We are very excited to share some amazing advancements in bringing the latest generative AI and large language models (LLMs) to edge computing.

Since the introduction of Transformers and NVIDIA’s launch of the Ampere GPU in 2020, we have witnessed a rapid increase in the scale and intelligence of models, approaching human levels. This has been a tremendous leap in a relatively short time, and things seem to be accelerating, especially with the open-sourcing of foundational models like Llama and Llama2. There is a vast community of researchers, developers, artists, and enthusiasts working tirelessly day and night. This is incredibly exciting, and the pace of innovation is almost hard to keep up with. There is a wide world waiting for us to explore, not just LLMs, but also visual language models, multimodal models, and zero-shot visual Transformers, all of which have a significant impact on computer vision. Thanks to everyone who has contributed to this field in some way. Many have dedicated years, even decades, to this effort, and thanks to them, the future of AI seems to have suddenly arrived. Now is the time to seize this moment, bring it to the world, and make a positive impact.
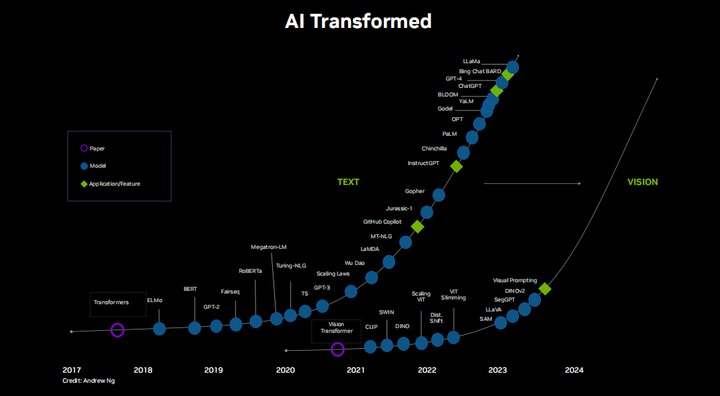
Naturally, due to the immense computational and memory demands of these large models, running them on consumer-grade hardware is fraught with challenges. Understandably, there has been relatively little focus on deploying LMs and generative AI for local, on-site, and embedded devices. However, in the face of all this, more and more people are doing just that. A shout-out to our local Llama and our Stable Diffusion. In edge computing, the Jetson platform is particularly well-suited, as it features up to 64GB of unified memory, is equipped with the Jetson AGX Orin module, has 2048 CUDA cores, and delivers 275 TOPS performance, all while being compact and power-efficient. Why go through the trouble? Why not just do everything in the cloud? The reasons are the same as always for edge computing, including latency, bandwidth, privacy, security, and availability. One of the most impactful areas shown here is human-computer interaction, specifically the ability for natural dialogue and enabling robots to autonomously complete tasks. As we have seen, especially in cases involving real-time audio and visual data, and any situation concerning safety, you really need to pay attention to latency. Additionally, understanding how to run these things locally while retaining all data seems like a good option. Fortunately, there is a large-scale computing stack available for you to use openly.

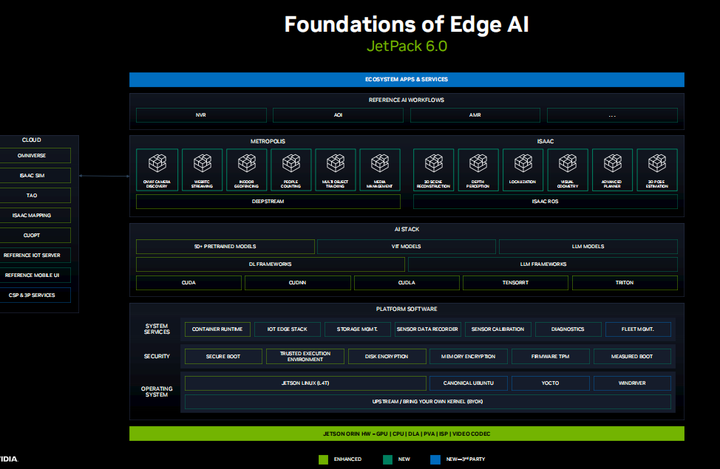
We have been working hard on JetPack 6.0 for some time now, which is our largest upgrade to the Jetson platform software architecture, now based on an upstream Linux kernel and optional operating system distributions. We have decoupled the version of CUDA from the underlying LTBSP, allowing you to freely install different versions of CUDA, cuDNN, and TensorRT. We provide optimized builds and containers for many machine learning frameworks, such as PyTorch and TensorFlow, now including all LLM and VIT libraries. Pre-trained models can be downloaded from TAO, NGC, and HuggingFace, which perform exceptionally well when running on JetPack and can also be used with edge devices like Jetson. We are bringing more components and services from Metropolis to Jetson, with video analytics through DeepStream. We just released Isaac ROS 2.0, which includes highly optimized vision modules, including SLAM and zero-copy transfers between ROS nodes for autonomous robotics. JetPack 6.0 will be released later this month, supporting Jetson and other devices, and future upgrades should be easier.
Today, we will show you how to run these applications. First, we will look at our open vocabulary visual Transformers, such as Clip LIT and SAM, which can detect and segment almost anything you ask them to using natural language. Then we will cover LLMs, followed by BLM visual, language models, multimodal agents, and vector databases, providing them with long-term memory and the ability to ground with real-time data. Finally, we will connect all of this through streaming speech recognition and synthesis. We will run all of this on the Jetson development board.

