Source: Machine Heart | Author: Robert Lucian Chiriac
Participants: Wang Zijia, Si, Yi Ming
How to create an intelligent vehicle system without changing the car? For a while, the author Robert Lucian Chiriac has been thinking about enabling cars to detect and recognize objects. This idea is very interesting because we have seen the capabilities of Tesla, and although we cannot buy a Tesla immediately (it must be mentioned that the Model 3 looks increasingly attractive), he had an idea to strive to realize this dream.
So, the author achieved this with Raspberry Pi, which can be installed in the car to detect license plates in real-time.
In the following content, we will introduce each step of the project and provide the GitHub project address, where the project address is just the client tool, and other datasets and pre-trained models can be found at the end of the original blog.
https://github.com/RobertLucian/cortex-license-plate-reader-client
Now, let’s see how the author Robert Lucian Chiriac built a useful onboard detection and recognition system step by step.
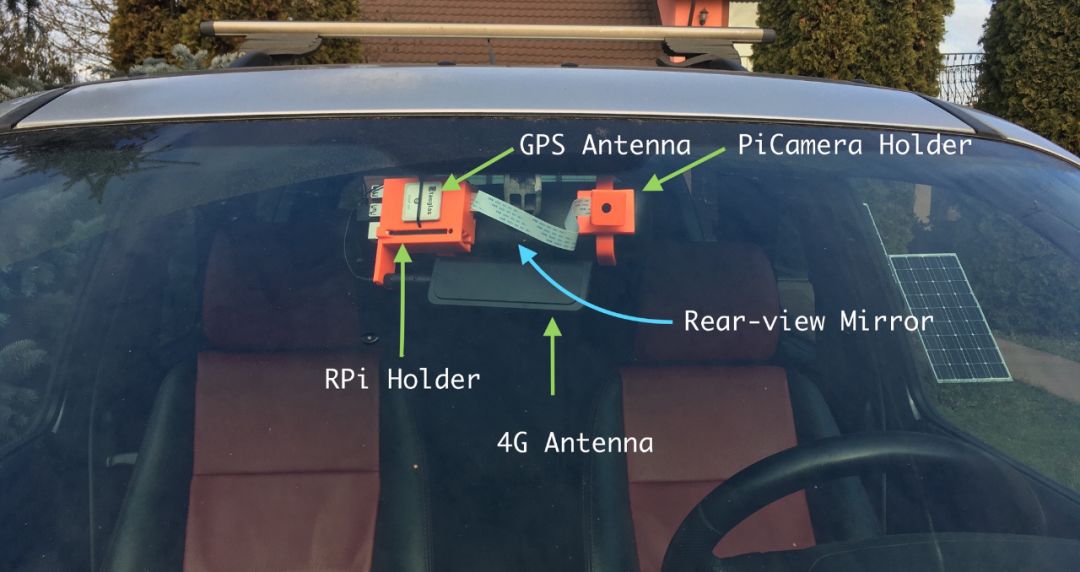
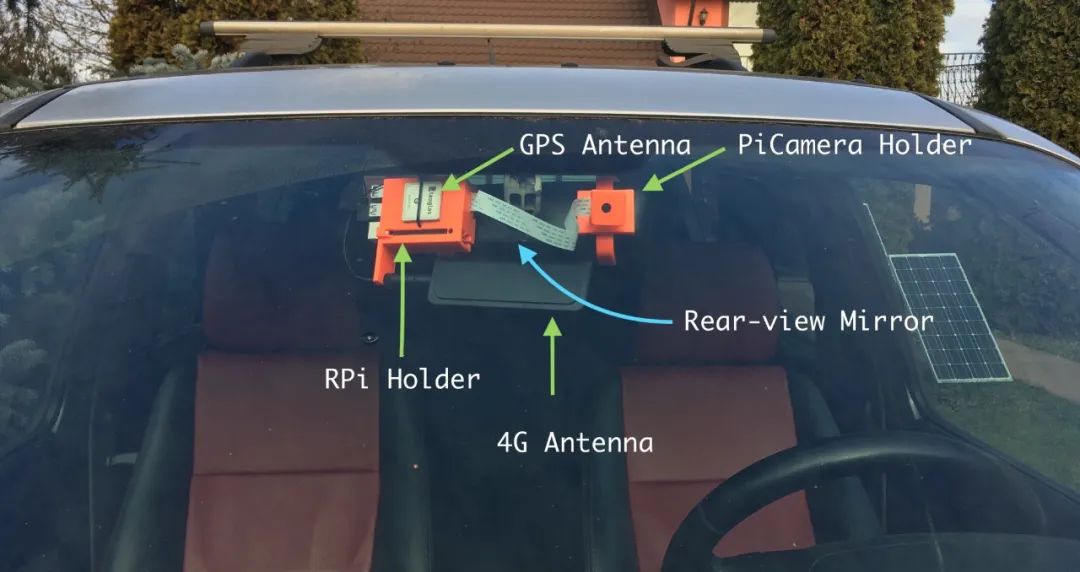
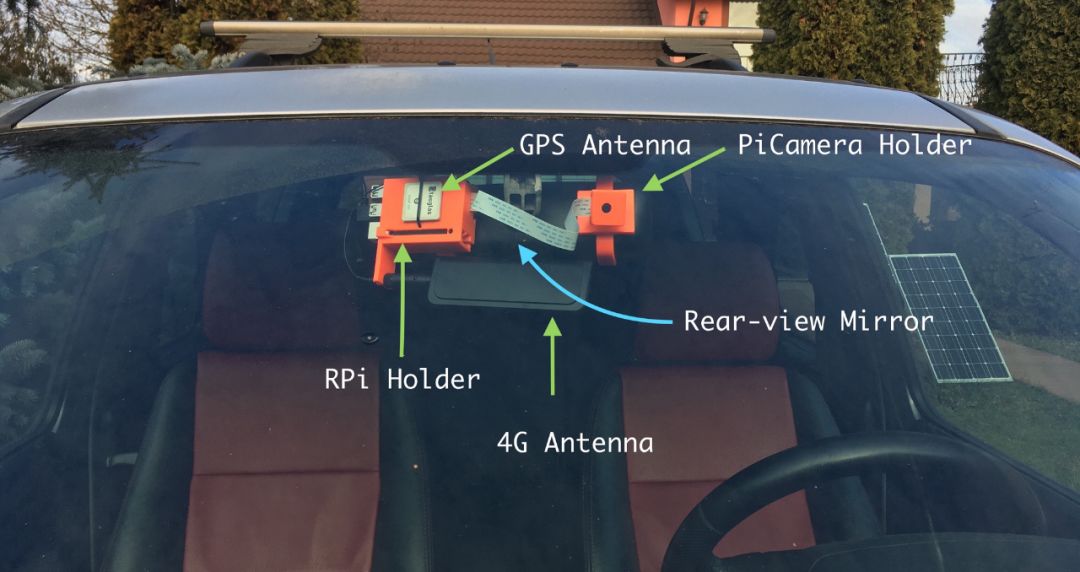
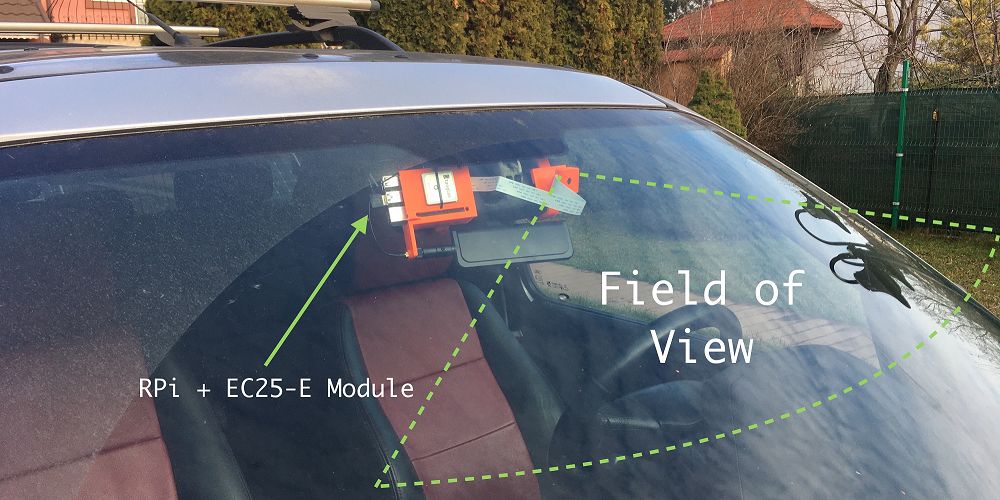
Here is a picture of the finished product.
