 Author: lpalmieriTranslator: Wang QiangEditor: Cai FangfangIn the field of machine learning development, if we look at the big picture and set aside all the minor details, we can distill two immutable steps in machine learning development: model training and prediction (or inference). Today, the preferred language for machine learning is Python (unless your work environment has some unusual constraints). This article will take you on a new journey. By the end, you may find that using Rust as a training backend and deployment platform is not as crazy or confusing as it sounds (besides the performance improvements mentioned in the title, there are actually many other benefits to this approach).
Author: lpalmieriTranslator: Wang QiangEditor: Cai FangfangIn the field of machine learning development, if we look at the big picture and set aside all the minor details, we can distill two immutable steps in machine learning development: model training and prediction (or inference). Today, the preferred language for machine learning is Python (unless your work environment has some unusual constraints). This article will take you on a new journey. By the end, you may find that using Rust as a training backend and deployment platform is not as crazy or confusing as it sounds (besides the performance improvements mentioned in the title, there are actually many other benefits to this approach).

Why Choose Python?
We could spend a lot of time discussing the various workflows used in machine learning development, but it is generally undisputed that we typically train models in a exploratory manner. You have a dataset, and you slice it into many segments to better understand it, then try various methods to solve the specific problem you are concerned with. (Identifying kittens in Google Street View images? Weather forecasting? Or optimizing crop yields? You decide what to do!)
There will be many pitfalls along the way, and most of the techniques you try are not out-of-the-box solutions, so the focus is on rapid prototyping and iterative improvement.
For a dynamic programming language like Python, this is an ideal use case.
More importantly, you must consider that most machine learning practitioners come from backgrounds in statistics, mathematics, physics, or similar fields, rather than being computer science experts. This means they (and I too✋) have had little training in software engineering practices and tools.
While Python supports both functional and object-oriented paradigms, you can use an imperative style and quickly get started with its scripting capabilities. It has a low barrier to entry, and as your experience grows, you become more proficient, and Python grows with you.
However, ease of use is far from sufficient: training machine learning models requires a lot of tedious computations, and Python is certainly not the fastest programming language.
Thus, we see the emergence of NumPy (1995/2006), SciPy (2001), Pandas (2008), and Scikit-learn (2007). Without such a high-quality and comprehensive toolkit for machine learning and scientific computing, Python would not have achieved its current status.
However, if you delve deeper, you will find that there is not much room for Python: you are using Python to orchestrate and leverage a powerful core of C and C++ routines.
Python is the frontend of these systems, allowing users to easily glue them together with the Python user interface. C and C++ are your backend, the source of the magic behind the scenes.

Indeed, this is a feature of Python that is often overlooked: using its Foreign Function Interface (FFI) to interoperate with other programming languages is quite easy. In particular, Python libraries can delegate programs that require extensive numerical computations to C and C++, a strategy that all foundational libraries in the Python scientific ecosystem utilize.
Of course, technology alone cannot determine everything. Sociological factors are crucial for the success (or demise) of most projects, even if some people find this hard to accept.
So we should add some context: Python is an open-source project (hi, MATLAB!), and its penetration level in academic institutions is significant; in fact, when deep learning stepped into the spotlight, most of the scientific ecosystem related to it had already been established.
In hindsight, it is quite natural to view Python as a strong candidate to dominate the field of machine learning, and the outcome is not surprising.
Should We Continue Using Python in the Future?
We have briefly introduced some reasons for choosing Python as the preferred programming language for machine learning development.
But the world is not static: changes in the environment can significantly alter perceptions of which tools are the “best tools for the job.”
Some recent trends may strengthen Python’s position in the field of machine learning.
Microservices
Microservices architecture currently dominates architectural design approaches: companies run their businesses with loosely coupled collections of containerized services that communicate over the network.
Running a polyglot stack has never been easier: the essence of your main application and business logic can be written in Java—when you want to leverage machine learning to determine whether a credit card transaction is legitimate or fraudulent, you can issue a POST request to a Python microservice.
The days of data scientists and machine learning engineers executing model exploration in Python are long gone; now we hand everything over to the “production team,” which will comprehensively rewrite the logic in the language of the company’s choice.
DevOps
You build it, you run it—Werner Vogels (CTO of Amazon)
Since we are talking about business, it must be emphasized: machine learning models do not exist in a vacuum; they are part of products or processes that companies want to launch, optimize, or improve.