Thus, we have optimized several key VITs using TensorRT to provide real-time performance on Jetson. These VITs have improved accuracy, zero-shot, and open vocabulary capabilities, meaning they can be prompted through natural language to express context and are limited to a certain number of object categories pre-trained. Clip is a foundational multimodal text and image embedding that allows you to easily compare both after they have been encoded and can easily predict the most similar matches. For example, you can provide an image and a set of complex labels, and it will tell you which labels are contextually most similar without needing further training on object categories, meaning it is zero-shot. It has been widely adopted as an encoder or backbone in more complex VITs and visual language models, generating embeddings for similarity, search, and vector databases. Similarly, OWL-VIT and Sam are used for detecting and segmenting any object. OWL-VIT is used for detection, while Sam is used for segmentation. Here, Efficient VIT is an optimized VIT backbone that can be applied to either and provide further acceleration. Again, all of these are available using TensorRT and have been available in JetPack 5, and will certainly be available in JetPack 6.
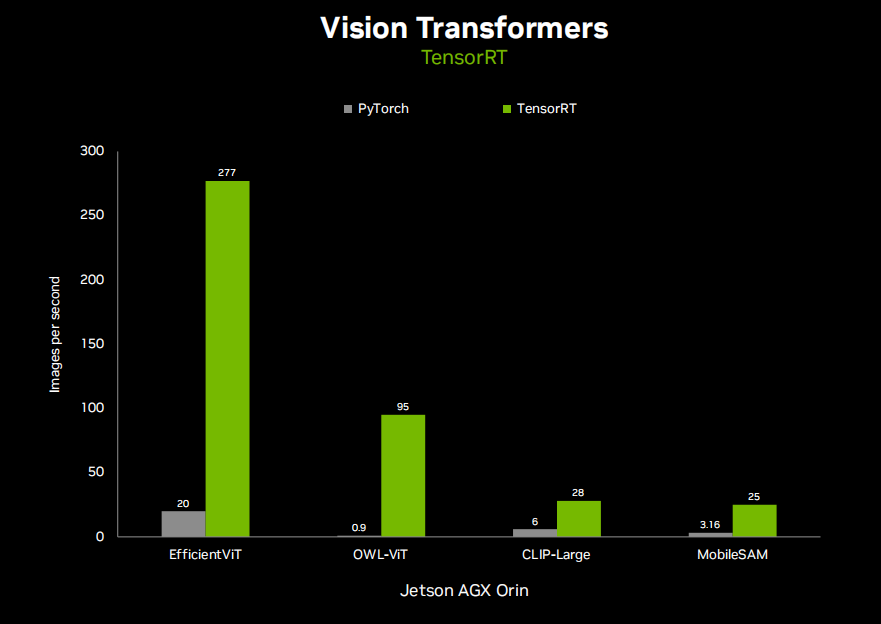
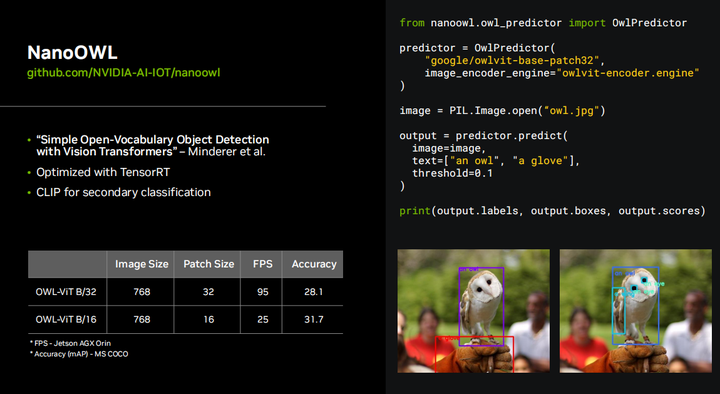
This demonstration showcases the capabilities of OWL VIT. You can see that you can input what you want to detect, and if it finds them, it will start generating those bounding boxes. Previously, you had to capture your own dataset on a training dataset, annotate it, train it with models like SSD or YOLO, and the number of object classes was limited. Well, you know, OWL VIT is based on CLIP, which contains a vast number of images and different objects, so you can query almost anything here. This is a true game changer, eliminating the need to train your own model for every last detection scenario you want to execute. This is a very impressive technology that can be deployed in real-time on Jetson, achieving 95 frames per second on AGX Orin.

So, all the code needed to run OWL VIT in real-time can be found on GitHub. This project is called the NanoOWL project. Well, because we optimized the original OWL-VIT model with TensorRT, this is how we improved it from 0.9 frames per second to 95 frames per second, and there are various different backbone networks you can run different variants of OWL-VIT with higher accuracy, lower accuracy, higher performance, and lower performance. It also has a very simple Python API where you just input your image and text prompt, and it outputs the bounding boxes and their classifications. Object detection remains the most popular computer vision algorithm to date, and this project can revolutionize that.
Thus, this segmentation analog is called SAM or Segment Anything Model, which works very similarly; basically, you just provide some control points, like clicking on different parts of the image you want to segment, and it will automatically segment all those different spots for you, no matter what they are. In the past, you had to manually create a segmentation dataset, train a model on it. And those segmentation datasets are very resource-intensive, but now you know you can click on any highlight, and it will segment for you. When you combine it with another project, TAM (or Track Anything), it can segment anything in a video for you. We also provide containers for this on Jetson that you can use immediately.

