Follow 👆 the official account and reply with 'python' to receive a beginner's tutorial! Source from the internet, please delete if infringing.1. Identifiers
An identifier is a name given to variables, constants, functions, classes, and other objects.
First, it must be stated that Python strictly distinguishes between uppercase and lowercase letters in any context!
Python has the following rules for naming identifiers:
-
The first character must be a letter from the alphabet or an underscore ‘_’
For example, a, Ak, _set_id, green are all valid, but $abc, &_a, ~bashrc, 123abc are not!
Some students might ask, can Chinese characters be used? Great! I really like and agree with this way of thinking and questioning; it helps you better explore the core principles. The answer is yes! For example:
>>> 我 = 1
>>> 我1
>>> 什么 = "apple"
>>> print(什么) # appleWith Python 3 fully supporting Unicode, compatibility with Chinese is getting better and better. It is indeed possible to use Chinese as variable names; if you don’t believe it, you can try it yourself in IDLE.
However, even though Chinese identifiers are supported, no one would actually do this, and I do not recommend it. Please adhere to the principle that the first character must be a letter from the alphabet or an underscore ‘_’.
Additionally, identifiers starting with an underscore usually have special meanings. For example, a variable starting with a single underscore, such as _foo, indicates a class member that should not be accessed externally and must be accessed through the interface provided by the class, and cannot be imported with “from xxx import *”; while a variable starting with double underscores, such as __foo, indicates a private member of the class; identifiers starting and ending with double underscores (like __foo__) are reserved for special methods in Python, such as __init__() which represents the constructor of the class. These will be discussed in detail later; for now, just know their special nature.
-
The other parts of the identifier can consist of letters, numbers, and underscores.
This means that identifiers can contain numbers in their other parts, as long as the first character is not a number. As for special characters? Of course, they are still not allowed. Therefore, a123c_, bbc, city_of_china, etc. are valid, while a&b, king-of-the-world, [email protected] are not.
Additionally, due to the visual similarity between l (lowercase L) and the number 1, as well as the uppercase O and the number 0, please try not to have them appear next to each other to maintain semantic clarity and ensure that misreading does not occur.
Similarly, we can continue to think outside the box; inserting Chinese into English is also syntactically permissible, but definitely do not do this!
>>> a这都能行b舅服你 = 100
>>> a这都能行b舅服你
100-
Identifiers are case-sensitive.
This is based on Python’s strict distinction between uppercase and lowercase letters, so identifiers abc and ABC are two different identifiers.
-
Variable names should be all lowercase, while constant names should be all uppercase.
This is not a requirement at the syntax level but rather a coding standard. Although you can use PI to represent a variable, we usually consider this to represent a constant for Pi.
-
Function and method names should use lowercase with underscores.
This is also not a syntactic requirement but a coding standard. When defining a function or method name, please try to use naming conventions like get, set, count_apple, total_number, etc.
-
Class names should use CamelCase.
This is also not a syntactic requirement but a coding standard. CamelCase refers to capitalizing the first letter of each word, arranged together like a camel’s hump. For example, ThreadMixIn, BrokenBarrierError, _DummyThread, etc.
-
Module and package names should be in lowercase.
Try to keep module and package names in lowercase and do not use the same names as standard libraries or well-known third-party libraries.
Finally, it is important to remind everyone:
Do not use keywords and built-in function names for variable naming!
Next, we will discuss what keywords are in Python, and the knowledge about built-in functions will come in later chapters.
