For more content, you can join the Linux system knowledge base package (tutorials + videos + Q&A).
Table of Contents
1. Download rknn-llm and DeepSeek model
2. Install RKLLM-Toolkit
2.1 Install miniforge3 tool
2.2 Download miniforge3 installation package
2.3 Install miniforge3
3. Create RKLLM-Toolkit Conda environment
3.1 Enter Conda base environment
3.2 Create a Conda environment named RKLLM-Toolkit with Python 3.8 version (recommended version)
3.3 Enter RKLLM-Toolkit Conda environment
4. Install RKLLM-Toolkit
5. Convert DeepSeek-R1-1.5B from HuggingFace to RKLLM model
6. Run demo on RK3588
7. Recommended development boards
Consolidate, share, and grow, so that both you and others can gain something! 😄
• ubuntu20.04• python3.8• RK3588 development board
1. Download rknn-llm and DeepSeek model
-
RKNN Model Download:
You can obtain the relevant RKNN models from the official Rockchip website. RKNN is a cross-platform neural network inference engine that can run on Rockchip SoCs.
- The download method is usually through tools provided by GitHub or official RKNN channels for downloading and converting.
-
DeepSeek Model Download:
- DeepSeek is a deep learning model. If it has a public HuggingFace model, you can download it directly through the API provided by HuggingFace.
- If there is no public model file, you may need to contact the corresponding developer or company to obtain the model file.
git clone https://github.com/airockchip/rknn-llm.git
git clone https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
Place the rknn-llm files in the following directory Place the DeepSeek model in the examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo directory
Place the DeepSeek model in the examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo directory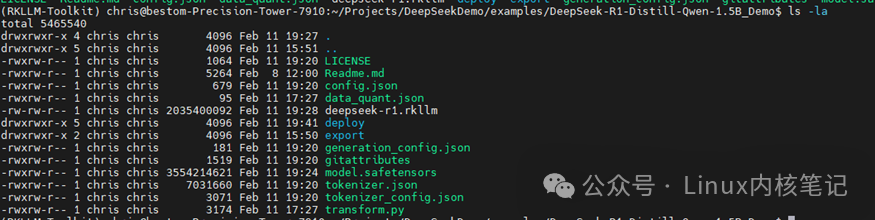
2. Install RKLLM-Toolkit
To run model inference on the RK3588 development board, we need to install RKLLM-Toolkit. This toolkit includes optimization, inference, and deployment tools for RKNN models.
2.1 Install miniforge3 tool
Miniforge3 is a lightweight distribution of Conda designed to simplify Python environment and dependency management. Before installing RKLLM-Toolkit, we need to first install Miniforge3.
conda -V
# If it prompts conda: command not found, it means conda is not installed
# If it prompts, for example, version conda 23.9.0
2.2 Download miniforge3 installation package
Download the appropriate Miniforge3 installation package based on the operating system, for example:
wget -c https://github.com/condaforge/miniforge/releases/latest/download/Miniforge3-Linux-x86_64.sh
2.3 Install miniforge3
chmod 777 Miniforge3-Linux-x86_64.sh
./Miniforge3-Linux-x86_64.sh
3. Create RKLLM-Toolkit Conda environment
To manage dependencies and environments related to RKLLM-Toolkit, we need to create a new Conda environment.
3.1 Enter Conda base environment
Ensure that Conda is correctly installed and initialized. You can activate the Conda environment with the following command:
source ~/miniforge3/bin/activate
# (base) xxx@xxx-pc:~$
3.2 Create a Conda environment named RKLLM-Toolkit with Python 3.8 version (recommended version)
It is recommended to use Python 3.8 version to create the environment, as RKLLM-Toolkit is best compatible with this version. Create a new Conda environment named <span>RKLLM-Toolkit</span>:
conda create -n RKLLM-Toolkit python=3.8
3.3 Enter RKLLM-Toolkit Conda environment
Once you enter the Conda environment, you can start installing dependencies and toolkits related to RKLLM-Toolkit.
conda activate RKLLM-Toolkit
# (RKLLM-Toolkit) xxx@xxx-pc:~$
4. Install RKLLM-Toolkit
In the RKLLM-Toolkit Conda environment, use the pip tool to directly install the provided toolchain whl package. During the installation process, the installation tool will automatically download the relevant dependencies required by RKLLM-Toolkit.
The whl file specifies the file path from the previously downloaded rknn-llm.

