Address:https://github.com/NotPunchnox/rkllama
RKLLama is an open-source server and client solution designed to run large language models (LLMs) optimized for the Rockchip RK3588 (S) and RK3576 platforms, and to interact with them. Unlike solutions such as Ollama or Llama.cpp, RKLLama fully utilizes the Neural Processing Units (NPU) on these devices, providing an efficient and high-performance solution for deploying artificial intelligence and deep learning models on Rockchip hardware.
RKLLama comes equipped with a REST API, allowing you to easily build custom clients tailored to specific needs. It also provides an integrated command-line interface (CLI) client, simplifying the process of testing and interacting with the API.
Based on this video:
https://www.youtube.com/watch?v=Kj8U1OGqGPc
Download
git clone https://github.com/notpunchnox/rkllama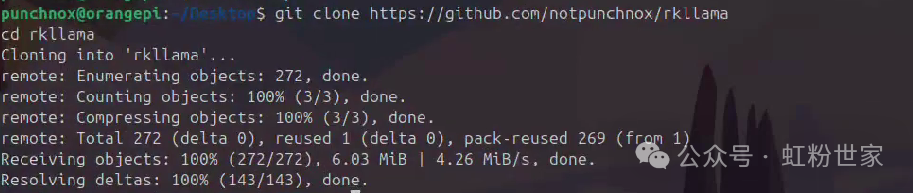
To install, execute setup.sh in the download directory.
bash setup.sh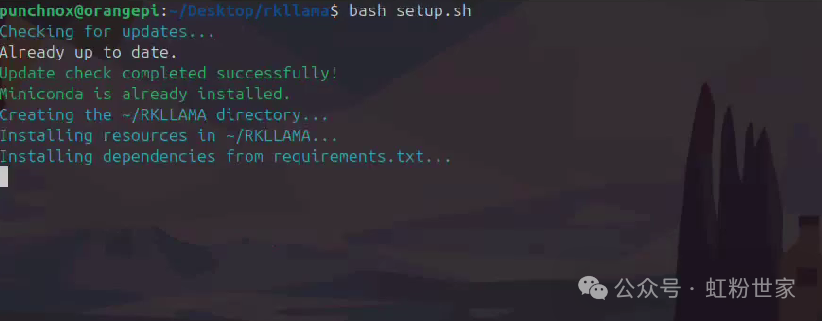
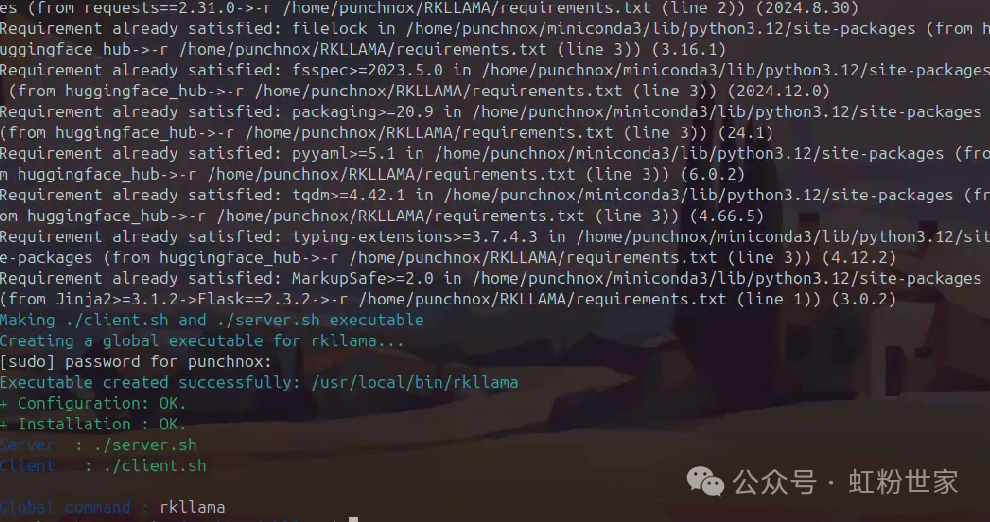
Successful installation display
Run rkllama to see available commands
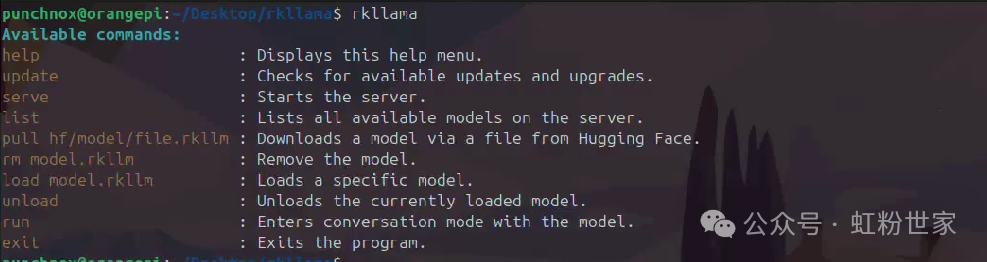
Available commands:
- help: Displays this help menu.