2. Python Reserved Words
Python reserved words, also called keywords, are special identifiers officially designated by the Python language for syntax functions, and they cannot be used as any custom identifier names. Keywords consist only of lowercase letters. The standard library in Python provides a keyword module that can output all keywords for the current version:
>>> import keyword
>>> keyword.kwlist
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']You can also refer to the table below:
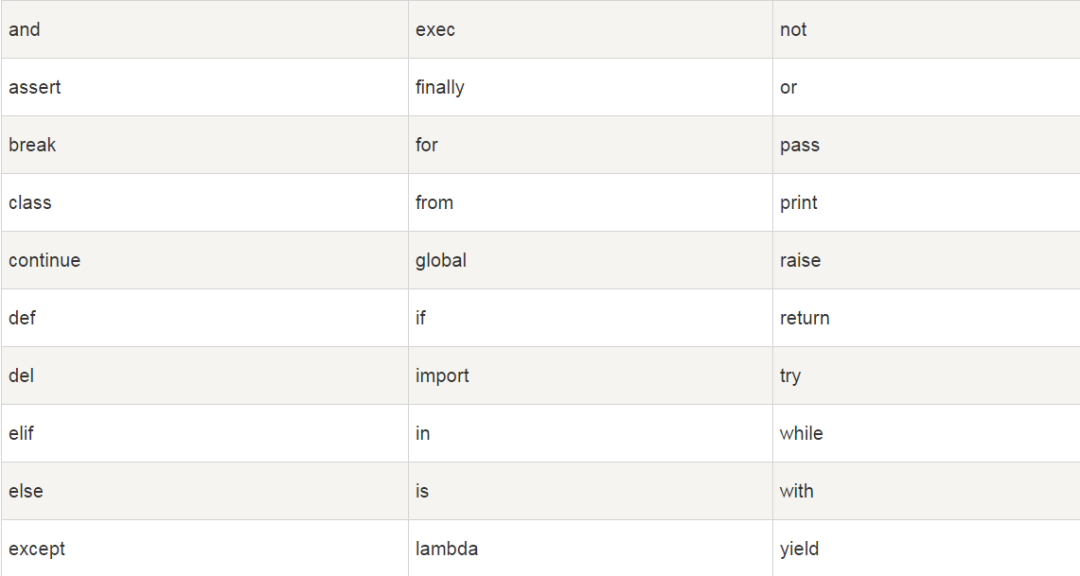
So what happens if you make this mistake? For example:
>>> if = 1
SyntaxError: invalid syntax
>>> print(and)
SyntaxError: invalid syntax
>>> def = "hi"
SyntaxError: invalid syntaxDid you see that? It directly prompts a syntax error.
In addition to not being able to use keywords as identifiers, as we emphasized earlier, you also cannot use the same names as built-in functions. Python has many built-in functions, for example, sum is a function for summing, and let’s look at the consequences of incorrect naming:
>>> sum([1,2,3,4])
10
>>> sum = "incorrect identifier name"
>>> sum([1,2,3,4])
Traceback (most recent call last): File "<pyshell#19>", line 1, in <module> sum([1,2,3,4])
TypeError: 'str' object is not callableRegardless of the significance of sum([1,2,3,4]), its function is to add 1, 2, 3, and 4 together to get 10. Then, giving a variable the same identifier name of sum results in an exception when calling sum([1,2,3,4]) later on, with the error reason being that str is not a callable type. Ultimately, it is due to the name sum being duplicated.
3. Comments
In the programs we write, there are not only codes but also many comments. Comments serve explanatory and helpful purposes; they are effectively non-existent during code execution, transparent, and do not participate in any work. However, they play an indispensable role in code maintenance, explanation, testing, and so on. Every programmer should strive to write high-quality comments. There are many high-level articles and discussions on the specific topic of comments, please search and learn on your own. Here, we will only discuss how to comment in Python.
-
Single-line comments
In Python, a single-line comment starts with the symbol ‘#’, and everything from it to the end of the line is comment content.
#!/usr/bin/python3
# The following method serves to…..
# First comment
# I am a single-line comment
# This is an empty function that does nothing. This comment is also useless.
def main():
pass # pass indicates a placeholder, doing nothing. Why do I need to comment on it???-
Multi-line comments
Python does not have a true multi-line comment (block comment) syntax. You can only start each line with a ‘#’, pretending to be a multi-line comment,囧 (Do you have any emojis?).
# First line comment
# Second line comment
# Third line comment
def func():
print("This is a sad story!")-
Documentation comments
In certain specific locations, content enclosed in triple quotes is also treated as a comment. However, this type of comment has a specific purpose, which is to provide documentation content for doc, and this content can be automatically collected into help documentation by existing tools. For example, the documentation for functions and classes:
def func(a, b):
"""
This is the documentation for the function.
:param a: Addend
:param b: Addend
:return: Sum
"""
return a + b
class Foo:
"""
This class initializes an age variable
"""
def __init__(self, age):
self.age = ageIt must be emphasized that this type of comment must immediately follow the definition body and cannot be placed at arbitrary positions.
4. The First Two Lines of Code
Many times, we see similar lines of code starting with ‘#’ at the beginning of some py script files; they are not comments but some settings.
