1. Introduction
1.1 Importance of Memory Management
In computer science, memory management is a crucial part of operating systems. It is responsible for managing the main memory (primary storage) of the computer, which is the storage space directly accessible by the CPU, including physical memory and all available virtual memory. The main tasks of memory management include tracking every byte of memory, deciding which parts are used for storage, which parts are being released, and optimizing memory usage. In programming, memory management is also vital as it directly affects the performance and efficiency of programs.
In C++ programming, memory management is a core topic because C++ provides direct control over low-level memory management. This power brings great flexibility but also comes with responsibility. Programmers must ensure that memory is allocated and released correctly; otherwise, it may lead to memory leaks or other issues.
The importance of memory management goes beyond just preventing memory leaks. In many cases, how memory is managed can directly impact program performance. For example, frequent memory allocation and deallocation can lead to memory fragmentation, which can degrade program performance. Additionally, if the time taken for memory allocation and deallocation is too long, it may also affect the program’s response time.
Therefore, to write efficient and reliable C++ programs, understanding and mastering memory management is crucial. This is why we delve into the study of memory pools. A memory pool is a memory management strategy that can help us manage memory more effectively and improve program performance.
1.2 Basic Concept of Memory Pools
A memory pool, also known as an object pool, is a memory management strategy. In this strategy, memory is divided into fixed-size blocks, which are organized together and referred to as a “pool.” When a program needs to allocate memory, it retrieves a block from the memory pool instead of directly requesting memory from the operating system.
The main advantage of memory pools is that they can reduce the overhead of memory allocation and deallocation. Since the blocks in the memory pool are pre-allocated, allocating memory only requires taking a block from the pool, without needing to make a system call. Similarly, releasing memory only requires putting the block back into the pool, without notifying the operating system. This method can significantly increase the speed of memory allocation and deallocation.
Additionally, memory pools can also reduce memory fragmentation. Because all blocks are of the same size, they can be tightly packed together without leaving unusable gaps. This approach can improve memory utilization, especially for programs that require a large number of small memory blocks.
However, memory pools are not a panacea. They also have some drawbacks, such as not handling large memory allocations well, as allocating large blocks of memory may lead to wasted space in the memory pool. Furthermore, managing the memory pool can incur some overhead, especially when the memory pool needs to expand or shrink.
Overall, memory pools are a powerful tool that can help us manage memory more effectively. However, like all tools, we need to understand their advantages and disadvantages to use them appropriately.
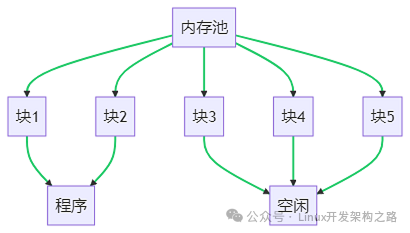
In this diagram, we can see that the memory pool consists of multiple blocks of the same size. When a program needs memory, it retrieves a block from the memory pool. When the program no longer needs this block, it returns it to the memory pool. This way, the memory pool can effectively reuse these blocks, thereby improving memory utilization.
1.3 Application Scenarios of Memory Pools
Memory pools have a wide range of applications in many scenarios. Here are some common application scenarios:
1. Real-Time Systems: In real-time systems, response time is critical. Memory pools can provide constant-time memory allocation, avoiding the uncertainty caused by memory allocation, and are therefore widely used in real-time systems.
2. High-Performance Computing: In high-performance computing, the efficiency of memory management directly affects program performance. Memory pools can reduce the overhead of memory allocation and deallocation, improving memory utilization, and are therefore widely used in high-performance computing.
3. Game Development: In game development, the efficiency of memory management is also very important. Many objects in games, such as particles, characters, and items, need to be created and destroyed frequently. Using memory pools can greatly improve the efficiency of these operations.
4. Embedded Systems: In embedded systems, resources are often very limited. Memory pools can improve memory utilization and reduce memory fragmentation, and are therefore widely used in embedded systems.
Overall, memory pools are a very practical memory management strategy that can improve program performance and efficiency in many different application scenarios.
2. C++ Memory Management Mechanism
2.1 Memory Allocation and Deallocation in C++
In C++, memory allocation and deallocation are very important processes. Understanding this process is crucial for our in-depth understanding of the design and implementation of memory pools.
