Information security public service announcement, information security knowledge enlightenment.
Add WeChat group and reply to the public account: WeChat Group; QQ group: 16004488
You can request for free: Learning Tutorial
Writing a computer virus is not just about destruction; it also depends on how widely your virus can spread while avoiding detection, and it must be smarter than antivirus software companies. This is about innovation and creativity.
A computer virus is, in many ways, like a paper airplane. You need to fold the plane in a clever and creative way and try to make it fly as long as possible before it inevitably lands.
Before the World Wide Web, spreading viruses was a challenge. If you were lucky, it would infect any computer other than your own. If you were even luckier, your virus would gain fame like the Whale virus or the Michelangelo virus.
If you want to be regarded as a “virus author,” you must earn that title. Among underground hacker organizations, the virus authors are the ones I respect the most among hackers/crackers/intruders. Because not everyone can do it; it truly demonstrates a deeper knowledge of systems and software than others.
You cannot expect to become a virus author simply by following the conventional path.
Writing a real virus requires more skills than an average “hacker.” Over the years, I have not successfully written a well-functioning binary file infecting virus. It has always been errors, errors, errors. This is a frustrating thing.
Therefore, I persist in writing worms, trojan bombs, and ANSI bombs. I stick to writing exploits for BBS and reverse-engineering video game software to crack its copyright protection.
Whenever I thought my assembly skills were finally enough to try to write a virus, failure hit me in the face again. It took me several years to write a truly executable virus. That’s why I am obsessed with viruses and want to find out some real virus authors.
In Ryan “elfmaster” O’Neill’s legendary book “Learning Linux Binary Analysis,” he points out:
This is a great challenging project that goes beyond conventional programming conventions, requiring developers to break out of traditional patterns to manipulate code, data, and environment to behave in a certain way. During my exchanges with AV antivirus software developers, I was surprised that none of them had any real ideas about how to reverse-engineer a virus, let alone design any real heuristics to identify them (other than signatures). In fact, writing viruses is very difficult and requires comparatively strict skills.
1. Writing a Virus in Assembly Language
Viruses are an art. Assembly and C (without using code libraries) will be your brushes. Today, I will help you navigate through some challenges I faced. Let’s get started and see if you have the potential to become an artist!
Unlike my previous “source code infection” virus tutorial, this is a more advanced and challenging experience/application (even for experienced developers). However, I encourage you to keep reading and absorb as much as you can.
Let’s first describe what I think a true virus should have as characteristics:
—— A virus infects binary executable files
—— Virus code must be independent, independent of other files, code libraries, programs, etc.
—— The infected host file can continue to execute and spread the virus
—— The virus behaves like a parasite without harming the host file. The infected host should continue to execute as it did before infection
Since we are going to infect binary executable files, here’s a brief list of several different types of executable files.
ELF– (Executable and Linkable Format) The standard binary file format for Unix and Unix-like systems. This is also used by many mobile phones, game consoles (PlayStation, Nintendo), etc.
Mach-O– (Mach Object) The binary executable file format used by NeXTSTEP, macOS, iOS, etc. You are actually using it because all Apple phones use this.
PE– (Portable Executable) Used for 32-bit and 64-bit Microsoft operating systems
MZ– (DOS) The executable file format supported by DOS… all Microsoft 32-bit and below operating systems use it
COM– (DOS) The executable file format supported by DOS… all Microsoft 32-bit and below operating systems use it
There are many virus tutorials for Microsoft, but ELF viruses seem more challenging and tutorials are scarce, so I will mainly focus on infecting 32-bit ELF programs.
I will assume that the reader has at least a general understanding of how viruses replicate. If not, I recommend you read my previous blog post topics:
https://cranklin.wordpress.com/2011/04/19/how-to-write-a-stupid-simple-computer-virus-in-3-lines-of-code/
https://cranklin.wordpress.com/2011/11/29/how-to-create-a-computer-virus/
https://cranklin.wordpress.com/2012/05/10/how-to-make-a-simple-computer-virus-with-python/
The first step is to find the file to infect. The DOS instruction set can conveniently find files. The AH:4Eh INT 21 instruction can find the first matching file based on a given file description, while the AH:4Fh INT 21 instruction can find the next matching file.
Unfortunately, it won’t be that simple for us. Using Linux assembly to retrieve the file list, there isn’t much relevant documentation. Among the few answers, we find it relies on the POSIX system’s readdir() function. But we are hackers, right? Let’s do what hackers should do to achieve it.
A tool you should be familiar with is strace. By running strace ls, we see the system calls and signals traced when the ls command is run.