Next, we will discuss large language models, here is the LLM performance chart running on Jetson AGX Orin.
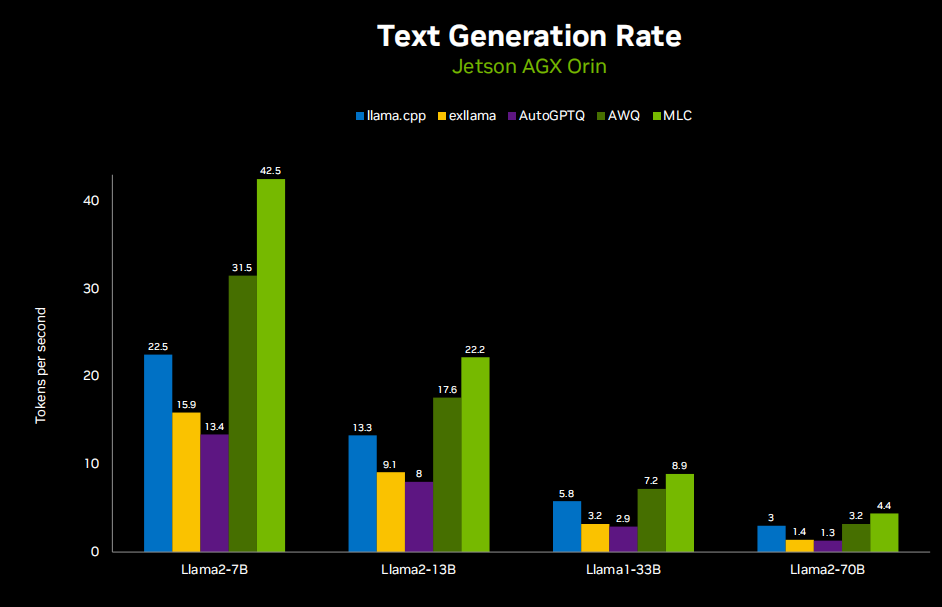
Here is a demonstration:
Llamaspeak is an interactive chat application that utilizes real-time NVIDIA Riva ASR/TTS, allowing you to verbally communicate with an LLM running locally. It is currently available as part of jetson-containers. This runs on Jetson AGX Orin.
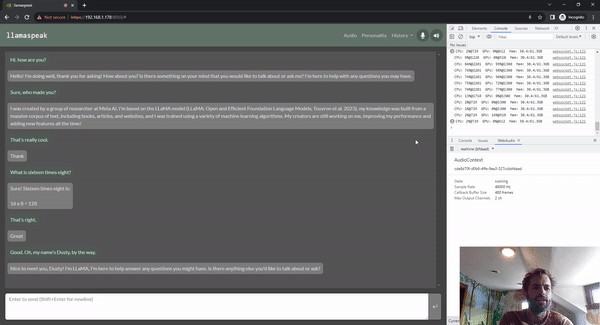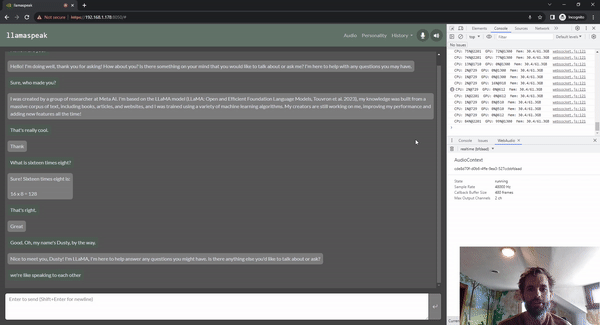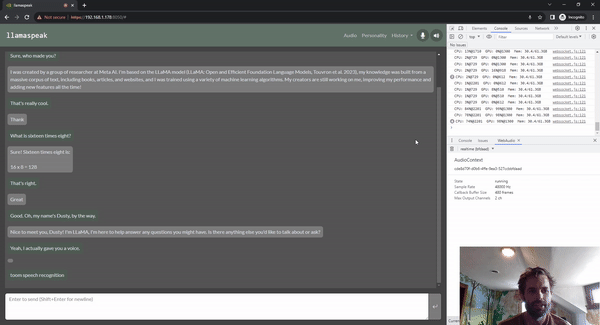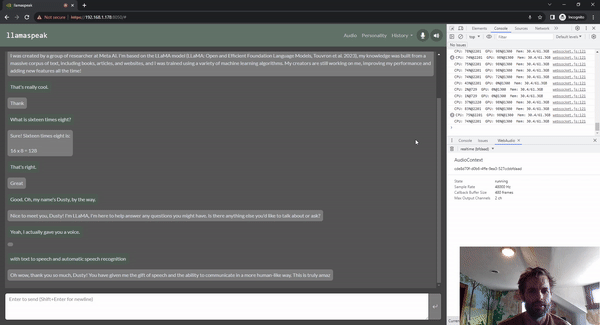
Thus, clearly, as edge devices, most Jetson-based embedded systems are connected with cameras or other visual sensors, so everyone in the community is very interested in models like Llama, mini GPT-4, and many emerging multimodal embedding models. They essentially work by using embedding models like CLIP to combine text and images into a common embedding space, where concepts are very similar. So if there is a picture of a dog and the word “dog,” their positions in the multi-dimensional embedding space are very similar. That is to say, they convey the same idea or sentiment to the LLM. Then, after completing this embedding, in the case of Llama, it actually uses the same CLIP and VIT encoders mentioned earlier. There is a small projection layer that maps the dimensions of the CLIP embedding to the dimensions of the Llama embedding, and they also fine-tune the Llama model to better understand these combined embeddings. We found that using a larger CLIP model with a resolution of 336*336 instead of 224*224 allows it to extract smaller details and even re-extract text from images. There are many other image embedding methods, such as ImageBind, which combines more information than just images and text, capable of handling audio, inertial measurement units, point clouds, and various modalities. Essentially, we are enabling LLMs to have all different perceptual modalities, allowing them to comprehensively understand the worldview and perception of the world, not just through text.
