Related Reading: What are the differences between Arm architecture upgrades from v9 to v8?
The separation of CPU design and manufacturing through foundry models provides AMD with high flexibility. The second and third generation EPYC processors can relatively freely choose different processes to match specific chip design needs, objectively helping AMD to “win big with small” and continuously take market share from Intel.
However, the beneficiaries of this flexibility are more AMD itself. Large-scale users such as AWS and Alibaba Cloud are not satisfied with traditional customizations that mainly adjust core counts, operating frequencies, and TDP metrics, and hope for more autonomy in CPU design; or emerging CPU suppliers like Ampere want to choose suitable technology routes… Arm is almost the only answer in the server CPU market.
If TSMC helps solve the manufacturing issues of CPUs, then Arm helps solve the design issues of CPUs.
Cortex Incubates Neoverse
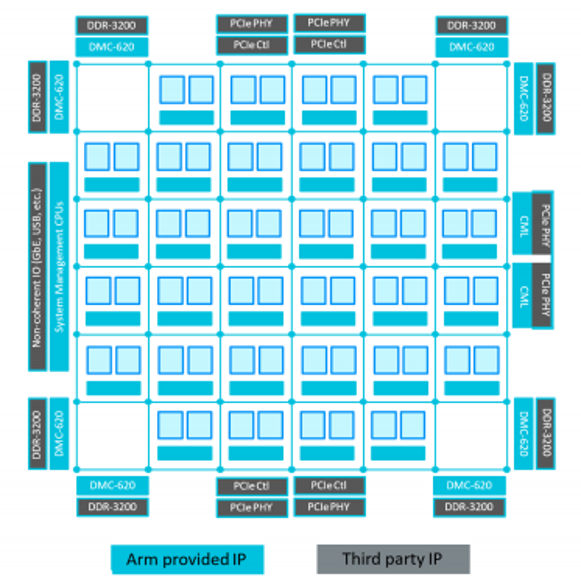
For “The Big Three” customers with sufficient chip design capabilities such as Amazon (Annapurna Labs), Alibaba (Pingtouge), and Ampere, Arm’s Neoverse platform provides the foundation for designing a server CPU, including the microarchitecture of CPU cores and supporting processes.
Arm’s positive attack on the server CPU market can be traced back to October 2011 when Arm released the optional 64-bit architecture (AArch64) with ARMv8-A. A year later, Arm released the microarchitectures Cortex-A53 and Cortex-A57 that implement the ARMv8-A 64-bit instruction set, with AMD expressing plans to launch corresponding server products—the latter’s years of experience in the server market was precisely what was lacking in Arm’s camp at the time.
In the following years, chip suppliers such as Cavium, Qualcomm, and domestic Huaxintong, as well as large-scale users like Microsoft, actively promoted 64-bit Arm entering the data center market. However, the truly large-scale deployments should start from November 2018 when AWS previewed its first Arm server CPU—Graviton.
Graviton is based on the Cortex-A72 launched in 2015, with a 16nm process, 16 cores, and 16 threads, and compared to x86 server CPUs of the same period, it is somewhat “unremarkable”, relying heavily on Amazon’s “own child” that can be fully optimized.
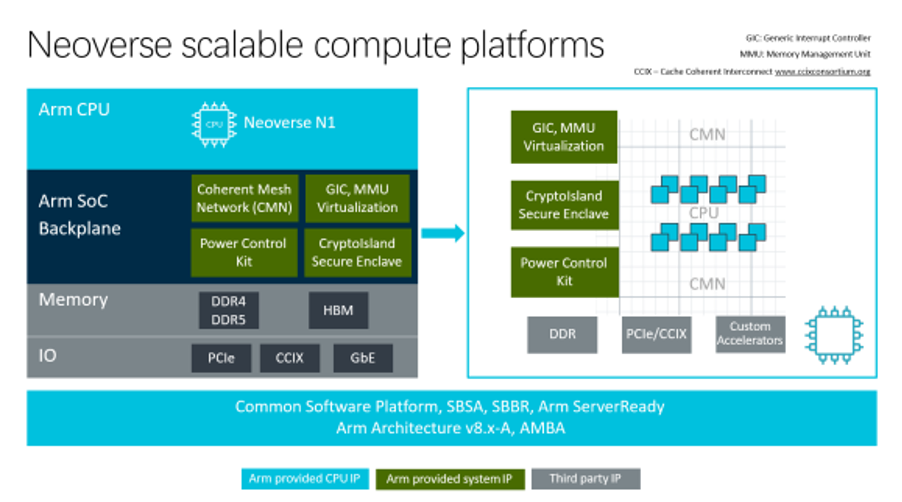
The Cortex-A family is already the most performance-oriented among the Cortex brothers, but it is not designed for server platforms and cannot relax power consumption limits to boost performance. Therefore, a month before Graviton was publicly released, Arm launched the Neoverse platform aimed at cloud computing and edge infrastructure, starting with the 16nm A72 and A75, code-named Cosmos.
