1 = "string"
LGORT = "string"
LGOBE = "string"
CHARG = "string"
MEINS = "string"
LABST = "double"
UMLME = "double"
INSME = "double"
EINME = "double"
SPEME = "double"
RETME = "double"
}
}
}
}
# This transformation operation is mainly for convenience in field naming
transform {
Sql {
plugin_input = "stock"
plugin_output = "stock-tf-out"
query = "select MATNR, MAKTX, WERKS,NAME1,LGORT,LGOBE,CHARG,MEINS,LABST,UMLME,INSME,EINME,SPEME,RETME from stock"
}
}
# Connect to starRocks for data partition overwrite, this example is suitable for starRocks table creation, using partition insert overwrite
sink {
jdbc {
plugin_input = "stock-tf-out"
url = "jdbc:mysql://XXX:9030/scm?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true"
driver = "com.mysql.cj.jdbc.Driver"
user = "lab"
password = "XXX"
compatible_mode="starrocks"
query = """insert overwrite ods_sap_stock PARTITION (WERKS='1080') (MATNR, MAKTX, WERKS,NAME1,LGORT,LGOBE,CHARG,MEINS,LABST,UMLME,INSME,EINME,SPEME,RETME) values(?,?,?,?,?,?,?,?,?,?,?,?,?,?)"""
}
}
# connector-starrocks integration (not seen supporting SQL statements for data insert overwrite, this example scenario is not suitable), more suitable for scenarios where all table data is deleted and rebuilt
// sink {
// StarRocks {
// plugin_input = "stock-tf-out"
// nodeUrls = ["ip:8030"]
// base-url = "jdbc:mysql://ip:9030/"
// username = "lab"
// password = "XXX"
// database = "scm"
// table = "ods_sap_stock"
// batch_max_rows = 1000
// data_save_mode="DROP_DATA"
// starrocks.config = {
// format = "JSON"
// strip_outer_array = true
// }
// schema_save_mode = "RECREATE_SCHEMA"
// save_mode_create_template="""
// CREATE TABLE IF NOT EXISTS `scm`.`ods_sap_stock` (
// MATNR STRING COMMENT 'Material',
// WERKS STRING COMMENT 'Factory',
// LGORT STRING COMMENT 'Storage Location',
// MAKTX STRING COMMENT 'Material Description',
// NAME1 STRING COMMENT 'Factory Name',
// LGOBE STRING COMMENT 'Location Description',
// CHARG STRING COMMENT 'Batch Number',
// MEINS STRING COMMENT 'Unit',
// LABST DOUBLE COMMENT 'Unrestricted Stock',
// UMLME DOUBLE COMMENT 'In-Transit Stock',
// INSME DOUBLE COMMENT 'Quality Inspection Stock',
// EINME DOUBLE COMMENT 'Restricted Stock',
// SPEME DOUBLE COMMENT 'Frozen Stock',
// RETME DOUBLE COMMENT 'Returns'
// ) ENGINE=OLAP
// PRIMARY KEY ( MATNR,WERKS,LGORT)
// COMMENT 'SAP Inventory'
// DISTRIBUTED BY HASH (WERKS) PROPERTIES (
// "replication_num" = "1"
// )
// """
// }
// }
- http to paimon
<span><span>example/http2paimon</span></span>
env {
parallelism = 1
job.mode = "BATCH"
}
source {
Http {
plugin_output = "stock"
url = "https://ip/http/prd/query_sap_stock"
method = "POST"
headers {