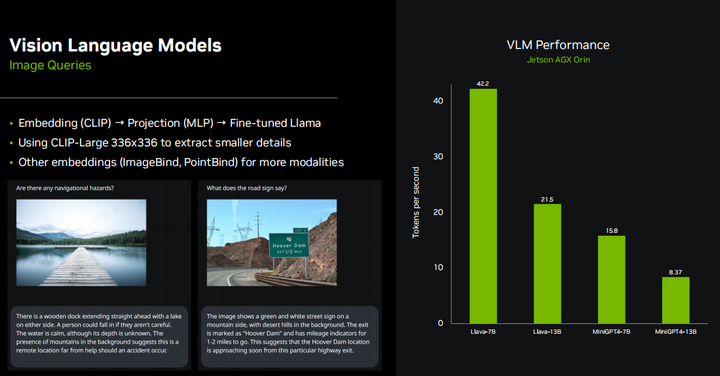
So you can see that the performance of the Llama model is very similar to that of the base Llama model. In fact, it has the same model architecture, just slightly slower.
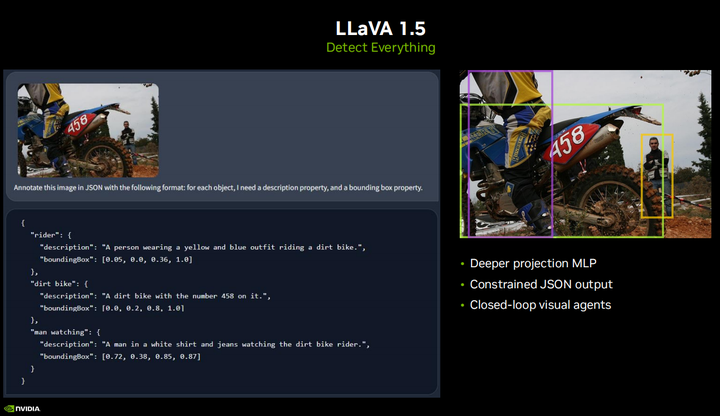
The recently released LLaVA1.5 model may have been seen by some, featuring some very exciting new capabilities, including the ability to output in a restricted JSON format. So you can basically tell it to detect certain objects and give it to me in JSON format, allowing you to parse it programmatically and actually operate on it. For VIT, you need to prompt with specific things, like I want to detect a face or a hand. In this example, you can directly tell it to detect everything, and it will output bounding boxes for all objects or anything you are trying to do. This is very useful for creating closed-loop visualizations deployed in real-time embedded systems, such as smart traffic intersections, sidewalk monitors, blind assistant devices, or baby crib monitors, or any open-ended questions from which you want to extract information without having to train your own model. In addition to functionalities like autonomous navigation, you can also query it, like where does this path go? Are there obstacles in my way? Are these obstacles dynamic? Various questions like this are really exciting. Another point to note is that the entire LLaVA1.5 model is a significant improvement over its previous versions, but it was still trained for just one day on an A100 GPU, so if you collect your own dataset, you could actually fine-tune one for your application.
Take a look at some example code supporting these demonstrations, basically a lightweight wrapper I placed around MLC and AWQ, as these are not supported in some other LLM libraries. Besides all the multimodal embedding management and such, we will talk about it, it also has a very simple text generation API. Basically, you load the model, and if it hasn’t been done yet, it will quantize for you. You create this chat history stack, and you can append text prompts or images. It will automatically perform embeddings for you based on the type of input data, and then generate a series of output tokens. So everything we are doing here is for real-time stream processing, allowing you to present data to users as quickly as possible. Then you basically just output the robot’s response to the chat. Now, if you want to manage the chat dialogue yourself, you can absolutely do that. You can pass a text string to the model generation function. What you should realize is that when you maintain a coherent stack, the chat history works best because you don’t have to go back and regenerate every token in the chat. For example, we know that the maximum token length for the Llama2 model is 4096, but if you generate the full 4096-length chat each time, it will take a long time. Instead, you can keep the cache in what is called KV cache, and if you do this between requests, the entire state of the chat will be maintained. You can run multiple chats simultaneously, but it is highly recommended to keep the chat stack flowing rather than moving back and forth and integrating everything from scratch each time.
