Follow👆the public account and reply with 'python' to get the zero-based tutorial! Source from the internet, please delete if infringingIntroduction to Python Data Analysis Basics
1. Descriptive Statistics (descriptive statistics)
Descriptive statistics is the first step in understanding the basic characteristics of a dataset, including statistics such as mean, median, and standard deviation.
[Tutorial Access Method at the End!!]
Use pandas library to calculate the descriptive statistics of the dataset.
import pandas as pd
# Create a dataset
data = {
'age': [25, 30, 35, 40, 45],
'income': [50000, 60000, 70000, 80000, 90000]
}
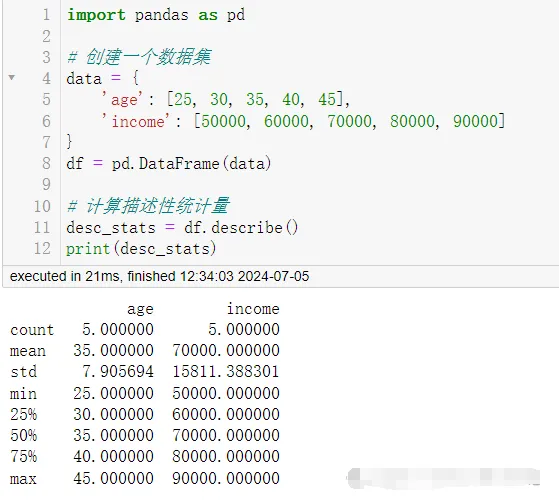
df = pd.DataFrame(data)
# Calculate descriptive statistics
desc_stats = df.describe()
print(desc_stats)
2. Data Visualization (data visualization)
Data visualization is the graphical representation of data, which helps in discovering patterns, trends, and anomalies.
Use matplotlib and seaborn libraries to create charts.
import matplotlib.pyplot as plt
import seaborn as sns
# Load built-in dataset
tips = sns.load_dataset("tips")
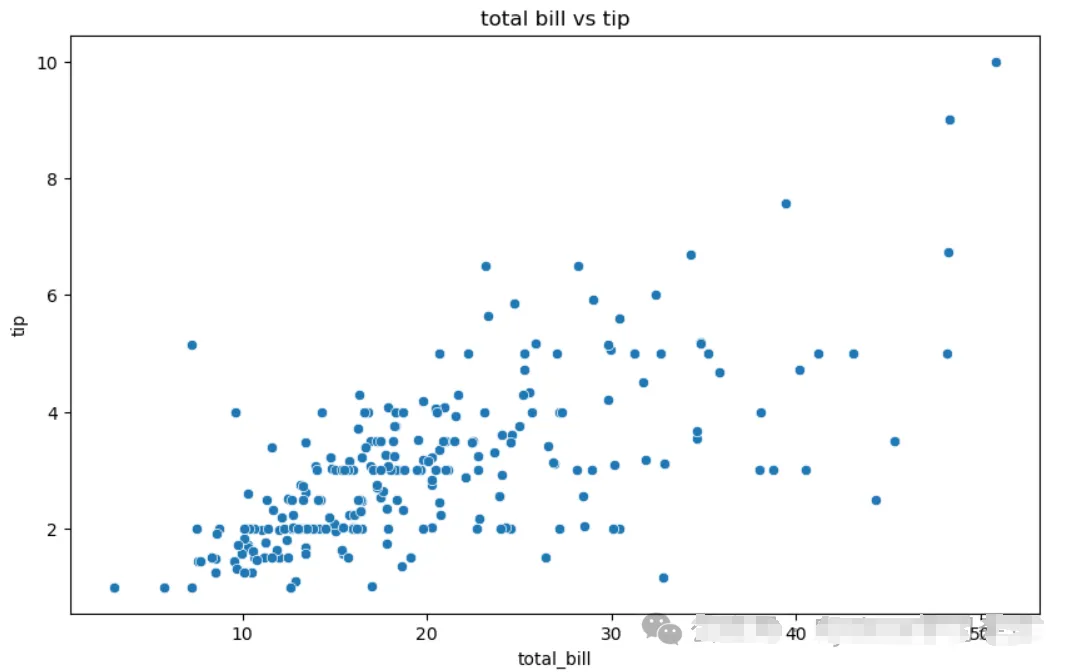
# Create scatter plot
plt.figure(figsize=(10, 6))
sns.scatterplot(x="total_bill", y="tip", data=tips)
plt.title('total bill vs tip')
plt.show()

3. Exploratory Data Analysis (exploratory data analysis, EDA)
EDA is the process of understanding data using charts and other statistical methods without explicit hypotheses.