Authorization = "Basic XXX"
Content-Type = "application/json"
}
body = """{"IT_WERKS": [{"VALUE": "1080"}]}}"""
format = "json"
content_field = "$.ET_RETURN.*"
schema {
fields {
MATNR = "string"
MAKTX = "string"
WERKS = "string"
NAME1 = "string"
LGORT = "string"
LGOBE = "string"
CHARG = "string"
MEINS = "string"
LABST = "double"
UMLME = "double"
INSME = "double"
EINME = "double"
SPEME = "double"
RETME = "double"
}
}
}
}
# This transformation operation is mainly for convenience in field naming
transform {
Sql {
plugin_input = "stock"
plugin_output = "stock-tf-out"
query = "select MATNR, MAKTX, WERKS,NAME1,LGORT,LGOBE,CHARG,MEINS,LABST,UMLME,INSME,EINME,SPEME,RETME from stock"
}
}
# Connect to paimon for data synchronization, currently, Paimon does not support insert overwrite partition overwrite, this example is for reference only and not suitable for this requirement
sink {
Paimon {
warehouse = "s3a://test/"
database = "sap"
table = "ods_sap_stock"
paimon.hadoop.conf = {
fs.s3a.access-key=XXX
fs.s3a.secret-key=XXX
fs.s3a.endpoint="http://minio:9000"
fs.s3a.path.style.access=true
fs.s3a.aws.credentials.provider=org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider
}
}
}
4
DolphinScheduler Integration
SeaTunnel
- Create worker image
FROM dolphinscheduler.docker.scarf.sh/apache/dolphinscheduler-worker:3.2.2
RUN mkdir /opt/seatunnel
RUN mkdir /opt/seatunnel/apache-seatunnel-2.3.10
# Container integration of seatunnel
COPY apache-seatunnel-2.3.10/ /opt/seatunnel/apache-seatunnel-2.3.10/
Package the image and push it to the image repository
docker build --platform=linux/amd64 -t apache/dolphinscheduler-worker:3.2.2-seatunnel .
- Deploy a worker using the new image, modify the
<span><span>docker-compose.yaml</span></span>, and add a<span><span>dolphinscheduler-worker-seatunnel</span></span>node.
...
dolphinscheduler-worker-seatunnel:
image: xxx/dolphinscheduler-worker:3.2.2-seatunnel
profiles: ["all"]
env_file: .env
healthcheck:
test: [ "CMD", "curl", "http://localhost:1235/actuator/health" ]
interval: 30s
timeout: 5s
retries: 3
depends_on:
dolphinscheduler-zookeeper:
condition: service_healthy
volumes:
- ./dolphinscheduler-worker-seatunnel-data:/tmp/dolphinscheduler
- ./dolphinscheduler-logs:/opt/dolphinscheduler/logs
- ./dolphinscheduler-shared-local:/opt/soft
- ./dolphinscheduler-resource-local:/dolphinscheduler
networks:
dolphinscheduler:
ipv4_address: 172.15.0.18
...
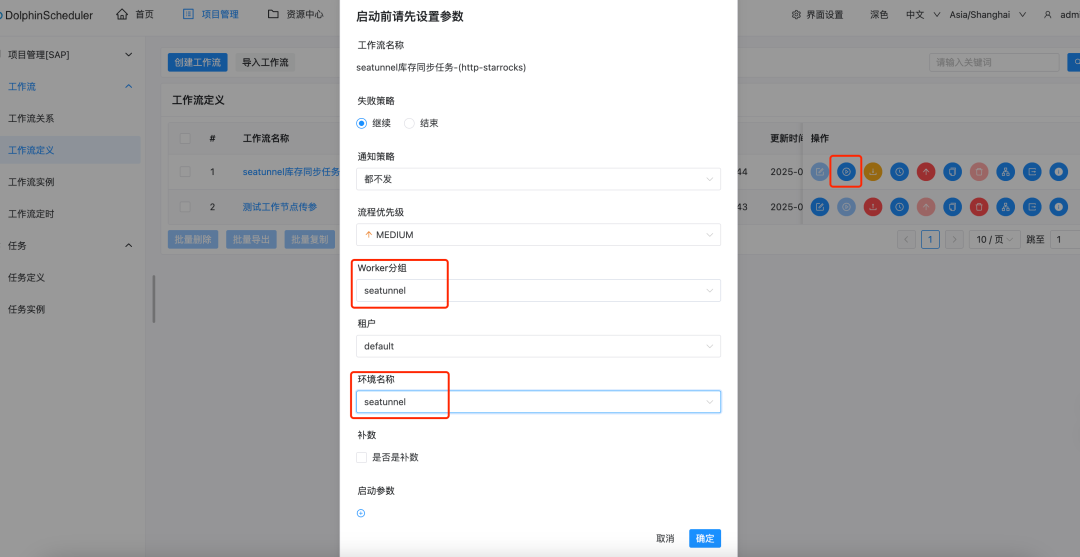
- DolphinScheduler configuration for SeaTunnel group and environment settings
-
Security Center – Worker Group Management, create a group for this node’s IP for future tasks requiring SeaTunnel to run in this group

