
Big Data Digest Work
Author|Ding Yanjun
In daily work or study, one often encounters the following frustration:
“Xiao Ren, please type out the contents of this PDF and send it to me.”
Ugh, what a hassle, a 2MB PDF can’t be finished by 12 o’clock!

Many times while studying, I find that many documents are in PDF format, which is not conducive to learning. Therefore, it is necessary to convert PDFs to Word files. However, you may have downloaded many software programs online that only convert the first five pages (like WPS, etc.), or require payment. So, is there any free conversion software available?
So, we bring you a free, simple, and fast method to teach you how to batch process PDF files using Python, extracting the content you want and saving it in Word format.
Before implementing the PDF to Word functionality, we need a Python development and runtime environment, along with the necessary dependencies installed. For the Python environment, we recommend using PyCharm. Anaconda provides a very convenient installation and deployment option on local computers.
The dependencies required for the PDF to Word functionality are as follows:
-
PDFParser (Document Analyzer)
-
PDFDocument (Document Object)
-
PDFResourceManager (Resource Manager)
-
PDFPageInterpreter (Interpreter)
-
PDFPageAggregator (Aggregator)
-
LAParams (Parameter Analyzer)
Preparation Work
Note: This article uses the latest version of Python 3.6 on Windows 7.
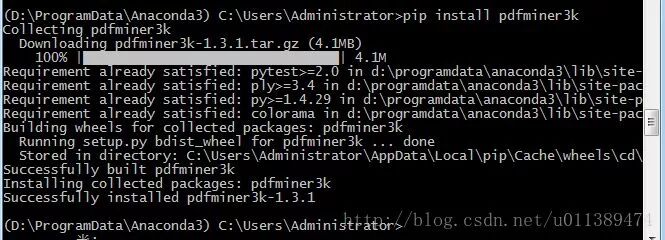
1. Install the pdfminer3k module
After installing Anaconda, you can install it directly via pip.
2. If the installation fails, you can try the following method
First, download pdfminer3k: https://pypi.python.org/pypi/pdfminer3k; then install pdfminer, extract the downloaded pdfminer3k to D: or another suitable drive, open the run window by pressing win+r, type cmd; switch to D drive by typing D:, cd pdfminer3k (the folder where pdf is extracted), and type setup.py install to install the software.
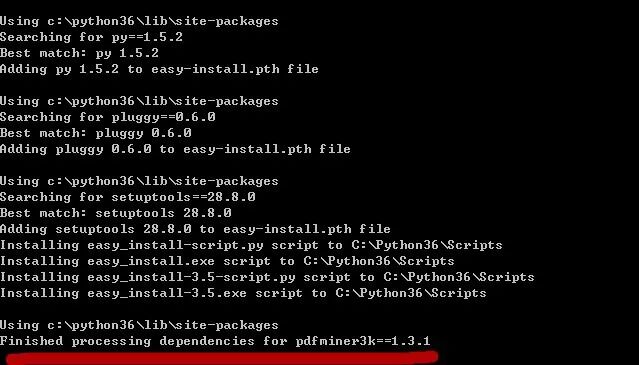
If it displays Finished, it means the installation was successful.
Code Implementation
1. Import the necessary packages
from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.layout import LAParams
from pdfminer.converter import PDFPageAggregator
The overall idea is to construct a document object, parse the document object, and extract the required content.
