
Source: Ma Ge Linux Operations
This article is approximately 8500 words, recommended reading time is 15 minutes. This article mainly explains what the Linux kernel is and showcases its functions and features through multiple images.1. Introduction
This article mainly explains what the Linux kernel is and showcases its functions and features through multiple images to help readers quickly understand what the Linux kernel is and how to comprehend it.
With over 13 million lines of code, the Linux kernel is one of the largest open-source projects in the world, but what exactly is a kernel and what is it used for?
2. What is a Kernel
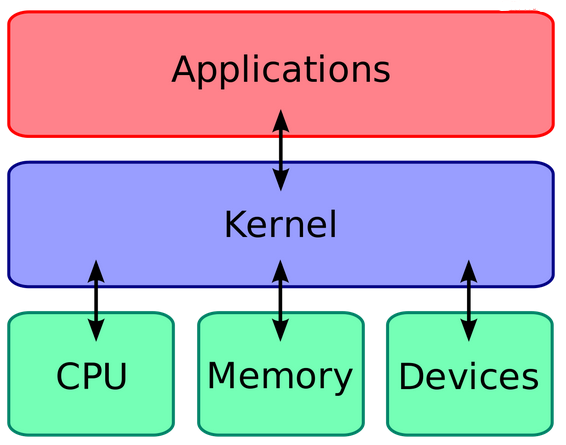
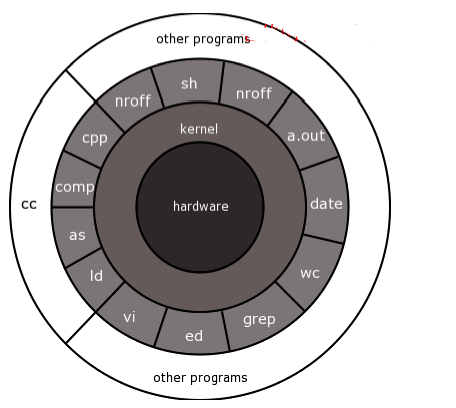
A kernel is the lowest level of easily replaceable software that interfaces with computer hardware. It is responsible for connecting all applications running in “user mode” to the physical hardware and allows processes, known as servers, to communicate with each other using inter-process communication (IPC).
3. Are There Different Types of Kernels?
Yes, that’s correct.
3.1 Microkernel
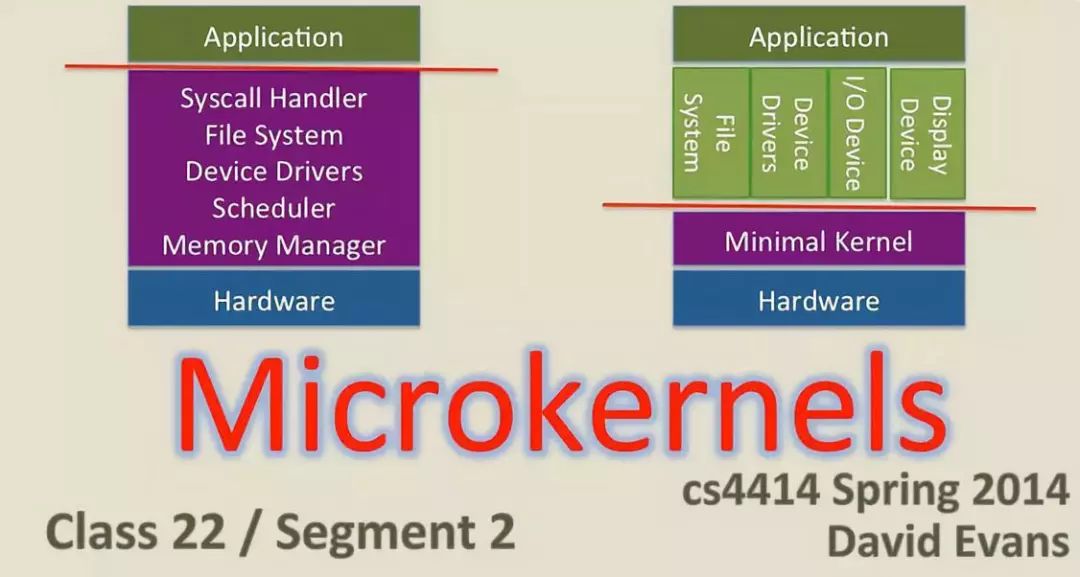
A microkernel only manages what it must manage: CPU, memory, and IPC. Almost everything else in the computer can be considered an attachment and can be handled in user mode. Microkernels have the advantage of portability because as long as the operating system continues to access hardware in the same way, you don’t have to worry about changing your video card or even the operating system.