△ Neoverse Scalable Computing Platform
Just four months later, in February 2019, Arm updated the roadmap for the Neoverse platform, launching the 7nm Neoverse N1, which offers over 30% performance improvement over previous targets.
The Neoverse N1, code-named Ares, is based on the Cortex-A76 launched in 2018, both having the same pipeline structure, featuring an 11-stage short pipeline design, with a front-end that is 4 wide for reading/decoding. Arm calls it an “accordion” pipeline, as it can overlap the second prediction stage with the first fetch stage and overlap the scheduling stage with the first issue stage in latency-sensitive situations, reducing the pipeline length to 9 stages. The L2 Cache also adds an optional 1MiB capacity, which is twice that of the A76.
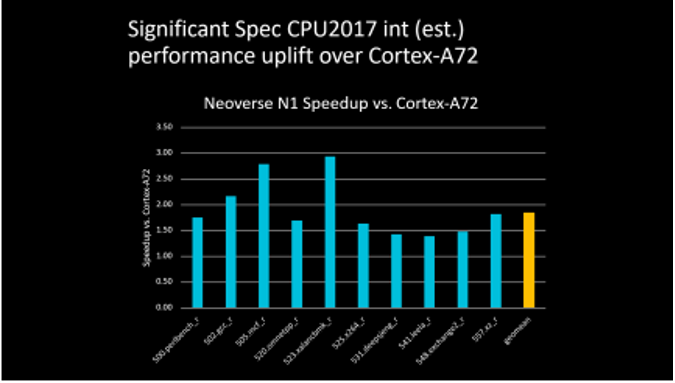
△ 4 vCPU Configuration, Performance Improvement of Neoverse N1 Compared to Cortex-A72
Compared to the previous generation A72 platform, the Neoverse N1 platform brought significant performance improvements, with many projects doubling their scores, especially in iconic machine learning projects where the results approached five times that of the previous generation. Although A72 has been around for a while, this performance gap indicates that the Neoverse N1 has indeed made a qualitative leap.
Graviton2 and Altra Series
The Neoverse N1 platform had a significant impact on the data center market, as everyone saw its enormous potential and value, as well as the opportunities behind it. If the previous A72 was only beginning to emerge in the data center market, then the Neoverse N1 made more people believe that Arm has the ability to share a piece of the pie in this field.
Two 7nm CPUs from cloud service providers and independent CPU suppliers are both based on Neoverse N1.
In November 2019, AWS officially announced the Graviton2 processor:
-
The number of cores surged to 64, four times that of the first generation;
-
The number of transistors increased sixfold, reaching 30 billion;
-
64MiB L2 Cache, eight times that of the first generation;
-
DDR4-3200 memory interface (frequency) is twice that of the first generation;
-
Operating frequency of 2.5GHz, slightly higher than the first generation’s 2.3GHz.
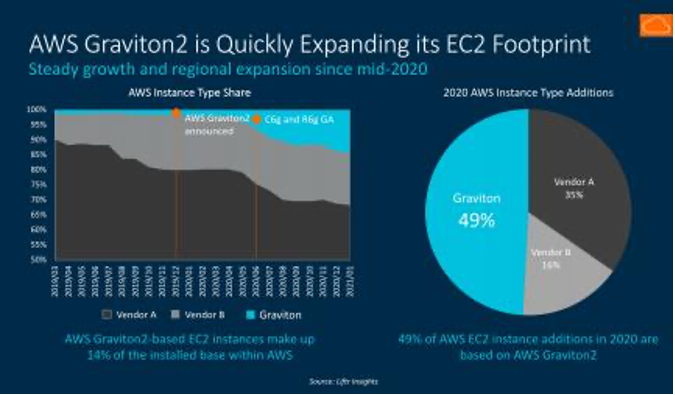
△ In 2020, Graviton2 occupied half of the new AWS EC2 instances, and the ratio of Intel and AMD is also intriguing
The number of EC2 (Elastic Compute Cloud) instance types based on Graviton2 quickly increased, including but not limited to general-purpose (M6g, T4g), compute-optimized (C6g), and memory-optimized (R6g, X2gd). The deployment regions and numbers have steadily increased since mid-2020—statistics show that in 2020, 49% of the incremental AWS EC2 instances were based on AWS Graviton2.
