
AliMei Guide: As a very practical language in daily development and production, it is necessary to master some Python usages, such as web scraping, network requests, etc. However, Python is single-threaded, and how to improve Python’s processing speed is a very important issue. A key technology to address this issue is called coroutines. This article discusses the understanding and use of Python coroutines, mainly focusing on the network request module, hoping to help those in need.
ConceptsBefore understanding the concept of coroutines and their application scenarios, it is essential to understand several basic concepts related to operating systems, mainly processes, threads, synchronization, asynchrony, blocking, and non-blocking. Understanding these concepts is helpful not only for the coroutine scenario but also for message queues, caching, etc. Below, the author summarizes their understanding and materials found online. ProcessIn interviews, we often remember a concept: a process is the smallest unit of resource allocation in a system. Yes, a system consists of individual programs, i.e., processes, which are generally divided into text, data, and stack areas. The text area stores the code (machine code) executed by the processor, which is usually a read-only area to prevent accidental modification of the running program. The data area stores all variables and dynamically allocated memory, further divided into initialized data (all initialized global, static, constants, and external variables) and uninitialized data (global and static variables initialized to 0). Initialized variables are initially stored in the text area and copied to the initialized data area after the program starts. The stack area stores the instructions and local variables of active function calls. In the address space, the stack area is adjacent to the heap area, and their growth directions are opposite. Memory is linear, so we place code in low address areas, growing from low to high, while the stack area is unpredictable in size, growing from high to low. When the heap and stack pointers overlap, it indicates that memory is exhausted, leading to memory overflow. The creation and destruction of processes are resource-intensive operations. A process must compete for CPU time to run. For a single-core CPU, only one process can execute code at a time, so multi-process implementation on a single-core CPU is achieved by rapidly switching between different processes, making it appear as if multiple processes are running simultaneously. Since processes are isolated and each has its own memory resources, they are relatively safe compared to threads that share memory. Data between different processes can only be communicated and shared through IPC (Inter-Process Communication). ThreadA thread is the smallest unit of CPU scheduling. If a process is a container, a thread is a program running inside that container. Threads belong to processes, and multiple threads within the same process share the process’s memory address space. Communication between threads can occur directly through global variables, making inter-thread communication relatively unsafe, hence the introduction of various locking mechanisms, which will not be elaborated here. When one thread crashes, it causes the entire process to crash, meaning other threads also fail, but this is not the case with multiple processes; if one process crashes, another continues to run. In multi-core operating systems, by default, there is only one thread per process, so handling multiple processes is akin to one process per core. Synchronization and AsynchronySynchronization and asynchrony focus on the message communication mechanism. Synchronization means that when a function call is made, it will not return until the result is obtained. Once the call returns, the return value is immediately available, meaning the caller actively waits for the result. Asynchrony means that after a request is sent, the call immediately returns without a result, notifying the caller of the actual result through callbacks or other means. Synchronous requests require active reading and writing of data while waiting for results; asynchronous requests do not provide immediate results. Instead, after the call is made, the callee notifies the caller through status or notifications, or processes the call through a callback function. Blocking and Non-blockingBlocking and non-blocking focus on the state of the program while waiting for the call result (message, return value). A blocking call means that the current thread will be suspended until the call result returns. The calling thread only returns after obtaining the result. A non-blocking call means that the call will not block the current thread until the result is immediately available. Therefore, the distinguishing condition is whether the data accessed by the process/thread is ready and whether the process/thread needs to wait. Non-blocking is generally implemented through multiplexing, with select, poll, and epoll being several implementation methods. CoroutineAfter understanding the previous concepts, we can look at the concept of coroutines. A coroutine belongs to a thread and is also known as a micro-thread or fiber, with the English name Coroutine. For example, when executing function A, I want to interrupt and execute function B at any time, then interrupt B and switch back to execute A. This is the role of coroutines, allowing the caller to switch freely. This switching process is not equivalent to a function call because there is no call statement. The execution method is similar to multi-threading, but there is only one thread executing coroutines. The advantage of coroutines is their high execution efficiency because the switching of coroutines is controlled by the program itself, eliminating the overhead of switching threads. Additionally, since there is only one thread, there are no conflict issues, and there is no need to rely on locks (which consume many resources for locking and unlocking). Coroutines are mainly used in I/O-intensive programs to solve efficiency issues and are not suitable for CPU-intensive program processing. However, in practical scenarios, these two types of scenarios are very common. To fully utilize CPU efficiency, a combination of multi-process and coroutines can be used. We will discuss this combination later. PrinciplesAccording to Wikipedia’s definition, a coroutine is a subroutine scheduling component without priority, allowing subroutines to suspend and resume at specific points. Therefore, theoretically, as long as there is enough memory, a thread can have an arbitrary number of coroutines, but only one coroutine can run at a time, sharing the computer resources allocated to that thread. Coroutines are designed to fully leverage the advantages of asynchronous calls, while asynchronous operations are intended to avoid blocking threads during I/O operations.Knowledge PreparationBefore understanding the principles, we need to prepare some knowledge.