Microkernels also occupy very little memory and installation space, and they are often more secure because only specific processes run in user mode, which does not have the high privileges of administrator mode.
3.1.1 Pros
-
Portability
-
Small installation space
-
Low memory usage
-
Security
3.1.2 Cons
-
More abstract hardware through drivers
-
Hardware may respond slower because drivers are in user mode
-
Processes must wait in a queue to obtain information
-
Processes cannot access other processes without waiting
3.2 Monolithic Kernel
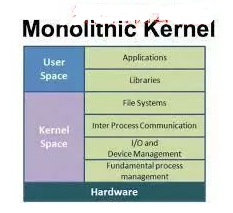
A monolithic kernel, in contrast to a microkernel, includes not just CPU, memory, and IPC, but also device drivers, file system management, and system server calls. Monolithic kernels are better at accessing hardware and multitasking because if a program needs to obtain information from memory or other running processes, it has a more direct line to access that information without waiting in a queue to complete tasks. However, this can lead to problems because the more things that run in management mode, the more things can cause system crashes if they behave abnormally.
3.2.1 Pros
-
More direct access to hardware for programs
-
Easier communication between processes
-
If your device is supported, it should work without additional installation
-
Processes respond faster because there is no queue waiting for processor time
3.2.2 Cons
-
Larger installation size
-
Higher memory usage
-
Less secure because all operations run in management mode

4. Hybrid Kernel
A hybrid kernel can choose what runs in user mode and what runs in management mode. Generally, device drivers and file system I/O will run in user mode, while IPC and server calls will remain in manager mode. This is a win-win situation, but it usually requires more work from hardware manufacturers because they bear the responsibility for all drivers. It may also have some inherent latency issues associated with microkernels.
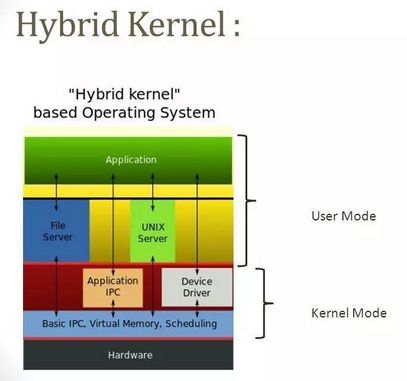
4.1 Pros
-
Developers can choose what runs in user mode and what runs in management mode
-
Smaller installation space compared to monolithic kernels
-
More flexible than other types
4.2 Cons
-
Will suffer from the same process latency as microkernels
-
Device drivers often need to be managed by users
5. Where are Linux Kernel Files Located?
In Ubuntu, kernel files are stored in the /boot folder, named vmlinux-version. The name vmlinuz comes from the Unix world, where in the 1960s, the kernel was simply referred to as “Unix”. So when the kernel was first developed in the 1990s, Linux began to refer to the kernel as “Linux”.

When developing virtual memory to facilitate multitasking, the prefix “vm” was added to the file to indicate that the kernel supports virtual memory. For a time, the Linux kernel was called vmlinux, but as the kernel grew too large to fit into the available boot memory, the kernel image was compressed, and the ending “x” was changed to “z” to indicate that it was compressed with zlib. Not all compressions are the same; LZMA or BZIP2 are often used instead, and some kernels are simply referred to as zImage.
There are also other very important files in the /boot folder, called initrd.img-version, system.map-version, config-version. The initrd file serves as a small RAM disk used to extract and execute the actual kernel file. The system.map file is used for memory management before the kernel is fully loaded, and the config file tells the kernel which options and modules to load when compiling the kernel image.