Step 1:Define the project scope
Before starting, the first question that came to my mind was what such a system should be able to do. If there’s one thing I’ve learned so far, it’s that taking things step by step is always the best strategy. So, besides basic visual tasks, all I need is to be able to clearly recognize license plates while driving. This recognition process involves two steps:
-
Detect the license plate.
-
Recognize the text within each license plate bounding box.
I think if I can accomplish these tasks, doing other similar tasks (such as determining collision risks, distances, etc.) will be much easier. I might even be able to create a vector space to represent the surrounding environment – sounds cool to think about.
Before determining these details, I knew I had to first achieve:
-
A machine learning model that detects license plates using unlabeled images as input;
-
Some hardware. Simply put, I need a computer system connected to one or more cameras to call my model.
Let’s start with the first thing – building an object detection model.
Step 2:Select the right model
After careful research, I decided to use the following machine learning models:
-
YOLOv3 – This is one of the fastest models currently available and has a comparable mAP to other SOTA models. We use this model to detect objects;
-
CRAFT text detector – We use it to detect text in images;
-
CRNN – Simply put, this is a recurrent convolutional neural network model. It must process sequential data to arrange detected characters in the correct order;
How do these three models work together? The following describes the workflow:
-
First, the YOLOv3 model receives frames of images from the camera and finds the bounding boxes for the license plates in each frame. It is not recommended to use very precise predicted bounding boxes – bounding boxes that are slightly larger than the detected objects are better. If they are too tight, it may affect the performance of subsequent processes;
-
The text detector receives the cropped license plates from YOLOv3. At this point, if the bounding boxes are too small, it is likely that part of the license plate text will be cropped out, resulting in poor prediction results. However, when the bounding boxes are enlarged, we can let the CRAFT model detect the positions of the letters, allowing for very precise positioning of each letter;
-
Finally, we can pass the bounding boxes of each word from CRAFT to the CRNN model to predict the actual words.
With the basic model architecture sketch in hand, I can start tackling the hardware.
Step 3:Design the hardware
When I realized I needed a low-power hardware, I thought of my old love: Raspberry Pi. Because it has a dedicated camera, the Pi Camera, and enough computing power to preprocess each frame at a decent frame rate. The Pi Camera is a physical camera for Raspberry Pi and has a mature and complete library.
To connect to the internet, I can use the 4G connection from EC25-E, which I have used in a previous project with its GPS module, details can be found:
Blog Address: https://www.robertlucian.com/2018/08/29/mobile-network-access-rpi/
Then I need to start designing the casing – it should be fine to hang it on the car’s rearview mirror, so I finally designed a support structure divided into two parts:
-
On the side facing the rearview mirror, the Raspberry Pi + GPS module + 4G module will be kept. You can check my article about the EC25-E module for information about the GPS and 4G antennas I used;
-
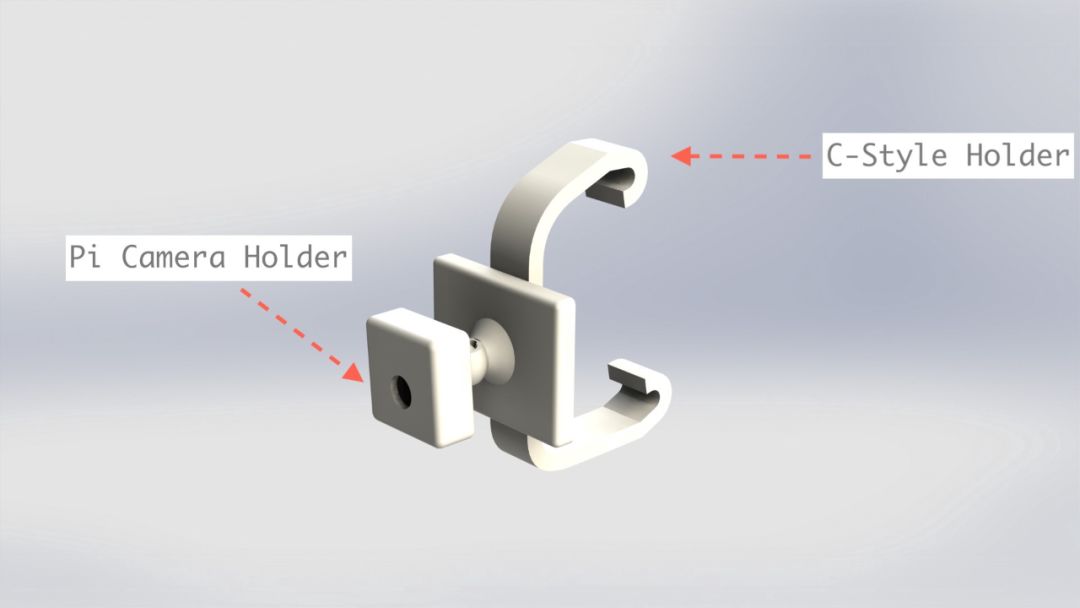
On the other side, I used an arm that utilizes a ball joint to support the Pi Camera.
