The Cortex A77 architecture, newly launched by Arm in May 2019, utilizes TSMC’s 7nm process with a peak frequency of 3GHz, achieving a 20% performance improvement. A previous article introduced the architecture of the strongest X86 processor, ZEN, which can be found here. This article analyzes the strongest Arm processor, A77, based on the same principles, exploring its design scheme and the similarities and differences with the X86 architecture.
First, let’s briefly introduce the Arm instruction set architecture. Currently, general-purpose processors are basically divided into two camps: one led by INTEL and AMD, which uses CISC (Complex Instruction Set Computer) instruction sets, and the other led by Arm, which uses RISC (Reduced Instruction Set Computer) instruction sets. The main difference between the two is the singularity of instruction functions. RISC ISA typically completes a simple, independent operation or control with one instruction, with a fixed instruction length and a relatively uniform format. In contrast, CISC ISA instructions have much more complex functions, with variable instruction lengths and complex formats. Because RISC instruction encoding and functionality are very advantageous for hardware implementation, today’s processors, whether X86 or Arm, have hardware execution cores based on RISC architecture. The X86 architecture adds an extra step of translating CISC instructions into RISC-like microinstructions, which complicates the decoding process and increases the number of pipeline stages. This is also an important factor in why X86 processors consume more power than comparable RISC processors.

The Cortex A77 targets the high-performance mobile domain and employs the Arm v8.2 64-bit instruction set architecture. The hardware design is a direct successor to the A76, also utilizing a 7nm process, with no change in peak frequency. From this perspective, the pipeline structure of the A77 should be consistent with that of the A76, and the 20% improvement mainly lies in the microarchitecture details aimed at enhancing IPC and parallel execution capabilities. As the process advances to 7nm, the power density of a single chip significantly restricts the increase in frequency. Arm primarily targets the mobile market and does not align frequency control with INTEL, but rather pursues performance per unit power. Therefore, many designs do not prioritize frequency as the primary goal. For example, the L1 cache size reaches 64KB, even exceeding ZEN2’s 32K. Other features like DynamIQ and big.LITTLE are essentially standard for Arm.
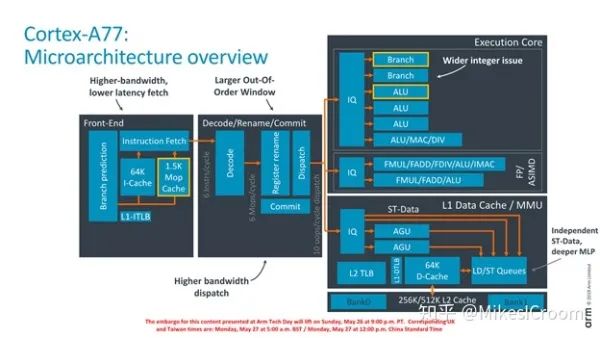
The A77’s pipeline structure has not changed significantly; it remains a standard physical register out-of-order machine. There are several noteworthy points. The first is the 1.5K entry Mop Cache, a structure that has existed in X86 for a long time but has finally appeared in Arm processors. X86, being a complex instruction set, introduces Mop Cache to store decoded microinstructions, allowing it to bypass the fetch and decode pipelines, achieving greater dispatch width. We see that this Mop Cache is positioned at the fetch stage, and after the muxing of Icache results, it is sent to the decode module. If this structure is correct, the primary purpose of this Mop Cache is to control power consumption and reduce branch penalties. The decode stage has been increased to handle 6 instructions simultaneously, while also widening the issue width, adding one ALU and one BRU. Thus, the A77’s execution units consist of 4 ALUs, 2 BRUs, and 2 load-store pipes. It is evident that Apple’s processor design has had a significant impact on Arm. As everyone strives to enhance concurrency and boost single-core peak performance, Arm cannot remain aloof, continuing its extreme energy efficiency design. Another reason may be related to the resurgence of Arm servers, as Huawei and Amazon have introduced their own designed Arm server chips, reviving the ARM server market that had cooled for several years. In this context, Arm also needs a processor with single-core performance that can compete with the X86 camp, which can encourage more manufacturers to enter and challenge X86. The A77’s configuration can be said to cater to both the high-end mobile market and the entry-level server market’s needs.

