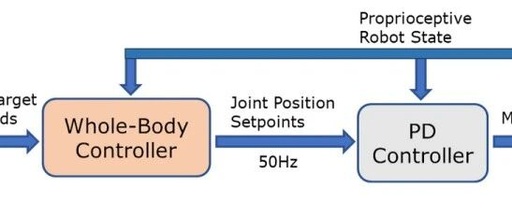
AI Agent Daily Digest 2025-10-15: Comprehensive Insights on Large Models, Papers, Open Source Frameworks, and Industry Trends
Today’s daily report includes today’s popular AI frameworks on GitHub, new models from HuggingFace, industry insights, and several interesting papers selected from arXiv. The main focus of our current era is the condensation of information, and with the overwhelming amount of information available, this daily report provides an overview of the open-source frameworks, models, and … Read more