Armv9: Inheriting the Past and Opening the Future
In November 2011, Armv8 was announced, bringing Arm into the 64-bit era. With the joint efforts of Arm and ecosystem partners, after several product iterations, Arm’s camp took a decade to establish a foothold in the server market.
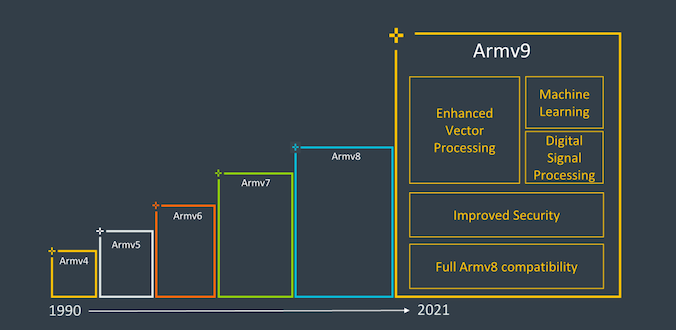
At the end of March 2021, Armv9 was released, focusing on upgrades in security, machine learning (ML), and digital signal processing (DSP) capabilities based on Armv8.
Among the three major features brought by the new architecture, machine learning may be the most familiar and concerning content for the public. With the rise of heterogeneous applications, artificial intelligence (AI) technologies represented by machine learning have deeply penetrated all aspects of our lives, whether in backend data centers or on terminals and edge sides, machine learning has vast applications.
To better enhance the computing power required for AI and DSP, ARMv9 upgraded the originally supported Scalable Vector Extension (SVE) to version 2.0. This technology can improve the performance of machine learning and digital signal processing applications, helping to handle a series of workloads such as 5G systems, VR/AR, and machine learning.
SVE2 provides adjustable vector sizes, ranging from 128b to 2048b, allowing for variable granularity of 128b for vectors, which will not be affected by hardware platforms. This means that software developers only need to compile their code once, and it can be applied to Armv9 and subsequent products, achieving “write once, run anywhere.” Similarly, the same code will be able to run on more conservative designs with lower hardware execution width capabilities, which is crucial for Arm designs from IoT and mobile to data center CPUs.
SVE2 extensions also add the ability to compress and decompress code and data within CPU cores, as the process of moving data in and out of the chip consumes significant power, using as much data as possible within the chip can reduce such data movement and thus lower energy consumption.
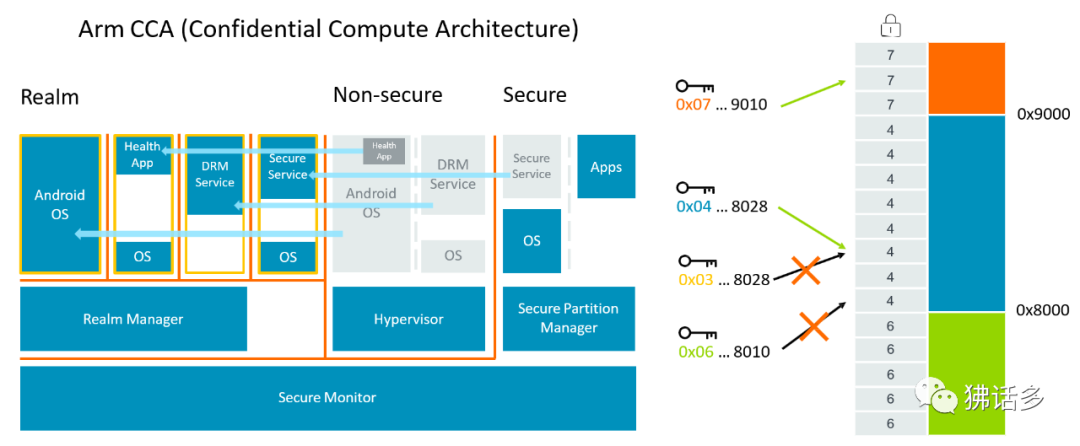
More importantly, the Confidential Compute Architecture (CCA), which is also the most important content of this version update. In fact, security issues have become increasingly severe in recent years, with ransomware and hacker attacks occurring constantly. In the face of the ever-increasing network attack issues, it requires not only the efforts of network service providers and software companies but also hardware infrastructure providers, including Arm, to block potential vulnerabilities from the source, leading to the emergence of CCA. This is a security protection capability based on architecture, executing computations in a hardware-based secure operating environment to protect certain code and data from being accessed or modified, and even from being affected by privileged software.
