
New Intelligence Report
Editor: Peach Very Sleepy
[New Intelligence Guide] The method for training large models may be revolutionized! AI expert Karpathy has released a new project that trains GPT-2 using only 1000 lines of C code, eliminating the need for the massive GPT-2 library. He has announced that a new course will be launched soon.
After a month of silence, Karpathy has finally launched.This time it is not an AI course, but a new project.
Train GPT-2 using only 1000 lines of pure C code.
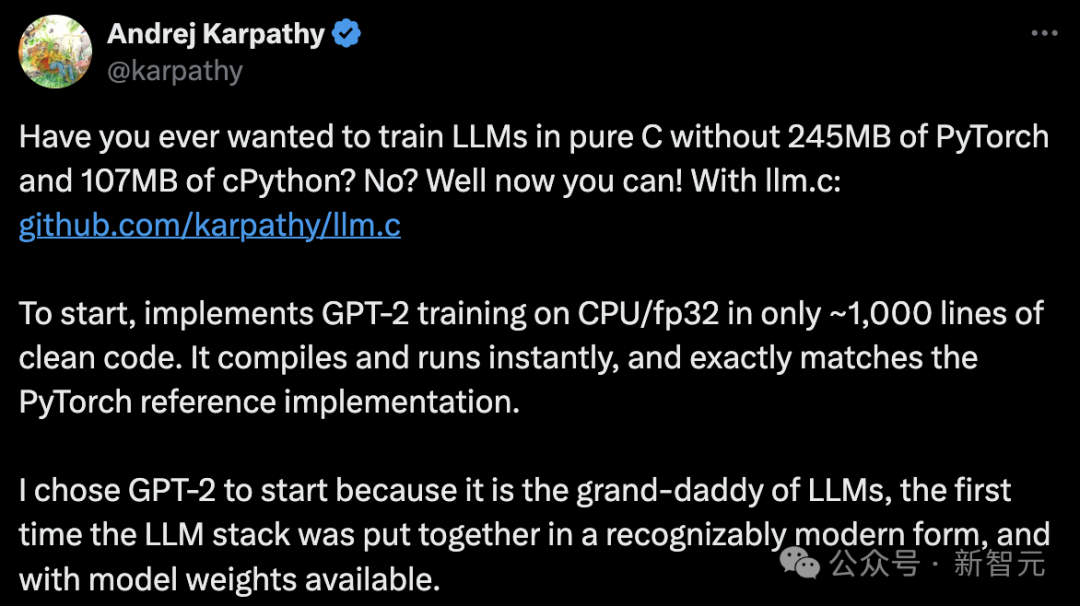
Imagine if we could train large language models (LLMs) without relying on the massive PyTorch (245MB) and cPython (107MB) libraries, using only pure C code. Now, with llm.c, this seemingly impossible task has become a reality!The highlight of this project is that it achieves the capability to train the GPT-2 model on a standard computer processor (CPU) using only about 1000 lines of concise C code.Moreover, this code can be compiled and run immediately, and its training results are completely consistent with the PyTorch version of GPT-2.The reason for choosing GPT-2 as a starting point is that it marks an important milestone in the development of large language models, integrating such a technology stack in a form we are now familiar with, and the model weights are publicly available.
This project has already garnered 2.5k stars just hours after its release.
Project address: https://github.com/karpathy/llm.cSome netizens have expressed that startups are waiting for Karpathy to discover new ideas.Few people know that SUNO was originally a branch of nanoGPT. (The first product of the Suno startup team, Bark, was inspired by nanoGPT)
 Perhaps what Karpathy is attempting is to redesign the LLM architecture, exploring a simpler and more efficient model training method through the llm.c project.
Perhaps what Karpathy is attempting is to redesign the LLM architecture, exploring a simpler and more efficient model training method through the llm.c project.
 “What I cannot create, I do not understand.”
“What I cannot create, I do not understand.” 
 Karpathy is truly making AI accessible to the masses.
Karpathy is truly making AI accessible to the masses. So, how can we train LLMs using only C code?
So, how can we train LLMs using only C code?
Training GPT-2 with a thousand lines of C code
In the project introduction, Karpathy also mentioned his current research:– Directly implementing with CUDA will be much faster, potentially approaching PyTorch.– Using SIMD instructions to accelerate the CPU version, AVX2 on x86/NEON on ARM (like Apple chips).– Adopting more modern architectures, such as Llama2, Gema, etc.For the repo, Karpathy hopes to maintain both a clean, simple reference implementation and more optimized versions that can approach PyTorch but require minimal code and dependencies.