#!/usr/bin/env python
# -*- coding:utf-8 -*-The first line: It specifies the Python interpreter to run this script, specific to Linux, not needed for Windows. Under the env method, the system will automatically use the Python pointed to by the environment variable. Another way is #!/usr/bin/python3.6, which forces the use of the python3.6 interpreter in the system to execute the file. This method is not good; if your local Python3.6 version is deleted, an error of ‘interpreter not found’ will occur.
Regardless of which method is used, both refer to settings when executing the script using ./test.py in Linux; when using methods like python test.py or python3 test.py, this line does not take effect.
For example, I wrote a script as follows:
#!/usr/bin/python2
print "hello" # Note here that there are no parentheses, this is the print method of Python 2 versionCarefully observe the execution process below, and you will find that no matter how you set the first line of code, it will be executed according to the Python version called at the time:
[feixue@feixue-VirtualBox: ~/python]$ cat test.py
#!/usr/bin/python2
print "hello"
[feixue@feixue-VirtualBox: ~/python]$ python2
Python 2.7.12 (default, Nov 19 2016, 06:48:10) [GCC 5.4.0 20160609] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> exit()
[feixue@feixue-VirtualBox: ~/python]$ python3
Python 3.6.1 (default, Aug 15 2017, 11:19:20) [GCC 5.4.0 20160609] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> exit()
[feixue@feixue-VirtualBox: ~/python]$ python2 test.py
hello
[feixue@feixue-VirtualBox: ~/python]$ python3 test.py
File "test.py", line 3
print "hello"
^SyntaxError: Missing parentheses in call to 'print'So what is the use of this line? It’s used like this.
[feixue@feixue-VirtualBox: ~/python]$ chmod +x test.py
[feixue@feixue-VirtualBox: ~/python]$ ll test.py
-rwxrwxr-x 1 feixue feixue 34 Sep 5 22:57 test.py*
[feixue@feixue-VirtualBox: ~/python]$ ./test.py
helloThe second line: The encoding method of the code. This is not the encoding of the data that the program needs to process, but the character encoding of the program itself. In Python 3, Unicode is fully supported, and the default encoding is UTF-8, so we don’t have to worry about Chinese issues or garbled text issues, so this line can actually be omitted. But in Python 2, character encoding is a very troublesome issue, and usually requires specifying this line. If you want to customize another encoding type, you can do it like this: # — coding: cp-1252 –, but unless there is a compelling need, please do not take unnecessary risks and stick to using UTF-8 encoding.
These two lines should be at the top of the file, at the leftmost position, without spaces or blank lines, utf8 and utf-8 are both acceptable.
PS: What does the ‘-*-‘ mean? It’s just for decoration, nothing more,囧.
In addition to these two lines, we sometimes also include the author’s name, contact address, copyright statement, version statement, etc., all depending on personal preference.
5. Statements and Indentation
A statement: In code, the shortest code that can fully express a certain meaning, operation, or logic is called a statement. Statements typically do not exceed one line; those exceeding one line are called multi-line statements.
For example, the following are all considered statements:
a = apple
from . import modles
print("haha")
lis.append(item)Python’s standard statements do not require the use of semicolons or commas to indicate the end of a statement; simply moving to the next line indicates that the statement has ended and the next one begins.
A code block: A group of statements linked together to accomplish a specific function constitutes a code block. There are various types of code blocks, including conditionals, loops, functions, and classes. The first line of a code block usually starts with a keyword and ends with a colon (:). For example:
# This is a conditional block of code
if expression:
pass
elif expression:
pass
else:
passFor example:
# This is a class code block
class Foo:
def __init__(self, name, age):
self.name = name
self.age = age
def get_name(self):
return self.name
# This is a function code block
def func(a, b):
summer = a+b
return summer*2Python’s most distinctive syntax is the use of indentation to indicate code blocks, without the need for curly braces ({})
The number of spaces for indentation is variable, but statements within the same code block must have the same number of indentation spaces.
If the number of spaces for indentation is inconsistent, an indentation error will be thrown (remember the exception name IndentationError! Newbies often encounter it):
File "test.py", line 6
print ("False") # Indentation is inconsistent, will lead to runtime error
^IndentationError: unindent does not match any outer indentation levelPEP8 (Python’s official coding standard): It is recommended to use four spaces for indentation! In text editors, you need to set it to automatically convert tabs to 4 spaces to ensure that tabs and spaces are not mixed. In Pycharm, the tab key is automatically converted into 4 spaces for indentation. In the Linux environment, such as the vim editor, please be sure to use spaces and not the tab key!