△ Arm Confidential Compute Architecture (left), Memory tagging extension technology introduced by Android 11 and OpenSUSE (right)
To this end, CCA introduces the concept of dynamically creating confidential realms—this is a secure containerized execution environment that supports secure data operations and can isolate data from the hypervisor or operating system. The management function of the hypervisor is undertaken by a “realm manager,” while the hypervisor itself is only responsible for scheduling and resource allocation. The advantage of using “realms” is that it greatly reduces the trust chain of running a given application on the device, making the operating system largely transparent to security issues, and allowing critical applications that require supervisory control to run on any device.
In practical applications, memory is a very easy target for attacks, and memory safety has always been a focus of the industry. How to detect issues before memory safety vulnerabilities are exploited is an important step in improving global software security. To this end, the “Memory Tagging Extensions” (MTE) technology continuously developed by Arm and Google has also become a part of Armv9, allowing for the identification of memory space and temporal safety issues in software, linking pointers pointing to memory with tags, and checking whether the tag is correct when using the pointer. If access exceeds bounds, the tag check will fail, allowing for the immediate detection and blocking of memory safety vulnerabilities.
What are the differences between Arm architecture upgrades from v9 to v8?
Over the past few years, Arm has made improvements to the ISA and various updates and expansions to the architecture. Some of these may be very important, while others may be just a glimpse.
Recently, as part of Arm’s Vision Day event, the company officially released the first details of its next-generation Armv9 architecture, laying the foundation for Arm to become the next 300 billion chip computing platform over the next decade.
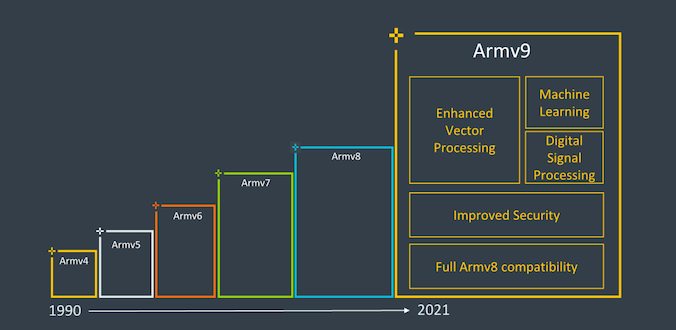
One big question readers might ask is what exactly is the difference between Armv9 and Armv8 that allows the architecture to achieve such a significant upgrade. Indeed, from a purely ISA perspective, v9 may not achieve a fundamental leap compared to v8 as v8 introduced AArch64, a completely different execution mode and instruction set that has larger microarchitectural branches compared to AArch32, such as extended registers, 64-bit virtual address space, and more improvements.
Armv9 continues to use AArch64 as the baseline instruction set but adds some very important extensions to its functionality to ensure the increase of architecture numbering and allow Arm to not only gain some software re-benchmarking capabilities for AArch64 with the new features of v9 but also maintain the extensions we gained over the years on v8.
Arm believes the new Armv9 architecture has three main pillars: security, AI, and improved vector and DSP functionality. For v9, security is a very important theme, and we will delve into the new extensions and features in detail, but first, the DSP and AI functions should be straightforward.

The new Armv9 compatible CPUs promise the greatest new features that developers and users can see immediately—SVE2 as the successor to NEON.