I will print these parts using my reliable Prusa i3 MK3S 3D printer, and I also provide the 3D printing parameters at the end of the original text.
Figure 1: The shape of the Raspberry Pi + 4G/GPS casing
Figure 2:Using a ball joint arm to support the Pi Camera
Figures 1 and 2 show how they look when rendered. Note that the C-shaped bracket is pluggable, so the Raspberry Pi’s accessories and the support for the Pi Camera are not printed together with the bracket. They share a socket, with the bracket plugged in. If any reader wants to replicate this project, this is very useful. They only need to adjust the bracket on the rearview mirror. Currently, this base works well in my car (Land Rover Freelander).
Figure 3:Side view of the Pi Camera support structure
Figure 4:Front view of the Pi Camera support structure and RPi base
Figure 5:Expected camera field of view
Figure 6:Close-up of the embedded system with built-in 4G/GPS module and Pi Camera
Clearly, these things take some time to model, and I need to do it several times to get a sturdy structure. The PETG material I used has a layer height of 200 microns. PETG works well at 80-90 degrees Celsius and has strong resistance to UV radiation – although not as good as ASA, it is still quite strong.
This was designed in SolidWorks, so all my SLDPRT/SLDASM files, as well as all the STLs and gcode, can be found at the end of the original text. You can also use these to print your own version.
Now that the hardware issue is resolved, it’s time to start training the model. Everyone should know that it is best to work on the shoulders of giants. This is the essence of transfer learning – learning from a very large dataset, and then leveraging the knowledge gained from it.
I found many pre-trained license plate models online, but not as many as I initially expected. However, I found one trained on 3600 license plate images. This training set is not large, but it’s better than nothing. Additionally, it was trained based on the pre-trained model from Darknet, so I can use it directly.
Model Address: https://github.com/ThorPham/License-plate-detection
Since I already had a recordable hardware system, I decided to drive around town for a few hours to collect new video frame data to fine-tune the previous model.
I used VOTT to label the frames containing license plates, ultimately creating a small dataset of 534 images, all with labeled bounding boxes for the license plates.
Dataset Address: https://github.com/RobertLucian/license-plate-dataset
Then I found code that implements YOLOv3 using Keras and used it to train my dataset, then submitted my model to this repo so that others could use it. I eventually achieved an mAP of 90% on the test set, which is a great result considering my dataset is very small.
To find a suitable network for text recognition, I went through countless attempts. Finally, I accidentally discovered keras-ocr, which packages CRAFT and CRNN, is very flexible, and has pre-trained models – this is fantastic. I decided not to fine-tune the models and keep them as they are.
keras-ocr Address: https://github.com/faustomorales/keras-ocr
The best part is that predicting text with keras-ocr is very simple. Essentially, it’s just a few lines of code. You can check the project homepage to see how it is done.
Step 5:Deploy my license plate detection model
There are mainly two methods for model deployment:
-
Perform all inference locally;
-
Perform inference in the cloud.
Both methods have their challenges. The first means having a central “brain” computer system, which is complex and expensive. The second faces challenges in terms of latency and infrastructure, especially when using GPUs for inference.
During my research, I stumbled upon an open-source project called cortex. It is new in the AI field, but as the next development direction for AI development tools, it undoubtedly makes sense.
Cortex Project Address: https://github.com/cortexlabs/cortex
Basically, cortex is a platform for deploying machine learning models as production web services. This means I can focus on my application while leaving the rest to cortex to handle. It does all the setup on AWS, and all I need to do is write a few dozen lines of code to define the predictors for each model.
Below is a terminal from the cortex runtime obtained from the GitHub repo. If this isn’t elegant and simple, I don’t know what word to use to describe it:
Since this computer vision system is not designed for autonomous driving, latency is less critical for me, and I can use cortex to address this issue. If it were part of an autonomous driving system, using services provided by cloud providers would not be a good idea, at least not right now.