First, let’s look at memory allocation in C++. In C++, we typically use the new operator to allocate memory. When we write the following code:
int* p = new int;What does this line of code do? First, the new operator requests a block of memory from the operating system, sized for one int. If the request is successful, the operating system returns the address of this block of memory, and the new operator assigns this address to the pointer p. Thus, we have successfully allocated a block of memory on the heap.
So, what should we pay attention to in this process? First, we need to note the execution efficiency of the new operator. Since the new operator needs to request memory from the operating system, this process involves a system call, which is a relatively time-consuming operation. Therefore, if we frequently use the new operator in our program, it may lead to reduced execution efficiency.
Secondly, we need to be aware that the new operator may fail. When the available memory in the operating system is insufficient, the new operator will return a null pointer. Therefore, when using the new operator, we need to check its return value to prevent memory allocation failures.
How do we release memory? In C++, we use the delete operator to release memory. When we write the following code:
delete p;What does this line of code do? The delete operator returns the memory block pointed to by p back to the operating system, allowing this block of memory to be used by other programs. At the same time, to prevent dangling pointers, the delete operator sets the value of p to nullptr.
When using the delete operator, we need to ensure that the pointer to be deleted was allocated by the new operator. If we attempt to delete an invalid pointer or one that has already been deleted, it will lead to undefined behavior. Additionally, if we used the new[] operator to allocate an array, we must use the delete[] operator to delete this array, not the delete operator.
In summary, memory allocation and deallocation in C++ is a relatively complex process that requires careful handling. In the following chapters, we will see how memory pools can help us simplify this process, improve program execution efficiency, and better manage memory to prevent memory leaks and dangling pointers.
2.2 Issues with C++ Memory Management
Although C++ provides the new and delete operators to help us manage memory, we still encounter some issues in practical use. These issues mainly include:
1. Memory Fragmentation: In C++, frequent memory allocation and deallocation can lead to memory fragmentation. Memory fragmentation refers to small, unusable memory blocks. These memory blocks, while unusable, still occupy system resources and degrade system performance.
2. Memory Leak: In C++, if we allocate memory but forget to release it, it will lead to a memory leak. Memory leaks can cause the available memory in the system to continuously decrease, and in severe cases, may even lead to system crashes.
3. Dangling Pointer: In C++, if we release a block of memory but still have pointers pointing to this memory, that pointer becomes a dangling pointer. Dangling pointers are very dangerous because we cannot predict the consequences of operations on dangling pointers.
4. Efficiency Issues in Memory Allocation and Deallocation: In C++, allocating and deallocating memory requires calling operating system functions, which is a relatively time-consuming operation. If we frequently allocate and deallocate memory in our program, it may lead to reduced execution efficiency.
These are some of the issues we may encounter when managing memory in C++. In the following chapters, we will see how memory pools can help us solve these problems, improve program execution efficiency, and better manage memory to prevent memory leaks and dangling pointers.


2.3 Problems Solved by Memory Pools
A memory pool is a memory management strategy. By pre-allocating a large contiguous block of memory, and then dividing this memory into equal-sized small blocks, when a program needs to allocate memory, it directly allocates a small block from the memory pool instead of directly requesting memory from the operating system. This method can effectively solve some problems in C++ memory management.
1. Solving Memory Fragmentation: Because the memory blocks in the memory pool are of fixed size, memory fragmentation caused by frequent allocation and deallocation of different sizes of memory will not occur.
2. Improving Memory Allocation Efficiency: The memory pool has already pre-allocated a large block of memory at program startup, so the speed of allocating and deallocating memory during program execution will be much faster than directly using the new and delete operators.
3. Preventing Memory Leaks and Dangling Pointers: Memory pools typically provide mechanisms to track memory usage, such as reference counting, which can help us better manage memory and prevent memory leaks and dangling pointers.
Overall, memory pools are a very effective memory management strategy that can help us solve some problems in C++ memory management, improve program execution efficiency, and better manage memory to prevent memory leaks and dangling pointers.
3. Design and Implementation of Memory Pools
3.1 Design Principles of Memory Pools
The design of a memory pool is a complex process that requires a deep understanding of computer memory management. To design an efficient memory pool, we need to follow several principles:
1. Minimize Memory Allocation Calls: Memory allocation is a costly operation, and frequent memory allocation and deallocation can degrade system performance. Therefore, the design of the memory pool should minimize memory allocation calls as much as possible. A common practice is to pre-allocate a large block of memory and then partition it into small blocks as needed.