Quick Start
Download the dataset and tokenize it. The Tinyshakespeare dataset downloads and tokenizes the fastest:
python prepro_tinyshakespeare.py
The printed content is as follows:
Saved 32768 tokens to data/tiny_shakespeare_val.binSaved 305260 tokens to data/tiny_shakespeare_train.bin
Here, the .bin files contain raw data streams of int32, which represent the Token IDs defined by the GPT-2 tokenizer.Of course, you can also tokenize the TinyStories dataset by running prepro_tinystories.py.Theoretically, we can now start training the model. However, the current reference code based on CPU and FP32 runs very inefficiently, making it impossible to train these models from scratch.Therefore, we choose to initialize with the weights of the GPT-2 model released by OpenAI and then fine-tune the model.For this purpose, we need to download the GPT-2 model weight files and save them as checkpoints so that they can be loaded in the C environment:
python train_gpt2.py
This script downloads the GPT-2 (124M) model and performs 10 iterations of training on a single data batch to achieve overfitting.Next, the script will execute several generation tasks, and most importantly, save two files:
-
gpt2_124M.bin, which contains the raw weights that can be loaded in the C environment;
-
gpt2_124M_debug_state.bin, which contains additional debugging information, such as input data, targets, logits, and loss.
This information is helpful for debugging, unit testing, and ensuring complete consistency with the PyTorch reference implementation.Currently, the main focus is on the model weights in the gpt2_124M.bin file. With them, we can initialize the model in the C environment and start training.First, we need to compile the code:
make train_gpt2
You can open the Makefile and read the comments inside.It will automatically check if your computer supports OpenMP, which is very helpful for accelerating code execution with very low complexity.Once the compilation of train_gpt2 is complete, you can start running it:
OMP_NUM_THREADS=8 ./train_gpt2
Now, you need to set the number of threads for the program to run based on the number of CPU cores on your computer.Then, the program will load the model weights and tokens, followed by several iterations of fine-tuning using the Adam optimization algorithm with a learning rate set to 0.0001.Finally, the program will generate a sample based on the model.In summary, the code implements the data processing flow for each layer of the model, including forward propagation, backward propagation, and parameter updates, and is organized into a complete loop.When running on a MacBook Pro with the M3 Max chip, the output is as follows:
[GPT-2]max_seq_len: 1024vocab_size: 50257num_layers: 12num_heads: 12channels: 768num_parameters: 124439808train dataset num_batches: 1192val dataset num_batches: 128num_activations: 73323776val loss 5.252026step 0: train loss 5.356189 (took 1452.121000 ms)step 1: train loss 4.301069 (took 1288.673000 ms)step 2: train loss 4.623322 (took 1369.394000 ms)step 3: train loss 4.600470 (took 1290.761000 ms)... (truncated) ...step 39: train loss 3.970751 (took 1323.779000 ms)val loss 4.107781generated: 50256 16773 18162 21986 11 198 13681 263 23875 198 3152 262 11773 2910 198 1169 6002 6386 2583 286 262 11858 198 20424 428 3135 7596 995 3675 13 198 40 481 407 736 17903 11 329 703 6029 706 4082 198 42826 1028 1128 633 263 11 198 10594 407 198 2704 454 680 1028 262 1027 28860 286 198 3237 323step 40: train loss 4.377757 (took 1366.368000 ms)
Currently, the results generated by the program are just Token IDs, and we need to convert these numbers into readable text.This process is quite simple to implement in C, as it mainly involves looking up and outputting corresponding string segments.Now, we can use a tool called tiktoken to accomplish this task:
import tiktokenenc = tiktoken.get_encoding("gpt2")print(enc.decode(list(map(int, "50256 16773 18162 21986 11 198 13681 263 23875 198 3152 262 11773 2910 198 1169 6002 6386 2583 286 262 11858 198 20424 428 3135 7596 995 3675 13 198 40 481 407 736 17903 11 329 703 6029 706 4082 198 42826 1028 1128 633 263 11 198 10594 407 198 2704 454 680 1028 262 1027 28860 286 198 3237 323".split()))))
The printed content is as follows:
<|endoftext|>Come Running Away,Greater conquerWith the Imperial bloodthe heaviest host of the godsinto this wondrous world beyond.I will not back thee, for how sweet after birthNetflix against repounder,will notflourish against the earlocks ofAllay
Karpathy stated that he is very satisfied with how Netflix is presented in the model’s generated results, as it shows that the model still retains some characteristics from its training process.Additionally, he did not adjust the hyperparameters for fine-tuning, so if these settings can be optimized, especially by extending the training time, there should be significant room for improvement in the model’s performance.