Deploying ML models with cortex requires:
-
Defining a cortex.yaml file, which is the configuration file for our API. Each API will handle one type of task. I assigned the task for the yolov3 API to detect the bounding boxes for license plates on the given frame, while the crnn API predicts the license plate number with the help of the CRAFT text detector and CRNN;
-
Defining the predictor for each API. Basically, all you need to do is define a predict method for a specific class in cortex to receive a payload (all the server parts are already handled by the platform), which can be used to predict results and then return the predictions. It’s that simple!
Here is an example predictor for the classic iris dataset, but due to the length of the article, I won’t go into the specific details here. You can find how to use these two APIs in the project link – all other resources for this project are at the end of this article.
# predictor.pyimport boto3
import pickle
labels = ["setosa", "versicolor", "virginica"]
class PythonPredictor:
def __init__(self, config):
s3 = boto3.client("s3")
s3.download_file(config["bucket"], config["key"], "model.pkl")
self.model = pickle.load(open("model.pkl", "rb"))
def predict(self, payload):
measurements = [
payload["sepal_length"],
payload["sepal_width"],
payload["petal_length"],
payload["petal_width"],
]
label_id = self.model.predict([measurements])[0]
return labels[label_id]
To make predictions, you just need to use curl like this:
curl http://***.amazonaws.com/iris-classifier \
-X POST -H "Content-Type: application/json" \
-d '{"sepal_length": 5.2, "sepal_width": 3.6, "petal_length": 1.4, "petal_width": 0.3}'
Then you will receive feedback like setosa, very simple!
Step 6:Develop the client
With cortex helping me with deployment, I can start designing the client – this is the more challenging part.
I thought of the following architecture:
-
Collect frames from the Pi Camera at an acceptable resolution (800×450 or 480×270) at 30 FPS and push each frame into a public queue;
-
In a separate process, I will take frames from the queue and distribute them to multiple workstations on different threads;
-
Each worker thread (or what I call inference thread) will make API requests to my cortex API. First, a request to my yolov3 API, then if any license plates are detected, another request will be sent to my crnn API with a batch of cropped license plates. The predicted license plate numbers will be returned in text format;
-
Pushing each detected license plate (with or without recognized text) to another queue, which will ultimately broadcast it to the browser page. At the same time, the predicted license plate numbers will be pushed to another queue to be saved to disk in CSV format later;
-
The broadcast queue will receive a set of unordered frames. The task of the consumer is to first place them in a very small buffer (the size of a few frames), and each time broadcast a new frame to the client for reordering. This consumer runs separately in another process and must also try to keep the queue size fixed to a specified value to display frames at a consistent frame rate. Obviously, if the queue size decreases, the frame rate will decrease proportionally, and vice versa;
-
Meanwhile, another thread will run in the main process, fetching predictions and GPS data from another queue. When the client receives a termination signal, predictions, GPS data, and timestamps will also be stored in a CSV file.
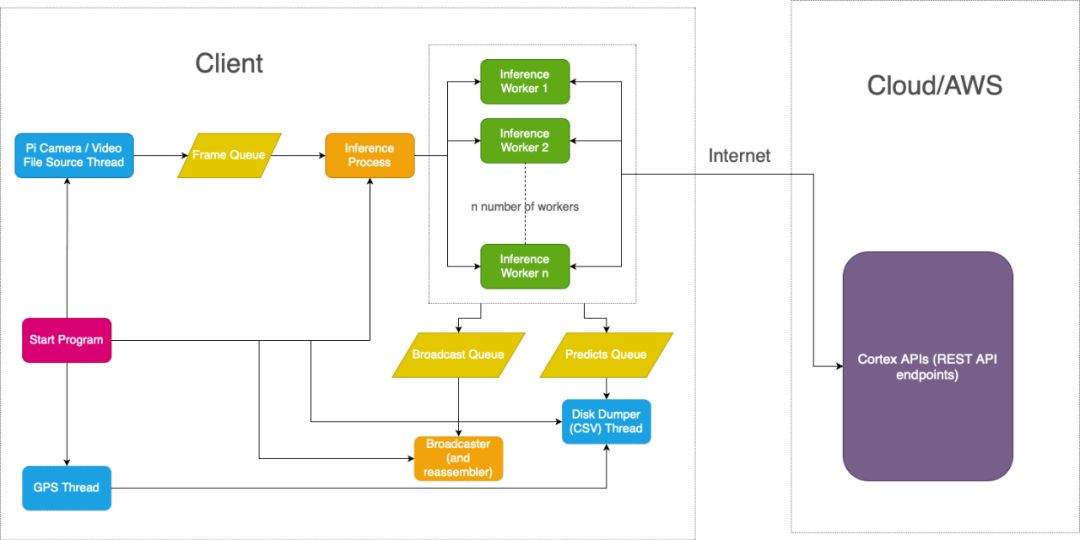
The following diagram shows the relationship flow between the client and the cloud API provided by AWS.