Therefore, it is naive to think that a team composed solely of data scientists can achieve significant results. You need a combination of skills ranging from product to software engineering.
So what programming language should such a team use?
Remember the rise of JavaScript: the same person using JavaScript and NodeJS can handle both frontend and backend work for the system (“full stack”).
As a general-purpose programming language, Python offers the same convenience. You can use its scientific stack for machine learning development and leverage its frameworks (like Django, Flask, and FastAPI) for model deployment, then provide predictions via REST or gRPC APIs.
Nice, right?
Chain Reaction
-
Python has a vast machine learning ecosystem;
-
You want your machine learning algorithms or frameworks to be adopted: so you write code in Python (or provide Python bindings using FFI);
-
The Python ecosystem becomes stronger.
Round and round it goes.
Conclusion
Tomorrow, we may still be writing machine learning software in Python.
Will we use it forever? Unlikely, it’s like asking what the future of the computer industry will look like in ten years.
But I wouldn’t bet on seeing the sunset of Python in the next five years.
So, what about Rust?

That’s right!
But more importantly, we need to clear up any possible misunderstandings before we dive into the main topic.
I do not believe Rust will replace Python as the preferred language for machine learning—there is no sign of that happening, neither today nor in the future; this is not a trend.
The two languages cater to different audiences, and they are optimized for different constraints, addressing a range of different problems.
However, Rust has its place in the world of machine learning.
Rust has the potential to replace C and C++ as the preferred Python backend for machine learning workloads.
Why Rust?
There is no better answer than the preface of this book:
For example, handling low-level details of memory management, data representation, and concurrency in a “system-level” manner.Traditionally, this programming domain has been viewed as a mysterious kingdom that only a few who have spent enough time learning to avoid its notorious traps can enter.Even those who practice it must tread carefully to avoid their code being vulnerable, crashing, or corrupting.
Rust eliminates those old traps and provides a friendly and sophisticated set of tools to help you navigate through and break down these barriers.Those programmers who need to “dive deep” into lower-level control can use Rust to do so without incurring the common risks of crashes or security vulnerabilities, nor do they need to grasp the intricacies of a volatile toolchain.Better yet, this language is designed to guide you naturally into writing reliable code that is efficient in terms of performance and memory usage.
Rust offers performance on par with C and C++ with a level of confidence that is thoroughly leading.
You trust that the compiler knows what you do not: in other words, you safely transition from “What is this?” to “Let’s run this code in production!”
This greatly lowers the barrier to entry.
It allows more people (including me✋) to write high-performance machine learning algorithms.
More people can contribute to the backend of the projects they use every day.
This will foster a larger community, more experimentation, and more sustainable projects—in other words, it will create a healthier and more diverse ecosystem.
Returning to the trends I mentioned earlier, you will again find the powerful force of full-stack development: the person responsible for model exploration (using Python) can dive deep and use Rust to rewrite their hot paths to optimize the final solution.
But how difficult is it to do this in practice?

How much faster can clustering algorithms be implemented in Rust?
I prepared a workshop for RustFest 2019: we implemented the K-Means clustering algorithm from scratch using ndarray (a Rust equivalent of NumPy).
A few weeks ago, I wrote some notes about the workshop, and the related materials can be found on GitHub: it consists of a series of test-driven exercises, each contributing to the final solution.
I cannot ignore this question: how fast is the example implementation of K-Means in Rust compared to scikit-learn?
A group of us, who were equally curious about this question, spent two days at RustFest implementing it, and we finally arrived at an answer.
Without @sitegui, @dunnock, and @ThomAub, this process would have taken much longer: thank you for your help!
Implementation
I published a cleaned-up K-Means implementation using a Rust crate: linfa-clustering (https://crates.io/crates/linfa-clustering). linfa-clustering is a subset of linfa (https://crates.io/crates/linfa)—we will discuss the latter in more detail later.
From the source code, you can see that the focus is on clear and understandable optimization configurations: it is an example implementation of the Lloyd algorithm.
Most speedup opportunities have not been utilized, and there is certainly room for further tuning and polishing—for example, it only uses multithreading for the assignment step, while the update step is still single-threaded.
To make a direct comparison, I wrote Python bindings for it (https://github.com/LukeMathWalker/linfa-python): linfa is on PyPi (https://pypi.org/project/linfa/), as a Python library.