pip3 install 1.1.4/rkllm-1.1.4/rkllm-toolkit/packages/rkllm_toolkit-1.1.4-cp38-
cp38-linux_x86_64.whl
If the following command executes without error, the installation is successful.
(RKLLM-Toolkit) xxx@sys2206:~/temp/SDK$ python
Python 3.8.20| packaged by conda-forge |(default, Sep 302024,17:52:49)
[GCC 13.3.0] on linux
Type "help","copyright","credits" or "license" for more information.
>>> from rkllm.api import RKLLM
INFO: Note: NumExpr detected 64 cores but "NUMEXPR_MAX_THREADS" not set, so enforcing safe limit of 8.
INFO: NumExpr defaulting to 8 threads.
>>>

5. Convert DeepSeek-R1-1.5B from HuggingFace to RKLLM model
5.1 ScriptConverting the DeepSeek-R1-1.5B model from HuggingFace to a format supported by RKLLM is the core step of the entire process. The RKNN tool supports ONNX format models, so we need to convert the PyTorch model from HuggingFace to ONNX format, and then use the RKNN tool for conversion.Write the conversion script transform.py and save it in the DeepSeek-R1-Distill-Qwen-1.5B directory.
from rkllm.api import RKLLM
from datasets import load_dataset
from transformers import AutoTokenizer
from tqdm import tqdm
import torch
from torch import nn
import os
# os.environ['CUDA_VISIBLE_DEVICES']='1'
modelpath ='.'
llm =RKLLM()
# Load model
# Use 'export CUDA_VISIBLE_DEVICES=2' to specify GPU device
# options ['cpu', 'cuda']
ret = llm.load_huggingface(model=modelpath, model_lora = None, device='cpu')
# ret = llm.load_gguf(model = modelpath)
if ret !=0:
print('Load model failed!')
exit(ret)
# Build model
dataset ="./data_quant.json"
# Json file format, please note to add prompt in the input,like this:
# [{"input":"Human: 你好!\nAssistant: ","target":"你好!我是人工智能助手KK!"},...]
qparams = None
# qparams = 'gdq.qparams' # Use extra_qparams
ret = llm.build(do_quantization=True, optimization_level=1, quantized_dtype='w8a8',
quantized_algorithm='normal', target_platform='rk3588', num_npu_core=3, extra_qparams=qparams, dataset=dataset)
#if ret !=0:
# print('Build model failed!')
# exit(ret)
# Evaluate Accuracy
def eval_wikitext(llm):
seqlen =512
tokenizer = AutoTokenizer.from_pretrained(
modelpath, trust_remote_code=True)
# Dataset download link:
# https://huggingface.co/datasets/Salesforce/wikitext/tree/main/wikitext-2-raw-v1
testenc =load_dataset(
"parquet", data_files='./wikitext/wikitext-2-raw-1/test-00000-of-00001.parquet', split='train')
testenc =tokenizer("\n\n".join(
testenc['text']), return_tensors="pt").input_ids
nsamples = testenc.numel()// seqlen
nlls =[]
for i in tqdm(range(nsamples), desc="eval_wikitext: "):
batch = testenc[:,(i * seqlen):((i +1)* seqlen)]
inputs ={"input_ids": batch}
lm_logits = llm.get_logits(inputs)
if lm_logits is None:
print("get logits failed!")
return
shift_logits = lm_logits[:,:-1,:]
shift_labels = batch[:,1:].to(lm_logits.device)
loss_fct = nn.CrossEntropyLoss().to(lm_logits.device)
loss =loss_fct(
shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
neg_log_likelihood = loss.float()* seqlen
nlls.append(neg_log_likelihood)
ppl = torch.exp(torch.stack(nlls).sum()/(nsamples * seqlen))
print(f'wikitext-2-raw-1-test ppl:{round(ppl.item(),2)}')
# eval_wikitext(llm)
# Chat with model
messages ="<|im_start|>system You are a helpful assistant.<|im_end|><|im_start|>user你好!\n<|im_end|><|im_start|>assistant"
kwargs ={"max_length":128,"top_k":1,"top_p":0.8,
"temperature":0.8,"do_sample": True,"repetition_penalty":1.1}
# print(llm.chat_model(messages, kwargs))
# Export rkllm model
ret = llm.export_rkllm("./deepseek-r1.rkllm")
if ret !=0:
print('Export model failed!')
exit(ret)
- Write the quantization calibration dataset data_quant.json and save it in the DeepSeek-R1-Distill-Qwen-1.5B directory
[{"input":"Human: 你好!\nAssistant: ", "target": "你好!我是人工智能助手!"}]
5.2 Script Analysis
- Import required modules and initialize
from rkllm.api import RKLLM
from datasets import load_dataset
from transformers import AutoTokenizer
from tqdm import tqdm
import torch
from torch import nn
import os
# os.environ['CUDA_VISIBLE_DEVICES']='1'
- rkllm.api: Used to load and operate RKLLM (Rockchip Large Language Model).
