1. Continuously Trying to Implement AI Application End
Based on my understanding of operations and maintenance, I developed an open-source operation and maintenance tool https://github.com/shaowenchen/ops.
The Ops tool divides operation and maintenance tasks into two categories: script execution and file distribution, while the operation and maintenance targets, hosts and Kubernetes clusters, implement these two types of operations.
Ops provides capabilities such as Ops CLI command line terminal, Ops Server service API interface, Ops Controller cluster resource management, and a simple UI interface.
Although Ops Copilot was developed half a year ago, it did not leverage the capabilities of the Ops project and remained very independent, merely connecting to LLM, providing some conversational capabilities and the ability to execute scripts locally. I hope to have the opportunity to rewrite Ops Copilot with this AI Agent technology route.
The main work goal recently is to develop an AI Agent based on Ops to automate some operation and maintenance tasks.
2. Finding an Iterative AI Agent Technology Route is Important
The AI Agent is an important capability for AI to interact directly with the physical world, a key technology that can truly enhance productivity and free humans from repetitive and mechanical work.
AI Agents sound great, but this is from the perspective of a technology consumer. From the perspective of an AI Agent developer, this task is not so easy:
-
A strong demand that ideally matches the work content and drives you to develop the AI Agent. -
Refining the AI Agent’s scenarios requires a lot of usage scenarios to refine and continuously optimize implementation. -
An iterative technology route.
1 and 2 depend on the fundamentals of the position, whether it supports you to develop the AI Agent. 3 is controllable by oneself, and this article will focus on introducing an iterative AI Agent technology route.
Introducing new technologies in our team is never done overnight, always accompanied by periodic reports, phased results, risk control, etc. Even if you have good ideas and execution capabilities, internet teams find it hard to tolerate long periods of human investment without seeing any results.
The development model of internet products has already embraced agile development, which requires continuously delivering usable products, obtaining feedback, and continuing to iterate.
3. What is a Service-Oriented AI Agent
Service-oriented AI Agent is a term I coined, let me explain this term.
3.1 The Difference Between AI Agent and Copilot
AI Agent emphasizes autonomy and the ability to proactively solve problems, while Copilot emphasizes assistance and providing suggestions, requiring human guidance.
By identifying the main actor of the task, one can quickly distinguish between the two. If the task is led by a program, it is an AI Agent; if it is led by a person, it is a Copilot.
3.2 Service-Oriented AI Agent
Typically, the AI Agents people talk about are localized, meaning they need to execute on the device being operated, and if necessary, the AI Agent can deploy LLM services locally.
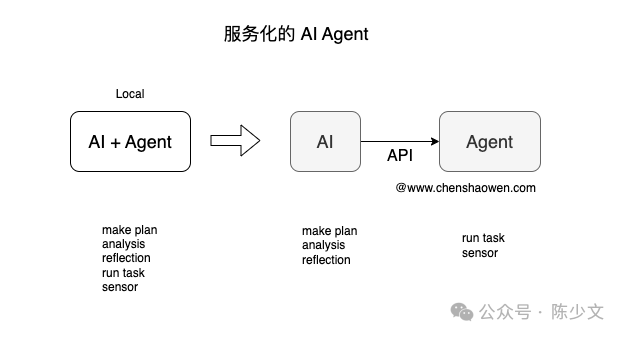
As shown in the image, a service-oriented Agent provides task execution and environmental perception capabilities in the form of an API.
For example, a Python script generated by AI needs to call the Agent’s API to execute and return the execution results. Similarly, if you need to obtain the current environmental information of the AI, you also need to call the Agent API.
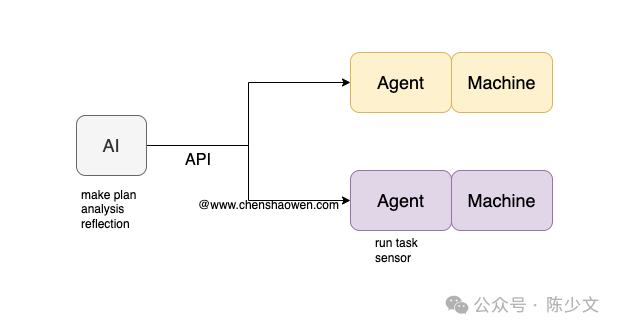
Of course, you can also adopt a multi-Agent approach. As shown in the image, each Agent connects to its respective operational object, keeping the environmental perception and execution capabilities on the device being operated.