I want to highlight the comparison:
-
Training time;
-
Inference time, measured when the model is exposed as a gRPC microservice.
We measured the time it takes to expose the model as a microservice to provide predictions, which is closer to how this code would perform in a real production environment.
You can find instructions, results, and code to reproduce the benchmark tests on GitHub (https://github.com/LukeMathWalker/clustering-benchmarks). The training benchmark tests using pytest-benchmark showed that when training a K-Means model on a dataset of 1 million points, linfa’s training speed is 1.3 times that of scikit-learn.
| Library | Average Training Time (ms) |
|---|---|
| Linfa (Python wrapper on Rust) | 467.2 |
| Scikit Learn | 604.7 (1.3 times slower) |
Overall, their speed comparison is quite close—due to the parallel nature of the assignment step, linfa may be slightly faster.
If you find this result puzzling, think again: we are comparing an implementation that only took two days of a teaching workshop with the implementation used by the currently most mature machine learning framework.
Crazy, right?
From the benchmark code, you can see that the linfa K-Means implementation provides an interface similar to scikit-learn.
from sklearn.datasets import make_blobs
import pytest
from linfa import KMeans
from sklearn.cluster import KMeans as sk_KMeans
@pytest.fixture(scope="session", autouse=True)
def make_data():
return make_blobs(n_samples=1000000)
def test_k_means_rust(benchmark, make_data):
dataset, cluster_index = make_data
model = KMeans(3, max_iter=100, tol=1e-4)
labels = benchmark(model.fit_predict, dataset)
assert len(labels) == len(cluster_index)
def test_k_means_python(benchmark, make_data):
dataset, cluster_index = make_data
# Using the same algorithm
model = sk_KMeans(3, init="random", algorithm="full", max_iter=100, tol=1e-4, n_init=1)
labels = benchmark(model.fit_predict, dataset)
assert len(labels) == len(cluster_index)I also want to introduce you to the Rust version—the interface looks slightly different (for some reason, I might discuss this in another blog post), but you can easily identify the same steps:
use linfa::clustering::{generate_blobs, KMeans, KMeansHyperParams};
use ndarray::array;
use ndarray_rand::rand::SeedableRng;
use rand_isaac::Isaac64Rng;
fn main() {
// Our random number generator, seeded for reproducibility
let mut rng = Isaac64Rng::seed_from_u64(42);
// For each of our expected centroids, generate 1000 data points around it (a "blob")
let expected_centroids = array![[10., 10.], [1., 12.], [20., 30.], [-20., 30.]];
let dataset = generate_blobs(10000, &expected_centroids, &mut rng);
// Configure our training algorithm
let n_clusters = 4;
let hyperparams = KMeansHyperParams::new(n_clusters)
.max_n_iterations(200)
.tolerance(1e-5)
.build();
// Infer an optimal set of centroids based on the training data distribution
let model = KMeans::fit(hyperparams, &dataset, &mut rng);
// Assign each point to a cluster using the set of centroids found using `fit`
let labels = model.predict(&dataset);
}Inference Benchmarking
As mentioned earlier, using a dedicated microservice to serve machine learning models has become an established pattern in the industry.
However, these microservices often have little or no business logic: they are merely a remote function call.
Given a serialized machine learning model, can we fully automate/abstract API generation? With the increasing popularity of TensorFlow Serving, my idea has been validated.
Therefore, I decided to benchmark three scenarios:
-
K-means from scikit-learn running on a gRPC server in Python;
-
K-means from linfa (Python wrapper) running on a gRPC server in Python;
-
K-means from linfa (Rust) running on a gRPC server in Rust (tonic, https://github.com/hyperium/tonic).
I have not done any form of tuning on these gRPC web servers:what we are evaluating is out-of-the-box performance.I invite you to check the source code (Rust/Python).
Linfa on the Rust web server processes requests 25 times faster than scikit-learn, and 7 times faster than linfa (Python wrapper) on the Python gRPC server.