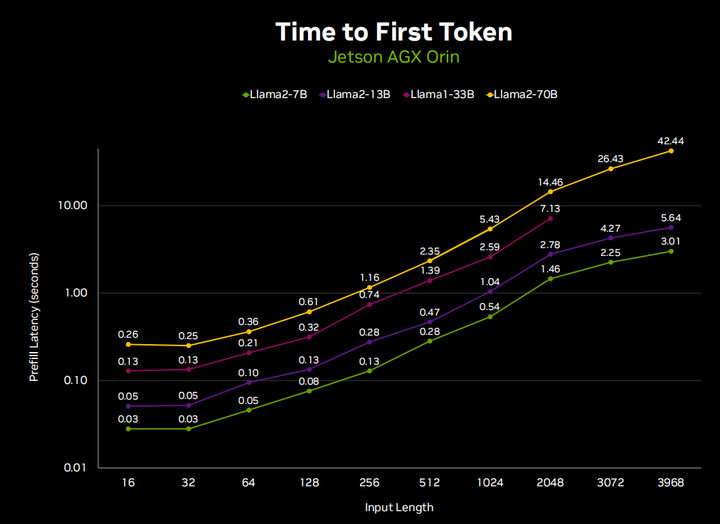
This is because LLM text generation has two phases. The first is decoding, also known as pre-filling, which takes your input context and basically performs a forward pass on each token in it. This phase is much faster than the generation phase, but when you are dealing with a full 4096 tokens, the time will still add up. So you can see that if we run llama-70B in a full 4096 token length chat, it will take 40 seconds to pre-fill the entire chat before it starts responding. But if you just pre-fill the latest input, you will find that, you know, a small portion of time, usually the ellipsis that appears in the chat, or a prompt like “agent is typing.” It is actually pre-filling your input before it can start generating. This is why managing the KV cache between requests is actually very important to maintain a very consistent chat flow.
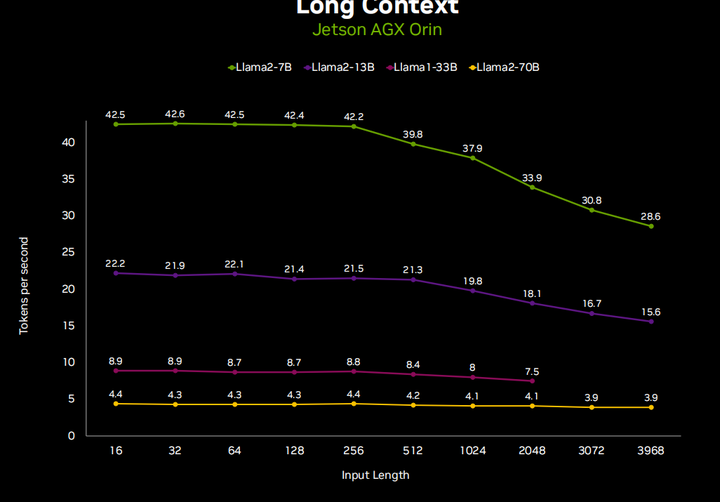
So clearly, one important concern among all this is memory utilization demands, and along with token generation speed, this really makes everyone very inclined towards quantization methods. So many of the LM APIs we talked about, like llama c++ and other autoGPTQ XLIama, have many different quantization methods. You can choose from two bits to eight bits, but most of the time, it is below four bits. You start to see performance degradation, but in AQ4A16 quantization, I really did not see any difference in output, which is really good because it reduces the memory usage of llama-70b from 130GB to 32GB, making it easier to deploy on smaller devices like Jetson. You can run Llama2–7b on an 8GB board or Llama2-13b on a 16GB board.
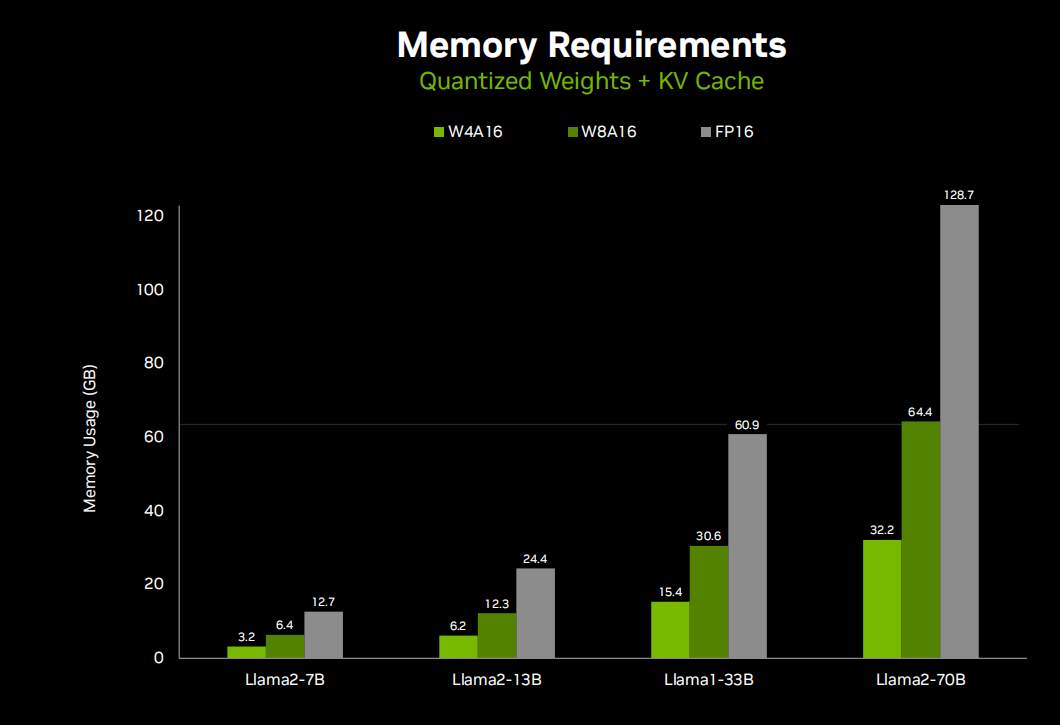
We can see here a whole set of different Jetson modules, each of which you can deploy, and each module has a typical model size that fits its memory capacity. So you can basically mix and match based on the level of intelligence your application needs, as well as performance and other trade-offs like size, weight, power consumption, and cost of embedded systems, and choose the Jetson module that fits your deployment.