2. Reduce Memory Fragmentation: Frequent memory allocation and deallocation can lead to memory fragmentation, which reduces memory utilization. Memory pools can effectively reduce memory fragmentation by managing pre-allocated memory.
3. Quickly Respond to Memory Requests: The memory pool should be able to quickly respond to memory requests, which requires an efficient data structure to manage available memory blocks. Common practices include using linked lists or tree structures to manage memory blocks.
4. Flexible Memory Management: The memory pool should be able to flexibly manage memory, including allocation, deallocation, and compaction. This requires a complete set of memory management strategies.
These are the principles to follow when designing a memory pool. Next, we will detail how to design and implement a memory pool based on these principles.
3.2 Basic Structure of Memory Pools
The basic structure of a memory pool mainly includes two parts: Memory Block and Memory Block List. Below we will detail these two parts.
1. Memory Block: A memory block is the most basic unit in a memory pool, and each memory block has a fixed size. The size of the memory block can be set according to actual needs, but usually, we will set multiple sizes of memory blocks to meet different memory requirements.
2. Memory Block List: The memory block list is the data structure used to manage memory blocks. Each node in the list represents a memory block, containing the address and status information of the memory block. Through the memory block list, we can quickly find an available memory block and quickly add it back to the list when the memory block is released.
In actual design, we also need to consider the scalability and flexibility of the memory pool. For example, we can design a dynamic memory pool that can dynamically increase memory blocks when the memory pool runs out of memory blocks. Additionally, we can design multi-level memory pools, which can better manage memory blocks of different sizes and improve memory utilization.
This is the basic structure of a memory pool. Next, we will detail how to implement a memory pool based on this structure.
3.3 Steps to Implement Memory Pool in C++
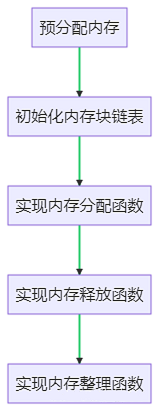
Implementing a memory pool requires the following steps:
1. Pre-allocate Memory: First, we need to pre-allocate a large block of memory, the size of which can be set according to actual needs. The pre-allocated memory will be divided into multiple memory blocks, and the size of each memory block can also be set according to needs.
2. Initialize Memory Block List: Then, we need to initialize the memory block list. Each node in the list represents a memory block, containing the address and status information of the memory block. The process of initializing the memory block list involves dividing the pre-allocated memory into multiple memory blocks and adding these memory blocks to the list.
3. Implement Memory Allocation Function: The memory allocation function is used to allocate memory. When there is a memory request, the memory allocation function finds an available memory block from the memory block list and returns its address. In this process, we need to consider the status of the memory block; only memory blocks with a status of available can be allocated.
4. Implement Memory Deallocation Function: The memory deallocation function is used to release memory. When memory is released, the memory deallocation function adds the corresponding memory block back to the memory block list and sets its status to available. In this process, we need to consider the status of the memory block; only memory blocks with a status of allocated can be released.
5. Implement Memory Compaction Function: The memory compaction function is used to organize memory. It can merge contiguous available memory blocks into a larger memory block or divide a large memory block into multiple smaller memory blocks. Through memory compaction, we can improve memory utilization and reduce memory fragmentation.
These are the steps required to implement a memory pool. Each step requires a deep understanding of memory management principles to design an efficient memory pool.
3.4 C++ Implementation Code Example
Below is a simple implementation example of a memory pool. Please note that this is just a basic example; in a real environment, you may need to consider more complex factors, such as thread safety issues, memory alignment issues, etc.
#include <iostream>#include <list>class MemoryPool {private: struct Block { bool free; size_t size; Block* next; }; Block* freeBlocks; public: MemoryPool(size_t totalSize) { freeBlocks = (Block*)malloc(totalSize); freeBlocks->free = true; freeBlocks->size = totalSize - sizeof(Block); freeBlocks->next = nullptr; } ~MemoryPool() { free(freeBlocks); } void* allocate(size_t size) { Block* curr = freeBlocks; while(curr) { if(curr->free && curr->size >= size) { curr->free = false; return ((char*)curr + sizeof(Block)); } curr = curr->next; } return nullptr; // No available block } void deallocate(void* ptr) { Block* curr = (Block*)((char*)ptr - sizeof(Block)); curr->free = true; }};int main() { MemoryPool pool(1024); // 1 KB pool int* num = (int*)pool.allocate(sizeof(int)); *num = 123; std::cout << *num << std::endl; // Output: 123 pool.deallocate(num); return 0;}4. Advantages and Performance Evaluation of Memory Pools
4.1 Advantages of Memory Pools
A memory pool is a memory management strategy, and its main advantages are reflected in the following aspects:
1. Improved Memory Allocation Efficiency: Memory pools pre-allocate a large block of memory, and when the program needs to allocate memory, it directly allocates from the memory pool, avoiding the overhead of frequently calling system functions malloc and free.