The Scalable Vector Extension (SVE) debuted in 2016 and was first implemented in Fujitsu’s A64FX CPU core, which supports Japan’s top supercomputer Fugaku. The issue with SVE is that the first iteration of the new variable-length vector-length SIMD instruction set has a relatively limited range and is more targeted at HPC workloads, lacking many more general instructions still covered by NEON.
SVE2 was released in April 2019, aiming to address this issue by supplementing the new scalable SIMD instruction set with necessary instructions to serve workloads currently still using NEON, such as DSP.
In addition to the various modern SIMD features added, the advantages of SVE and SVE2 also lie in their variable vector sizes, ranging from 128b to 2048b, allowing for variable granularity of 128b for vectors, regardless of the hardware they run on. If purely viewed from the perspective of vector processing and programming, this means that software developers only need to compile their code once, and if in the future some CPU has local 512b SIMD execution pipelines, that code will be able to fully utilize the entire width of the unit. Similarly, the same code will be able to run on more conservative designs with lower hardware execution width capabilities, which is crucial for Arm designs from IoT and mobile to data center CPUs. While retaining the 32b encoding space of the Arm architecture, it can accomplish all of this. However, architectures like X86 require new instructions and extensions to be added based on vector size.
Machine learning is also seen as an important component of Armv9, as Arm believes that in the coming years, an increasing number of ML workloads will become commonplace, including scenarios with critical performance or power efficiency requirements. This makes it a long-term need to run ML workloads on dedicated accelerators, while we will continue to run smaller-scale ML workloads on CPUs.
The matrix multiplication instructions are key here, representing an important step towards the broader adoption of v9 CPUs as fundamental capabilities in the ecosystem.
Generally, I believe SVE2 may be the most important factor in ensuring the upgrade to v9, as it is a more definitive ISA feature that can distinguish itself from v8 CPUs in everyday use, and can ensure that the software ecosystem can function normally, which is different from the existing v8 stack. For Arm in the server domain, this has actually become quite a significant issue, as the software ecosystem is still based on the v8.0 software package, which unfortunately lacks the most important v8.1 large system extensions.
Advancing the entire software ecosystem and assuming that the new v9 hardware has new architectural extension capabilities will help push things forward and possibly address certain current situations.
However, v9 involves not only SVE2 and new instructions but also pays great attention to security, and we will see some more fundamental changes in security.
Introducing the Confidential Compute Architecture
In recent years, security and hardware security vulnerabilities have become a top priority in the chip industry, with vulnerabilities like Spectre and Meltdown and all their class side-channel attacks indicating that rethinking how to ensure security has become a fundamental need. Arm’s approach to solving this overarching issue is to redesign how secure applications work through the introduction of the Arm Confidential Compute Architecture (CCA).
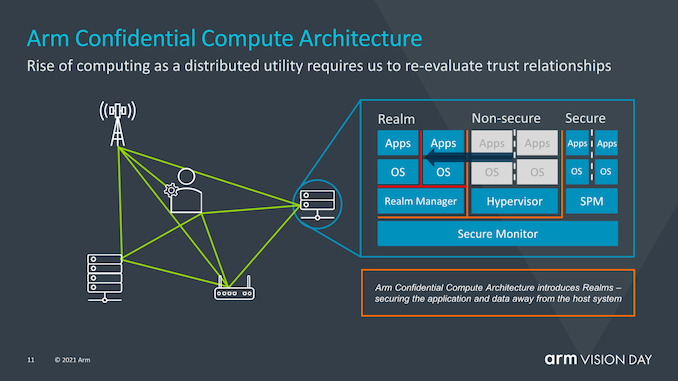
Before continuing, I want to clarify that today’s disclosure is merely a high-level explanation of how the new CCA operates; Arm has stated that more details on how the new security mechanisms work will be announced later this summer.
