
Learning programming is essentially learning high-level languages, which are designed for humans to communicate with computers.
However, computers do not understand high-level languages; they must be converted into binary code through a compiler to run. Knowing high-level languages does not equate to understanding the actual execution steps of a computer.
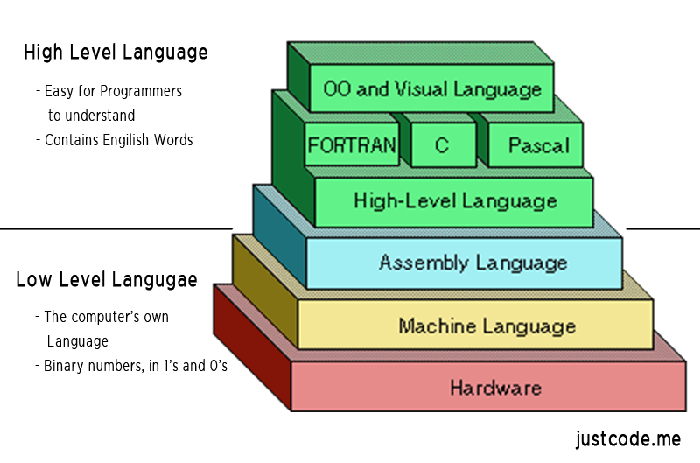
The only language that computers truly understand is low-level languages, which are specifically used to control hardware. Assembly language is a low-level language that directly describes/controls the operation of the CPU. If you want to understand what the CPU is actually doing and the steps involved in code execution, you must learn assembly language.
Assembly language is not easy to learn, and even concise introductions are hard to find. Here, I attempt to write the most understandable assembly language tutorial, explaining how the CPU executes code.

1. What is Assembly Language?
We know that the CPU is responsible only for computation and lacks intelligence. When you input an instruction, it executes it once, then stops and waits for the next instruction.
These instructions are binary, known as opcode, for example, the addition instruction is 00000011.The role of the compiler is to translate the programs written in high-level languages into a series of opcodes.
For humans, binary programs are unreadable, and it is impossible to see what the machine has done. To solve the readability issue and occasional editing needs, assembly language was born.
Assembly language is the textual form of binary instructions, with a one-to-one correspondence with the instructions. For instance, the addition instruction 00000011 is written in assembly language as ADD. Once converted back to binary, assembly language can be directly executed by the CPU, making it the lowest-level low-level language.
2. Origins
In the early days, programming involved manually writing binary instructions and inputting them into the computer via various switches; for example, to perform addition, one would press the addition switch. Later, the invention of the punch card machine allowed binary instructions to be input into the computer automatically by punching holes in cards.
To address the readability issue of binary instructions, engineers wrote those instructions in octal. Converting binary to octal is straightforward, but octal is also not very readable. Naturally, in the end, words were used to express them, with the addition instruction written as ADD. Memory addresses were no longer referenced directly but were represented by labels.
This added another step, which is to translate these textual instructions into binary. This step is called assembling, and the program that completes this step is called an assembler. The text it processes is naturally called assembly code. After standardization, it was referred to as assembly language, abbreviated as asm.