- update: Checks for available updates and upgrades.
- serve: Starts the server.
- list: Lists all available models on the server.
- pull hf/model/file.rkllm: Downloads a model from a file on Hugging Face.
- rm model.rkllm: Deletes a model.
- load model.rkllm: Loads a specific model.
- unload: Unloads the currently loaded model.
- run: Enters a dialogue mode with the model.
- exit: Exits the program.
Start the service
rkllama serve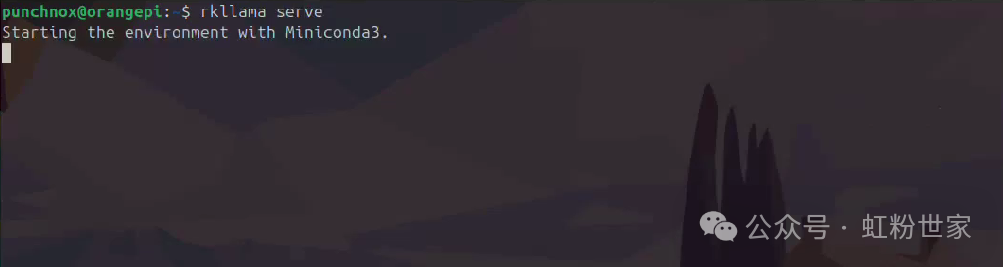
Display after successful start
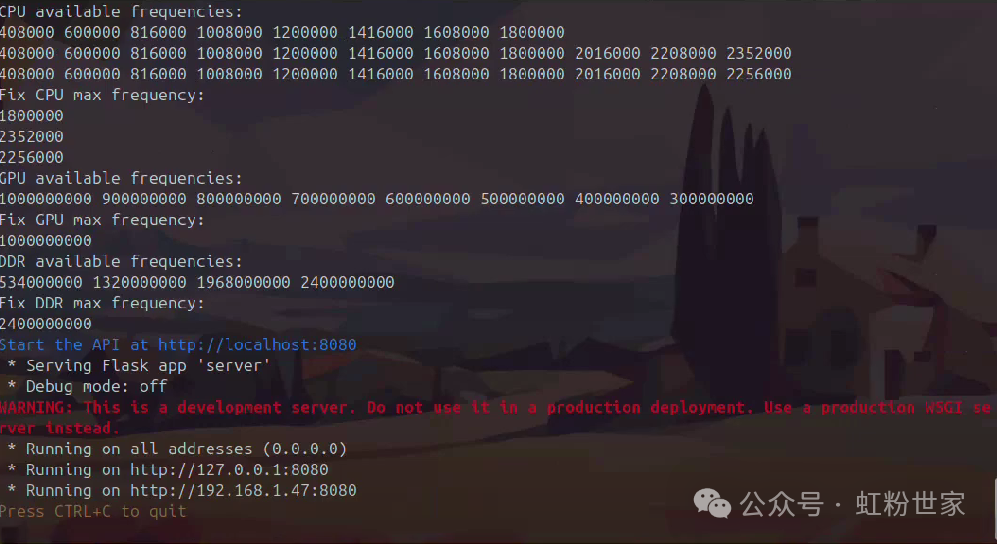
In another terminal, download the model
rkllama pull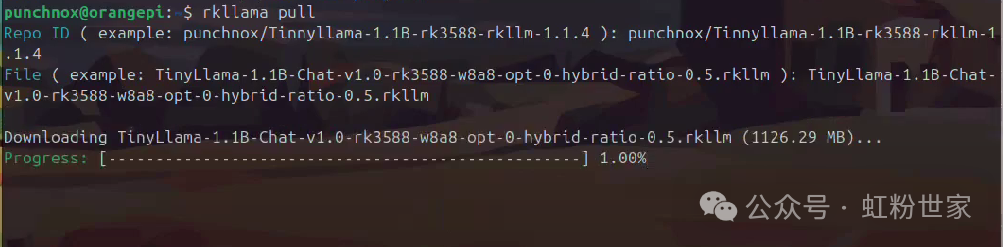