- datasets: Used to load datasets, in this code used to load the Wikitext dataset.
- transformers: Used to load HuggingFace’s pre-trained models and tokenizers.
- torch: PyTorch library, used for training and inference of deep learning models.
- tqdm: Used to display progress bars.
- os: Operating system-related module, commented out the setting of the CUDA_VISIBLE_DEVICES variable, which is intended to set the GPU device.
- Load model
modelpath = '.'
llm = RKLLM()
# Load model
ret = llm.load_huggingface(model=modelpath, model_lora=None, device='cpu')
if ret != 0:
print('Load model failed!')
exit(ret)
- RKLLM(): Creates an RKLLM instance for loading and operating the model.
- load_huggingface: This function loads a pre-trained model from HuggingFace. The modelpath passed indicates the model path, which can be a local directory or a HuggingFace model path.
- model_lora=None: No LoRA (Low-Rank Adaptation) is used to fine-tune the model here; if there is a LoRA model, its path can be passed.
- device=’cpu’: Specifies the device as CPU; if there is a GPU device, it can be set to ‘cuda’, and the CUDA_VISIBLE_DEVICES environment variable can be set to specify which GPU to use.
- Build model
dataset = "./data_quant.json"
qparams = None
ret = llm.build(do_quantization=True, optimization_level=1, quantized_dtype='w8a8',
quantized_algorithm='normal', target_platform='rk3588', num_npu_core=3, extra_qparams=qparams, dataset=dataset)
if ret != 0:
print('Build model failed!')
exit(ret)
-
dataset: Specifies the path to the JSON file used for quantization. This JSON file should contain training data and needs to provide the appropriate format (including input and target output).
-
build: This function is used to build the model and perform quantization (do_quantization=True). It includes:
- do_quantization=True: Perform quantization.
- optimization_level=1: Optimization level, the higher the number, the stronger the optimization effect.
- quantized_dtype=’w8a8′: Quantized data type, indicating 8-bit weights and activations.
- quantized_algorithm=’normal’: Quantization algorithm, here the standard quantization algorithm is used.
- target_platform=’rk3588′: The target platform is RK3588 (Rockchip’s high-performance SoC).
- num_npu_core=3: Use 3 NPU cores for acceleration.
- extra_qparams=qparams: Optional additional quantization parameters, which can be passed if needed (here it is None).
- dataset=dataset: The training dataset used for quantization.
During the build process, the model will be quantized and optimized for the target platform (such as RK3588).
5.3 Run the script
- Run the transfer script transform.py
(RKLLM-Toolkit) chris@bestom-Precision-Tower-7910:~/Projects/DeepSeekDemo/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo$ python transform.py
INFO: rkllm-toolkit version:1.1.4
The argument `trust_remote_code` is to be used with Auto classes. It has no effect here and is ignored.
Downloading data files:100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████|1/1[00:00<00:00,7157.52it/s]
Extracting data files:100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████|1/1[00:00<00:00,57.08it/s]
Generating train split:1 examples [00:00,2.34 examples/s]
Optimizing model:100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████|28/28[00:40<00:00,1.44s/it]
Building model:100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████|399/399[00:13<00:00,30.41it/s]
WARNING: The bos token has two ids:151646 and 151643, please ensure that the bos token ids in config.json and tokenizer_config.json are consistent!
INFO: The token_id of bos is set to 151646
INFO: The token_id of eos is set to 151643
INFO: The token_id of pad is set to 151643
Converting model:100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████|339/339[00:00<00:00,584169.70it/s]
INFO: Exporting the model, please wait ....
[=================================================>]597/597(100%)
INFO: Model has been saved to ./deepseek-r1.rkllm!