-
Environment Management – Create an environment, add one for executing SeaTunnel, and bind the Worker group created in the previous step to the SeaTunnel group

-
Create workflow definitions, filling in the SeaTunnel task configurations above

-
When running, select the SeaTunnel worker group and environment to run in this integrated environment
Reprinted from Mr. Jun Yao Original link: https://junyao.tech/posts/9c6867c5.html


User Cases
NetEase Mail Daily Interaction Huisheng Project Homework Help Bosch Intelligent Driving NIOGreat Wall MotorsJiduChangan AutomobileCisco NetworkingFood TravelFresh FoodChina Unicom MedicalLenovoNewNet BankVipshop FubonConsumer Finance ZiruYouzanYiliDangbei Big DataZhenda GroupChuan Zhi EducationBigoYY Live Three-in-OneTaimei MedicalCisco WebexIndustrial Securities
Migration Practice
Azkaban Ooize(Dangbei Migration Case)Airflow (Youzan Migration Case)Air2phin(Migration Tool)Airflow MigrationPractice
Release Notes
Apache DolphinScheduler version 3.2.2 officially released!Apache DolphinScheduler version 3.2.1 released: Comprehensive upgrades in functionality and securityApache DolphinScheduler 3.3.0 Alpha released, major upgrades in functionality and performance optimization!
Join the Community
There are many ways to follow the community:
- GitHub: https://github.com/apache/dolphinscheduler
- Official Website:https://dolphinscheduler.apache.org/en-us
- Subscribe to Developer Emails:dev@[email protected]
- X.com:@DolphinSchedule
- YouTube:https://www.youtube.com/@apachedolphinscheduler
- Slack:https://join.slack.com/t/asf-dolphinscheduler/shared_invite/zt-1cmrxsio1-nJHxRJa44jfkrNL_Nsy9Qg
Similarly, there are many ways to contribute to Apache DolphinScheduler, mainly divided into code and non-code contributions.
📂 Non-code contributions include:
Improving documentation, translating documents; translating technical and practical articles; submitting practical and theoretical articles; becoming an evangelist; community management, answering questions; conference sharing; testing feedback; user feedback, etc.
👩💻 Code contributions include:
Finding bugs; writing fix code; developing new features; submitting code contributions; participating in code reviews, etc.
We hope that your first PR (documentation, code) will also be simple, as the first PR is to familiarize yourself with the submission process and community collaboration and to experience the friendliness of the community.The community has compiled a list of suitable issues for beginners:https://github.com/apache/dolphinscheduler/pulls?q=is%3Apr+is%3Aopen+label%3A%22first+time+contributor%22Priority issue list:https://github.com/apache/dolphinscheduler/pulls?q=is%3Apr+is%3Aopen+label%3Apriority%3AhighHow to Contribute Link:https://dolphinscheduler.apache.org/zh-cn/docs/3.2.2/%E8%B4%A1%E7%8C%AE%E6%8C%87%E5%8D%97_menu/%E5%A6%82%E4%BD%95%E5%8F%82%E4%B8%8E_menuIf you ❤️ the little dolphin, please give me a star!https://github.com/apache/dolphinscheduler

Your friend Xiuxiu has tapped you
And asks you to help her click“Share”