
The Editor Says: Currently, researchers are using various deep learning frameworks. This article introduces six common deep learning frameworks and discusses the advantages of PyTorch compared to them.
This article is excerpted from “Deep Learning Framework PyTorch: Introduction and Practice”. For more details, please click Read the Original.

-
The Birth of PyTorch
In January 2017, the Facebook AI Research (FAIR) team open-sourced PyTorch on GitHub, quickly taking the top spot on GitHub’s trending list.
As a framework released in 2017 with advanced design concepts, PyTorch’s history can be traced back to 2002 when Torch was born at New York University. Torch used a less common language, Lua, as its interface. Lua is concise and efficient, but due to its niche status, not many people used it, leading many to hesitate at the thought of learning a new language just to master Torch (in fact, Lua is simpler than Python).

Considering Python’s leading position in computational science, as well as its complete ecosystem and ease of use, almost any framework inevitably has to provide a Python interface. Finally, in 2017, the team behind Torch launched PyTorch. PyTorch is not just a simple wrapper around Lua Torch to provide a Python interface, but rather it has restructured all modules on top of Tensors and introduced a state-of-the-art automatic differentiation system, becoming the most popular dynamic graph framework today.
Upon its release, PyTorch immediately garnered widespread attention and quickly became popular in the research community. As shown in Figure 1, the Google Trends index for PyTorch has been continuously rising since its release, surpassing the popularity of the other three frameworks (Caffe, MXNet, and Theano) by October 18, 2017, and its popularity continues to grow.
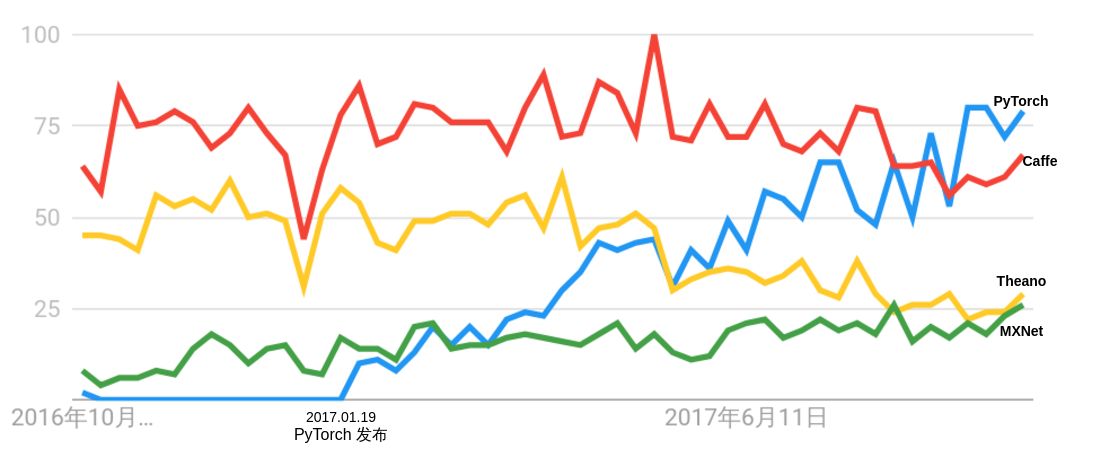
Figure 1 Comparison of Google Trends for PyTorch, Caffe, Theano, and MXNet (Category: Science)
-
Overview of Common Deep Learning Frameworks
With the development of deep learning, various deep learning frameworks have emerged in universities and companies. In particular, in the past two years, giants like Google, Facebook, and Microsoft have heavily invested in a series of emerging projects related to deep learning, and they have also supported some open-source deep learning frameworks.
Currently, researchers are using different deep learning frameworks, including TensorFlow, Caffe, Theano, and Keras, as shown in Figure 2. These frameworks are applied in fields such as computer vision, speech recognition, natural language processing, and bioinformatics, achieving excellent results. This section mainly introduces several influential frameworks in the current deep learning field, and due to the author’s personal experience and understanding, evaluations of each framework may have inaccuracies.