6. Linux Kernel Architecture
Because the Linux kernel is monolithic, it occupies the most space and has the highest complexity compared to other types of kernels. This is a design feature that caused quite a bit of debate in the early days of Linux and still carries some of the same design flaws inherent in monolithic kernels.
To address these flaws, one thing Linux kernel developers have done is to make kernel modules loadable and unloadable at runtime, meaning you can dynamically add or remove features of the kernel. This can not only add hardware capabilities to the kernel, but also include modules for running server processes, such as low-level virtualization, and can even replace the entire kernel in some cases without needing to reboot the computer.
Imagine if you could upgrade to a Windows service pack without needing to restart…
7. Kernel Modules
What if Windows has all available drivers installed but you only need to enable the ones you need? This is essentially what kernel modules do for Linux. Kernel modules, also known as loadable kernel modules (LKM), are essential for keeping the kernel working with all hardware without consuming all available memory.

Modules typically add functionalities such as devices, file systems, and system calls to the core kernel. The file extension for LKMs is .ko, and they are usually stored in the /lib/modules directory. Due to the nature of modules, you can easily customize the kernel by setting modules to load or not load at boot time using the menuconfig command, editing the /boot/config file, or using the modprobe command to dynamically load and unload modules.
Third-party and closed-source modules are available in some distributions, such as Ubuntu, but they may not be installed by default because the source code for these modules is not available. The developers of the software (e.g., nVidia, ATI, etc.) do not provide the source code, instead building their own modules and compiling the necessary .ko files for distribution. While these modules are free as in beer, they are not free as in speech, and thus are excluded from some distributions because maintainers believe they “pollute” the kernel by providing non-free software.
The kernel is not magical, but it is essential for any normally functioning computer. The Linux kernel differs from OS X and Windows because it contains kernel-level drivers and makes many things “work out of the box”. Hopefully, you will gain a better understanding of how software and hardware work together and the files needed to boot a computer.
8. Summary of Linux Kernel Learning Experiences
Opening
Everyone has their own learning methods when it comes to learning the kernel, and perspectives vary. Below are some things I’ve summarized from my learning process, which I believe are efficient for myself, and I share them for discussion.
In learning the kernel, this is a personal opinion; omissions are inevitable, and I welcome corrections.
Why Write This Blog
When you first start learning the kernel, don’t get fixated on one aspect or focus on one subsystem to the point of diving headfirst into actual lines of code. This can be overwhelming and lead to frustration, as a function body (assuming you’re learning a specific function of a subsystem) may contain design ideas from many other subsystems (usually a lot of related data structures or global variables supporting the management of that subsystem) in the corresponding code implementation. At that moment, seeing these things can be confusing and hard to understand, leading to many questions.
(If you get entangled in these questions and dig too deep, you will often find yourself frequently crossing into other subsystems while learning the current subsystem, leading to a scattered focus). In fact, once you understand the various subsystems, going back to look at these things will be much simpler, and your thought process will be clearer. Therefore, avoid “only seeing the trees and not the forest”; don’t rush into the low-level code too soon, and don’t study the low-level code too early.
I made this mistake when I first encountered the kernel in my sophomore year, diving into memory management to look at very low-level implementation code. Although it was based on the design ideas of memory management, it was relatively isolated because I had not learned other subsystems yet. I would say my perspective and thinking were quite narrow, so I skipped over the implementations of other subsystems involved in the code. This was somewhat clever, but also unavoidable.
My Learning Method
At the beginning, I believed the main issue was whether you knew or not, rather than whether you understood or not. When a subsystem implements a certain strategy or method, what you need to do in your learning is to know that it exists, and then understand the described strategy or method.
Based on my learning experience, when starting to learn the kernel, I think what you need to do is establish a general framework of the kernel in your mind, understanding the design concepts and construction ideas of each subsystem. These concepts and ideas will present a clear outline from a macro perspective, much like the main trunk of a tree stripped of branches and leaves; it becomes clear at a glance.
Of course, it will certainly involve specific implementation methods and functions, but the functions or methods you encounter at this time are at a higher level of kernel implementation, being major functions. By understanding these functions, you will know which design ideas they are targeting, what kind of functionalities they implement, and what purposes they achieve. The saying “familiarity breeds contempt” applies here as well.