Service-oriented AI Agents have the following advantages:
-
Separation of responsibilities: Agents are only responsible for execution and perception, while AI is only responsible for analysis and aggregation. -
Execution environments are more flexible and can be configured based on resource and security factors, such as cluster operation Agents, GPU operation Agents, and cloud resource operation Agents. -
It is easier to integrate with existing systems; a SideCar Agent can be developed for each system to connect to AI instead of integrating all systems with a localized AI Agent.
3.3 Ops is a Service-Oriented Agent End
The positioning of Ops Server is to execute built-in Task tasks in Ops through API interfaces. These Task tasks are sensitive operation and maintenance operations.
Through the Ops Server API interface, the following capabilities can be achieved:
Perception:
-
Host list -
Kubernetes cluster information -
Information that can be obtained through Shell on the Host -
Information that can be obtained through kubectl on the Kubernetes cluster, as well as information that can be obtained through Shell on each node
Execution:
-
Host operations -
Kubernetes cluster kubectl operations, as well as Shell operations on each node
These capabilities are sufficient for AI to complete most operation and maintenance tasks.
4 Start Writing a Service-Oriented AI Agent
4.1 Abstract Two Objects
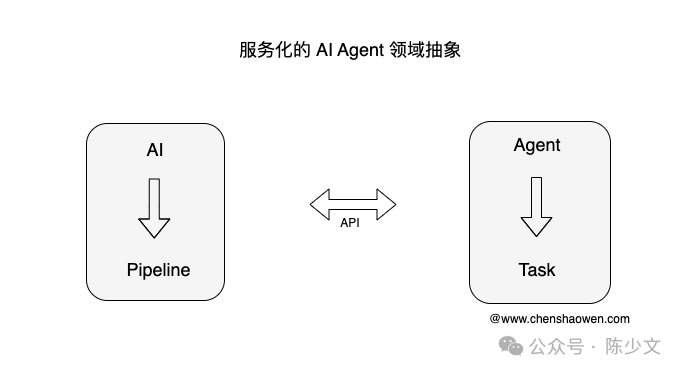
As shown in the image, in the service-oriented AI Agent:
-
The object driving AI is the Pipeline.
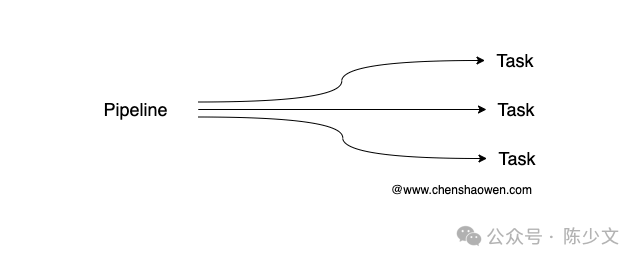
An AI-side Pipeline corresponds to multiple Tasks on the Agent side. These Tasks achieve the goals of the Pipeline through a certain sequence of combinations, conditional controls, and variable values.
-
The object driving the Agent is the Task.
In Ops, I have already provided a Task CRD object that comes with a large number of Shell scripts for converging and reusing basic operation and maintenance operations.
4.2 Use Task to Encapsulate Basic Operations of the Agent
Here are some operation and maintenance Tasks we use online:
kubectl -n ops-system get task
NAME CRONTAB STARTTIME RUNSTATUS
check-gpu-drop init
check-node-existed init
check-npu-drop init
check-pod-existed 36m successed
check-svc-existed init
cordon-node init
delete-pod 48m successed
get-gpu-status init
get-os-status init
get-pod-error-logs-byname 36m successed
get-pod-error-logs-bysvc 62m successed
get-podlogs-byname init
get-podlogs-bysvc init
inspect-clusterip 120m successed
list-clusters 45h failed
list-error-events-bypod 36m successed
list-error-events-bysvc 62m successed
list-events-bypod init
list-events-bysvc init
list-nodes init
list-pods init
list-pods-abnormal init
list-pods-bysvc 62m successed
list-tasks 45h successed
none-action init
top-nodes-bycpu init
top-nodes-bymem init
top-pods-bycpu init
top-pods-bycpu-node init
top-pods-bymem init
top-pods-bymem-node init
uncordon-node init
Adding a new Task only requires writing a Yaml file, making it very easy to develop a new Task.