Figure 2 Common Deep Learning Frameworks
1 . Theano
Theano was initially developed at the LISA lab of the University of Montreal and started development in 2008. It is the first influential Python deep learning framework.
Theano is a Python library for defining, optimizing, and computing mathematical expressions, especially for multi-dimensional arrays (numpy.ndarray). When solving problems involving large amounts of data, programming with Theano can achieve faster speeds than hand-written C code, and with GPU acceleration, Theano can even be several orders of magnitude faster than CPU-based C code. Theano combines a computer algebra system (CAS) with an optimizing compiler, and can generate customized C code for various mathematical operations. For tasks involving complex mathematical expressions with repeated calculations, computation speed is crucial, so this combination of CAS and optimizing compiler is very useful. For cases where each different mathematical expression needs to be calculated, Theano can minimize the computation involved in compilation/parsing while still providing symbolic features like automatic differentiation.
Theano was born in a research institution, serving researchers, and its design has a strong academic flavor, but it has significant flaws in engineering design. Theano has long been criticized for difficulties in debugging and slow graph construction. To accelerate deep learning research, several third-party frameworks such as Lasagne, Blocks, PyLearn2, and Keras were developed on its foundation, providing better encapsulated interfaces for user convenience.
On September 28, 2017, just before the official release of Theano 1.0, Yoshua Bengio, one of the three deep learning giants, announced that Theano would cease development: “Theano is Dead.” Although Theano is about to exit the historical stage, as the first Python deep learning framework, it has fulfilled its mission well, providing significant assistance for early pioneers in deep learning research, while also laying the foundational design direction for subsequent deep learning framework development: a computation graph at the core, using GPU-accelerated computing.
In November 2017, the LISA lab launched a beginner’s project on GitHub, aimed at helping newcomers quickly grasp the practical basics of machine learning, using PyTorch as the teaching framework.
Comment: Since Theano has ceased development, it is not recommended as a research tool for continued learning.
2 TensorFlow
On November 10, 2015, Google announced the launch of the new open-source machine learning tool TensorFlow. TensorFlow was initially developed by the Google Brain team, part of Google’s machine intelligence research department, based on the deep learning infrastructure DistBelief developed by Google in 2011. TensorFlow is mainly used for machine learning and deep neural network research, but it is a very basic system, and thus can also be applied in many fields. Due to Google’s significant influence in the field of deep learning and its powerful promotional capabilities, TensorFlow gained immense attention upon its release and quickly became the most widely used deep learning framework today.
TensorFlow can largely be regarded as the successor to Theano, not only because they share a large number of common developers but also because they have similar design philosophies, both based on computation graphs for implementing automatic differentiation systems. TensorFlow uses data flow graphs for numerical computation, where the nodes in the graph represent mathematical operations, and the edges represent the multi-dimensional arrays (tensors) passed between these nodes.
TensorFlow’s programming interface supports Python and C++. With the release of version 1.0, alpha versions of APIs for Java, Go, R, and Haskell were also supported. Additionally, TensorFlow can run on Google Cloud and AWS. TensorFlow also supports Windows 7, Windows 10, and Windows Server 2016. Since TensorFlow uses the C++ Eigen library, the library can be compiled and optimized for ARM architecture. This means users can deploy their trained models on various servers and mobile devices without executing separate model decoders or loading a Python interpreter.
As the most popular deep learning framework today, TensorFlow has achieved great success, but it has also faced numerous criticisms, which can be summarized into four main points.
-
Overly complex system design; the total codebase of TensorFlow on GitHub exceeds 1 million lines. Such a large codebase makes maintenance a daunting task for project maintainers, and for readers, understanding TensorFlow’s underlying operational mechanisms is an extremely painful process, often ending in abandonment.
-
Frequent changes to the interface. TensorFlow’s interface has been in rapid iteration without adequately considering backward compatibility, leading many open-source codes to become incompatible with the new version of TensorFlow, indirectly causing numerous bugs in third-party frameworks based on TensorFlow.
-
Interface design that is overly obscure. In designing TensorFlow, many abstract concepts such as graphs, sessions, namespaces, PlaceHolder, etc., were created, making it difficult for ordinary users to understand. The same functionality has multiple implementations in TensorFlow, with varying quality and subtle differences that can easily lead users astray.