Testing
Here is a simple unit test program to verify that the C code we wrote matches the implementation in the PyTorch framework.You can compile and execute it with the following command:
make test_gpt2./test_gpt2
This code will first load the gpt2_124M_debug_state.bin file and then perform a forward computation.This process will generate the model’s prediction results (logits) and loss, and compare them with the standard implementation in PyTorch.Next, it will use the Adam optimization algorithm to train the model for 10 rounds to ensure that the training loss is consistent with the results from PyTorch.
Tutorial
At the end of the project, Karpathy also included a very small tutorial—
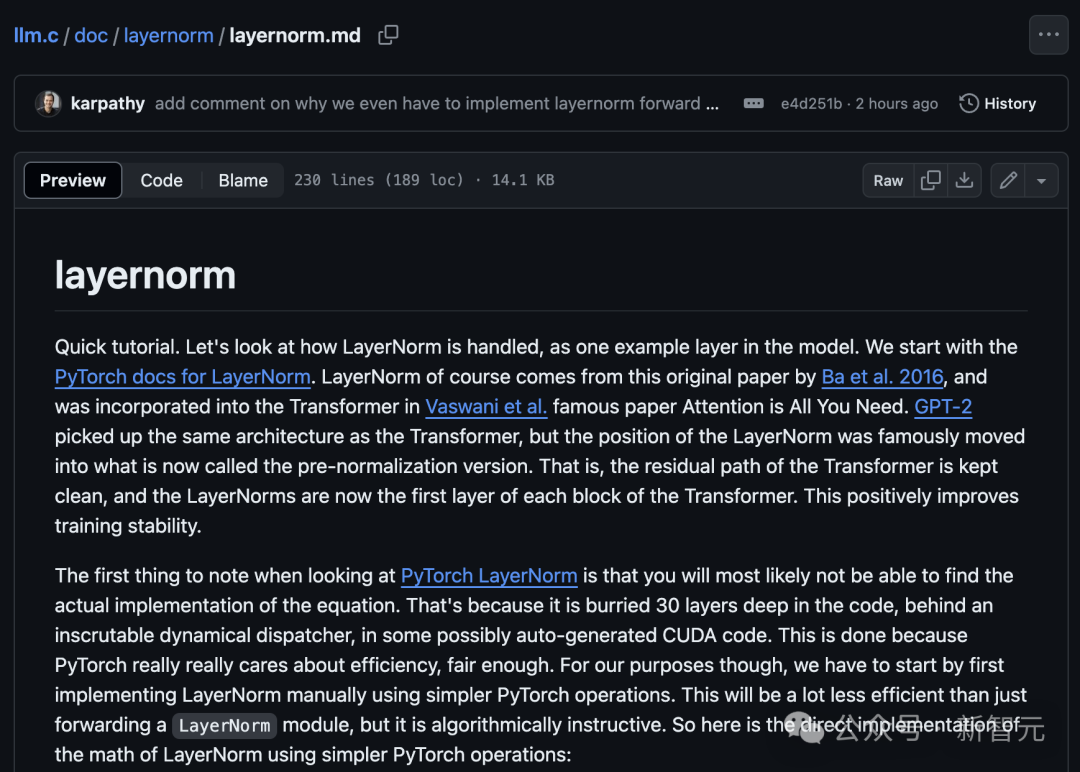
Project address: https://github.com/karpathy/llm.c/blob/master/doc/layernorm/layernorm.mdIt is a simple step-by-step guide to implementing a single layer of the GPT-2 model, namely LayerNorm.This is a great starting point for understanding how to implement layers in C.
Pure CUDA can also train
At the beginning of training, pre-allocate a large block of one-dimensional memory to store all the data needed during the training process.The benefit of this approach is that we do not need to allocate or free memory again during the entire training process. This not only simplifies memory management but also ensures that memory usage remains constant, optimizing data processing efficiency.The next core task is to manually write code to implement the forward and backward propagation processes for each layer in the model and connect these layers in sequence.Additionally, to build a complete model, we also need to implement several key components, including the encoder, matrix multiplication (matmul), self-attention mechanism, GELU activation function, residual connections, softmax function, and cross-entropy loss calculation.