1) Modern mainstream operating systems are almost all time-sharing operating systems, meaning a computer serves multiple users using time-slice rotation, with the basic unit of system resource allocation being processes and the basic unit of CPU scheduling being threads.
2) Runtime memory space is divided into variable areas, stack areas, and heap areas. In memory address allocation, the heap area grows from low to high, while the stack area grows from high to low.
3) When a computer executes, it reads and executes instructions one by one. When executing the current instruction, the address of the next instruction is in the instruction register’s IP, the ESP register points to the current stack top address, and the EBP points to the base address of the current active stack frame.
4) When a function call occurs in the system, the operation is: first, push the parameters onto the stack from right to left, then push the return address onto the stack, and finally push the current value of the EBP register onto the stack, modifying the value of the ESP register to allocate space for the current function’s local variables in the stack area.
5) The context of a coroutine includes the stack area belonging to the current coroutine and the values stored in the registers.
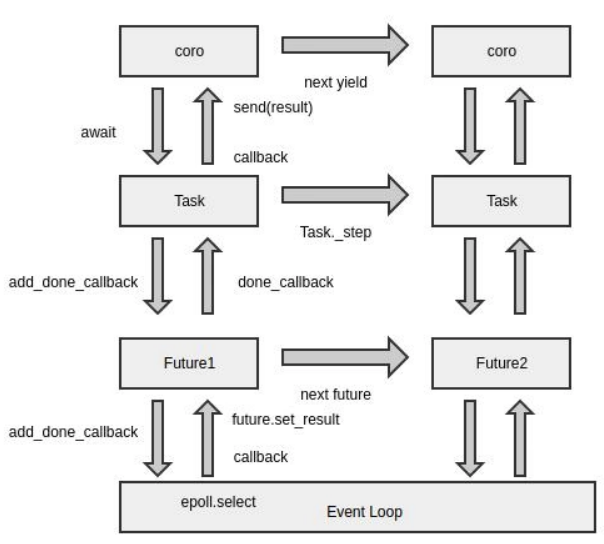
Event LoopIn Python 3.3, coroutines are used with the keyword yield from, and in 3.5, the syntax sugar async and await was introduced. We mainly look at the principle analysis of async/await. The event loop is a core component; those who have written JavaScript will be more familiar with the event loop, which is a programming architecture that waits for the program to allocate events or messages (Wikipedia). In Python, the asyncio.coroutine decorator is used to mark functions as coroutines, and these coroutines are used with asyncio and its event loop. In subsequent developments, async/await has become increasingly widespread. async/awaitasync/await is key to using Python coroutines. Structurally, asyncio is essentially an asynchronous framework, and async/await is the API provided for the asynchronous framework to facilitate user calls. Therefore, to use async/await to write coroutine code, users must work with asyncio or other asynchronous libraries. FutureIn actual development of asynchronous code, to avoid callback hell caused by too many callback methods while needing to obtain the return results of asynchronous calls, clever language designers created an object called Future, which encapsulates the interaction behavior with the loop. The general execution process is: after the program starts, it registers a callback function with epoll through the add_done_callback method. When the result attribute receives a return value, it actively runs the previously registered callback function, passing it to the coroutine. This Future object is asyncio.Future. However, to obtain the return value, the program must restore the working state, and since the lifespan of the Future object is relatively short, after each registration of a callback, event generation, and triggering of the callback process, the work may have already been completed. Therefore, a new object called Task is introduced, which is stored in the Future object to manage the state of the generator coroutine.Python has another Future object, concurrent.futures.Future, which is incompatible with asyncio.Future and can easily cause confusion. The difference is that concurrent.futures is a thread-level Future object, used to pass results between different threads when using concurrent.futures.Executor for multi-threaded programming. TaskAs mentioned above, Task is the task object that maintains the state of the generator coroutine and handles execution logic. The Task has a _step method responsible for the state transition of the generator coroutine and the EventLoop interaction process. The entire process can be understood as: Task sends a value to the coroutine, restoring its working state. When the coroutine reaches a breakpoint, it obtains a new Future object and then processes the callback registration process between the future and the loop. LoopIn daily development, there is a misconception that each thread can have an independent loop. In practice, only the main thread can create a new loop through asyncio.get_event_loop(), while using get_event_loop() in other threads will throw an error. The correct approach is to explicitly bind the current thread to the main thread’s loop using asyncio.set_event_loop().The loop has a significant flaw: its running state is not controlled by Python code, making it impossible to stably extend coroutines to run in multi-threaded environments during business processing. Summary
