Skip to content
Many people have heard of the term cache coherency, but do not fully understand the considerations for System-on-Chip (SoC) devices, especially those using Network-on-Chip (NoC). To understand the current issues, one must first grasp the role of cache in the memory hierarchy.
Cache in Memory Hierarchy
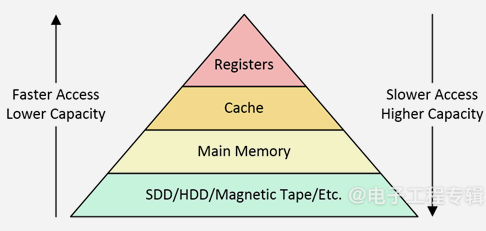
The CPU has relatively few extremely fast registers. The CPU can access these registers within a single clock cycle. However, their storage capacity is small. In contrast, accessing main memory to read or write data takes many clock cycles. This often leaves the CPU idle for most of the time.
In 1965, British computer scientist Maurice Wilkes proposed the concepts of cache and memory caching. This involved placing a small amount of fast memory, called cache, near the CPU. The term “cache” itself comes from the French word “cacher,” meaning “to hide” or “to conceal,” with the concept being to use cache to hide main memory from the CPU. A high-level view of the memory hierarchy involving simple caching is shown in Figure 1.
Figure 1: A high-level view showing the position of cache in the memory hierarchy. (Source: Arteris)
This process operates based on two key points. First, when a program running on the CPU involves a location in main memory, it typically operates on several nearby locations. Thus, when the CPU requests a single piece of data from main memory, the system brings in data from nearby locations.
This approach ensures that relevant data is available when needed. Secondly, programs often perform many operations on the same dataset. Therefore, storing frequently used data in the cache closest to the CPU is beneficial. This proximity allows for faster data access and processing.
In SoC, cache is implemented on-chip in high-speed, high-power, low-capacity SRAM. Meanwhile, main memory is implemented off-chip on printed circuit boards (PCBs), typically in the form of low-speed, low-power, high-capacity DRAM.
To minimize latency, designers have added multi-level caches in many contemporary SoCs. These caches typically include two levels: L1 and L2. L1 cache is closest to the CPU, has the smallest capacity, but the fastest access speed, usually within 1 to 2 clock cycles. L2 cache is slightly further from the CPU, has a larger capacity, but slower access speed, typically between 4 to 10 clock cycles.
Multi-level caches maximize performance while minimizing off-chip accesses to main memory. Accessing this main memory can consume hundreds of clock cycles. By using multi-level caches, data can be retrieved faster from these caches rather than the slower main memory, thereby improving the overall efficiency of the system.
When multiple CPU cores are involved, all this complexity increases. Consider a common scenario where a cluster contains four CPU cores labeled from core 0 to 3, each with its dedicated L1 cache. In some implementations, each core also has its dedicated L2 cache. In other designs, cores 0 and 1 share an L2 cache. These different configurations affect how data is stored and accessed at different cache levels.
Typically, all processor cores in a single cluster are homogeneous, meaning they are of the same type. However, having multiple clusters of processor cores is becoming increasingly common. In many cases, the cores in different clusters are heterogeneous, or of different types. For example, in Arm’s big.LITTLE technology, the “big” cores are designed for maximum performance but are used less frequently.
The “LITTLE” cores, on the other hand, are optimized for energy efficiency, used more frequently but with lower performance. For instance, in Arm-based smartphones, the “big” core might be activated for relatively infrequent tasks like Zoom calls. In contrast, the “LITTLE” cores can handle more common, less demanding tasks like playing music and sending text messages.
Maintaining Cache Coherency
In systems where multiple processing units with independent caches share the same main memory, shared data may have multiple copies. For example, there may be one copy in main memory, while each processor may have more copies in its local cache. To maintain cache coherency, all changes to a data copy must be reflected in all copies. This can be achieved by updating all copies with the new data or invalidating other copies.
Cache coherency can be maintained under software control. However, managing coherency in software is very complex and difficult to debug. Nevertheless, coherency can still be achieved through techniques like cache flushing, which marks modified data stored in the cache as dirty, meaning it must be written back to main memory. Cache flushing can be performed across the entire cache or at specific addresses, but it consumes a significant number of CPU cycles and must be executed on all CPUs holding copies of the data.
The preferred method for maintaining cache coherency is to use dedicated hardware to manage the cache without the software being aware. For example, caches associated with cores in a processor cluster typically include all the hardware necessary to maintain cache coherency.
SoCs are composed of many functional blocks known as Intellectual Property (IP) blocks. A processor cluster is one such IP block. A common way to connect IP blocks is through NoC.
In many SoC designs, there is no need for coherency outside the processor cluster, allowing the use of non-coherent or IO-coherent AXI5 or AXI5-Lite NoCs, such as Arm’s NI or Arteris’s FlexNoC. However, for SoC designs with multiple processor clusters that lack inherent cache coherency, or when integrating third-party IP or custom accelerator IP that requires cache coherency, a coherent NoC is necessary. Examples in this regard include Arm CMN using AMBA CHI protocol or Arteris Ncore using AMBA ACE and/or CHI.
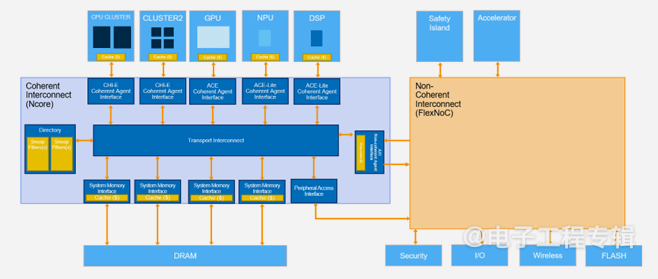
Figure 2: In the above example, the main system uses a coherent NoC, while the secure island uses a non-coherent NoC. (Source: Arteris)
Applying cache coherency universally across the chip can consume significant resources and may not be necessary for specific components. Therefore, as shown in Figure 2, isolating cache coherency to subsets of the chip, such as CPU clusters and specific accelerator IP, can utilize resources more effectively and reduce complexity. Coherent NoCs (like Ncore) perform excellently in applications requiring strict synchronization. Meanwhile, non-coherent interconnects (like FlexNoC) are ideal for scenarios where strict synchronization is not required.
Designers can strategically balance the need for data coherency in specific areas while benefiting from more streamlined communication channels where strict coherency is not necessary. In today’s complex heterogeneous SoCs, the synergy between coherent and non-coherent interconnects has become a strategic advantage, enhancing the overall efficiency and adaptability of the system.
Andy Nightingale, Vice President of Product Management and Marketing at Arteris, has over 36 years of experience in the high-tech industry, including 23 years at Arm in various engineering and product management positions.
(Original article published on EE Times sister site EDN, reference link: SoC design: When a network-on-chip meets cache coherency, translated by Franklin Zhao.)
This article is copyrighted by Electronic Engineering Times and may not be reproduced.