The most significant change in the front-end pipeline is the addition of the Mop Cache. Assuming its width is consistent with the number of decodes, the 1.5K entries can store 9,000 32-bit instructions, which should cover most application scenarios in the mobile domain. After warming up the Mop Cache, instructions can be sent directly from the Mop Cache to the decode stage without going through the Icache path, allowing the entire fetch unit to enter a low-power state. Additionally, it stores information decoded from instructions, including branch and loop prediction results, enabling zero-cycle hardware loops, further improving loop execution efficiency. Thirdly, fetching from the Mop reduces the length of the fetch pipeline, so in the event of a branch misprediction, if the new target is also in the Mop, the penalty for flushing the pipeline will be significantly reduced. Here, a dynamic code optimization technique is also mentioned, seemingly learning the characteristics of code sequences to enhance subsequent execution capabilities; it is unclear how Arm implements this.
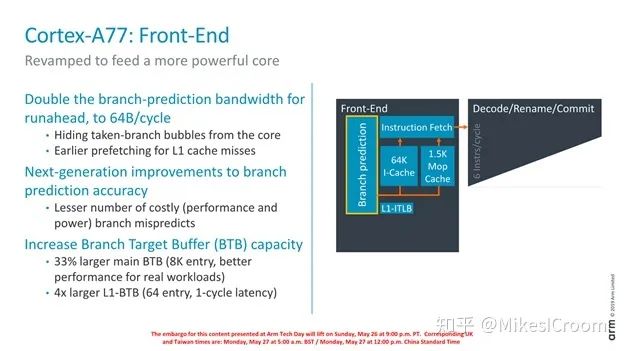
Branch prediction is another key optimization technique. It is evident that it aligns closely with ZEN2’s direction, which is also the most important performance metric for the front-end pipeline. The A77 expands the branch prediction bandwidth to 64B, theoretically allowing it to predict the branch results of 16 simultaneous 32-bit instructions. Similar to ZEN, it significantly increases the size of the BTB. It can be seen that the A77 lacks an L0 BTB compared to ZEN and only has a two-level BTB. Without specific data, it is difficult to determine which scheme is better; it should be selected based on the application scenarios each faces. The common trend is larger predictors and prediction widths.
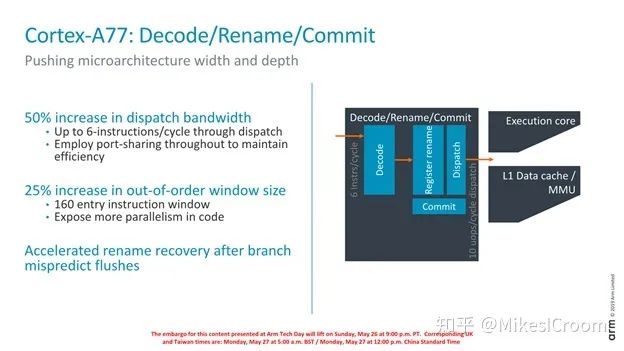
The decode stage mainly increases the dispatch width by 50%, theoretically allowing 6 instructions to execute concurrently, which provides greater parallel execution capability. Consequently, the number of ROB entries has also increased to 160. It is mentioned that the speed of updating the renaming table after a branch misprediction has been accelerated. Typically, the renaming table is restored to its actual renaming state when the corresponding branch retires. The term “accelerate” here may imply that multiple branch recovery points have been provided, allowing recovery to the most recent recovery point without waiting for retirement. This would increase both hardware complexity and area. Due to a lack of detailed information, only reasonable speculation can be made.
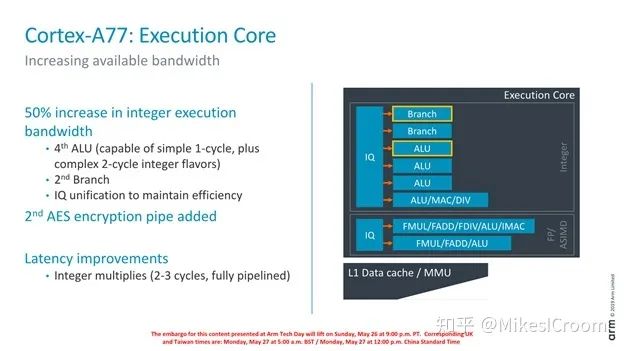
The execution units primarily see an increase in quantity, aligning with Apple. Note that Arm has consistently maintained a single-cycle ALU, which is crucial for single-core IPC performance, a point that ZEN2 also maintains. The A77 adopts a Unified Issue Queue, differing from ZEN’s separate design. An integrated IQ can lead to better scheduling effects but will significantly restrict frequency increases. This reflects that Arm does not prioritize frequency but considers overall power consumption more. Another change is the addition of a crypto pipeline to enhance AES encoding and decoding capabilities. The author remains cautious about this point. Currently, crypto acceleration usually employs dedicated accelerators because the algorithms are fixed, allowing ASICs to achieve very high acceleration ratios with relatively low hardware costs. Moreover, ASIC-implemented crypto accelerators can be completely isolated from the processor, achieving purely hardware-based encryption and decryption, thus ensuring a high level of security. In contrast, using processors for this purpose results in significant performance and power consumption disparities, and the higher software involvement in instruction implementation makes security harder to guarantee.

The load-store pipeline similarly employs a unified Issue Queue. It can be seen that the A77 has two address paths and two store data paths, allowing it to execute two store instructions simultaneously. The combination may consist of two loads, two stores, or one load and one store. The adoption of two store pipes is quite aggressive, likely aimed at achieving higher memory handling performance. For typical applications, this additional store data path is unlikely to have much impact.