Practical ApplicationAfter introducing the concepts and principles, let’s see how to use them. Here, I will provide an example of a practical scenario to demonstrate how to use Python coroutines.ScenarioExternally receiving some files, each file contains a set of data, which needs to be sent to a third-party platform via HTTP and obtain results. AnalysisSince there is no processing logic before and after each data set in the same file, the network requests sent using the Requests library previously executed serially, meaning that sending the next data set had to wait for the return of the previous one, resulting in a long processing time for the entire file. This request method can be entirely implemented using coroutines. To facilitate sending requests with coroutines, we use the aiohttp library instead of the requests library. A brief introduction to aiohttp will be provided here.aiohttpaiohttp is an asynchronous HTTP client/server for asyncio and Python. Being asynchronous, it is often used on the server side to receive requests and in client web scraping applications to initiate asynchronous requests. Here, we mainly use it to send requests.aiohttp supports both client and HTTP server, enabling single-threaded concurrent I/O operations without using Callback Hell, and supports Server WebSockets and Client WebSockets, along with middleware. Code ImplementationLet’s get straight to the code; talk is cheap, show me the code~
import aiohttp
import asyncio
from inspect import isfunction
import time
import logger
@logging_utils.exception(logger)
def request(pool, data_list):
loop = asyncio.get_event_loop()
loop.run_until_complete(exec(pool, data_list))
async def exec(pool, data_list):
tasks = []
sem = asyncio.Semaphore(pool)
for item in data_list:
tasks.append(
control_sem(sem,
item.get("method", "GET"),
item.get("url"),
item.get("data"),
item.get("headers"),
item.get("callback")))
await asyncio.wait(tasks)
async def control_sem(sem, method, url, data, headers, callback):
async with sem:
count = 0
flag = False
while not flag and count < 4:
flag = await fetch(method, url, data, headers, callback)
count = count + 1
print("flag:{},count:{{}}".format(flag, count))
if count == 4 and not flag:
raise Exception('EAS service not responding after 4 times of retry.')
async def fetch(method, url, data, headers, callback):
async with aiohttp.request(method, url=url, data=data, headers=headers) as resp:
try:
json = await resp.read()
print(json)
if resp.status != 200:
return False
if isfunction(callback):
callback(json)
return True
except Exception as e:
print(e)
Here, we encapsulated the request method for sending batch requests, receiving the amount of data to be sent at once and the data itself. When used externally, it is only necessary to construct the network request object data and set the request pool size. Additionally, a retry function is set up to retry 4 times to prevent individual data network request failures during network fluctuations. Final EffectAfter refactoring the network request module using coroutines, when the data volume is 1000, the processing time improved from 816 seconds to 424 seconds, effectively doubling the speed. Moreover, as the request pool size increases, the effect becomes more pronounced. Due to the third-party platform’s simultaneous connection data limit, we set a threshold of 40. The optimization level is significant. Author’s NoteLife is short, I use Python. Whether coroutines are good or not, those who use them know. If you have similar scenarios, consider enabling them, or for other scenarios, feel free to leave comments for discussion.References:
Understanding async/await:
https://segmentfault.com/a/1190000015488033?spm=ata.13261165.0.0.57d41b119Uyp8t
Coroutine concepts and principles (C++ and Node.js implementations)
https://cnodejs.org/topic/58ddd7a303d476b42d34c911?spm=ata.13261165.0.0.57d41b119Uyp8t
Should Traditional Enterprises Go All In for Digital Transformation?
Is it a difficult question for traditional enterprises to go all in for digital transformation? What perspective should be used to make a choice?Identify the QR code below or click “Read the original text” to find out the answer from Aliyun MVP.


 You Might Also LikeClick the image below to read
You Might Also LikeClick the image below to read
How Did Alibaba Engineers Quickly Locate Online Memory Leaks in 48 Hours?

What Did Flink Do to Double Its GitHub Stars in Just One Year?
 Follow “Ali Technology” Stay Updated on Cutting-Edge Technologies
Follow “Ali Technology” Stay Updated on Cutting-Edge Technologies