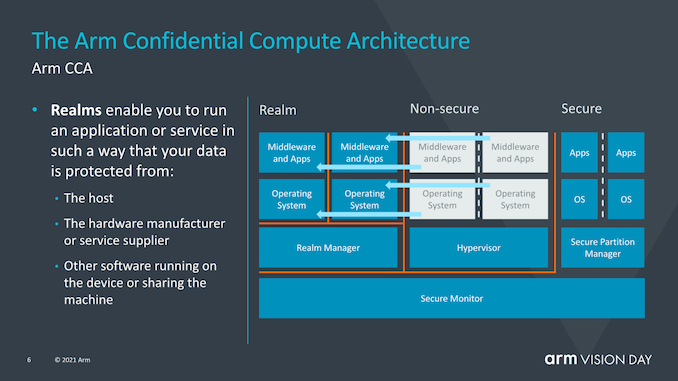
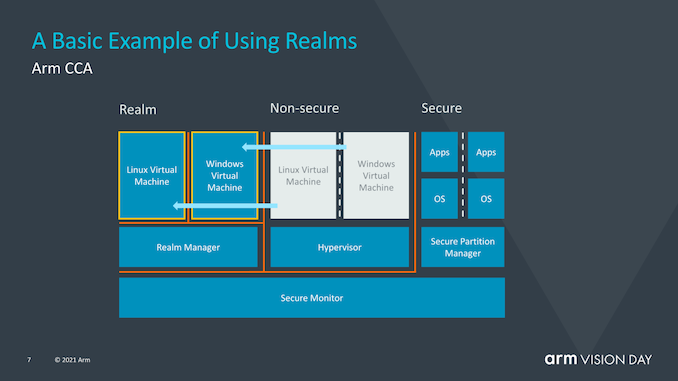
The goal of CCA is to gain greater benefits from the current software stack situation, where applications running on devices must inherently trust the operating system and hypervisor they run on. The traditional security model is built on the fact that higher privilege software layers are allowed to view lower execution layers; however, this can become a problem when the operating system or hypervisor is compromised in any way.
CCA introduces the new concept of dynamically creating “realms”, which can be seen as a secure containerized execution environment that is completely opaque to the OS or hypervisor. The hypervisor will still exist, but will only be responsible for scheduling and resource allocation. The “realm” will be managed by a new entity called the “realm manager,” which is considered a piece of new code, roughly one-tenth the size of the hypervisor.
Applications within the realm will be able to “prove” the realm manager to determine whether it is trustworthy, which is not possible for traditional hypervisors.
Arm has not delved into what exactly causes this isolation between the realm and the non-secure world of the operating system and hypervisor, but it certainly sounds like hardware-supported address spaces that cannot interact with each other.
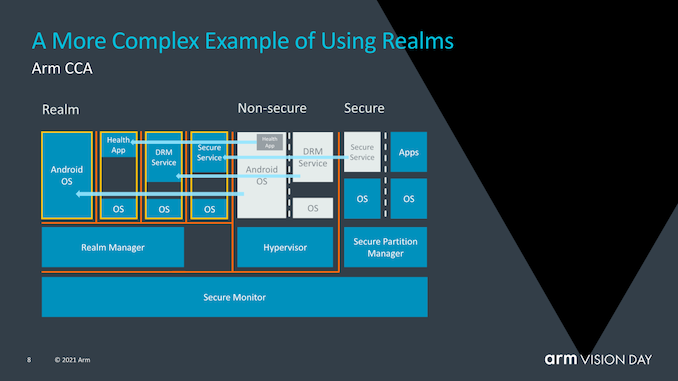
The advantage of using realms is that it greatly reduces the trust chain of running a given application on the device, and the OS becomes increasingly transparent to security issues. In contrast to today’s need for enterprises to use dedicated devices with authorized software stacks, critical applications requiring supervisory control will be able to run on any device.