Figure 7:Flowchart of the client based on the cloud API provided by cortex
In our example, the client is the Raspberry Pi, and the inference requests are sent to the cloud API provided by cortex on AWS.
The source code of the client can also be found in its GitHub: https://github.com/robertlucian/cortex-licens-plate-reader-client
One challenge I had to overcome was the bandwidth of 4G. It is best to reduce the bandwidth required for this application to minimize potential hangups or excessive use of available data. I decided to have the Pi Camera use a very low resolution: 480×270 (we can use a small resolution here because the Pi Camera has a very narrow field of view, so we can still easily recognize license plates).
However, even at this resolution, the JPEG size of each frame is about 100KB (0.8MBits). Multiply that by 30 frames per second and you get 3000KB, which is 24mb/s, and this is a lot even without HTTP overhead.
Therefore, I used some tricks:
-
Reduce the width to 416 pixels, which is the size required by the YOLOv3 model, and the scale is obviously intact;
-
Convert the image to grayscale;
-
Remove the top 45% of the image. The idea here is that the license plate will not appear at the top of the frame because cars do not fly, right? As far as I know, removing 45% of the image does not affect the predictor’s performance;
-
Convert the image to JPEG again, but this time the quality is much lower.
The final size of the resulting frames is about 7-10KB, which is very good. This translates to about 2.8Mb/s. But considering all the overhead, it is about 3.5Mb/s. For the crnn API, the cropped license plates do not require much space at all; even without compression, they are only about 2-3KB each.
In summary, to run at 30FPS, the bandwidth required for the inference API is about 6Mb/s, a figure I can accept.
The above is an example of real-time inference using cortex. I need about 20 GPU-equipped instances to run it smoothly. Depending on the latency of this group of GPUs, you might need more GPUs or fewer instances. The average latency from capturing frames to broadcasting them to the browser window is about 0.9 seconds, which is amazing considering the inference happens far away – I am still surprised by it.
The text recognition part may not be the best, but it at least proves one point – it can be made more precise by increasing the video resolution, reducing the camera’s field of view, or fine-tuning.
As for the issue of needing too many GPUs, this can be solved through optimization. For example, using mixed precision/full half precision (FP16/BFP16) in the model. Generally, using mixed precision has a minimal impact on accuracy, so we did not make too many compromises.
In summary, if all optimizations are in place, reducing the number of GPUs from 20 to one is actually feasible. If properly optimized, it is even possible to not use up the resources of a single GPU.
Original Address:https://towardsdatascience.com/i-built-a-diy-license-plate-reader-with-a-raspberry-pi-and-machine-learning-7e428d3c7401
Recommended Reading
▼
 Electronic comic series, updated with nine images.
Electronic comic series, updated with nine images.
 【Strong Content】618 free 3D packaging shares
【Strong Content】618 free 3D packaging shares
 【Second Wave of Content】A large wave of free 3D packaging shares
【Second Wave of Content】A large wave of free 3D packaging shares
 Domestic and foreign brands of chip capacitors
Domestic and foreign brands of chip capacitors
 A summary of domestic and foreign brands of DC-DC power chips
A summary of domestic and foreign brands of DC-DC power chips
 Can a few cents 32768 crystal oscillator write a solid article?
Can a few cents 32768 crystal oscillator write a solid article?
 License plate recognition control board schematic + PCB + 3D complete selfless sharing
License plate recognition control board schematic + PCB + 3D complete selfless sharing
 【Visual Feast】 The other side of electronic components you’ve never seen!
【Visual Feast】 The other side of electronic components you’ve never seen!
 Completely written in C, highly portable, super cool menu architecture!
Completely written in C, highly portable, super cool menu architecture!
 【Video】 Foreigners teach you the effects of energizing transistors and MOSFETs, I don’t believe anyone doesn’t understand!
【Video】 Foreigners teach you the effects of energizing transistors and MOSFETs, I don’t believe anyone doesn’t understand!
Please click the bottom right corner to give me a little attention!