As for the auxiliary functions called by the main function, they are like branches and leaves, and there is no need to delve into them too early. At this time, you will have initially established the connection between the framework of the kernel subsystems and the code implementations. The connection is quite simple; for instance, upon seeing a function name, you can recall which subsystem it pertains to and what functionality it implements.
I believe that at this stage, you should read LKD3. This book is quite general and mainly describes the concepts, designs, and major implementation methods of each subsystem, while it touches very little on the specific code implementations of relevant functions (compared to ULK3, which focuses on in-depth analysis of specific function codes). Of course, you can read it, but reading this book too early can feel painful and tedious, as it mainly consists of function implementations. It has little, but not none, which is great as it meets our current needs while avoiding an early dive into actual code.
Moreover, this book provides some programming tips at important points, serving as guiding advice. The main subsystems include: memory management, process management and scheduling, system calls, interrupts and exceptions, kernel synchronization, time and timer management, virtual file systems, block I/O layers, devices, and modules. (The order of these is essentially the order of the LKD3 directory).
When I was learning, I read three books in parallel: first LKD3, focusing on one subsystem, mainly to understand the principles and ideas of the design. Of course, I also encountered introductions to some major functions, but mostly, the book does not delve deeply into the implementation of the functions themselves. Then I looked at ULK3 and PLKA for the same subsystem, but did not analyze the low-level specific function codes in detail, just skimming through them without seeking deep understanding.
Sometimes, when I got stuck on a certain point in one book, I would find a different angle of description of the same problem in another book, and sometimes a single sentence would provide clarity, like a sudden realization. I often encountered such situations.
This does not mean that during the learning process, one completely ignores the implementation of some function bodies; if you really want to thoroughly understand the code implementation, no one will stop you. I gradually delved deeper through repeated readings. For example, in VFS, when opening a file, it requires analyzing the path, and there are many details to consider (like .././ etc.), but its code implementation is easy to understand.
Similarly, in CFS scheduling, calculating the time slice allocated to a process based on schedule latency, the number of processes in the queue, and their nice values (using dynamic priority) is too important to overlook.
ULK3 will also provide general introductions to design principles and ideas, mostly located in the introductory paragraphs of each theme. However, more detailed analysis of the main function implementations supporting these principles and ideas is presented, often summarized in the first paragraph, with explanations of the function implementations in steps.
I selectively read, sometimes cross-referencing with the source code opened in Source Insight to confirm that the code is generally implemented according to the steps described in the book, which serves to enhance my intuitive understanding. Since the steps often involve various safety and effectiveness checks for different implementation purposes, if I do not understand, I skip over them. This does not hinder my overall grasp of the function body’s functionality.
PLKA lies between LKD3 and ULK3. I believe the author of PLKA (who appears to be a handsome German guy with excellent skills) must have read ULK. Regardless of his intention or otherwise, PLKA is somewhat different from ULK, providing supplementary explanations for the detailed function explanations, eliminating edge cases in the function body, such as special case handling, effectiveness checks, etc., while not hindering the understanding of the overall function. The authors even emphasize different aspects of the same major function’s explanation.
This, in turn, helps us learners deepen our understanding. Additionally, an important point is that PLKA targets the 2.6.24 kernel version, while ULK is 2.6.11 and LKD3 is 2.6.34. In some aspects, PLKA is closer to modern implementations. The reason the authors chose either 11 or 24 is that these two versions made significant changes in certain aspects or represent landmark turning points (this information is mostly introduced in the preface of the books, but I can’t recall the specific details).
Intel V3, targeted at X86 CPUs, is naturally an authoritative book on system programming. The kernel implementations can find their roots in this book. Therefore, when reading the above three books on a certain subsystem, don’t forget to look for foundational supporting information in the corresponding chapters of V3.
During the reading process, many questions will arise, which is certain. From big questions about design ideas to small questions about the purpose of a specific line of code. Various aspects and questions can all be recorded (however, I did not do so; I did not record all questions, only a few key ones). I am sure there will be many questions; otherwise, kernel-related forums would have long been closed.
In fact, most of the questions (many of which are about whether you know something exists) can be easily solved as long as you are willing to look back. Reading a book a hundred times reveals its meaning. Looking back several times and understanding the connections between different chapters is not a problem. I have done this as well, reading certain subsystems several times, experiencing it firsthand.