4.3 Use Pipeline to Connect Business Scenarios
Since Ops does not abstract the concept of Pipeline, I defined the Pipeline object on the AI side.
For each specific scenario, a Pipeline can be written. Here is an example:
var allPipelines = []ops.LLMPipeline{
pipelineGetClusterIP,
}
// View cluster IP details
var pipelineGetClusterIP = ops.LLMPipeline{
Desc: "Query - View cluster IP details",
Namespace: "ops-system",
Name: "get-cluster-ip",
NodeName: "anymaster",
Variables: []ops.VariablePair{
{
Key: "clusterip",
Desc: "For example, `clusterip: 1.2.2.4`, 1.2.2.4 is clusterip",
Required: true,
},
},
LLMTasks: []ops.LLMTask{
{
Name: "inspect-clusterip",
},
{
Name: "app-summary",
},
},
}
Here, two Tasks are used:
-
inspect-clusterip – Query cluster IP details, executed via API call, the task will be dispatched to the Agent for execution. -
app-summary – Summarize the output information through LLM.
There are two types of Tasks: one type is obtained in real-time from the Agent; the other type is custom Tasks defined on the AI side, which is to encapsulate some tasks unrelated to Ops. Of course, another Agent can also be developed to execute such tasks.
4.4 Development on the AI Side
Typically, an AI Agent is a process that runs in a loop, continuously processing expected data, making plans, executing plans, reflecting, and making new plans, repeating until the problem is solved.
However, this processing method consumes a lot of tokens, and during the early stages of project development, prompts, tasks, and environmental perception are not well-prepared, making it difficult to achieve good results. Therefore, it is mainly divided into the following iterative stages:
-
Implement AI Agent assistance capabilities for preset scenarios.
For specific scenarios with fixed contexts and determined inputs, our goal in developing the AI Agent will be very clear, making it easier to achieve good results. At the same time, this is also for us to accumulate relevant Task capabilities and debug prompts.
-
Recall key information through vector libraries and surrounding systems.
It can be foreseen that as the number of scenarios increases dramatically, the information needed to provide to LLM for Pipeline description, clusters, and hosts will grow, leading to the following problems:
-
Long texts will reduce the accuracy of identifying which Pipeline to execute. -
Lack of sufficient context and feedback will lead to the AI Agent being unable to solve problems or verify whether the problems are resolved.
At this point, it is necessary to recall more relevant data, including Pipeline-related information, execution results, and information from surrounding systems that depend on it. This allows the AI Agent to autonomously execute the Pipeline based on this information, obtain results, and continue executing until the termination condition is met.
-
Autonomous awakening.
No longer requiring manual at awakenings, but allowing the AI Agent to automatically capture key information and awaken autonomously. From a technical standpoint, this is not difficult; the challenge lies in whether the AI Agent is ready to adapt to all scenarios.
Using manual at awakenings can only cover a portion of the scenarios, but if the AI Agent needs to awaken automatically, there will be many more details and boundaries to consider.
-
AI autonomously writes Pipelines.
The AI Agent autonomously retrieves relevant Tasks and contextual information from the vector library based on inputs, writes Pipelines, and even new Tasks. At this point, the AI Agent has reached an ideal state.
4.5 Check the Effects I Have Achieved
Currently, according to the above ideas, I have completed stage 1, but stages 2, 3, and 4 are technically feasible and require time for iteration.
-
Restart a Pod.
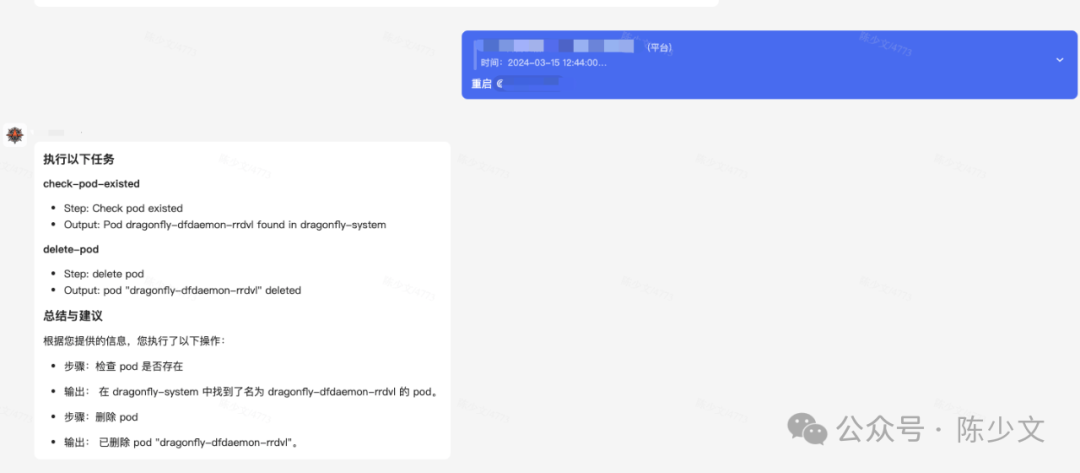
-
View the details of an alarm message.
