Detailed Explanation of Smooth Policy Iteration (SPI) Architecture Against Adversarial Reinforcement Learning
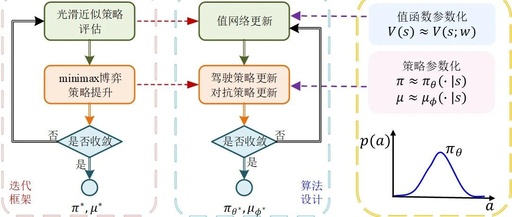
It is well known that the max operator (or min operator) is a core component of the Bellman equation, and its efficient solution runs through various reinforcement learning algorithms, including mainstream Actor-Critic algorithms such as PPO, TRPO, DDPG, DSAC, and DACER. Friends familiar with algorithm design may have a question: why is the max operator … Read more