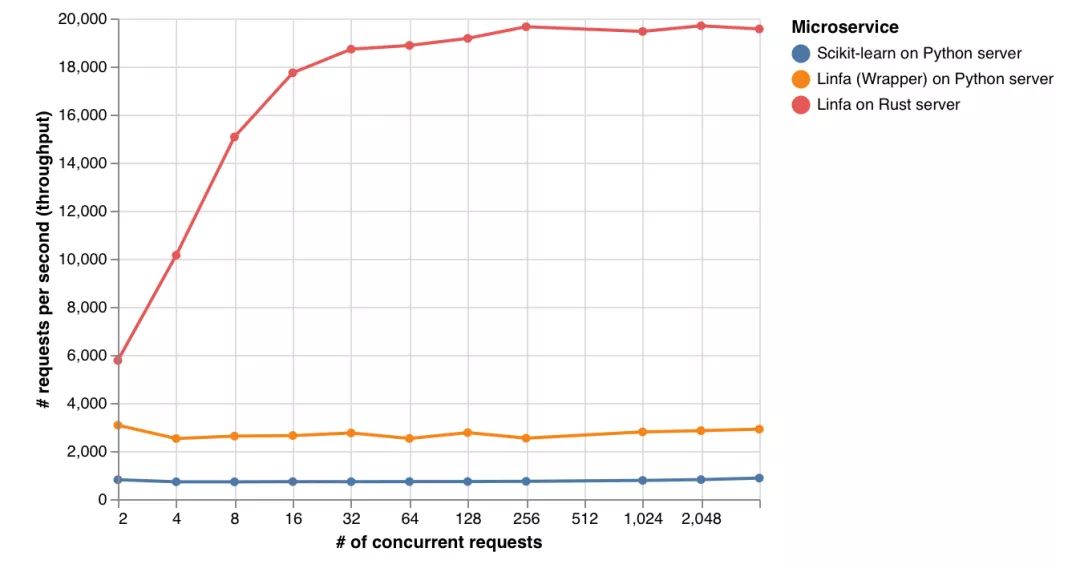
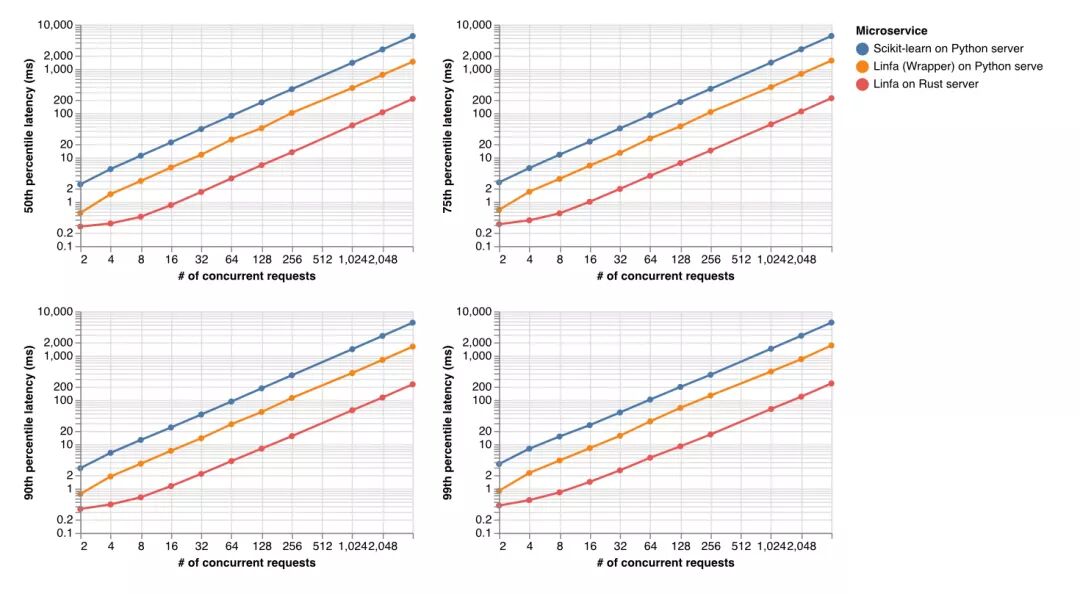
Latency (how long it takes to provide a response) is also similar, where linfa on the Rust web server is consistently 25 times faster than scikit-learn and 6 times faster than linfa (Python wrapper) on the Python web server.