Manually download the model and place it in RKLLAMA/models. You can download the Qwen2.5 model from https://huggingface.co/c01zaut/Qwen2.5-3B-Instruct-RK3588-1.1.4/tree/main
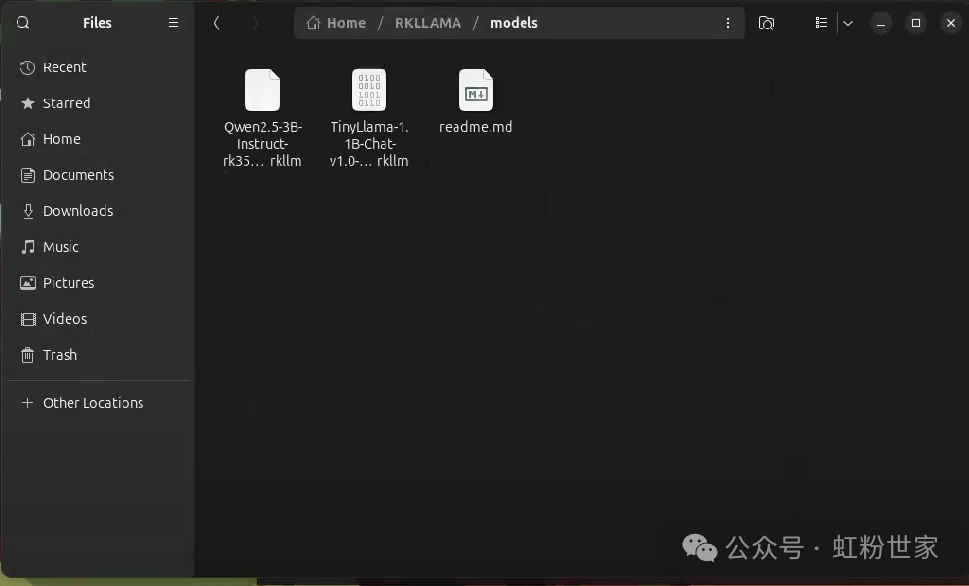
At this point, run
rkllama listto see the available models
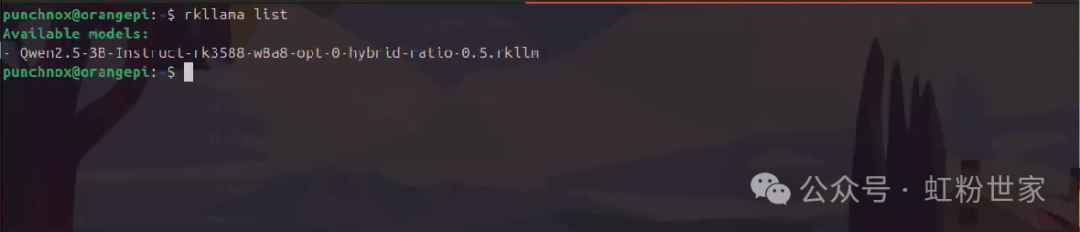
Run this model
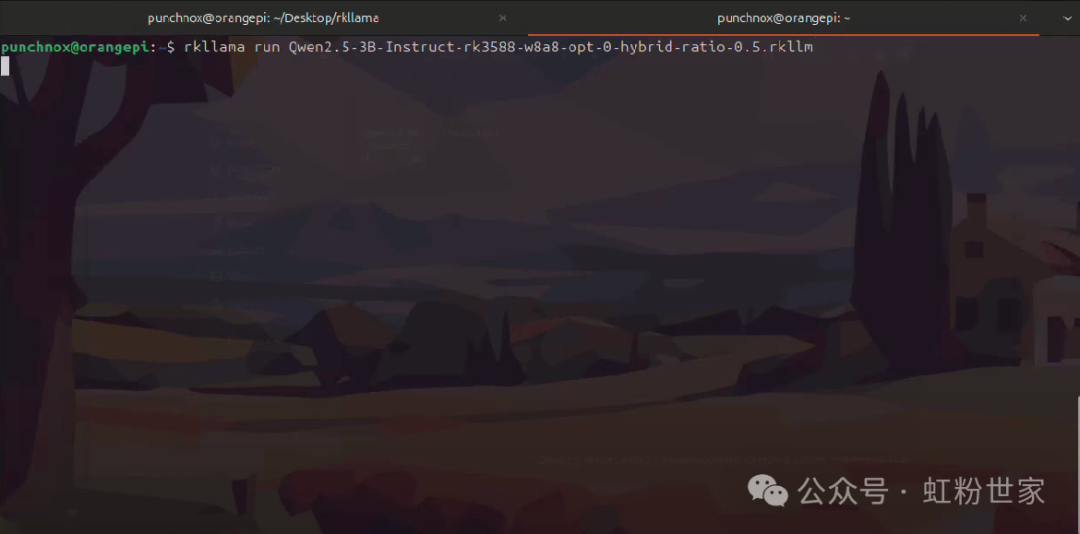
After starting, you can see