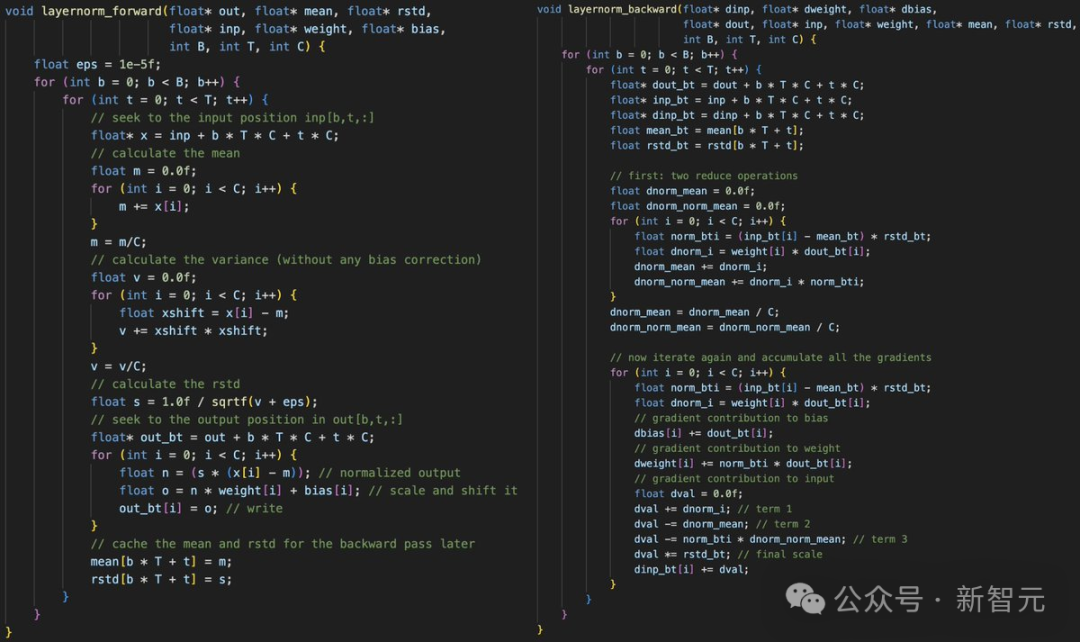 Karpathy continues to explain that once you have all the layers, you can chain them together.To be honest, writing this process is quite tedious and somewhat torturous, as you must ensure that all pointers and tensor offset vectors are correctly aligned.
Karpathy continues to explain that once you have all the layers, you can chain them together.To be honest, writing this process is quite tedious and somewhat torturous, as you must ensure that all pointers and tensor offset vectors are correctly aligned.
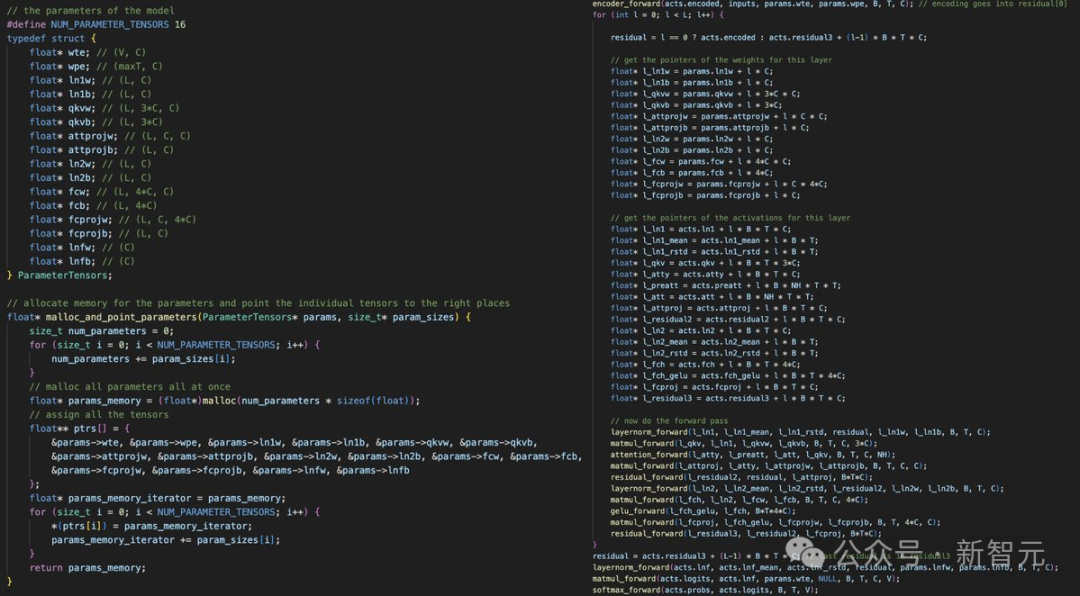
Left image: Allocating a one-dimensional array in memory and pointing all model weights and activations to it
Right image: Carefully performing all pointer arithmeticAfter completing the forward and backward propagation of the model, the subsequent tasks, such as setting up the data loader and adjusting the Adam optimization algorithm, become relatively