(RKLLM-Toolkit) chris@bestom-Precision-Tower-7910:~/Projects/DeepSeekDemo/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo$

6. Run demo on RK3588
Use DeepSeek-R1-Distill-Qwen-1.5B_Demo for testing and verification• DeepSeek-R1-Distill-Qwen-1.5B_Demo code pathcd examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy• Translate DeepSeek-R1-Distill-Qwen-1.5B_Demo
Here, taking the compilation of the Linux version as an example, download and install the cross-compilation tools required for compilation:<span>gcc-arm-10.2-2020.11-x86_64-aarch64-none-linux-gnu</span>
https://developer.arm.com/downloads/-/gnu-a/10-2-2020-11
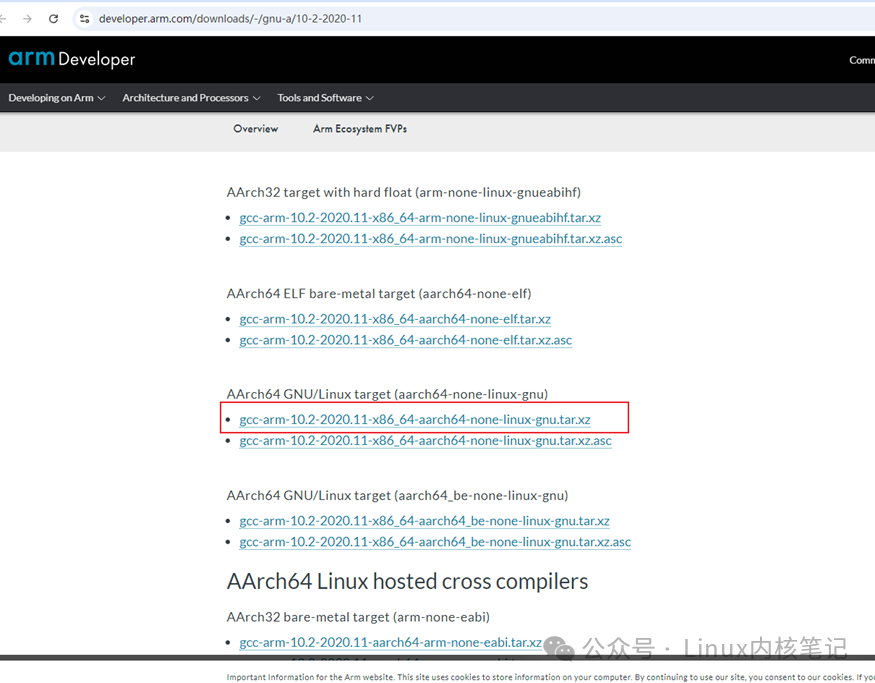
tar -xf gcc-arm-10.2-2020.11-x86_64-aarch64-none-linux-gnu.tar.xz
Modify the compilation script to specify the path of the cross-compilation tools
vi build-linux.sh
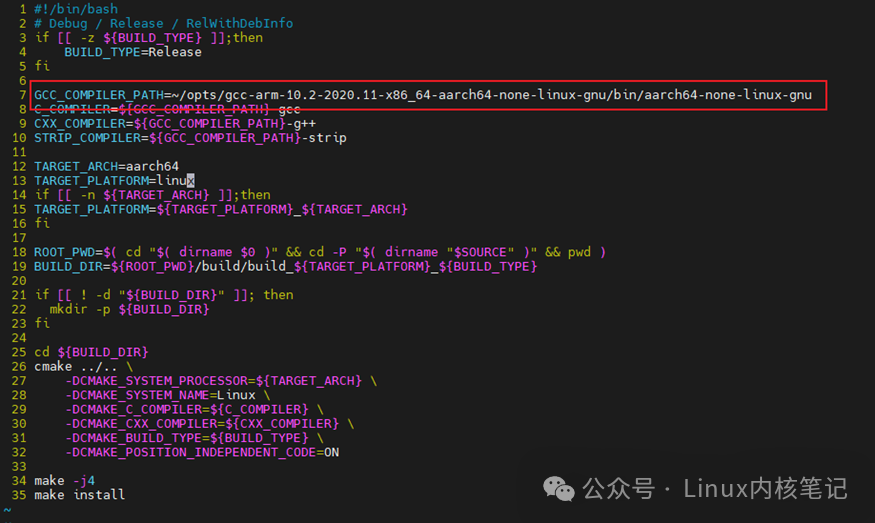 Execute build-linux.sh to start compilation
Execute build-linux.sh to start compilation
(RKLLM-Toolkit) chris@bestom-Precision-Tower-7910:~/Projects/DeepSeekDemo/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy$ ./build-linux.sh
-- The C compiler identification is GNU 10.2.1
-- The CXX compiler identification is GNU 10.2.1
-- Check for working C compiler:/home/chris/opts/gcc-arm-10.2-2020.11-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu-gcc
-- Check for working C compiler:/home/chris/opts/gcc-arm-10.2-2020.11-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu-gcc -- works
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Detecting C compile features
-- Detecting C compile features - done
-- Check for working CXX compiler:/home/chris/opts/gcc-arm-10.2-2020.11-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu-g++
-- Check for working CXX compiler:/home/chris/opts/gcc-arm-10.2-2020.11-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu-g++-- works
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Configuring done
-- Generating done
-- Build files have been written to:/home/chris/Projects/DeepSeekDemo/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy/build/build_linux_aarch64_Release
Scanning dependencies of target llm_demo
[50%] Building CXX object CMakeFiles/llm_demo.dir/src/llm_demo.cpp.o
[100%] Linking CXX executable llm_demo
[100%] Built target llm_demo
[100%] Built target llm_demo
Install the project...