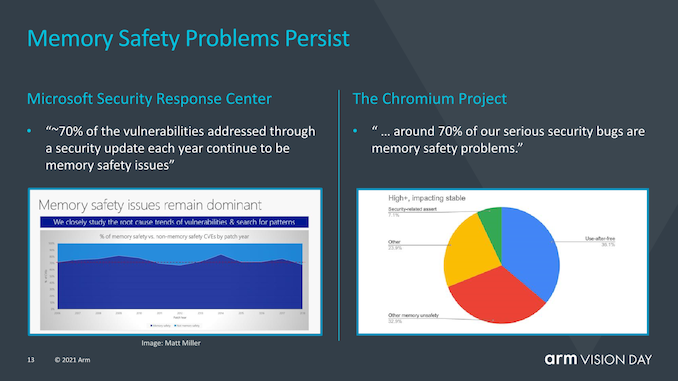
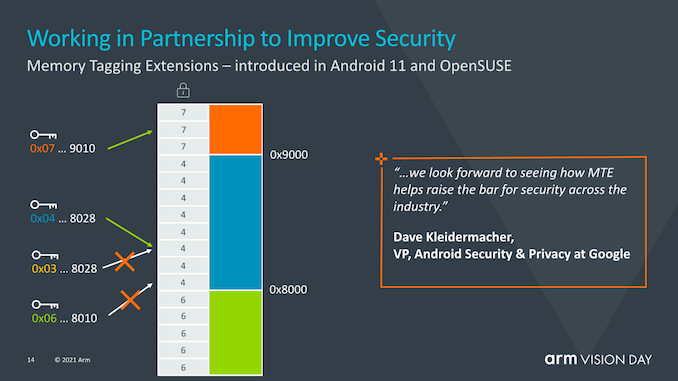
MTE (memory tagging extensions) is not a new feature of v9 but was introduced with v8.5. MTE or memory tagging extensions aim to help address two of the most persistent security issues in the world of software: buffer overflows and use-after-free are ongoing software design issues that have been part of software design for the past 50 years, and it may take years to identify or resolve these issues. MTE aims to help identify such issues by tagging pointers at allocation and checking at use.
The Future Arm CPU Roadmap
This is not directly related to v9, but is closely related to the technical roadmap for the upcoming v9 design. Arm also discussed some of their expected performance perspectives for v9 designs over the next two years.
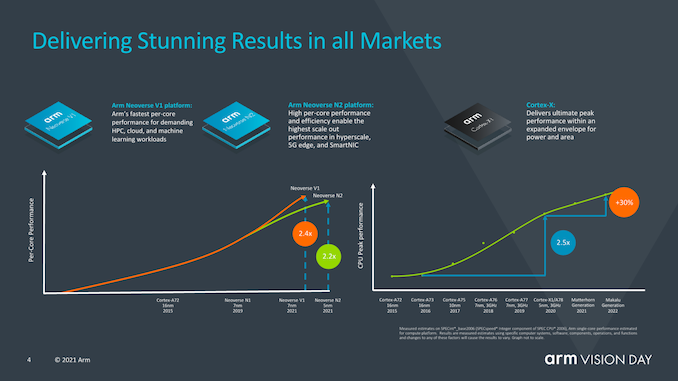
Arm talked about how the mobile market has improved device performance by 2.4 times this year with devices featuring X1 (here we only refer to the IPC of ISO process design), which is twice that of the Cortex-A73 launched years ago.
Interestingly, Arm also mentioned the Neoverse V1 design and how it achieved 2.4 times the performance of the A72-like design, revealing that they expect the first V1 devices to be released later this year.
For the next-generation mobile IP cores codenamed “Matterhorn” and “Makalu”, the company publicly revealed that the combined expected IPC gain for these two generations is 30%, excluding any frequency or other performance gains that SoC designers can achieve. This actually represents a 14% increase in generational performance for these two new designs, and as indicated by the performance curves in the slide, it shows that the pace of improvement has slowed compared to the work Arm has managed over the past few years since A76. However, the company noted that the pace of progress is still far ahead of the industry average. But the company also admitted that this has been dragged down by some industry participants.
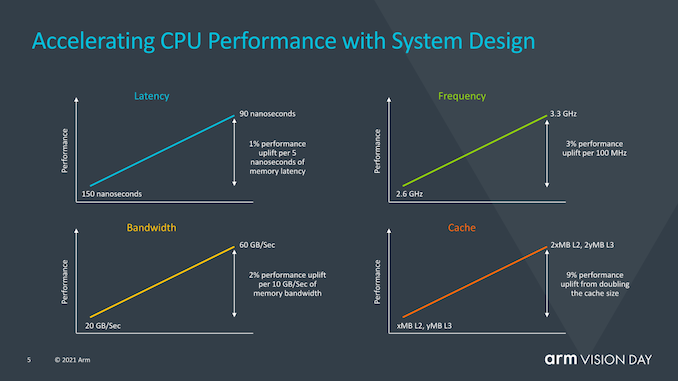
Arm also provided an interesting slide focusing on the impact of system-side performance, not just CPU IP performance. From some of the data provided here, for example, 1% of performance loss in every 5ns of memory latency is a figure we have widely discussed over several generations, but Arm also pointed out that regardless of whether improvements are made through memory path enhancements, additional caches, or optimized frequency features, they could achieve a whole generation of CPU performance improvements. I think this is an evaluation of the current conservative approach of SoC suppliers, which have not fully utilized the expected performance margin of the X1 core, and subsequently did not achieve the expected performance predictions of the new cores.