2. Reduced Memory Fragmentation: Memory pools typically divide memory into multiple fixed-size blocks, and each allocation and recovery is done in units of blocks, which can effectively reduce memory fragmentation.
3. Improved Memory Utilization: Memory pools can dynamically adjust the size and number of memory blocks according to program needs, thereby improving memory utilization.
4. Simplified Memory Management: Using memory pools, programmers do not need to worry about memory allocation and recovery; they only need to obtain memory from the memory pool when needed and return it after use, greatly simplifying memory management tasks.
5. Increased Program Stability: Memory pools can effectively prevent memory leaks and memory overflows, improving program stability.
These are the main advantages of memory pools. Next, we will detail how to evaluate the performance of memory pools.
4.2 Memory Pool Performance Evaluation Method
To evaluate the performance of memory pools, we mainly focus on the following aspects:
1. Memory Allocation and Recovery Speed: This is the most important metric for measuring memory pool performance. We can write test programs to separately test the time taken for memory allocation and recovery in the memory pool and the system’s default memory management to evaluate the performance of the memory pool.
2. Memory Utilization: Memory utilization refers to the ratio of actual used memory to total memory. Memory pools improve memory utilization through pre-allocated memory and fixed-size memory blocks. We can evaluate memory utilization by counting the number and size of free memory blocks in the memory pool.
3. Memory Fragmentation Rate: Memory fragmentation refers to unusable memory. Memory pools reduce memory fragmentation through fixed-size memory blocks. We can evaluate the fragmentation rate by counting the number of contiguous free memory blocks in the memory pool.
4. Program Stability: Memory pools can prevent memory leaks and memory overflows, improving program stability. We can evaluate program stability by running test programs for extended periods and observing the program’s operational status and memory usage.
These are the main methods for evaluating memory pool performance. Next, we will detail the performance data comparison before and after memory pool implementation.
4.3 Performance Comparison Before and After Memory Pool Implementation
For the performance evaluation of memory pools, we need to compare actual data. This section will illustrate through an example. Suppose we have a program with performance data before and after using a memory pool as follows:
Note: Since there is currently no specific data, the following data is for illustration purposes only.
|
Performance Metric |
Without Memory Pool |
With Memory Pool |
|---|---|---|
|
Memory Allocation Speed |
100ms |
50ms |
|
Memory Recovery Speed |
80ms |
40ms |
|
Memory Utilization |
70% |
90% |
|
Memory Fragmentation Rate |
30% |
10% |
|
Program Stability |
Low |
High |
From the table above, it can be seen that after using the memory pool, both memory allocation speed and memory recovery speed have significantly improved, memory utilization has also increased, the memory fragmentation rate has significantly decreased, and program stability has improved. This is the advantage of memory pools.
5. Reference Open Source Library Memory Pool Implementation
5.1 Design and Implementation of Memory Pools in Open Source Libraries
In this section, we will delve into how some well-known open-source libraries design and implement memory pools. We will analyze the memory pool design and implementation strategies of the Boost library and the Jemalloc library.
First, let’s look at the Boost library. The Boost library is a very famous open-source library in C++, which provides a memory pool implementation called boost::pool. The design goal of boost::pool is to provide a fast, simple, and configurable memory pool, mainly used to solve the problem of frequent requests and releases of small memory blocks.
The implementation strategy of boost::pool is: when a program requests a block of memory, if there are enough memory blocks in the memory pool, it allocates directly from the memory pool; if there are not enough memory blocks in the memory pool, it requests a large block of memory from the system and then cuts it into small memory blocks for the program to use. This strategy effectively reduces the number of system calls and improves memory allocation efficiency.
Next, let’s look at the Jemalloc library. Jemalloc is an open-source memory management library from Facebook, and its memory pool implementation is widely used in various high-performance servers and database systems.