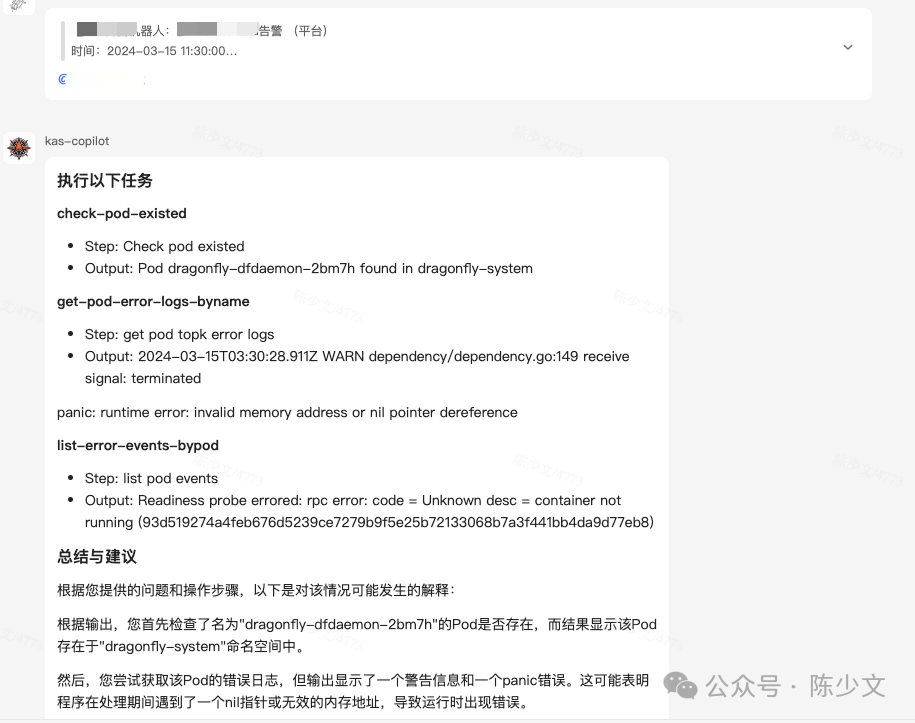
Basically realized the connection between Pipelines and Tasks, able to handle some basic operation and maintenance scenarios. It is worth noting that the cost of integrating new scenarios is particularly low. You only need to reuse or add Tasks, register them to allTasks, and orchestrate Pipelines registered to allPipelines to add new scenarios.
5. Alignment is a Huge Challenge in Developing AI Agents
It may not only be the development of AI Agents; all LLM application scenarios will encounter alignment issues.
5.1 How to Effectively Extract Key Information
When the AI side runs the Pipeline, it needs to hit the Pipeline and extract relevant running parameters. For this, it is necessary to:
-
Describe the purpose of the Pipeline in detail.
var pipelineGrafanaAlertPodErrorRequest = ops.LLMPipeline{
Desc: "Analysis - Grafana alert Pod exception request ratio greater than 10%",
}
The Desc allows LLM to accurately identify the purpose of the Pipeline.
-
Describe the meaning, format characteristics, etc., of the variables in detail.
type VariablePair struct {
Key string
Value UniversalValue
Desc string
Regx string
ExampleValue UniversalValue
DefaultValue UniversalValue
Required bool
}
Inaccurate extraction of variables is a common problem; detailed descriptions of dependent variables are needed. These descriptions include variable descriptions, regular expressions, example values, default values, and whether they are required. The more features are present, the easier it is for LLM to make correct judgments.