-
Disorganized documentation. As a complex system, TensorFlow has numerous documents and tutorials, but lacks clear organization and hierarchy, making it easy to find resources but difficult for users to locate a truly step-by-step introductory tutorial.
Due to the low productivity of directly using TensorFlow, many developers, including Google itself, have attempted to build more user-friendly interfaces based on TensorFlow, including Keras, Sonnet, TFLearn, TensorLayer, Slim, Fold, and PrettyLayer, among countless others that appear in the news every few months, but most have faded into silence. To this day, TensorFlow still lacks a unified and user-friendly interface.
Thanks to Google’s strong promotional capabilities, TensorFlow has become the hottest deep learning framework today, but due to its inherent flaws, it is still far from its original design goals. Additionally, due to Google’s somewhat strict control over TensorFlow, many companies are developing their own deep learning frameworks.
Comment: Imperfect but the most popular deep learning framework, with a strong community, suitable for production environments.
3 . Keras
Keras is a high-level neural network API, written in pure Python, and uses TensorFlow, Theano, and CNTK as backends. Keras was born to support rapid experimentation, capable of quickly turning ideas into results. Keras is arguably the easiest to use among deep learning frameworks, providing a consistent and concise API that significantly reduces the workload for users in typical applications, avoiding the need to reinvent the wheel.
Strictly speaking, Keras cannot be classified as a deep learning framework; it is more like a deep learning interface built on top of third-party frameworks. The drawbacks of Keras are evident: excessive encapsulation leads to a loss of flexibility. Keras was initially created as a high-level API for Theano, later adding TensorFlow and CNTK as backends. To shield users from backend discrepancies and provide a consistent user interface, Keras has layered encapsulation, making it overly difficult for users to add new operations or access low-level data. Additionally, excessive encapsulation has made Keras programs relatively slow, with many bugs hidden within the encapsulation, making Keras the slowest among all the frameworks discussed in this article in most scenarios.
Learning Keras is straightforward, but users will quickly encounter bottlenecks due to its lack of flexibility. Furthermore, during most of the time using Keras, users primarily call interfaces, making it difficult to genuinely learn deep learning content.
Comment: The easiest to get started with, but not flexible enough, limited in use.
4 . Caffe/Caffe2
Caffe stands for Convolutional Architecture for Fast Feature Embedding. It is a clear and efficient deep learning framework, primarily written in C++, supporting command line, Python, and MATLAB interfaces, and can run on both CPU and GPU.
The advantages of Caffe are its simplicity and speed, while its downside is a lack of flexibility. Unlike Keras, which loses flexibility due to excessive encapsulation, Caffe’s lack of flexibility mainly stems from its design. In Caffe, the main abstract object is the layer; to implement a new layer, one must write the forward and backward propagation code in C++, and if one wants the new layer to run on GPU, they also need to implement the forward and backward propagation in CUDA. This limitation makes it very difficult for users unfamiliar with C++ and CUDA to extend Caffe.
Caffe gained many users due to its ease of use, clear source code, outstanding performance, and rapid prototyping, once occupying half of the deep learning field. However, as the new era of deep learning has arrived, Caffe has shown significant shortcomings, with many problems gradually surfacing (including lack of flexibility, difficulty in extension, numerous dependencies hard to configure, and limited applications). Although many projects based on Caffe can still be found on GitHub, new projects are becoming increasingly rare.
The author of Caffe graduated from the University of California, Berkeley, joined Google to participate in TensorFlow development, and later left Google to join FAIR, where he served as engineering director and developed Caffe2. Caffe2 is an open-source deep learning framework that combines expressiveness, speed, and modularity. It inherits many Caffe designs and aims to resolve bottlenecks discovered during Caffe’s use and deployment over the years. Caffe2’s design pursues lightweight characteristics, emphasizing portability while maintaining extensibility and high performance. The core C++ library of Caffe2 provides speed and portability, while its Python and C++ APIs allow users to easily prototype, train, and deploy on Linux, Windows, iOS, Android, and even Raspberry Pi and NVIDIA Tegra.