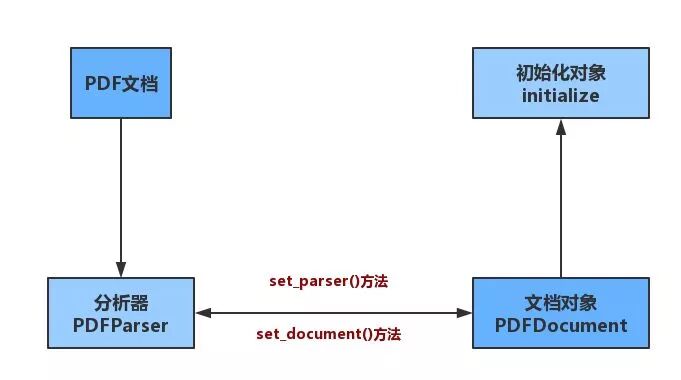
Constructing the Document Object
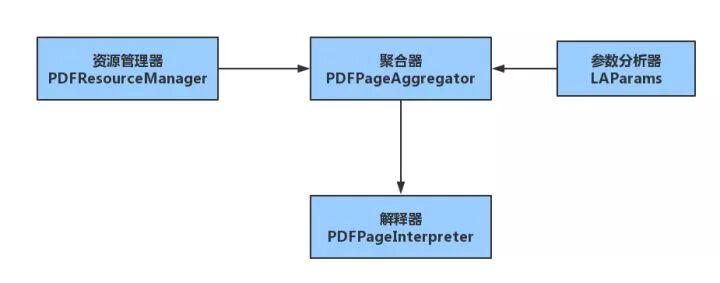
Constructing the Interpreter
2. Import the PDF file to be parsed
Place the file to be parsed in the same directory as the executing code, as shown:

Contents of test.pdf
3. The specific code is as follows:
from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.layout import LAParams
from pdfminer.converter import PDFPageAggregator
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
def parse():
# Open the local PDF file in binary read mode
fn = open('test.pdf','rb')
# Create a PDF document analyzer
parser = PDFParser()
# Create a PDF document
doc = PDFDocument()
# Connect the parser with the document object
parser.set_document(doc)
doc.set_parser(parser)
# Provide initialization password doc.initialize("lianxipython")
# If there is no password, create an empty string
doc.initialize("")
# Check if the document allows text extraction, if not, ignore
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
else:
# Create PDF resource manager
resource = PDFResourceManager()
# Create a PDF parameter analyzer
laparams = LAParams()
# Create an aggregator to read the document's objects
device = PDFPageAggregator(resource,laparams=laparams)
# Create an interpreter to encode the document into a format recognizable by Python
interpreter = PDFPageInterpreter(resource,device)
# Loop through the list, processing one page at a time
# doc.get_pages() gets the page list
for page in doc.get_pages():
# Use the interpreter's process_page() method to parse and read the individual page
interpreter.process_page(page)
# Use the aggregator's get_result() method to get the content
layout = device.get_result()
# Here layout is an LTPage object, which contains various objects parsed from this page
for out in layout:
# Check if it has the get_text() method to get the text we want
if hasattr(out,"get_text"):
print(out.get_text())
with open('test.txt','a') as f:
f.write(out.get_text()+'\n')
if __name__ == '__main__':
parse()
The final result in test.txt is as follows:
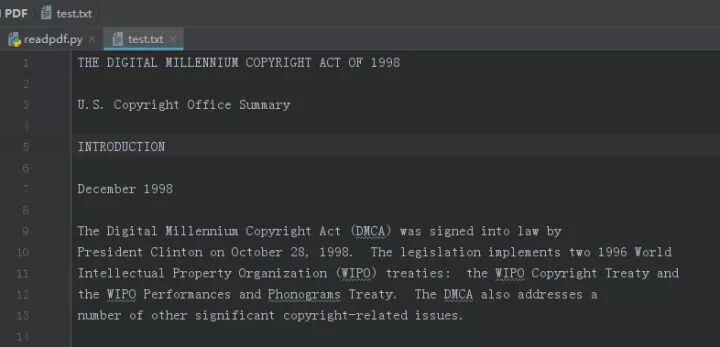
Conclusion
This concludes the introduction to the operation of batch converting PDF to Word using Python. This article merely serves as a demonstration of the code writing process using libraries. Specific techniques still require interested friends to discuss and study together, learning and improving mutually.
This article is a submission and represents the author’s personal views.
Author Introduction:
An amateur programmer obsessed with Python, after six months of hard practice, having gone from beginner to giving up, I now feel fortunate to have become obsessed with Python. My future ideal is to do meaningful things with a group of programmers who are passionate about Python. Zhihu column link: https://www.zhihu.com/people/cai-niao-fen-xi-64/activities
[Today’s Machine Learning Concept]
Have a Great Definition