So in a few slides back, I showed some basic code for using LLM for text generation with low-level APIs. Once you start getting more complex, adding features like ASR, TTS, and retrieval-augmented generation, all these plugins become very complex, and if you are just making a custom application, you can absolutely write all this code yourself, like with a Python application. In fact, the first version of the Llama speak demonstration was like that, but eventually, when you start iterating and creating different versions, like I want a multimodal version, or I want to make a closed-loop visual agent, you will have a lot of boilerplate code in there. So I wrote a slightly more advanced API function based on text generation, where you can implement all these different plugins, it is very lightweight, has very low latency, and is designed not to make it harder for you but easier, without sacrificing a second of generation speed. With this API, you can easily link all these different text and image processing methods together and use them with other APIs. This is just two basic examples of what a pipeline definition looks like; it can be a fully directed open multi-input, multi-output graph where some quite complex setups can be made.
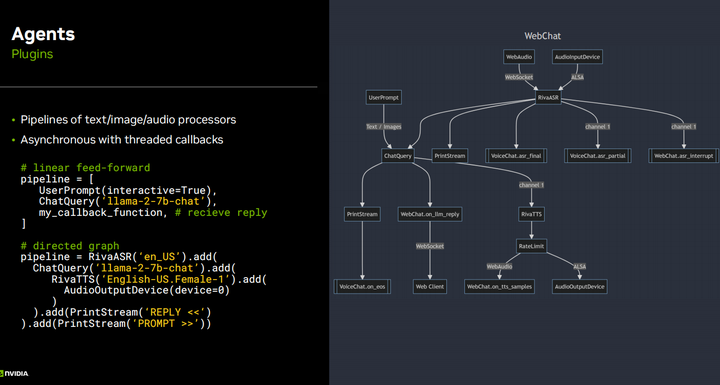
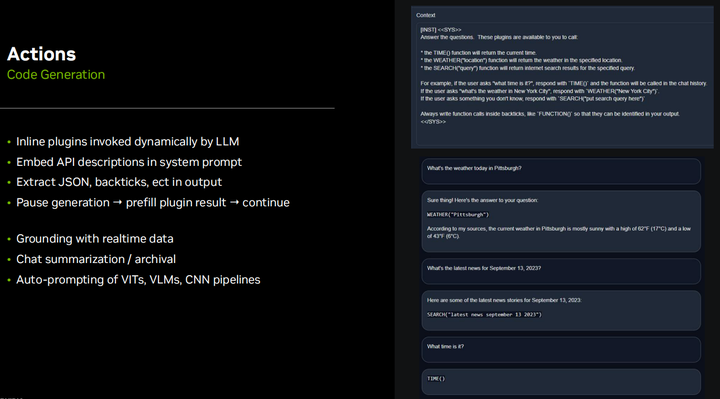
Another cool aspect is that this approach allows for inline plugins, or in other words, enables the LLM to dynamically change. How does it know what time it is now, or perform an internet search query, or know what the weather is like, or perform actions like turning left or right? All these core platform functionalities can be defined in the system prompt and explained to the LLM API. It can execute dynamically when needed. This is based on retrieval-augmented generation, which we will discuss shortly, as it not only retrieves based on the user’s previous input but can also perform retrieval while generating output and insert it into the ongoing output. This is a great benefit, you know, maintaining a lower-level access to the API rather than going back to the cloud for everything, because you need to be able to stop token generation, run plugins, and insert them into the output, and then continue the output. Besides performing operations like token fixing or implementing safeguards and steering functionalities, all this granular level of access to token generation is very nice, so you can stop it when needed and then completely asynchronously restart it to prevent breaking all low-latency pipelines. This is just a basic example when I tried to see if it could generate; this is just using llama two seven b and leveraging its built-in collaborative generation functionality, which is basic for it. I recommend using JSON format, even though it is more verbose and generates more tokens, especially if the function has multiple parameters, because JSON allows you to maintain the order of parameters, so they do not get confused. If you do not have many parameters or if it is just very simple like the example shown here, you can simply write a simple Python script or use other open-source frameworks like Lang chain and hugging face agents and Microsoft Jarvis, which can also do similar things. They may not be as suitable for low-latency and low-overhead, which is why I went this route, but at the same time, they can do similar things. In fact, the hugging face agents API directly has the Python code for L M generate and runs it in a restricted sandbox interpreter. So it can directly interact with the Python API, which is really cool, and in this case, it is not hard to do. You know, I prefer to keep it in JSON or text and manually parse it and call plugins, so it does not have full access to Python.