To enable the AI side to correctly identify the operational cluster objects, I even directly submitted the dynamically obtained Cluster list to LLM.
parmerters := jsonschema.Definition{
Type: "object",
Properties: map[string]jsonschema.Definition{
"nameRef": {
Type: "string",
Description: m.GetClusterManager().BuildtMarkdown(),
Enum: m.GetClusterManager().GetList(),
},
},
Required: []string{"nameRef"},
}
5.2 Retry is Still Effective
In a month, I wrote three or four versions of the AI Agent. The first version directly connected AI to Tasks without abstracting Pipelines, and the results were okay, but it often encountered situations like this.
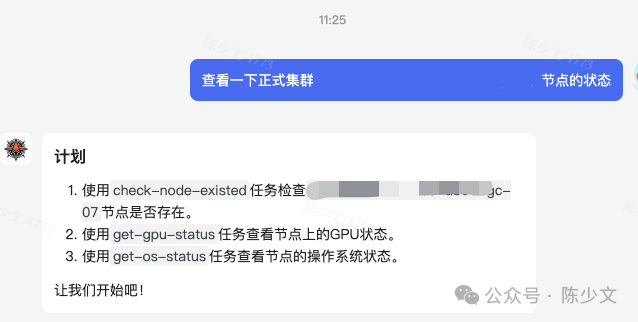
As shown in the image, LLM sometimes does not output the JSON format data I want, but directly outputs a Plan. The expected response should be LLM returning a segment of JSON data, then the Agent executing these Tasks and returning the final result to the user. The following image shows an expected example:
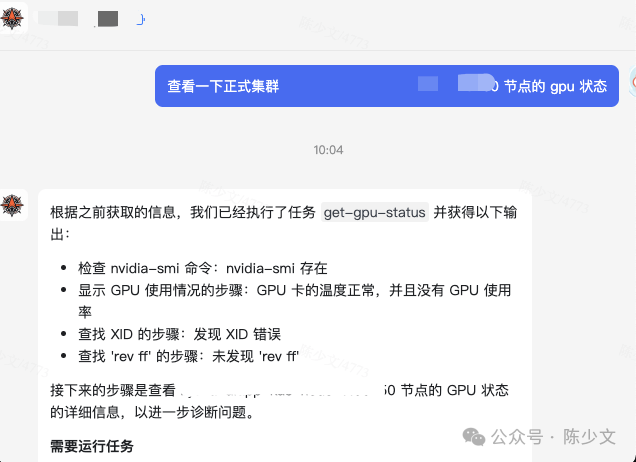
Therefore, retrying is still one of the key methods to solve alignment problems. When LLM does not understand your intent, you only need to retry once. When LLM cannot effectively extract key information, you only need to retry once. When LLM cannot provide the expected result, you only need to retry once.
When executing the Pipeline, if the program encounters an unexpected state, retrying usually improves the final response result immediately.
5.3 Reflection/Reward Can Improve Accuracy
Similarly, in the retry loop, if feedback or rewards can be added, it can also enhance LLM’s alignment capability with the scenario’s intent.
There are related descriptions in https://blog.langchain.dev/reflection-agents/, as shown in the image below:
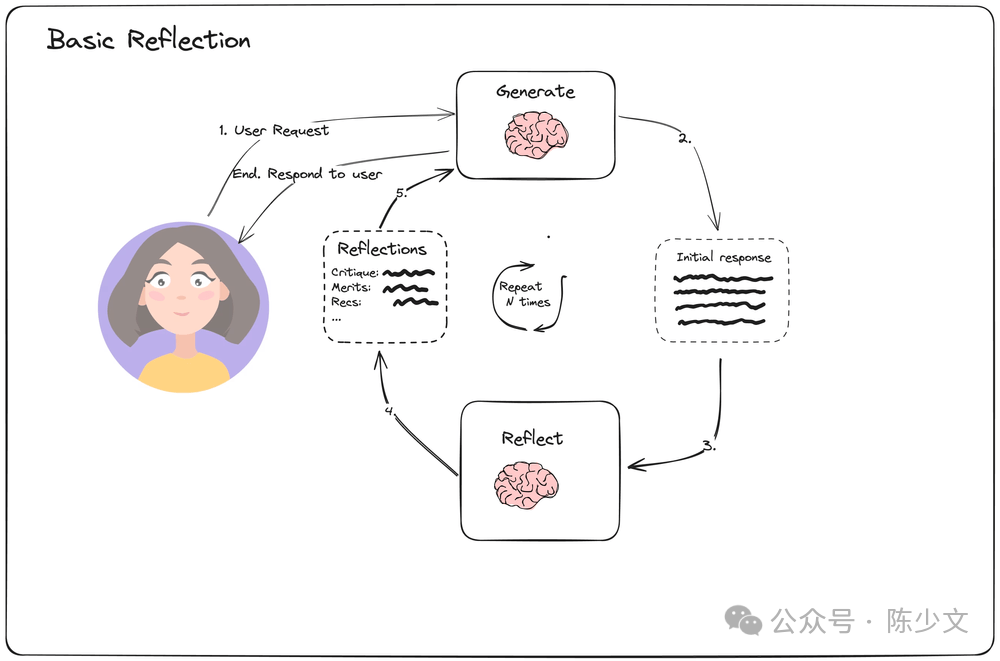
We only need to check whether the Pipeline’s state meets expectations, make our requests, check certain key states, provide evaluations, and then retry with LLM.