Use pandas and matplotlib for exploratory data analysis.
# Load built-in dataset
iris = sns.load_dataset("iris")
# Explore data using pandas
print(iris.head())
print(iris.info())
print(iris.describe())
# Use seaborn to draw boxplot to observe the petal length distribution of different iris species
sns.boxplot(x='species', y='petal_length', data=iris)
plt.show()
Output
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosa
<class 'pandas.core.frame.dataframe'="">
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal_length 150 non-null float64
1 sepal_width 150 non-null float64
2 petal_length 150 non-null float64
3 petal_width 150 non-null float64
4 species 150 non-null object
dtypes: float64(4), object(1)
memory usage: 6.0+ KB
None
sepal_length sepal_width petal_length petal_width
count 150.000000 150.000000 150.000000 150.000000
mean 5.843333 3.057333 3.758000 1.199333
std 0.828066 0.435866 1.765298 0.762238
min 4.300000 2.000000 1.000000 0.100000
25% 5.100000 2.800000 1.600000 0.300000
50% 5.800000 3.000000 4.350000 1.300000
75% 6.400000 3.300000 5.100000 1.800000
max 7.900000 4.400000 6.900000 2.500000
</class>
4. Hypothesis Testing (hypothesis testing)
Hypothesis testing is a statistical process to determine whether patterns in data are due to random variation or actual effects.
Use scipy for t-test.
from scipy import stats
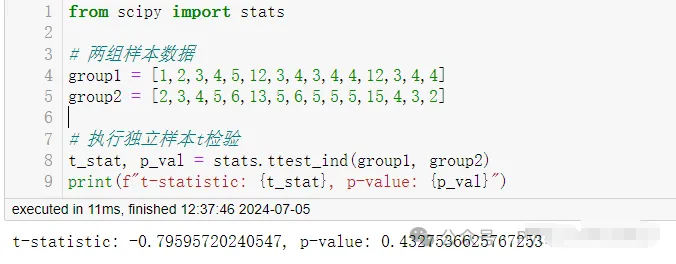
# Two sample datasets
group1 = [1,2,3,4,5,12,3,4,3,4,4,12,3,4,4]
group2 = [2,3,4,5,6,13,5,6,5,5,5,15,4,3,2]
# Perform independent samples t-test
t_stat, p_val = stats.ttest_ind(group1, group2)
print(f"t-statistic: {t_stat}, p-value: {p_val}")
Deep learning in Python – attention mechanism, Transformer model, generative models, object detection algorithms, graph neural networks, reinforcement learning, and visualization methods.
Practical Tips for Python Data Analysis
import pandas as pd
# Create a sample DataFrame
data = {'old_name_1': [1, 2, 3], 'old_name_2': [4, 5, 6]}
df = pd.DataFrame(data)
# Rename columns
df.rename(columns={'old_name_1': 'new_name_1', 'old_name_2': 'new_name_2'}, inplace=True)
Sometimes, you need to handle datasets with uninformative column names. You can easily rename columns using the rename method.
# Filter rows where a condition is met
filtered_df = df[df['column_name'] > 3]
Filtering rows by condition is a common operation that allows you to select only the rows that meet specific criteria.
# Drop rows with missing values
df.dropna()
# Fill missing values with a specific value
df.fillna(0)
Handling missing data is an important part of data analysis. You can either drop rows with missing values or fill them with default values.