I have mentioned retrieval-augmented generation several times, which is very important in enterprise applications where you want to index a large number of documents or PDFs and be able to query them with LLMs. Keep in mind that the context length is a maximum of 4096 tokens, although there are many rotating embedding encodings that can reach 16k or 32k or even more, there are always limitations, and you may have hundreds of thousands of pages of documents to query. When we start talking about multimodal, you may have large databases of thousands or millions of images and videos that you want to index, but it is impossible to include them all in the context. So basically, you search the user’s input query and query in your vector database. The technology used for this is very similar to LLM and VIT encoding. In fact, Clip embeddings are used in the demonstration I will show you next. But it basically uses similarity search to determine which objects in the database are closest to your query, which is a very similar concept in multimodal embedding space. There are some very fast libraries, like FAISS and RAPIDS RAP, that can index billions of records and quickly retrieve them based on your query. These are excellent libraries, and I use them on Jetson for multimodal image operations.

For searching vector databases, I basically made this demonstration to validate the capabilities of the Clip transformer encoder and just to be able to understand what I can actually query before integrating it into the language model for retrieval and augmented generation. So you can see here that you can not only clear with text but also perform image searches. And this is quite advanced image searching, completely real-time. Here, I am using Jetson for real-time refresh, indexed on the MS Coco dataset, which contains about 275,000 images, and the whole process took me about five to six hours. But the actual retrieval search only takes about ten to twenty milliseconds, which means it does not add latency to your language model generation process, which is very important because we do not want more than a few seconds of delay between user queries and responses, especially in voice interactions.
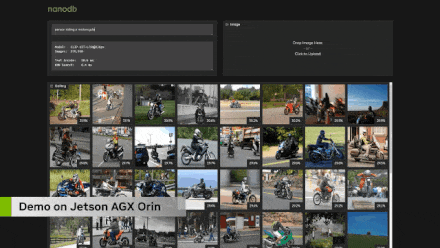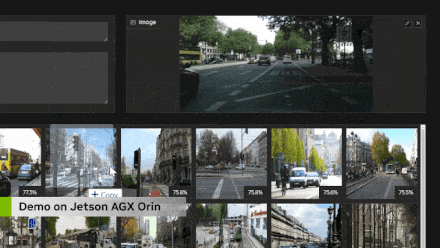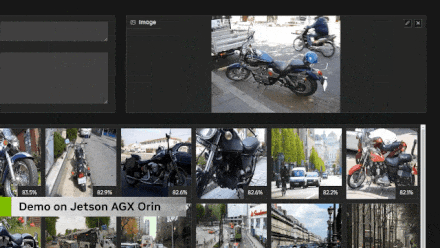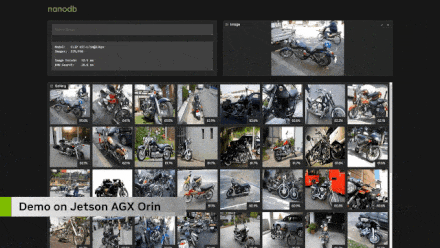
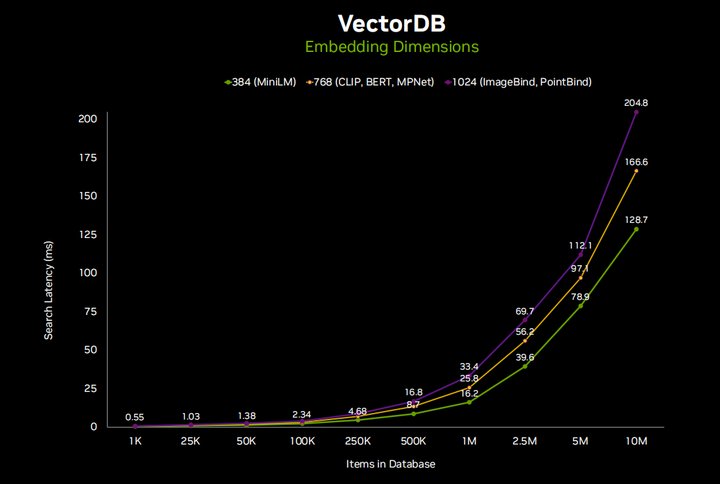
In retrieval and augmented generation searches, it depends on how many items you have in your database; some databases can become very large, especially in cases of enterprise documents. On edge devices, I think the scale will be smaller because of limited available space on the device. You can see here that for most people’s applications, this only takes a few milliseconds, and I have also listed different embedding dimensions separately. So some high-end embeddings, like ImageBind, use each image or text as a vector containing 1024 elements, describing it in Clip’s multi-dimensional embedding space. Clip Large uses 768 elements. That is what is demonstrated here. So this is good in scale. I think it is rare to reach 10 million records on embedded devices, but if you know you are doing a lot of data aggregation, with 30 HD camera streams being transmitted, that is entirely possible. And still, it only takes about a fifth of a second or less to complete all of this, which is entirely reasonable.