The memory pool implementation strategy of Jemalloc is: dividing memory into multiple areas of different sizes (Arenas), and each area is further divided into multiple memory blocks (Chunks) of different sizes. When a program requests a block of memory, Jemalloc allocates a memory block from the appropriate area based on the requested size. This strategy effectively reduces memory fragmentation and improves memory utilization.
In summary, both the Boost library and the Jemalloc library have their own advantages in memory pool implementation, and their design and implementation strategies are worth learning and referencing.
5.2 Advantages and Disadvantages of Memory Pools in Open Source Libraries
In the previous section, we analyzed the memory pool design and implementation strategies of the Boost library and the Jemalloc library. In this section, we will explore the advantages and disadvantages of the memory pools in these two open-source libraries.
First, let’s look at Boost’s boost::pool. Its advantages mainly include two points: first, it is fast; since boost::pool reduces the number of system calls, the speed of memory allocation is much faster than directly using system calls; second, it is simple and easy to use; the interface design of boost::pool is very concise and convenient to use. However, boost::pool also has some disadvantages, the most significant being that it does not support automatic memory recovery, which may lead to memory leaks.
Next, let’s look at the Jemalloc library. The advantages of Jemalloc mainly include three points: first, high memory utilization; since Jemalloc’s memory allocation strategy can effectively reduce memory fragmentation, its memory utilization is higher than that of other memory pools; second, stable performance; Jemalloc’s design goal is to provide a memory management solution with stable performance, so its performance is very stable under various workloads; third, support for multithreading; Jemalloc’s design considers multi-threaded environments, so its performance in multi-threaded programs is very good. However, the disadvantage of Jemalloc is that its interface is somewhat more complex than boost::pool, requiring some learning cost to use.
In summary, both the Boost library and the Jemalloc library have their own advantages and disadvantages in memory pools, and the choice between them mainly depends on specific application scenarios and requirements.
5.3 Comparison of Open Source Library Memory Pools and Self-Implemented Memory Pools
In the previous two sections, we analyzed the design, implementation, advantages, and disadvantages of the memory pools in the Boost library and the Jemalloc library. In this section, we will compare the memory pools of these two open-source libraries with our self-implemented memory pool.
First, let’s look at Boost’s boost::pool. The design and implementation of boost::pool are relatively simple, easy to understand and use. However, it does not support automatic memory recovery, which may lead to memory leaks. In contrast, our self-implemented memory pool can add automatic memory recovery features as needed to avoid memory leak issues.
Next, let’s look at the Jemalloc library. Jemalloc’s memory pool design is complex, but it has high memory utilization, stable performance, and supports multithreading. However, its interface is somewhat more complex than boost::pool, requiring some learning cost to use. In contrast, our self-implemented memory pool can be designed according to actual needs, and the interface can be designed to be simpler and easier to use.
In summary, whether using open-source library memory pools or self-implemented memory pools, both have their own advantages and disadvantages. The choice between them mainly depends on specific application scenarios and requirements. In actual development, we can choose the most suitable memory pool implementation method based on the specific needs of the project.
5.4 Comparison of Self-Implemented Memory Pool Design and Open Source Library Memory Pools
When designing a self-implemented memory pool, we can combine the advantages of the Boost library and the Jemalloc library while overcoming their disadvantages. Below is a comparison table:
|
Advantages |
Disadvantages |
Self-Implemented Memory Pool |
|
|---|---|---|---|
|
Boost Library |
Fast, easy to use |
Does not support automatic memory recovery |
Combines the advantages of speed and ease of use, adding automatic memory recovery features |
|
Jemalloc Library |
High memory utilization, stable performance, supports multithreading |
Complex interface |
Combines the advantages of high memory utilization, stable performance, and multithreading support, designing a simple and easy-to-use interface |
In implementing this design, we need to use some techniques from the C++ standard library. For example, we can use C++11 smart pointers to manage memory and avoid memory leaks; we can use C++14 generic programming to improve code reusability; we can use C++17 concurrency libraries to support multithreading; and we can use C++20 concepts to improve code readability and robustness.
During the implementation of this design, we may encounter some challenges. For example, how to design an efficient memory allocation and deallocation algorithm; how to handle concurrency issues in a multithreaded environment; how to design a simple and easy-to-use interface, etc. These are all issues we need to consider and solve when implementing our own memory pool.