Here, Arm emphasizes its pre-fetching mechanism. Data prefetching can effectively hide system memory access latency, which is crucial for high-performance processors. Typical prefetching is based on the execution characteristics of data, supporting one-dimensional or multi-dimensional stride forms of prefetching. The A77 proposes a system-aware prefetching method, claiming to provide greater prefetching capability tailored to the storage subsystem’s characteristics. Due to limited information, it is unclear how this system awareness is implemented; it may dynamically adjust the number and strategy of prefetches based on varying memory latencies and the usage rates of L3 cache across cores.
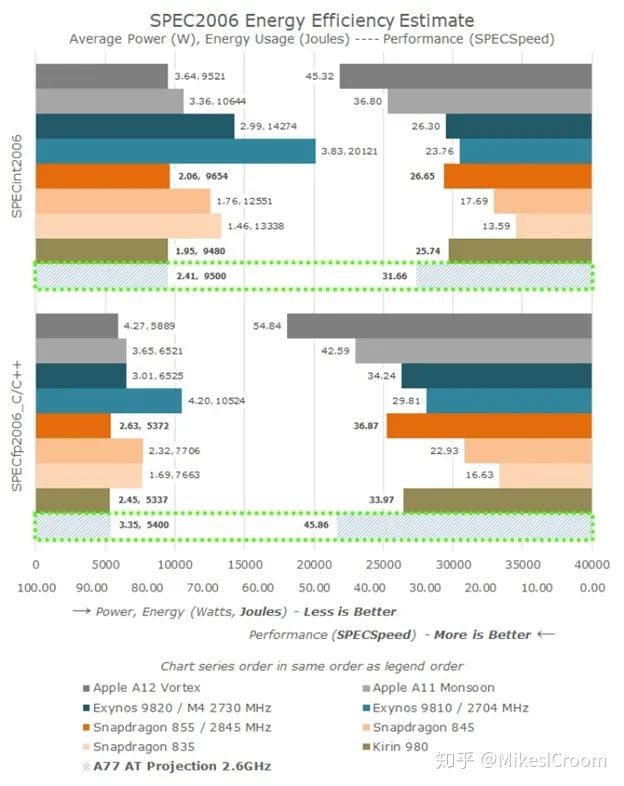
From the performance metrics provided by Arm, it is evident that the A77 maintains a high energy efficiency ratio, especially regarding power consumption, which is also Arm’s core competitive advantage.
From the A77’s technical specifications, the design of general-purpose processors shows the following trends: firstly, as explained in the “ZEN2” article, the microarchitecture of general-purpose processors has stabilized, and there are no new major innovations; improvements are being made in details, such as wider dispatch paths, more execution units, and larger predictors. This provides a great opportunity for followers to catch up. Secondly, the design of Arm’s mobile processors is gradually converging with the structures of INTEL and AMD in desktop processors; aside from lower core frequencies, other metrics are not significantly different, and many technologies unique to X86 are gradually appearing in Arm’s designs. As the process approaches its physical limits, the gap between Arm and INTEL is rapidly narrowing, and it is likely that in the near future, Arm processors will have the capital to compete with X86 in the server market. Thirdly, the reduction in process size leads to a significant increase in power density, becoming a critical factor restricting core frequency. It can be seen that the A77 does not support higher frequencies, and based on previous SOC designs, the final chip is estimated to maintain around 2.5G. Due to the more stringent heat dissipation conditions in mobile devices, typical applications may use multiple cores operating at lower frequencies, while for larger applications like gaming, single-core frequencies may be increased, with other cores reducing frequency or entering low-power states, keeping the overall chip power consumption within controllable limits. INTEL’s Turbo Boost technology employs a similar approach. Power consumption will remain a bottleneck for performance improvement for a long time, posing higher challenges for designers to provide flexible execution methods based on specific application scenarios.
Therefore, while leaders face numerous constraints, followers can strive to catch up. Now may be a great opportunity for the development of domestic processors. For example, the recently announced Xuantie 910 from Pingtouge has performance that can already match Arm A72, marking the smallest gap between domestic processors and world-class standards. It may not be long before we catch up with Arm in the mobile market. However, Arm’s advantages lie more in its ecosystem; whether the emerging RISC-V can break this limitation and establish its own ecosystem centered on open-source will become a key factor in the commercialization path of domestic processors. We look forward to that day coming soon.
This article is reprinted from the Jishu Community.
Original title: “The King of Mobility: An In-Depth Analysis of Arm’s Strongest Processor Cortex A77″
Jishu Column: AI Processor Architecture Design
Author: mikesicroom
Images in the article are sourced from the Arm Tech Day Presentation, May 26, 2019.
Recommended Premium Courses



End
Anxin Education is an innovative educational platform focused on the artificial intelligence and IoT industries, serving as the core official partner of the “Arm Intelligent Interconnection” and “Arm Future Chip” course and certification system, providing a comprehensive AIoT education service system from primary and secondary schools to higher education.
Relying on Arm’s global educational resources, Anxin Education has developed the ASC (Arm Smarter Connected) – “Arm Intelligent Interconnection Talent Training” and AFE (Arm Future Engineer) – “Arm Future Chip STEM Education” curricula, gathering professional teaching staff and an efficient operation team to build an online digital education platform aimed at cultivating technical talents in the field of intelligent interconnection that meet the demands of the times.