Caffe2 inherits the advantages of Caffe and is impressively fast. The Facebook AI lab collaborated with the applied machine learning team to significantly accelerate the model training process for machine vision tasks, completing training on a massive dataset like ImageNet in just one hour. However, despite being released for over six months and developed for more than a year, Caffe2 remains an immature framework, lacking complete documentation on its official website, and installation can be quite troublesome, with the compilation process often encountering exceptions. Relevant code is also rarely found on GitHub.
At its peak, Caffe occupied half of the computer vision research field. Although it is rarely used in academia today, many computer vision-related papers still employ Caffe. Due to its stability and outstanding performance, many companies continue to use Caffe for model deployment. While Caffe2 has made many improvements, it is still far from replacing Caffe.
Comment: Incomplete documentation, but excellent performance, nearly full platform support (Caffe2), suitable for production environments.
5 . MXNet
MXNet is a deep learning library that supports languages including C++, Python, R, Scala, Julia, MATLAB, and JavaScript; it supports both imperative and symbolic programming; and can run on CPU, GPU, clusters, servers, desktops, or mobile devices. MXNet is the next generation of CXXNet, which borrowed ideas from Caffe but is cleaner in implementation. At the 2014 NIPS conference, Tianqi Chen and Mu Li, both alumni of Shanghai Jiao Tong University, met and discussed their respective deep learning toolkit projects, discovering that they were all doing a lot of repetitive work, such as file loading. They decided to form the DMLC (Distributed (Deep) Machine Learning Community) to collaborate on developing MXNet, leveraging each other’s strengths to avoid reinventing the wheel.
MXNet is praised for its strong distributed support and noticeable memory and GPU memory optimization. With the same model, MXNet often occupies less memory and GPU memory, and in distributed environments, MXNet demonstrates significantly better scalability compared to other frameworks.
Due to MXNet’s initial development by a group of students lacking commercial applications, its usage was greatly limited. In November 2016, MXNet was officially chosen by AWS as its official deep learning platform for cloud computing. In January 2017, the MXNet project entered the Apache Foundation, becoming an incubator project of Apache.
Although MXNet has the most interfaces and has garnered considerable support, it has remained in a lukewarm state. I believe this is largely due to insufficient promotion and incomplete interface documentation. MXNet has long been in a rapid iteration process, yet its documentation has not been updated for a long time, making it difficult for new users to master MXNet, while old users often need to consult the source code to truly understand how to use the MXNet interface.
To improve the MXNet ecosystem and promote it, MXNet has launched numerous interfaces including MinPy, Keras, and Gluon, but the first two have essentially ceased development, while Gluon mimics PyTorch’s interface design. MXNet’s author, Mu Li, has even personally taught how to learn deep learning from scratch using Gluon, attracting many new users with sincerity.
Comment: Documentation is somewhat chaotic, but distributed performance is powerful, with the most language support, suitable for use on AWS cloud platform.
6 . CNTK
In August 2015, Microsoft announced the open-sourcing of the Computational Network Toolkit (CNTK), developed by Microsoft Research, on CodePlex. Five months later, on January 25, 2016, Microsoft officially open-sourced CNTK on their GitHub repository. As early as 2014, within Microsoft, Dr. Xuedong Huang and his team were working on improving the ability of computers to understand speech, but the tools they were using at the time were clearly slowing down their progress. Thus, a team of volunteers conceived and designed their own solution, ultimately leading to the birth of CNTK.
According to Microsoft developers, CNTK outperforms mainstream tools such as Caffe, Theano, and TensorFlow. CNTK supports both CPU and GPU modes, and like TensorFlow/Theano, it describes neural networks as a structure of computation graphs, where leaf nodes represent inputs or network parameters, and other nodes represent computation steps. CNTK is a very powerful command-line system capable of creating neural network prediction systems. CNTK was originally developed for internal use at Microsoft, and initially did not even have a Python interface, being developed in a language that is hardly used, and its documentation is somewhat obscure and difficult to understand, leading to relatively few users. However, in terms of the quality of the framework itself, CNTK performs quite well, with no obvious shortcomings, and it is particularly effective in the field of speech.