simple.Subsequently, Karpathy also introduced that his next step is to gradually migrate this process to CUDA, significantly improving computational efficiency, potentially approaching PyTorch levels, without relying on those complex libraries.Currently, he has completed several layers of this.The next steps include reducing computational precision—from FP32 to FP16 or even lower—and adding some new layers (like RoPE) to support more advanced model architectures such as Llama 2, Mistral, Gemma, etc.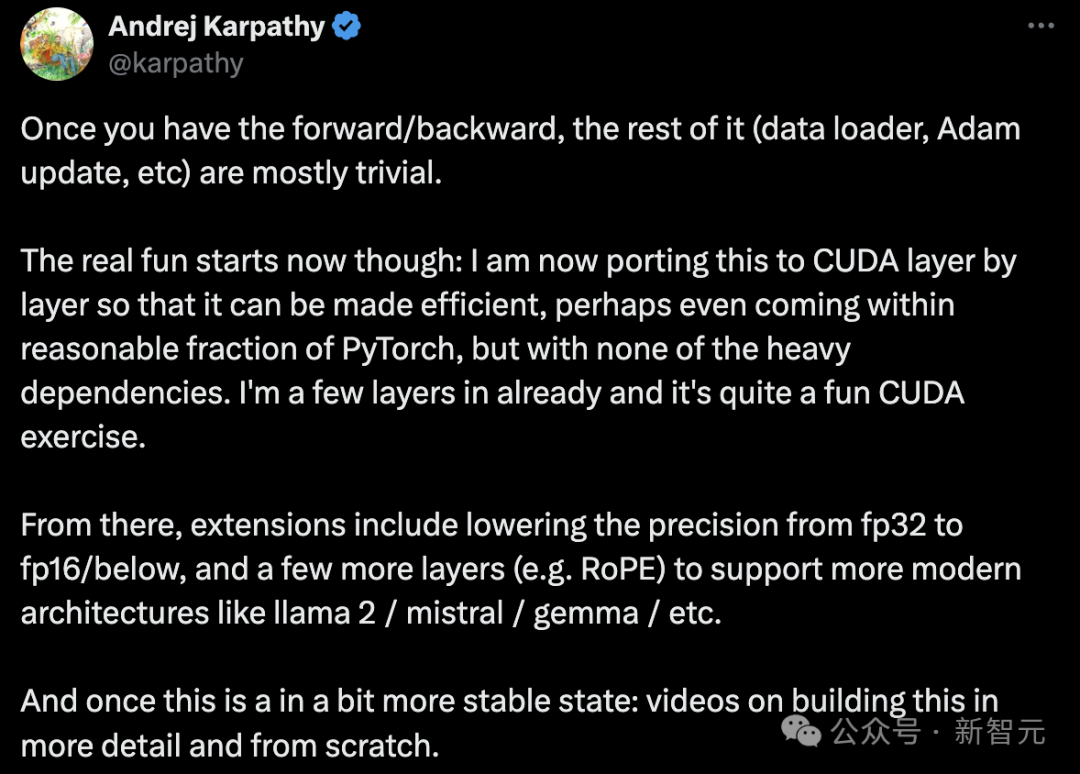 Of course, once all of this is completed, another episode of “Building from Scratch” will be released.References:https://github.com/karpathy/llm.chttps://twitter.com/karpathy/status/1777427944971083809
Of course, once all of this is completed, another episode of “Building from Scratch” will be released.References:https://github.com/karpathy/llm.chttps://twitter.com/karpathy/status/1777427944971083809