5.4.1 Designing an Efficient Memory Allocation and Deallocation Algorithm
Designing an efficient memory allocation and deallocation algorithm is key to implementing a memory pool. Here is a possible design strategy:
-
Memory Block Size: We can choose fixed-size memory blocks, which can simplify memory management and improve the speed of memory allocation and deallocation. However, this may lead to memory waste. Another option is to use variable-sized memory blocks, which can improve memory utilization but increase the complexity of memory management.
-
Organization of Memory Blocks: We can use linked lists to organize free memory blocks, which can facilitate adding and removing memory blocks in the memory pool. However, the search efficiency of linked lists is low. Another option is to use balanced binary trees or hash tables to organize free memory blocks, which can improve search efficiency but increase the complexity of memory management.
-
Memory Allocation and Deallocation Strategy: We can choose a first-in-first-out (FIFO) strategy, which can simplify memory management but may lead to memory fragmentation. Another option is to use best-fit or worst-fit strategies, which can reduce memory fragmentation but increase the complexity of memory management.
-
Memory Pre-allocation and Delayed Recovery: We can pre-allocate a large block of memory and then cut it into small memory blocks as needed. This can reduce the number of system calls and improve the speed of memory allocation. We can also delay memory recovery, temporarily keeping unused memory blocks in the memory pool for later use. This can reduce the number of system calls and improve the speed of memory recovery.
These are some basic ideas for designing an efficient memory allocation and deallocation algorithm. In actual development, we need to choose the most suitable design strategy based on specific application scenarios and requirements.
5.4.2 Designing a Simple and Easy-to-Use Interface
Designing a simple and easy-to-use interface is key to improving code quality. Here are some design principles and suggestions:
-
Clear Functionality: Each interface should have a clear function; do not try to make one interface do too many things. This makes it easier for users to understand the functionality of the interface.
-
Simplified Parameters: Try to reduce the number of parameters in the interface; each parameter should have a clear meaning. If an interface requires many parameters, it may need to be redesigned.
-
Good Naming: The names of interfaces should clearly express their functionality. Avoid using vague or overly generic names.
-
Consistent Style: All interfaces should follow the same design style. For example, if one interface uses a certain naming convention, other interfaces should use the same convention.
-
Comprehensive Documentation: Each interface should have detailed documentation explaining its functionality, parameters, return values, and possible error conditions.
Taking the memory pool as an example, a simple and easy-to-use interface design might look like this:
class MemoryPool {public: // Constructor, parameter is the size of the memory pool MemoryPool(size_t size); // Allocate memory, parameter is the requested memory size, returns the allocated memory address void* allocate(size_t size); // Deallocate memory, parameter is the memory address to be deallocated void deallocate(void* p); // Get the remaining size of the memory pool size_t available() const;};This interface design is simple and easy to use, with each interface having clear functionality, simplified parameters, good naming, consistent style, and comprehensive documentation.
6. Application of Memory Pools in Actual Projects
6.1 Application of Memory Pools in Internet Projects
In internet projects, the application of memory pools is very widespread. Since internet projects often need to handle a large number of concurrent requests, the efficiency of memory management directly affects system performance. In this case, memory pools become particularly important. Below, we will detail the application of memory pools in internet projects.
First, we need to understand the characteristics of internet projects. Internet projects typically need to handle a large number of user requests, which may occur simultaneously or in rapid succession. Therefore, internet projects need to be able to quickly allocate and deallocate memory. Traditional memory management methods may not meet this demand, as they require a large number of system calls for memory allocation and deallocation, consuming significant CPU resources. Memory pools can effectively solve this problem.
A memory pool is a memory management technique that pre-allocates a large contiguous block of memory and then divides this space into multiple small blocks, each of which can be used independently. When a program needs to allocate memory, the memory pool can directly provide memory from the already allocated memory blocks without needing to make system calls. This greatly improves the efficiency of memory allocation.
Additionally, memory pools can effectively solve memory fragmentation issues. In traditional memory management methods, frequent memory allocation and deallocation can lead to memory fragmentation, which reduces memory utilization. Memory pools can effectively avoid the generation of memory fragmentation by pre-allocating a large contiguous block of memory.
In internet projects, memory pools are typically used to manage frequently created and destroyed small objects, such as HTTP request and response objects, database connection objects, etc. By using memory pools, we can greatly improve the efficiency of creating and destroying these objects, thereby enhancing the overall system performance.