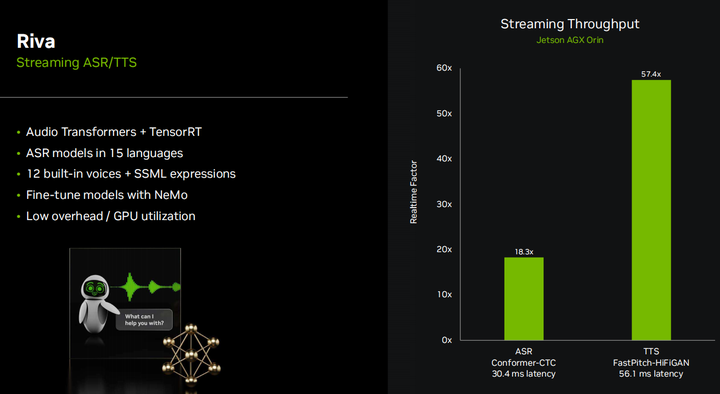
So coordinating with Riva to demonstrate how I made these text-to-speech demonstrations. Riva is an excellent open SDK provided by NVIDIA that integrates our state-of-the-art audio transformers trained with TensorRT acceleration. And it is fully streaming. It supports streaming speech recognition (ASR) and text-to-speech (TTS), allowing you to perform 18 ASR streams or 57 TTS streams in real-time on Jetson AGX Orin, but very few people will do that many streams on edge devices unless you have multi-microphone devices or something set up like that. But this means that when you are only doing one stream, you will only use less than 10% of the GPU, which is very good because it means our LLM token generation rate will only drop by less than 10% since the LLM will fully occupy the GPU.
Riva has many different ASR and TTS models, and it also supports neural machine translation. I have seen some people do some cool demonstrations with it, allowing real-time translation between different languages, showing that many LLMs (like Llama) are trained in English. While there are also some multilingual LLMs, if you are using an LLM trained in English but want to communicate in other languages, you can use neural machine translation in the pipeline to translate between the LLM and TTS.
Riva also has a cool feature for TTS SSML expressions, allowing you to speed up or slow down, change pitch, add emojis, laughter, or various fun elements to make the voice sound more realistic. Overall, it performs very well on local devices. So far, all the demonstrations I have shown you do not rely on any cloud computing or off-board computing. Once you download the containers or build the applications, you can run these demonstrations completely offline.
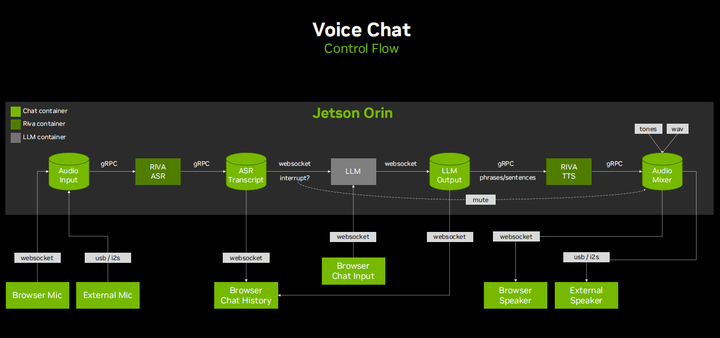
Here is basically the pipeline block diagram for interactive verbal chat management. It turns out that there are many subtleties in real-time chat, mainly the ability to interrupt the LLM’s verbose behavior. We understand these elements; they like to talk, and they will keep going on, and you can instruct them to be very concise in their output. But overall, they tend to ramble a bit, and it is important to be able to speak over them in a video and have the language model either continue when you do not want to query it or stop when you ask another question. I found that the best way to achieve this is to use a multi-threaded asynchronous model, where there is a bunch of queues, and everything goes into these queues and gets processed. You need to have the ability to interrupt and clear these queues based on what is happening. For example, the stream automatic speech recognition (ASR) outputs something called partial transcriptions. When you speak, these appear as little bubbles in the video because it is constantly redefining and forming what you think it is, but when you reach the end of a sentence, it performs what is called a final transcription. This final transcription is what is actually submitted to the language model, but if partial transcriptions start appearing and you have spoken more than a few words, it will pause the language model. If no more transcriptions are obtained within a second or two, the language model can continue speaking. If the final transcription does indeed become final, then you know the previous language model response has been canceled and replaced with a new response, which is important because then you do not want it to continue taking time generating the old response when you are already answering the next question.
Conclusion
So it turns out there are many subtleties here, and we try to implement it with as few heuristics as possible because that only leads to special cases, and overall, interacting with these models is very pleasant and fun. I really encourage you to get into the Jetson AI Lab (https://www.jetson-ai-lab.com/), download these containers, start experimenting with different models, discover their personalities, and build your own applications. I believe we will see them in real-world embedded systems and robotics in the near future, so let’s do it together.
Q&A about this workshop
1. Is this using RIVA ASR and STT?
Answer: Yes, it is running locally. It actually sounds better/clearer.
2. In the fruit and price demonstration, how does the model understand the content in the image?
Answer: It is trained on trillions of tokens from the internet, leveraging the power of Llama LLM and CLIP visual encoders.
3. Are there plans to create an updated version of Jetson for more unified memory and a more powerful APU? I want a more powerful inference machine.
Answer: The NVIDIA Jetson AGX Orin 64GB development kit offers 64GB of unified memory. While there are currently no official announcements regarding more memory for the Jetson platform, NVIDIA continues to assess the demand for increased memory capacity to support rapidly evolving AI models.
4. You often mention Orin, how is compatibility with older Jetson models like Jetson Xavier? What are the important considerations when using Xavier instead of Orin?
Answer: Many applications and containers should run on the Xavier generation of Jetson as long as memory requirements are met.
More:
Jetson Voice: Smart voice processing is everywhere from Jetson Nano to AGX Xavier