When you learn these subsystems in order, earlier chapters may reference later ones, as the author of PLKA mentioned, it is impossible to have no backward references. What they can do is to minimize these references without compromising your understanding of the current issue.
If you don’t understand something, it’s fine; just skip it. The later chapters will also have references to earlier ones, but this issue is simpler; you can go back and review the corresponding introductions, and what you didn’t understand at the time may be clearer now in terms of its design purpose and specific application. Not seeking deep understanding is only temporary.
For example, the interaction and references between various subsystems in the kernel are manifested in the code through interleaved function calls. For instance, when you learned memory allocation and deallocation functions in the memory management chapter, and you understood memory beforehand, when studying drivers or modules, you will encounter calls to these functions, making it easier to accept and not feel lost. Similarly, if you understand the management of system time and timers, revisiting the implementation of bottom halves in interrupts and exceptions will deepen your understanding.
Subsystem management requires a lot of data structures. One way subsystems interact is through pointers in their main data structures referencing each other. During the learning process, when a reference book explains a certain subsystem, it will explain the purpose of the main members in the data structure, but it certainly won’t cover everything (in cases where there are many members, like task_struct), and references based on a certain functionality of other subsystems may or may not be explained, and sometimes it may mention where this variable will be further explained.
Therefore, don’t get hung up on a point you don’t understand; let it go for now, and you can revisit it later. The connections can be established after you have a certain understanding of each subsystem. In fact, I still emphasize the importance of first understanding concepts and frameworks.
Once we have established this framework, we can choose a subsystem of interest, such as drivers, networking, or file systems. At this point, when you delve into the low-level code implementation, it will be much easier compared to starting with the code. Moreover, if you encounter something unclear or forget about an aspect of the implementation, you can find the corresponding subsystem, as you know where to look, making it easier to fill in the gaps. This is when the opportunity for integrating and reviewing previous content arises.
“Understanding the Linux Virtual Memory” (2.4 kernel version), LDD3, “Understanding the Linux Network Technology Inside”, almost every subsystem requires a book’s capacity for explanation. Therefore, when starting to learn, it is not advisable to delve too deeply into a certain module. Once you have a grasp of the various subsystems, you can then focus on learning a specific subsystem. At this point, the references to other systems will no longer feel overwhelming or complex and will make sense.
For example, the chapters listed in LDD3: constructing and running modules, concurrency and race conditions, timing, delays and deferred operations, memory allocation, interrupt handling, etc., all belong to the supporting subsystems for driver development. While this book dedicates a chapter to each of these subsystems, the level of detail cannot compare to PLKA, ULK3, and LKD3. After reading these three books, you will find that reading the relevant chapters in LDD3 feels as easy as drinking plain water; it becomes very casual, as the explanations in LDD3 are much more superficial compared to LKD3.
Having built a solid foundation, understanding PCI, USB, TTY drivers, block device drivers, and network card drivers becomes more targeted in terms of what needs to be learned. These subsystems belong to general subsystems, and after understanding them, the development of subsystems based on these subsystems—drivers (which need to be further tailored to hardware characteristics) and networking (which requires further understanding of various protocols)—will relatively lower the learning difficulty, speed up the learning process, and greatly improve learning efficiency. Easier said than done.
The prerequisite for achieving this effect is: you must calm down, read seriously, and be able to engage with the material. PLKA and ULK3 are thick as bricks, intimidating at first glance. Without interest, enthusiasm, and perseverance, it is impossible to succeed, as it requires time—quite a bit of time. I am not saying that you must have a solid foundation before engaging in driver development; I am merely stating that doing so will make the development process easier, more efficient, and will enhance your ability to handle kernel code. This is just my personal view and learning method, for reference only.
Language
PLKA was written by a German in German, later translated into English and then from English into Chinese. I couldn’t find its physical English version in online bookstores, so I bought the Chinese version. ULK3 and LKD3 are both in English. The writing of these experts is concise and easy to understand; reading the original version poses no problem for programmers learning computer programming, and it is best to experience it in its original form.