-- Install configuration:"Release"
-- Installing:/home/chris/Projects/DeepSeekDemo/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy/install/demo_Linux_aarch64/./llm_demo
-- Set runtime path of "/home/chris/Projects/DeepSeekDemo/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy/install/demo_Linux_aarch64/./llm_demo" to ""
-- Installing:/home/chris/Projects/DeepSeekDemo/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy/install/demo_Linux_aarch64/lib/librkllmrt.so
Package the compiled files for easy pushing to the device
(RKLLM-Toolkit) chris@bestom-Precision-Tower-7910:~/Projects/DeepSeekDemo/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy$ tar -zcvf install/demo_Linux_aarch64.tar.gz install/demo_Linux_aarch64/
• Run llm_demo
# push deepseek-r1.rkllm to device
C:\Users\king>adb push E:\lhj_files\deepSeekDemo\deepseek-r1.rkllm data/
# push install dir to device
C:\Users\king>adb push E:\lhj_files\deepSeekDemo\demo_Linux_aarch64.tar.gz data/
# Unzip the demo
C:\Users\king>adb shell
root@linaro-alip:/# cd data
root@linaro-alip:/data# tar -zxvf demo_Linux_aarch64.tar.gz
root@linaro-alip:/data# cd install/demo_Linux_aarch64/
# Run Demo
root@linaro-alip:/data/install/demo_Linux_aarch64# export LD_LIBRARY_PATH=./lib
root@linaro-alip:/data/install/demo_Linux_aarch64# taskset f0 ./llm_demo /data/deepseek-r1.rkllm 20484096
# Running result
rkllm init start
rkllm init success
Start using DeepSeek~~~~~~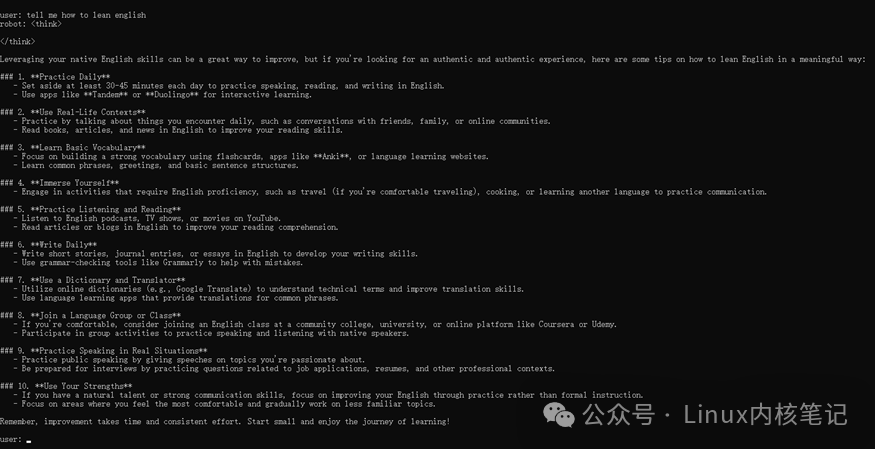
7. Recommended development boards
Development board official website: http://www.bestom.net/