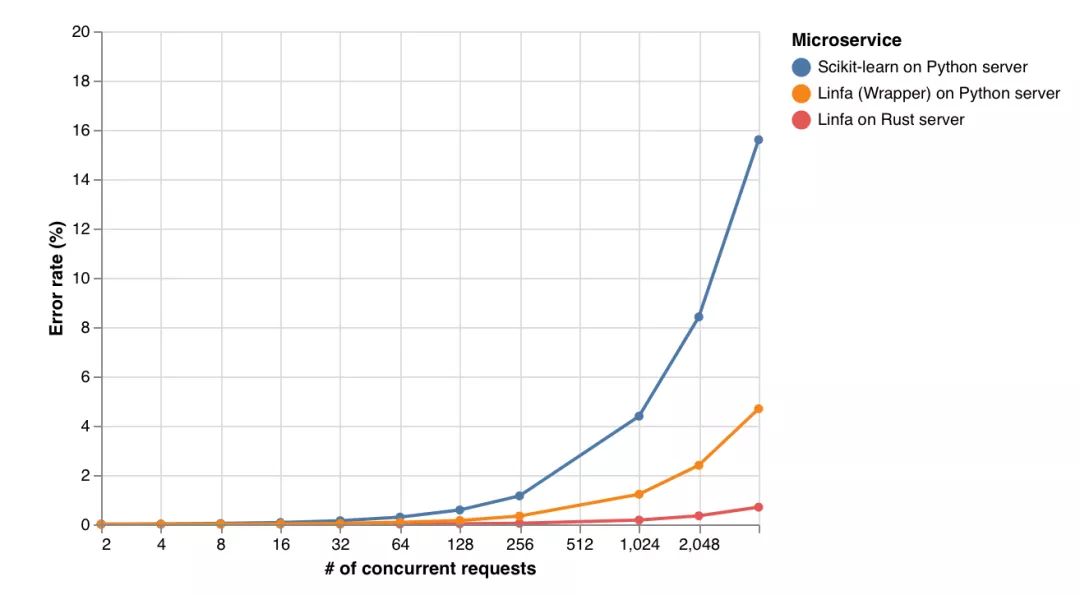
Linfa on the Rust web server also has the lowest error rate under heavy load.
New Workflows
This experiment is too small in scale to draw definitive conclusions, and I believe you can find faster implementations of the Lloyds algorithm for K-Means.
But I hope these results are enough to convince you that Rust can indeed play an important role in machine learning development. Anyone can write such a Rust implementation with just a little knowledge of ndarray (you can try the materials provided in the workshop)—how much potential have countless machine learning practitioners wasted due to the entry barriers of C and C++?
If that is not enough, I also want to tell you that Rust can not only replace the C and C++ backends of Python—it can also leverage its evolving asynchronous ecosystem to handle deployment tasks.
It is quite simple to do:
-
Use Rust-based Python libraries to identify candidate models;
-
Serialize the final model;
-
Provide the final model’s path and the expected format of input data as configuration;
-
Reap the rewards.

This is definitely an idea worth exploring in 2020.
Moving Forward
As mentioned earlier, linfa-clustering is a subset of linfa, which is a general machine learning framework in Rust that I plan to focus on in 2020.
Even at this point, it is premature to call it a framework: there is nothing beyond linfa-clustering yet😀.
There is a long way to go to achieve its bold mission statement, but interest in the Rust ecosystem in machine learning and related fields is growing: https://github.com/rust-ml/discussion/issues/1, https://github.com/rust-lang/wg-governance/issues/11.
Sometimes you just need to ignite a spark to expect it to blaze into a fire.
In fact, I firmly believe that only through community efforts can we support, build, and maintain a machine learning ecosystem in Rust—there are no shortcuts.
The Rust ecosystem does indeed contain a wealth of machine learning crates—just look at how many things come up when you search for machine learning on crates.io.
We do not need to rewrite everything from scratch: I see linfa as a meta-package, a collection of selected algorithm implementations in the Rust ecosystem. It is your first stop for meeting your machine learning needs, just like scikit-learn in Python.
If this article resonates with you, please take a look at the roadmap (https://github.com/LukeMathWalker/linfa/issues)—I look forward to your contributions!
Feedback, suggestions, and comments on this article are very welcome: you can reach me on Twitter @algo_luca, on GitHub @LukeMathWalker, or via email at [email protected].
Further Reading:
https://www.lpalmieri.com/posts/2019-12-01-taking-ml-to-production-with-rust-a-25x-speedup/
InfoQ Reader Group is now online! You can scan the QR code below to add the InfoQ assistant, reply with the keyword “Join Group” to apply for group membership. You can chat freely with InfoQ readers and editors, and receive valuable technical gifts, as well as participate in valuable activities. Come join us!

 Tap to view and reduce bugs👇
Tap to view and reduce bugs👇