So what is the correct way to indent?
-
All ordinary statements start at the leftmost position without indentation.
-
For all statement blocks, the first line does not need to be indented, and all lines following the line ending with a colon must be indented.
-
Once the statement block ends, revert the indentation to indicate that the current block has ended.
-
Statement blocks can be nested, so indentation can also be nested.
For example, let’s write an if/else control statement block:
First, the first statement does not need indentation:
if i > 10:Then the second statement, which is now inside the if, requires indentation:
if i > 10:
i = i + 10 # 4 spaces to the leftThe next statement is still inside the if, so it maintains the same indentation as the second statement:
if i > 10:
i = i + 10 # 4 spaces to the left
print(i) # 4 spaces to the leftThe fourth statement indicates that we have finished the if branch and are moving to the else branch, so the indentation needs to be reverted.
if i > 10:
i = i + 10 # 4 spaces to the left
print(i) # 4 spaces to the left
else:The fifth statement enters the else block and requires 4 spaces of indentation:
if i > 10:
i = i + 10 # 4 spaces to the left
print(i) # 4 spaces to the left
else:
i = i - 10 # 4 spaces to the leftThe sixth statement indicates that we have completed the else branch, and the entire if/else process is finished, so the indentation should revert.
if i > 10:
i = i + 10 # 4 spaces to the left
print(i) # 4 spaces to the left
else:
i = i - 10 # 4 spaces to the left
print("apple") # Indentation reverts, this is no longer related to if or else. Now let’s look at a nested indentation example, using two nested for loops:
for i in range(10):
for k in range(10): # This is also a for loop, and since it is nested inside another for, it requires indentation
if k != i: # If inside the double loop, requires 2 levels of indentation, i.e., starting from the left with 8 spaces
print(k) # Another nested if statement, requires another 4 spaces of indentation, totaling 12 spaces
else: # If ends, revert 4 spaces, starting the else branch
print(i+k) # Increases indentation again
print(i) # This time, not only does the else end, but the internal for also ends, reverting 8 spacesAt first, the indentation syntax may confuse you about when to indent, when to revert, and how many spaces to indent.
But with more writing and observation, you will quickly master it and no longer make mistakes. Python’s indentation syntax design is different from all other languages; it is a unique feature that has sparked much debate. Those who like it love it, finding it concise and clear, saving a lot of effort, and ensuring code neatness. Those who dislike it feel that it is cumbersome and prone to syntax errors, and that formatting tools cannot be used.
Writing multiple statements in the same line:
Earlier we said that Python typically has one statement per line, and a statement usually does not exceed one line. In fact, from a syntactic perspective, Python does not completely prohibit using multiple statements in one line; you can also use a semicolon to achieve this, for example:
import sys; x = 'multiple statements'; sys.stdout.write(x + '\n')The above line actually contains 3 statements, separated by semicolons, but it is strongly recommended not to do this, as it can lead to code readability issues, increased maintenance time, and a higher chance of errors. It is better to use three lines to express it; it is not only more elegant but also increases the line count, allowing you to tell your boss that you wrote 2 more lines today, ^_^.
Multi-line statements: The previous example was multiple statements in one line, but if a statement is too long, it can also occupy multiple lines, which can be achieved using a backslash (\):
string = "i love this country,"
+"because it is very beautiful!"
+ "how do you think about it?"
+ "Do you like it too?"For multi-line statements within [], {}, or (), you can directly hit enter without needing a backslash. For example:
result = subprocess.Popen("ipconfig /all", stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
shell=True, check=True)PEP8 recommends that each line should not exceed 79 characters. When it is time to break a line, just break it!
6. The pass Statement
The pass statement is a placeholder statement; it does nothing and is written to ensure the correctness of the syntax. The pass statement can be used in the following scenarios:
-
When you do not know how to write the subsequent code
-
When you do not need to write code details
-
When syntax requires it, but there is no actual content to write
-
Other scenarios that you deem necessary
For example:
# I just want to indicate that this func function needs three parameters, and what it actually does is not important
# However, if the function body is empty, it will cause a syntax error
# At this time, pass is the best choice.
def func(a,b,c):
pass7. Whitespace Characters and Blank Lines
Blank lines, whitespace characters, and code indentation are different; they are not part of Python syntax. Blank lines or whitespace characters are ignored like air. Continuous blank lines or whitespace characters are no different from a single blank line. Not inserting blank lines or whitespace characters during writing will not cause errors when the Python interpreter runs. However, the role of whitespace is to separate two different functions or meanings of code, facilitating future maintenance or refactoring.
