As a front-end developer, caching is a concept we encounter daily; it’s a common interview question and frequently comes up in our work. While most of us are familiar with caching headers, have we ever thought about why HTTP’s caching control is designed this way?
First, why have caching?
The code and resources on a webpage are downloaded from the server. If the server is far from the user’s browser, the download process can be time-consuming, causing the webpage to load slowly. The next time you visit the same webpage, the resources need to be downloaded again. If there are no changes to the resources, this re-download is unnecessary. Therefore, HTTP was designed with caching functionality, allowing downloaded resources to be stored so that when the page is reopened, it can read from the cache, significantly speeding up the process.
Furthermore, every request requires the server to handle various tasks, such as parsing the URL, reading files, and returning responses. The server has a limit to how many requests it can handle simultaneously, meaning there is a maximum load. By reducing unnecessary resource requests through caching, we can free up the server to handle more meaningful requests.
In summary, to improve webpage loading speed and reduce server burden, HTTP was designed with caching functionality.
So how is caching functionality designed in HTTP?
If everyone were to design HTTP’s caching functionality, how would you approach it?
The easiest solution would be to specify a time point; use the cache directly until that time, and only download new resources after it expires.
This is how HTTP 1.0 was designed, using the Expires header, which specifies the expiration time of resources. Before this time, the server is not requested, and the previously downloaded cached content is used:
Expires: Wed, 21 Oct 2021 07:28:00 GMT
However, this design has a bug; can anyone guess what it is?
First, this time refers to GMT, meaning it will convert to Greenwich Mean Time, which eliminates timezone issues.
The server converts the local time to GMT time. For example, if the current time is xxx and the desired caching time is yyy, then Expires is set to xxx + yyy.
If the browser’s time is accurate, the conversion to GMT should also yield xxx, so the cache time is yyy.
This is the ideal situation.
But what if the browser’s time is inaccurate? After converting to GMT, it may not be xxx, which means the actual caching time is not yyy, and this is the problem.
Thus, the expiration time cannot be calculated by the server; it should be calculated by the browser itself.
This is why HTTP 1.1 changed to the max-age method:
Cache-Control: max-age=600
The above indicates that the resource is cached for 600 seconds, or 10 minutes.
By letting the browser calculate the expiration time, the issues with Expires are avoided. (This is also why max-age is preferred when both max-age and Expires are present.)
Of course, different resources can have different max-age settings. For instance, when you open the homepage of Bilibili, you will see that different resources have different max-age values:
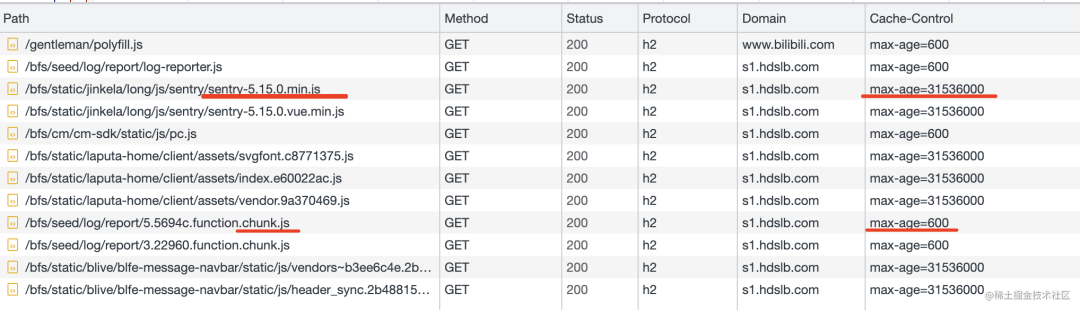
For example, some library’s JS files are set to expire in 31536000 seconds, or 1 year, because they generally do not change, so setting them for a year is reasonable.
In contrast, business-related JS files are set to expire in 600 seconds, or 10 minutes, as business code often changes.
Observant readers may notice that previously, headers were in a key: value format, but now they appear as key: k1=v1,k2=v2. Why is that?
That’s right; this is also a design change in HTTP 1.1, where they aimed to consolidate all caching-related headers, so they wrapped them in one layer and placed them in the Cache-Control header.
Thus, the naming also changed; Expires: xxx is referred to as a message header, while Cache-Control: max-age=xxx’s max-age is called a directive.
After changing to max-age, the browser will calculate the expiration time locally and download new resources accordingly.
But is that all?
Simply reaching the expiration time doesn’t mean the resource has changed; downloading the same content again is still unnecessary.
Therefore, it is necessary to confirm with the server whether the content has changed. If it has, then re-download; otherwise, no need to download again. This involves a negotiation process.
Thus, HTTP 1.1 also designed caching negotiation headers.
When we say a resource has expired, the browser needs to confirm with the server whether there are updates. How do we determine if a resource has expired?
It is relatively straightforward to use either the file content’s hash or the last modified time, known as Etag and Last-Modified, respectively:
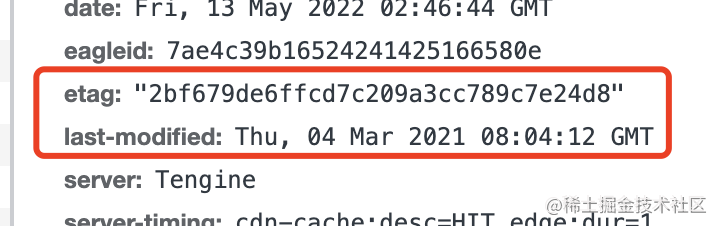
When the server returns the resource, it will include these two headers.
