Most open-source storage systems are built on the Linux operating system. This article introduces storage technology while also covering some Linux content, focusing on practicality. It will be helpful for both application development and kernel understanding.
When our project consists of thousands of files, manually writing a Makefile will be a nightmare. Fortunately, CMake helps us solve the most challenging problems. Today, we will introduce CMake, a tool for automatically generating Makefile files.
We will start with the simplest scenario, which involves only one source file. Of course, for a single file scenario, we can compile directly using gcc, but to illustrate the use of CMake, we will take this as our starting point. Later, we will gradually introduce more complex scenarios. The goal is simple: to lower the entry barrier and allow everyone to climb to the peak of Mount Tai unknowingly.

 Single File Software Engineering
Single File Software Engineering
We can first create a directory called simple, then create a file named main.cpp in that directory, with the following program code.
#include <iostream>
int main(int argc, char** argv)
{
std::cout << "this is a simple example!" << "\n";
return 0;
}Next, create a file named CMakeLists.txt. This file is used by CMake. The content of the file is as follows, isn’t it simple?
cmake_minimum_required(VERSION 3.16)
project(CMakeSunny
VERSION 1.0
DESCRIPTION "A CMake Tutorial"
LANGUAGES CXX)
add_executable(cmlearn
main.cpp)The cmake_minimum_required command specifies the minimum version of CMake required. The project command is used for naming, which includes the project name, version information, and project description. Finally, add_executable specifies the name of the executable file and the source code file.
With the above two files, create a directory named build under the root directory, then switch to that directory and execute cmake to generate a Makefile. Then execute the make command to compile the binary file. The specific commands to execute are as follows:
mkdir build
cd build
cmake ..
makeThe following image shows the relationship between the above files; main.cpp and CMakeLists.txt are the files we created. The directories and files in the build directory are generated by the cmake and make commands. The final generated binary file is also in the build directory, named cmlearn, as defined in CMakeLists.txt.
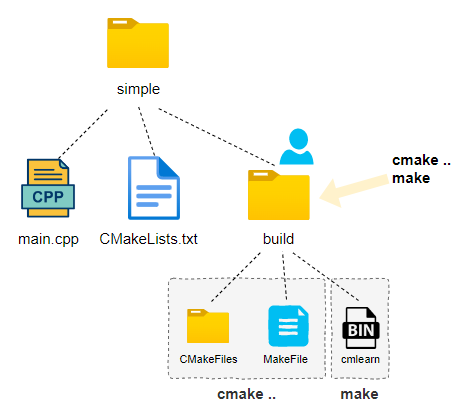

 Multi-file Software Engineering
Multi-file Software EngineeringFurthermore, if our software project typically contains more than one file, for example, we add a function for addition in a separate file. At this point, the project includes three separate files: main.cpp, add.cpp, and the header file add.h. The directory structure we created is shown in the image below.
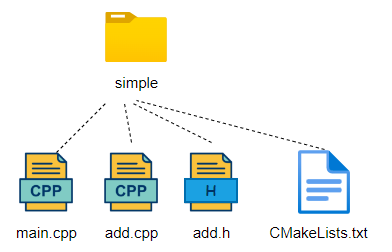
Next, we only need to make a very simple change to compile the new file’s content. As shown in the following code, we add add.cpp in the add_executable.
cmake_minimum_required(VERSION 3.16)
project(CMakeSunny
VERSION 1.0
DESCRIPTION "A CMake Tutorial"
LANGUAGES CXX)
add_executable(add
main.cpp
add.cpp)The content of the add.cpp file is as follows, and its function is simple: to implement an addition function.
int add(int a, int b)
{
return a+b;
}The implementation of the header file is even simpler, as shown below. Note that we are only demonstrating CMake’s functionality; many product-level necessary code names are not included here.
int add(int a, int b);To verify the correctness of the implementation, we can make some modifications in main.cpp to reference the function implemented in add.cpp. The modified content is as follows:
#include <iostream>
#include "add.h"
int main(int argc, char** argv)
{
int r = add(1, 3);
std::cout << "this is a simple example!" << r << "\n";
return 0;
}After completing the above modifications, you can return to the build directory, execute cmake .. and make commands, and you will see that a new binary file cmlearn has been generated. You can run this program and see that the result meets expectations.