PEP8 has specific recommendations for blank lines and whitespace.
Use blank lines to separate functions or class methods, indicating the start of a new segment of code. Also use a blank line to separate the entry of classes and functions to highlight the beginning of function entry.
When assigning variables, leave a blank space on both sides of the equal sign. A space follows a comma.
See the following code, which adheres to standard coding conventions, leaving the specified blank lines and whitespace characters in the required places.
#!/usr/bin/env python
# -*- coding:utf-8 -*-
class Foo:
pass
def func(a, b):
pass
if __name__ == '__main__':
pass8. String Representation
The following chapters on string data types will provide a deeper introduction to strings. Here, it serves as a preliminary knowledge foundation.
A string represents a continuous sequence of characters, which can be meaningful words, phrases, sentences, or meaningless character combinations. It does not depend on what it consists of internally but rather whether it is enclosed in quotes.
For example, abc might be a variable, but “abc” is definitely a string! (Again, it must be emphasized that there are no Chinese punctuation marks in the coding world; all symbol types are in English half-width! Never get this wrong!)
In Python, anything enclosed in quotes is a string; these quotes can be single quotes, double quotes, or even triple quotes.
In Python, single quotes and double quotes serve the same purpose. However, note that in other languages, double quotes indicate a string, while single quotes indicate a character! For example, in C or JSON! Therefore, many students often face issues when converting JSON formats due to using single quotes.
Using triple quotes (”’ or “””) allows you to specify a multi-line string.
The escape character ‘\’ is used for special escapes, such as \r\n,\\. It can turn a quote into a plain quote, with no effect.
Raw strings: By adding an ‘r’ or ‘R’ before the string, such as r”this is a line with \n”, indicates that the slashes in this string do not need to be escaped, equivalent to themselves. Therefore, the \n in the example will display as is and not as a newline.
Unicode strings: By adding a prefix ‘u’ or ‘U’, such as u”this is a unicode string”.
Bytes type: By adding a prefix ‘b’, such as b”this is a bytes data”. However, s=b”哈哈” is not allowed!
Strings are immutable types.
Strings concatenate automatically, such as “I” “love” “you” will automatically convert to “I love you”.
Some of this content may be difficult to understand; that’s okay, just keep reading.
9. How to Read Error Call Stack Information?
Now that we have started writing some simple Python code and statements, making mistakes is inevitable. Python provides us with very comprehensive and detailed error call stack information to help us locate errors. Taking the following code as an example (I have added line number information to each line, including blank lines):
def foo(s): #1
return 10 / int(s) #2 #3
def bar(s): #4
return foo(s) * 2 #5 #6
def main(): #7
bar('0') #8 #9
main() #10After running the code, the following error will pop up:
Traceback (most recent call last):
File "F:/Python/pycharm/201705/1.py", line 10, in <module>
main()
File "F:/Python/pycharm/201705/1.py", line 8, in main
bar('0')
File "F:/Python/pycharm/201705/1.py", line 5, in bar
return foo(s) * 2
File "F:/Python/pycharm/201705/1.py", line 2, in foo
return 10 / int(s)
ZeroDivisionError: division by zeroThese messages are the error prompts. We need to read from top to bottom; the English may seem complicated but is actually easy to understand. Traceback… indicates the start of tracing the error, saying that there is a problem in the main function on line 10 of the file 1.py. So where is the problem? It is in the bar function call on line 8 of the file 1.py, but what is the problem? Still not found the root cause; it says there is a problem in line 5, and then line 2, ultimately discovering that the problem lies in the line: return 10 / int(s). What is the issue? A division by zero error!
ZeroDivisionError is a division by zero exception. At this point, we suddenly realize that I tried to divide 10 by 0, resulting in an error, and now we know how to fix it.
In fact, locating errors and troubleshooting is that simple; it just requires you to patiently review the error call stack line by line, and based on the last error type, you can determine the cause of the error and modify it. It is not as complicated as you might think. Moreover, do not directly pass the error to someone else or a teacher! That way of asking, “I have an error here, what is the reason?” is the least sophisticated way to ask.
Receive the latest Python beginner learning materials for 2023, reply: Python
If this article has helped you, please take 2 seconds to like + share + let more people see this article and help them out of misconceptions.