So when the max-age time is reached, it can send a request to the server with the etag and last-modified to check if the resource has been updated.
The header that includes the etag is called If-None-Match:
If-None-Match: "bfc13a64729c4290ef5b2c2730249c88ca92d82d"
The header that includes the last-modified time is called If-Modified-Since:
If-Modified-Since: Wed, 21 Oct 2015 07:28:00 GMT
The server will check if the resource has changed. If it has, it will return 200 and include the new content in the response body, and the browser will use this newly downloaded resource.
If there are no changes, it will return 304, and the response body will be empty, allowing the browser to read from the cache.
This adds a negotiation phase, allowing local cache expiration to avoid redundant downloads when the server’s resource has not changed.
If a file is known not to change and does not require negotiation, how can we inform the browser? This can be done using the immutable directive to tell the browser that this resource is unchanged and does not require negotiation. Thus, even if the cache expires, it will not send validation headers (If-None-Match and If-Modified-Since):
Cache-control: immutable
Earlier, we discussed that HTTP 1.1 changed to Cache-control: k1=v1,k2=v2 format. Besides max-age, what other directives are there?
We have only covered browser caching control so far, but the request from the browser to the server may pass through many layers of proxies.
How is the caching of proxy servers controlled?
The cache in the browser is private to the user, known as private cache, while the cache on the proxy server is accessible to everyone, known as public cache.
If a resource should only be cached in the browser and not on the proxy server, it should be set to private; otherwise, set to public:
For example, this setting allows the resource to be cached on the proxy server for one year (the proxy server’s max-age is set with s-maxage) and caches it in the browser for 10 minutes:
Cache-control: public, max-age=600, s-maxage=31536000
This setting allows only the browser to cache:
Cache-control: private, max-age=31536000
Moreover, does cache expiration mean it cannot be used at all?
Not necessarily; it is also possible to use expired resources with such directives:
Cache-control: max-stale=600
The stale directive means not fresh. Including max-stale in the request allows the use of expired resources for a duration of 600 seconds; however, beyond that, it cannot be used.
Cache-control: stale-while-revalidate=600
This can also be set to stale-while-revalidate, meaning that while validating (negotiating), the expired cache can be used temporarily.
Cache-control: stale-if-error=600
Or set stale-if-error, meaning that if negotiation fails, the expired cache can still be used.
In this way, the max-age expiration time is not entirely strict; it allows for the use of expired resources for a period.
If I want to ensure that expired cache is not used until negotiation is complete, how can I enforce that?
This directive can be used:
Cache-Control: max-age=31536000, must-revalidate
The name itself indicates that if the cache has expired, it must wait for validation to complete, and expired cache cannot be used in the meantime.
Some may wonder, aren’t caches set by the user? How can there be both allowed and disallowed expiration?
While an individual user wouldn’t use both methods simultaneously, CDN providers might want to restrict the use of expired caches; hence they can set the must-revalidate directive.
Finally, HTTP also supports disabling caching altogether, like this:
Cache-control: no-store
Setting the no-store directive means files will not be cached, eliminating expiration time and negotiation processes.
If caching is allowed but requires negotiation each time, use no-cache:
Cache-control: no-cache
Some may find the difference between no-cache and must-revalidate confusing; let’s clarify:
No-cache effectively disables strong caching, requiring negotiation every time, while must-revalidate only prohibits the use of expired caches after strong caching has expired, enforcing negotiation.
Thus, we have completed our discussion on HTTP’s caching settings. Let’s summarize:
Summary
Caching can speed up page loading and reduce server pressure, which is why HTTP was designed with a caching mechanism.
In HTTP 1.0, the Expires header was used to control caching by specifying a GMT expiration time; however, this created issues when the browser’s time was inaccurate.
In HTTP 1.1, the max-age method was adopted to set expiration times, allowing the browser to calculate them. Additionally, all caching-related controls were consolidated under the Cache-control header, with directives like max-age.
After cache expiration, HTTP 1.1 introduced a negotiation phase, using If-None-Match and If-Modified-Since headers to send the resource’s Etag and Last-Modified to the server to check for expiration. If expired, it returns 200 with new content; otherwise, it returns 304, allowing the browser to use the cache.
In addition to the max-age directive, we also learned about the following directives:
-
public: Allows the proxy server to cache the resource -
s-maxage: Expiration time for the resource on the proxy server -
private: Disallows the proxy server from caching the resource; only the browser can cache it -
immutable: Indicates that the resource is unchanged and does not require negotiation, even if expired -
max-stale: Allows the use of expired resources for a certain time -
stale-while-revalidate: Returns expired resources during validation (negotiation) -
stale-if-error: Returns expired resources if negotiation (validation) fails -
must-revalidate: Prohibits using expired resources; negotiation must be completed first -
no-store: Disables caching and negotiation -
no-cache: Allows caching, but requires negotiation each time
While there are quite a few HTTP caching-related directives, they are all centered around max-age and the negotiation process after expiration. If the concepts are clear, they are quite easy to remember.