Arm continues to view CPUs as the most universal computing module of the future. While dedicated accelerators or GPUs will have their place, they struggle to address some important issues such as programmability, protection, universality (the ability to run them on any device), and the ability to work normally as verified.Currently, the computing ecosystem is extremely fragmented in how it operates, not only in terms of device types but also in device vendors and operating systems.
SVE2 and matrix multiplication can greatly simplify the software ecosystem and allow computing workloads to move forward in a more unified manner, which can run on any device in the future.

Finally, Arm also shared new information about the future of Mali GPUs, revealing that the company is developing new technologies like VRS, especially Ray Tracing. This is very surprising and also indicates that the desktop and console ecosystems driven by AMD and Nvidia’s introduction of RT are also expected to push the mobile GPU ecosystem towards RT.
Armv9 Design Set to Launch in Early 2022
Today’s announcement has come in a very high-level form, and we hope Arm will discuss more details and new features of Armv9 in the coming months during the company’s usual annual technology disclosures.
Overall, Armv9 seems to combine a more fundamental ISA shift (which can be seen as SVE2) with an overall re-benchmarking of the software ecosystem to summarize the last decade of v8 extensions and lay the foundation for the next decade of the Arm architecture.
Arm has already discussed Neoverse V1 and N2 in the second half of last year, and I do hope N2 will at least end up being designed and released based on v9. Arm further revealed that more CPU designs based on Armv9 (possibly the next generation mobile Cortex-A78 and X1) will be launched this year, and new CPUs may have already been adopted by the usual SoC suppliers and are expected to appear in commercial devices in early 2022.
Source:E-Enterprise Research Institute, Semiconductor Industry Observation
The “Complete Manual of ARM Series Processor Application Technology” contains 16 chapters (469 pages of valuable PDF),downloadlink:Complete Manual of ARM Series Processor Application Technology.
CPU and GPU Research Framework Collection
1. In-depth Industry Report: GPU Research Framework
2. Xinchuang Industry Research Framework
3. ARM Industry Research Framework
4. CPU Research Framework
5. Domestic CPU Research Framework
<6. In-depth Industry Report: GPU Research Framework
ARM CPU Processor Information Summary (1)
ARM CPU Processor Information Summary (2)
Complete Manual of ARM Series Processor Application Technology
Open Source Applications of Arm Architecture Servers
Arm Architecture Servers and Storage
Analysis of Server Hardware Architecture
Research on Current Status of Server Market
 Disclaimer:This account focuses on related technology sharing, and the content does not represent the position of this account, all traceable content is marked with sources, if there are copyright issues with published articles, please leave a message to contact for deletion, thank you.
For more architecture-related technology knowledge summaries, please refer to the “Architect’s Full Store Technical Data Pack” related e-book (37 bookstechnical data pack summary details can be obtained through “Read the original text“.
All store content is continuously updated, and now ordering “Architect’s Technical Full Store Data Pack Summary (All)” will allow you to enjoy free updates of all store content in the future, priced at only 198 yuan (original total price 350 yuan).
Please search for “AI_Architect” or “Scan Code” to follow the public account for real-time access to in-depth technical sharing, click “Read the original text” to get more originaltechnical dry goods.
Disclaimer:This account focuses on related technology sharing, and the content does not represent the position of this account, all traceable content is marked with sources, if there are copyright issues with published articles, please leave a message to contact for deletion, thank you.
For more architecture-related technology knowledge summaries, please refer to the “Architect’s Full Store Technical Data Pack” related e-book (37 bookstechnical data pack summary details can be obtained through “Read the original text“.
All store content is continuously updated, and now ordering “Architect’s Technical Full Store Data Pack Summary (All)” will allow you to enjoy free updates of all store content in the future, priced at only 198 yuan (original total price 350 yuan).
Please search for “AI_Architect” or “Scan Code” to follow the public account for real-time access to in-depth technical sharing, click “Read the original text” to get more originaltechnical dry goods.
“},