Comment: The community is not very active, but performance is outstanding, especially in speech-related research.
7 . Other Frameworks
In addition to the aforementioned frameworks, there are many others that have certain influence and user bases. For example, PaddlePaddle, open-sourced by Baidu; DyNet, developed by CMU; tiny-dnn, which is simple and dependency-free, compliant with C++11 standards; Deeplearning4J, developed in Java with extremely good documentation; Intel’s Nervana; and Amazon’s DSSTNE. Each of these frameworks has its own advantages and disadvantages, but most lack popularity and attention or are limited to specific fields. Additionally, many frameworks are specifically developed for mobile devices, such as CoreML and MDL, which are purely designed for deployment and are not universal, nor suitable as research tools.
-
Why Choose PyTorch
With so many deep learning frameworks, why choose PyTorch?
Because PyTorch is a rare framework that is simple, elegant, and efficient. In my opinion, PyTorch reaches the highest level among current deep learning frameworks. Among the open-source frameworks, none can surpass PyTorch in flexibility, ease of use, and speed simultaneously in two out of three aspects. Below are the reasons many researchers choose PyTorch.
① Simplicity: PyTorch’s design aims for minimal encapsulation, avoiding reinventing the wheel as much as possible. Unlike TensorFlow, which is filled with new concepts such as session, graph, operation, name_scope, variable, tensor, layer, etc., PyTorch’s design follows three abstract levels from low to high: tensor → variable (autograd) → nn.Module, representing high-dimensional arrays (tensors), automatic differentiation (variables), and neural networks (layers/modules), respectively. These three abstractions are closely linked, allowing for simultaneous modification and operation.
Another benefit of the simple design is that the code is easy to understand. PyTorch’s source code is only about one-tenth the size of TensorFlow’s, and fewer abstractions and a more intuitive design make PyTorch’s source code much easier to read. In my view, PyTorch’s source code is even easier to understand than the documentation of many frameworks.
② Speed: PyTorch’s flexibility does not come at the cost of speed; in many evaluations, PyTorch outperforms TensorFlow and Keras in speed. The running speed of a framework is greatly related to the programmer’s coding level, but for the same algorithm, the implementation using PyTorch is more likely to be faster than those implemented with other frameworks.
③ Ease of Use: PyTorch is the most elegantly designed framework with object-oriented design. PyTorch’s object-oriented interface design is derived from Torch, which is known for its flexibility and ease of use. The author of Keras was initially inspired by Torch when developing Keras. PyTorch inherits the essence of Torch, especially in API design and module interfaces, which are highly consistent with Torch. PyTorch’s design aligns with people’s thinking, allowing users to focus as much as possible on implementing their ideas—what you think is what you get—without considering too many constraints of the framework itself.
④ Active Community: PyTorch provides complete documentation, step-by-step guides, and forums maintained by the authors for users to communicate and ask questions. The Facebook AI Research lab provides strong support for PyTorch, and as one of the top three deep learning research institutions today, FAIR’s support ensures that PyTorch receives continuous development and updates, preventing it from fading away like many frameworks developed by individuals.
Within less than a year of PyTorch’s launch, various deep learning problems have been solved using PyTorch implementations available on GitHub. Many newly published papers have also adopted PyTorch as the tool for their implementations, and PyTorch is gaining increasing popularity.
If TensorFlow’s design is “Make It Complicated,” and Keras’s design is “Make It Complicated And Hide It,” then PyTorch’s design truly achieves “Keep it Simple, Stupid.” Simplicity is beauty.
Using TensorFlow, one can find a lot of others’ code; using PyTorch, one can easily implement their ideas.

This article is excerpted from“Deep Learning Framework PyTorch: Introduction and Practice”, for more details, please clickRead the Original.



Blog Insights
You are reading a professional think tank
Please share to Moments
For more details about this book, please click Read the Original
Long press the QR code to easily follow

 Click to read the original text, and you can quickly reach the book detail page!
Click to read the original text, and you can quickly reach the book detail page!