In summary, the application of memory pools in internet projects mainly reflects the following aspects:
1. Improved Memory Allocation Efficiency: Memory pools can directly provide memory from already allocated memory blocks without needing to make system calls, greatly improving memory allocation efficiency.
2. Reduced Memory Fragmentation: Memory pools can effectively avoid the generation of memory fragmentation, thereby improving memory utilization.
3. Enhanced System Performance: Memory pools can significantly improve the efficiency of frequently created and destroyed small objects, such as HTTP request and response objects, database connection objects, etc., thereby enhancing overall system performance.
Therefore, memory pools have a wide range of applications in internet projects and are one of the important means to improve system performance.
6.2 Application of Memory Pools in Embedded Projects
Embedded systems are specialized computer systems that are typically embedded in other devices to control and manage the operation of the device. Since the resources (such as memory, CPU, etc.) of embedded systems are usually very limited, memory management is particularly important in embedded systems. In this case, memory pools become especially important.
In embedded systems, the application of memory pools mainly reflects the following aspects:
1. Improved Memory Utilization: Since the memory resources of embedded systems are usually very limited, improving memory utilization is very important. Memory pools can effectively avoid the generation of memory fragmentation by pre-allocating a large contiguous block of memory, thereby improving memory utilization.
2. Improved Memory Allocation Efficiency: In embedded systems, programs may need to frequently allocate and deallocate memory. Traditional memory management methods may not meet this demand, as they require a large number of system calls for memory allocation and deallocation, consuming significant CPU resources. Memory pools can effectively solve this problem by directly providing memory from already allocated memory blocks without needing to make system calls, thereby greatly improving memory allocation efficiency.
3. Reduced System Calls: In embedded systems, system calls are a very resource-intensive operation because they require switching the CPU’s operating mode, consuming significant CPU resources. Memory pools can greatly reduce the number of system calls by directly providing memory from already allocated memory blocks without needing to make system calls.
Therefore, memory pools have a wide range of applications in embedded systems and are one of the important means to improve system performance.
6.3 Application of Memory Pools in Large-Scale Projects
In large-scale projects, the application of memory pools is also very widespread. Large-scale projects typically involve a large amount of data processing and complex business logic, which requires an efficient memory management mechanism to support. In this case, memory pools become particularly important. Below, we will detail the application of memory pools in large-scale projects.
First, we need to understand the characteristics of large-scale projects. Large-scale projects typically involve a large amount of data processing and complex business logic, which requires an efficient memory management mechanism to support. In this case, memory pools become particularly important. A memory pool is a memory management technique that pre-allocates a large contiguous block of memory and then divides this space into multiple small blocks, each of which can be used independently. When a program needs to allocate memory, the memory pool can directly provide memory from the already allocated memory blocks without needing to make system calls. This greatly improves the efficiency of memory allocation.
Additionally, memory pools can effectively solve memory fragmentation issues. In traditional memory management methods, frequent memory allocation and deallocation can lead to memory fragmentation, which reduces memory utilization. Memory pools can effectively avoid the generation of memory fragmentation by pre-allocating a large contiguous block of memory.
In large-scale projects, memory pools are typically used to manage frequently created and destroyed small objects, such as database connection objects, thread objects, etc. By using memory pools, we can greatly improve the efficiency of creating and destroying these objects, thereby enhancing overall system performance.
In summary, the application of memory pools in large-scale projects mainly reflects the following aspects:
1. Improved Memory Allocation Efficiency: Memory pools can directly provide memory from already allocated memory blocks without needing to make system calls, greatly improving memory allocation efficiency.
2. Reduced Memory Fragmentation: Memory pools can effectively avoid the generation of memory fragmentation, thereby improving memory utilization.
3. Enhanced System Performance: Memory pools can significantly improve the efficiency of frequently created and destroyed small objects, such as database connection objects, thread objects, etc., thereby enhancing overall system performance.
Therefore, memory pools have a wide range of applications in large-scale projects and are one of the important means to improve system performance.
7. Conclusion
After understanding the importance, basic concepts, application scenarios of memory pools, and how to design and implement memory pools in C++, we hope this article can help you address memory management issues. We also explored the advantages and performance evaluation of memory pools to provide you with a more comprehensive understanding of this concept. We referenced the memory pool implementations of open-source libraries to provide more insights from practice. In actual projects, whether in internet projects, embedded projects, or large-scale projects, the application of memory pools is particularly important.