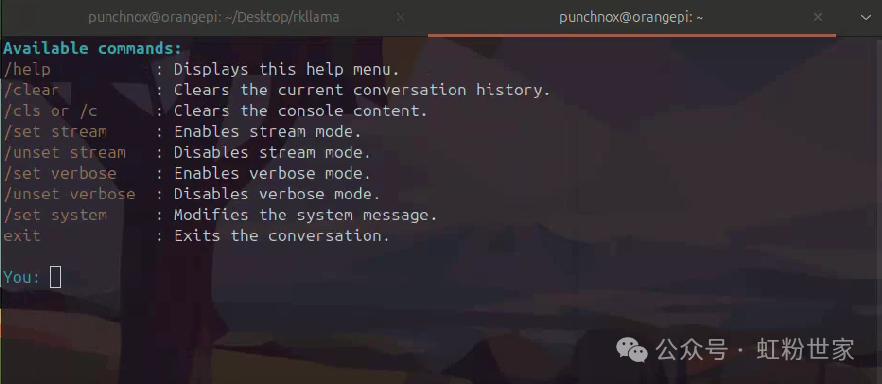
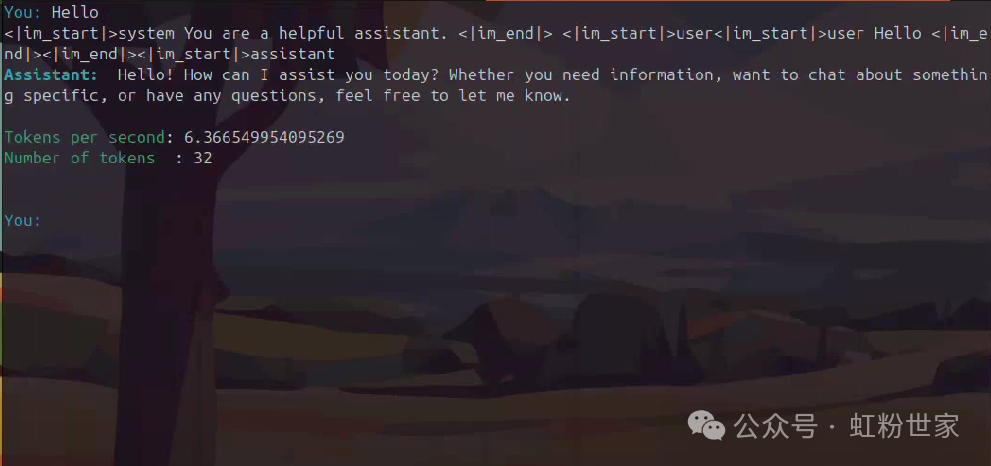
After ‘You:’, you can enter commands or prompts
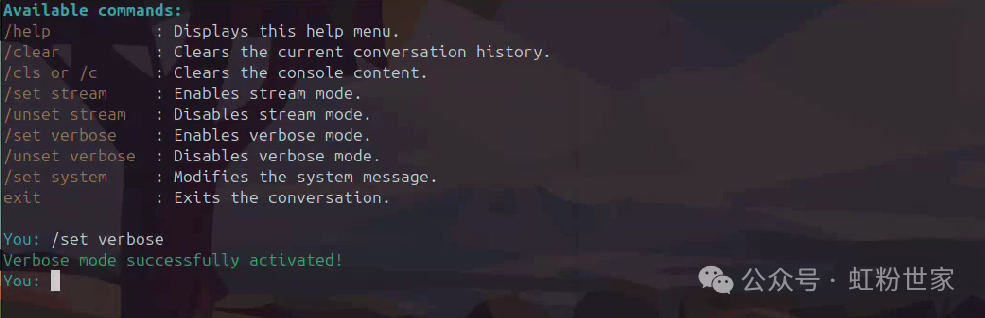
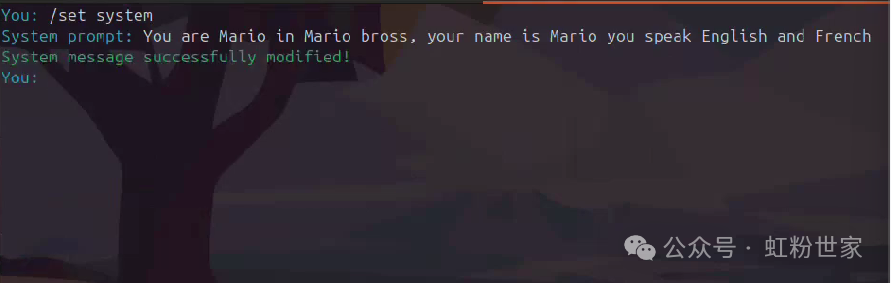
Set system prompts
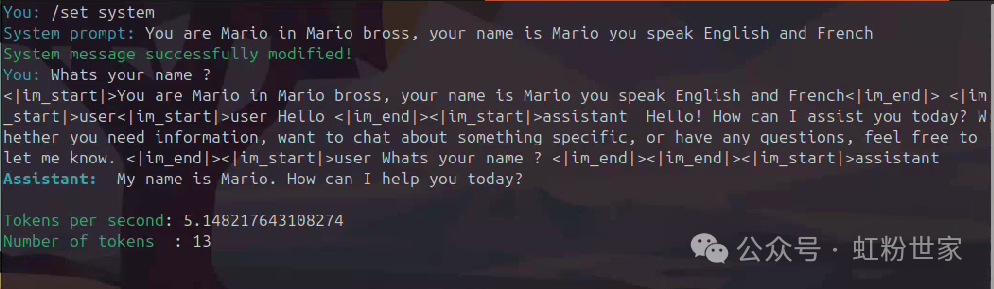
For more detailed instructions, refer to the GitHub readme.