If a book is indeed well translated, we can read the Chinese version, as learning in our mother tongue will speed up comprehension and learning progress. When reading in English, there is no need to think about translating it into Chinese.
Thoughts on APIs
“Being an expert in a specific field is less important than knowing the significance of the technology you are using. Knowing a specific API call is of little benefit; just look it up when you need it.” This sentence comes from a blog I read that was translated. I want to emphasize that this statement is quite fitting for application programming, but kernel APIs are not entirely the same.
The kernel is quite complex and learning it is not easy. However, as you reach a certain level, you will find that if you intend to write kernel code, the focus will still be on API interfaces. Most of these APIs are cross-platform, satisfying portability. Kernel hackers have largely standardized and documented these interfaces; what you need to do is simply call them.
Of course, when using them, it is best to be well-versed in the topic of portability in kernel coding conventions to write portable code. Just like application programs, you can use the dynamic library APIs provided by developers or open-source APIs. While both involve calling APIs, the difference lies in that using kernel APIs requires much more understanding than application APIs.
When you understand the implementation of operating systems—which provides foundational support for applications—then when you write applications, using multithreading, timers, synchronization locks, etc., while using shared library APIs, you can relate these to the operating system, integrating the documentation of that API with the corresponding support implementations in the kernel. This will guide you in choosing which API interface to use, selecting the most efficient implementation. Having a good understanding of system programming is beneficial for application programming, and can even be said to be greatly beneficial.
The Essence of Design Implementation: Knowing or Understanding
An operating system serves as an interface between underlying hardware and application software, and the implementation of its subsystems largely depends on hardware characteristics. When books describe the design and implementation of these subsystems, we read them and know them, but if we consider why the overall architecture is organized this way, or why local functions follow these processing steps, it’s not just about knowing; it’s about understanding. If you know that a certain functionality is implemented because that’s how the chip is designed and the CPU operates, then your questions will largely be resolved.
Delving deeper leads us to the design and implementation of chip architecture, which for programmers, whether system or application programmers, is a solid exploration, as this knowledge is quite hard.
For example, the implementation of interrupts and exceptions explained in ULK3 can be traced back to the design of Intel’s x86 series. Looking up the corresponding chapters in the Intel V3 manual can provide annotations for the code implementation described in ULK3. The same applies to time and timer management, where sufficient information can be obtained from the Intel V3 introduction to APIC. Operating systems are defined based on these hardware characteristics.
Once again, it’s not a question of understanding; it’s a question of knowing. Sometimes, knowing leads to understanding. Throughout the learning process, it’s a cycle of knowing, understanding, knowing, understanding, and so on.
Why does the beginning and end focus on knowing, while understanding is merely a step in between? Everything in the world has its own laws; humanity merely discovers them. Practice is primary, and practice is the process of knowing. Experience is the outcome of practice, and the summary of experience leads to theory; theory arises from practice, and only theory needs understanding. In learning the kernel, deep exploration ultimately brings us back to the chip, which is material, and its functionality is based on the physical and electronic characteristics inherent in nature. Tracing back to the source is what this is all about.
Hands-On Coding
What you gain from books is always shallow; true understanding requires hands-on practice. Just reading is absolutely insufficient; you must combine the programming advice given in the textbooks with your own coding. Start by testing in module form or compiling a development version of the kernel. With one machine, using UML debugging allows you to see where the kernel control is at each step, and single-step debugging to observe the execution process is much more intuitive than the explanations in the book. You must engage in actual operation.
Reference Books
When authors write books, they organize content based on their own understanding, viewing a theme from their own perspective, and their focus greatly relates to their personal experience. The timing of publication varies, and later authors aiming to write on the same theme and avoid clichés ideally need to find their own entry points to explain related issues, which justifies the publication of their book; uniformity devalues the work, making it less valuable.
Trusting books too much is worse than having no books at all.
http://lwn.net/Articles/161190/This is an introduction to ULK3, and I believe the key sentences within can position this book:
This description of the book is very accurate. Based on this, as guiding principles, we can use it efficiently.
When looking at a technical book, the preface is definitely the first section to skim through, followed by the table of contents. I find that during the reading process, I frequently check the table of contents, even enjoying looking at it.