# Group by a column and calculate mean for each group
grouped = df.groupby('group_column')['value_column'].mean()
Grouping and summarizing data is crucial for aggregating information in a dataset. You can use Pandas’ groupby method to calculate statistics for each group.
# Create a pivot table
pivot_table = df.pivot_table(values='value_column', index='row_column', columns='column_column', aggfunc='mean')
Pivot tables help reshape data and summarize it in tabular form. They are especially useful for creating summary reports.
# Merge two DataFrames
merged_df = pd.merge(df1, df2, on='common_column', how='inner')
When you have multiple datasets, you can merge them using Pandas’ merge function based on common columns.
# Apply a custom function to a column
def custom_function(x): return x * 2
df['new_column'] = df['old_column'].apply(custom_function)
You can apply custom functions to columns, which is especially useful when you need to perform complex transformations.

# Resample time series data
df['date_column'] = pd.to_datetime(df['date_column'])
df.resample('D', on='date_column').mean()
When working with time series data, Pandas allows you to resample the data to different time frequencies, such as daily, monthly, or yearly.
# Convert categorical data to numerical using one-hot encoding
df = pd.get_dummies(df, columns=['categorical_column'])
Categorical data often needs to be converted into numerical form for use in machine learning models. One common method is one-hot encoding.
# Export DataFrame to CSV
df.to_csv('output.csv', index=False)
When defining a certain list, writing a for loop can be cumbersome. Fortunately, Python has a built-in method to solve this in one line of code. Below is a comparison of creating a list using a for loop and creating a list in one line of code.
x = [1,2,3,4]
out = []
for item in x:
out.append(item**2)
print(out)
[1, 4, 9, 16]
# vs.
x = [1,2,3,4]
out = [item**2 for item in x]
print(out)
[1, 4, 9, 16]
Tired of defining functions that are only used a few times? Lambda expressions are your savior! Lambda expressions are used to create small, one-time, and anonymous function objects in Python, allowing you to create a function for you.
The basic syntax of lambda expressions is:
lambda arguments: expression
lambda arguments: expression
Note! As long as there is a lambda expression, any operation that a regular function can perform can be completed.
You can feel the powerful capabilities of lambda expressions from the following example:
double = lambda x: x * 2
print(double(5))
10
Once you master lambda expressions, learning to combine them with the Map and Filter functions can achieve even more powerful functionality. Specifically, map converts each element in a list by performing some operation and converts it into a new list.
In this example, it iterates through each element and multiplies it by 2, forming a new list. (Note! The list() function simply converts the output to a list type.)
# Map
seq = [1, 2, 3, 4, 5]
result = list(map(lambda var: var*2, seq))
print(result)
[2, 4, 6, 8, 10]
The Filter function takes a list and a rule, just like map, but it returns a subset of the original list by comparing each element with a boolean filtering rule.
# Filter
seq = [1, 2, 3, 4, 5]
result = list(filter(lambda x: x > 2, seq))
print(result)
[3, 4, 5]
Arange returns an arithmetic list with a given step size. Its three parameters start, stop, and step represent the starting value, ending value, and step size respectively. Note! The stop point is a ‘cut-off’ value, so it will not be included in the array output.
# np.arange(start, stop, step)
np.arange(3, 7, 2)
array([3, 5])
Linspace is very similar to Arange but slightly different. Linspace evenly divides the interval into a specified number of parts, so given the interval start and end, and the number of equal division points num, linspace will return a NumPy array. This is especially useful for data visualization and declaring axes when plotting.
# np.linspace(start, stop, num)
np.linspace(2.0, 3.0, num=5)
array([ 2.0, 2.25, 2.5, 2.75, 3.0])
In Pandas, you may encounter Axis when deleting a column or summing values in a NumPy matrix. We use the example of deleting a column:
df.drop('Column A', axis=1)
df.drop('Row A', axis=0)
If you want to handle columns, set Axis to 1, and if you want to handle rows, set it to 0. But why? Recall the shape in Pandas.
df.shape
(# of Rows, # of Columns)
Calling the shape attribute from a Pandas DataFrame returns a tuple where the first value represents the number of rows and the second value represents the number of columns.