5.4 Pre-selection of Data
As I mentioned earlier, when integrating a large number of scenarios, it will inevitably trigger the LLM’s token limit for word processing, and long texts will weaken LLM’s information extraction capability.
Pre-selecting data can avoid these problems and narrow down the issues to relevant input information.
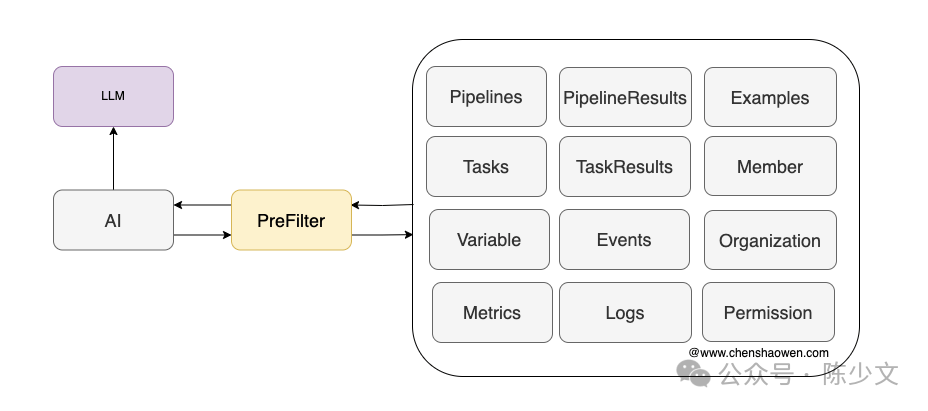
As shown in the image, the types of data that need pre-selection may include many, such as:
-
Execution templates, Pipeline, Task templates. -
Context, current input-related domain information, for operations and maintenance, this includes Metrics, Logs, Events, etc., which can also be queried in real-time through Tasks. -
Team personnel-related information, such as the application leader. -
Permission information, which needs to verify the user’s permissions when executing Permission Tasks. -
Knowledge base, which requires using vector databases for recall. -
Some examples and successful cases for LLM to do few-shot learning.
6. Conclusion
This article mainly summarizes my recent development of AI Agent applications, with the main content as follows:
-
In the team, implementing AI Agent applications and finding an iterative technology route is crucial, as it is beneficial for reporting and presenting phased results.
-
I introduced a design idea for service-oriented AI Agents, which separates the responsibilities of analysis (AI side) and execution (Agent side), with the two interacting through APIs. Service-oriented AI Agents facilitate integration with existing systems and avoid integrating all systems into a localized AI Agent.
-
I introduced an iterative idea for developing service-oriented AI Agents, where the AI side uses Pipeline objects, and the Agent side uses Task objects. First, align specific scenarios through built-in Pipelines, improve accuracy under large-scale practices through vector retrieval, then enable AI Agents to autonomously awaken and integrate into all scenarios, and finally allow LLM to autonomously orchestrate Pipelines to complete tasks.
-
I introduced several methods to solve alignment issues when developing AI Agent applications, including accurate function and field descriptions, retry mechanisms, Reflection/Reward mechanisms, and data pre-selection.
What is learned from books is shallow, and true understanding comes from practice. Only by actually writing AI Agents to solve real problems can one discover so many pitfalls; this article serves as a record.