Each CPU has different machine instructions, so the corresponding assembly languages are also different. This article introduces the most common x86 assembly language, which is used by Intel’s CPUs.
3. Registers
To learn assembly language, you must first understand two concepts: registers and the memory model.
First, let’s look at registers. The CPU is responsible for computation, not for storing data. Data is generally stored in memory, and when the CPU needs it, it reads and writes data from memory. However, the CPU’s computation speed is much faster than memory’s read and write speed, so to avoid being slowed down, the CPU comes with Level 1 and Level 2 caches. Essentially, CPU cache can be viewed as faster memory for reading and writing.
However, the CPU cache is still not fast enough, and since the addresses of data in the cache are not fixed, addressing during each read/write can also slow down speed. Therefore, in addition to the cache, the CPU also has registers to store the most frequently used data. This means that the most frequently read and written data (such as loop variables) are kept in registers, allowing the CPU to prioritize reading and writing from registers, which then exchange data with memory.
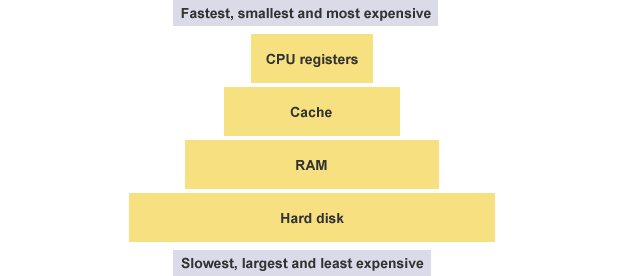
Registers do not distinguish data by address but by name. Each register has its own name, and we tell the CPU which specific register to fetch data from, making this the fastest method. Some people liken registers to the CPU’s zero-level cache.
4. Types of Registers
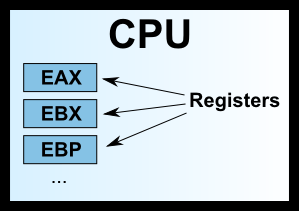
Early x86 CPUs had only 8 registers, each with a different purpose. Today’s registers number over 100, and they have all become general-purpose registers without specific designations, but the names of the early registers have been retained.
-
EAX
-
EBX
-
ECX
-
EDX
-
EDI
-
ESI
-
EBP
-
ESP
Among the 8 registers above, the first seven are general-purpose. The ESP register has a specific purpose, which is to save the current address of the stack (see the next section for details).
We often see names like 32-bit CPU and 64-bit CPU, which actually refer to the size of the registers. A 32-bit CPU has a register size of 4 bytes.
5. Memory Model: Heap
Registers can only hold a small amount of data; most of the time, the CPU must command registers to exchange data directly with memory. Therefore, in addition to registers, it is essential to understand how memory stores data.
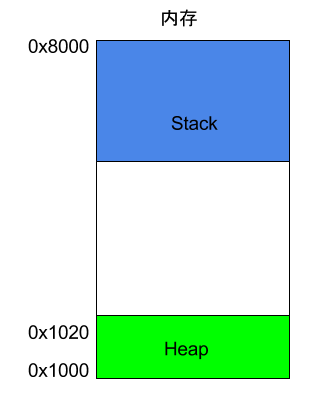
When a program runs, the operating system allocates a segment of memory for it to store the program and the data generated during execution. This segment of memory has a starting address and an ending address, for example, from 0x1000 to 0x8000, where the starting address is the smaller one and the ending address is the larger one.

During the program’s execution, for dynamic memory allocation requests (such as creating new objects or using the malloc command), the system will allocate a part of the pre-allocated memory to the user, specifically starting from the starting address (in reality, the starting address will have some static data, which we will ignore here). For example, if the user requests 10 bytes of memory, it will be allocated starting from the starting address 0x1000 and continuing to address 0x100A. If another request for 22 bytes is made, it will be allocated up to 0x1020.

This memory area allocated due to user requests is called the Heap. It grows from the starting address, increasing from lower addresses to higher addresses. An important characteristic of the Heap is that it does not disappear automatically; it must be manually released or reclaimed by a garbage collection mechanism.
6. Memory Model: Stack
In addition to the Heap, other memory usage is called the Stack. Simply put, the Stack is the memory area temporarily occupied due to function execution.
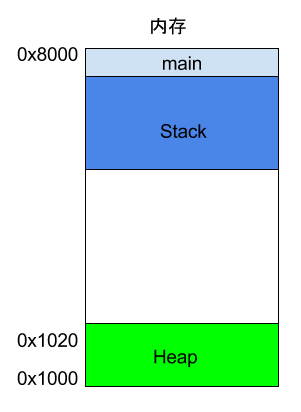
Consider the following example.
int main() { int a = 2; int b = 3;}
When the system starts executing the main function, it will establish a frame in memory for it, where all internal variables of main (such as a and b) are stored within this frame. After the main function finishes executing, that frame will be reclaimed, releasing all internal variables and no longer occupying space.
If a function calls another function, what happens?
int main() { int a = 2; int b = 3; return add_a_and_b(a, b);}
In the code above, the main function calls the add_a_and_b function. When this line is executed, the system will also create a new frame for add_a_and_b to store its internal variables. This means that at this moment, there are two frames: main and add_a_and_b. Generally, the number of frames corresponds to the number of layers in the call stack.
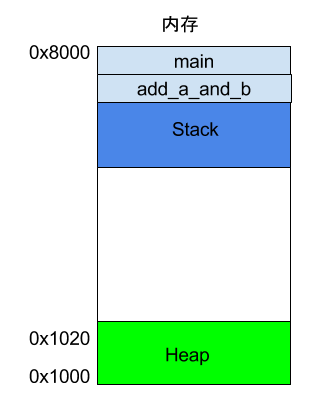
When add_a_and_b finishes executing, its frame will be reclaimed, and the system will return to the point where the main function was interrupted, continuing execution. Through this mechanism, function calls can be layered, and each layer can use its own local variables.
All frames are stored in the Stack, and since frames are stacked on top of each other, the Stack is called a stack. Creating a new frame is called “pushing” onto the stack; in English, it’s called push. Reclaiming the stack is called “popping”; in English, it’s called pop. The characteristic of the Stack is that the last frame pushed is the first one to be popped (because the innermost function call ends first), which is known as a