If you want to index it in Python, the row index is 0 and the column index is 1, which is similar to how we declare axis values.
If you are familiar with SQL, these concepts may be easier for you. In any case, these functions essentially combine DataFrames in a specific way. It can be challenging to track which is best to use at what time, so let’s review. Concat allows users to append one or more DataFrames either below or beside a table (depending on how you define the axis).
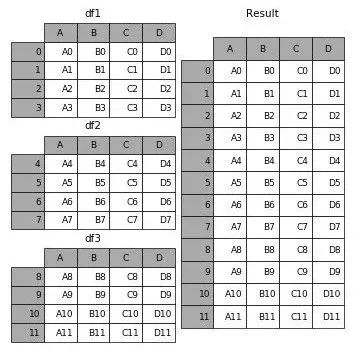
Merge combines multiple DataFrames based on matching rows with the same primary key (Key).
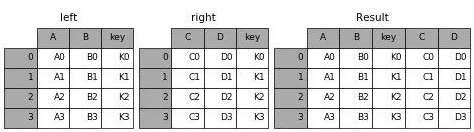
Join, like Merge, combines two DataFrames. However, it does not merge based on a specified primary key but rather based on the same column names or row names.
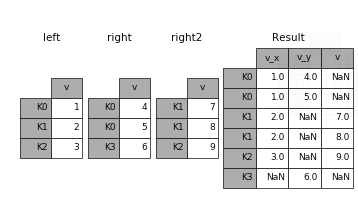
Apply is designed for Pandas Series. If you are not familiar with Series, you can think of it as an array similar to Numpy.
Apply applies a function to each element on the specified axis. Using Apply, you can format and manipulate the values of a DataFrame column (which is a Series) without looping, which is very useful!
df = pd.DataFrame([[4, 9],] * 3, columns=['A', 'B'])
df
A B
0 4 9
1 4 9
2 4 9
df.apply(np.sqrt)
A B
0 2.0 3.0
1 2.0 3.0
2 2.0 3.0
df.apply(np.sum, axis=0)
A 12
B 27
df.apply(np.sum, axis=1)
0 13
1 13
2 13
If you are familiar with Microsoft Excel, you may have heard of pivot tables. The built-in pivot_table function in Pandas creates spreadsheet-style pivot tables in the form of a DataFrame, which can help us quickly view data from certain columns. Here are a few examples: very intelligently grouping data by ‘Manager’:
pd.pivot_table(df, index=["Manager", "Rep"])
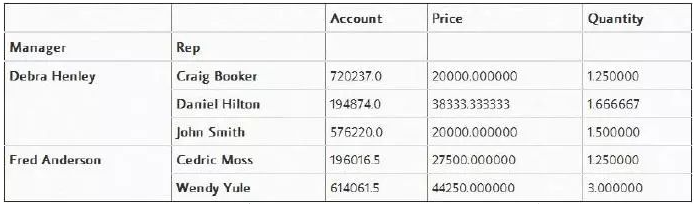
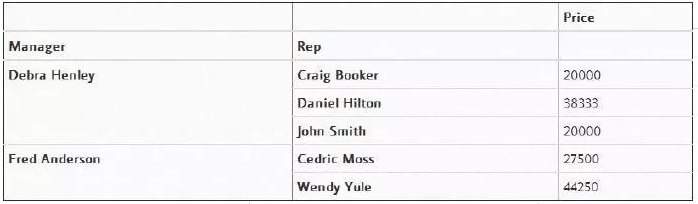
Or filter attribute values
pd.pivot_table(df,index=["Manager","Rep"],values=["Price"])
Based on the students’ learning progress, arrange corresponding Python training camps. Spending eight hours a week learning Python with me can improve yourself. What I arrange for you is free.
-
Like + Watch Again
-
Reply in the public account: “python”
Get the latest Python zero-based learning materials for 2024,Reply in the background:Python