 Software Engineering with Subdirectories
Software Engineering with SubdirectoriesIn reality, large projects are much more complex than what has been introduced above. For example, we mentioned the add.cpp file that implements an addition function. If we want to implement subtraction, multiplication, and division functions, these should also be implemented in separate files. It is best to place these calculations in a directory, such as a math directory. In large projects, source code is often organized this way, with the code for a functional module or detailed functionality organized in a subdirectory.
The source code can be organized into the structure shown in the image below, and a new CMakeLists.txt file must also be created in the math subdirectory. The content of this file can be very simple, as shown below, isn’t it simple!
add_library(math OBJECT sub.cpp
add.cpp)The add_library function is used to create a library. The library here corresponds to the concepts of dynamic and static libraries in Linux, but they are not exactly the same. In this example, we create an OBJECT type library, which generates object files. As mentioned earlier, this function can create dynamic and static libraries in Linux, which we will introduce in detail later.
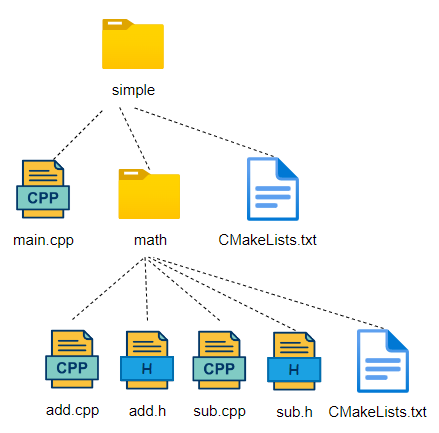
Below are several application scenarios for this function; for instance, STATIC is a static library, SHARED is a dynamic library, and OBJECT is the target file we are currently using. There are also MODULE, INTERFACE, and IMPORTED types.
add_library(<name> [STATIC | SHARED | MODULE]
[EXCLUDE_FROM_ALL]
[<source>...])
add_library(<name> OBJECT [<source>...])
add_library(<name> INTERFACE)
add_library(<name> <type> IMPORTED [GLOBAL])Having a CMakeLists.txt in the subdirectory is not enough; we need to add some content to the root directory’s CMakeLists.txt to establish a connection between the root directory and the math subdirectory. Establishing the connection is simple; we just need to add the following line of code to the root directory’s CMakeLists.txt.
add_subdirectory(math)
When we add the above code and execute the cmake command again in the build directory, it will trigger the generation of the Makefile in the subdirectory. When we execute the make command to compile, it will trigger the compilation of the subdirectory and generate object files.
target_link_libraries(cmlearn PUBLIC math)The above function implements the linking feature, linking the submodule math to the main module main, which will ultimately generate an executable program. However, we have not changed anything at the source code level, and the main program does not call any functions from add.cpp or sub.cpp, so there is actually no linking process.
If we want the main program to call the functions in math, we first need to include the header files in the main program. In the CMakeLists.txt, we need to add the following code to inform the compiler of the header file’s location. Otherwise, there will be an error message indicating that the header file cannot be found during compilation.
target_include_directories(cmlearn PUBLIC
"${PROJECT_SOURCE_DIR}/math"
)After completing the modifications to CMakeLists.txt, we finally need to modify the main program. The purpose of modifying the main program is to let it call the functions implemented in math. The modified main program is as follows, where it calls both the add and sub functions and includes the add.h and sub.h files at the beginning.
#include <iostream>
#include "add.h"
#include "sub.h"
int main(int argc, char** argv)
{
int sum = add(1, 3);
int diff = sub(3, 1);
std::cout << "The sum of 1 and 3 is " << sum << std::endl;
std::cout << "The diff of 3 and 1 is " << diff << std::endl;
return 0;
}
After completing the above modifications, we can execute the “cmake ..” command in the build directory, then run the make command to compile the program, and finally obtain an executable program.
Through the above example, we have gained a preliminary understanding of maintaining a large software project using CMake. In fact, CMake has even richer functionalities, which we will introduce in detail later.
Related Articles on Storage
The Dilemma of Thousands of Client NFS Services, Discussing Automatic Mounting Technology
Why is NFS Said to Have Poor Read/Write Performance, and How to Optimize It? End-to-End Analysis of NFS Protocol: Writing Data Flow End-to-End Analysis of NFS Protocol: File Locking Flow Analysis of Linux NFSD Software Architecture and Code Ceph File System Architecture and Practical Use Software Architecture and Case Analysis of Distributed Storage What is a File System? A Detailed Discussion Based on Ext4 in Linux Object Storage: Evolution from Standalone to Distributed What is Cloud Storage, Starting from Object Storage?