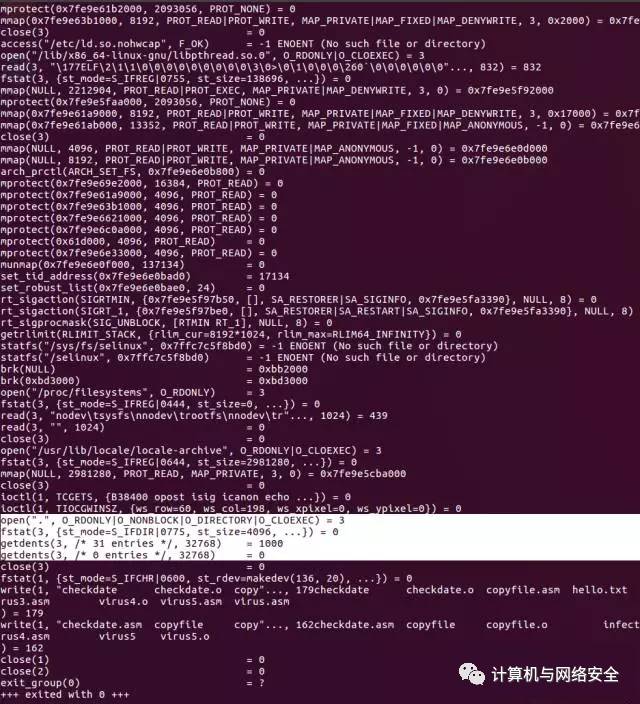
The call you are interested in is getdents. So the next step is to look up “getdents” at http://syscalls.kernelgrok.com/. This will give us a little hint about how we should use it and how we can get a directory listing. Here’s what I found:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
Now, the contents of the directory are already in our specified buffer, and we must parse it. For some reason, the offsets for each filename do not seem consistent, but it could also be my mistake. However, I am only interested in those raw filename strings. What I did was print the buffer to standard output and then save it to another file, and open it with a hex editor.
I found that each filename has a prefix, which consists of the hexadecimal value 0x00 (null) followed by the hexadecimal 0x08. The filename is null-terminated (ending with a hexadecimal 0x00).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
|
Actually, there’s a better way to do these things. All you need to do is match the bytes of the directory entry structure:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
But I am using a pattern I found that does not use the offsets in the structure.
The next step is to check the file to see if:
—— It is an ELF executable file
—— It is not already infected
Earlier, I introduced some different types of executable files used by different operating systems. These file types have different markers in their headers. For example, ELF files always start with 7f45 4c46. 45-4c-46 is the hexadecimal representation of the ASCII letters E-L-F.
If you dump the hexadecimal data of a Windows executable file, you will see it starts with 4D5A, representing the letter M-Z.
Hexadecimal dumps of OSX executable files show the marked bytes CEFA EDFE, which is the little-endian “FEED FACE”.
You can see more about executable file formats and their respective markers here:
https://en.wikipedia.org/wiki/List_of_file_signatures
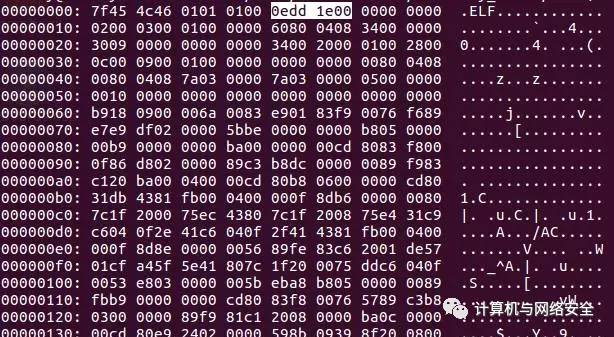
In my virus, I want to write my own marker in the unused space of the ELF file header at bytes 9 – 12. This is a nice spot to store a double word “0edd1e00″—my name.
I need this to mark the files I have infected so that I do not infect already infected files again. Otherwise, the length of infected files will snowball, and the Jerusalem virus was first detected because of this.
By simply reading the first 12 bytes, we can determine whether the file is a good candidate for infection and then move on to the next target. I plan to store each potential target in a separate buffer called “target”.
Now it’s starting to get difficult. To infect ELF files, you need to know everything about the ELF file structure. Here’s a good starting point for learning:
http://www.skyfree.org/linux/references/ELF_Format.pdf
Unlike simple COM files, ELF presents some different challenges. Simply put, ELF files include: ELF header, program header, section header, and instruction opcodes.
The ELF header tells us about the program header and section header. It also tells us the entry point location of the program in memory (the first instruction opcode to be executed).
The program header tells us which “segment” belongs to the TEXT segment, which “segment” belongs to the DATA segment, and gives offsets in the file.
The section header provides information about each “section” and their belonging “segments”. This can be a bit confusing. The first thing to understand is that an executable file is in a different state on disk than it is when running in memory, and these headers provide relevant information about both states.
The TEXT segment is the readable/executable code segment that contains our code and other read-only data.
The DATA segment is the readable/writable data segment that contains global variables and dynamic linking information.
In the TEXT segment, there is a .text section and a .rodata section. In the DATA segment, there is a .data section and a .bss section.
If you are familiar with assembly language, these section names should sound familiar to you.
.text is where the code resides, .data is where initialized global variables are stored. .bss contains uninitialized global variables, and since it is uninitialized, it does not occupy disk space.
Unlike PE files (Microsoft’s), ELF files do not have many areas that can be infected. Old DOS, COM files almost allow you to add virus code anywhere and overwrite memory code at address 100h (because COM files always start mapping at memory address 100h). ELF files do not allow you to write to the TEXT segment.
The following are the main methods for ELF infecting viruses:
2. Infect the Text Segment Padding Area
Infect the tail of the .text section. We can take advantage of the ELF file’s characteristics that when loaded into memory, the tail will be padded with ‘0’ to fill a complete memory page. Due to the memory page length limitation, we can only accommodate a 4 kb virus on a 32-bit system or a 2 mb virus on a 64-bit system. This may seem small, but it is enough to accommodate a small virus written in C or assembly language.
The implementation method for this goal is:
—— Modify the entry point (ELF header) to the tail of the .text section
—— Increase the page length of the corresponding section in the section table (ELF header)
—— Increase the file length and memory length of the TEXT segment by the length of the virus code
—— Traverse each program header that has been parasitized by the virus and increase the corresponding offset according to the page length
—— Find the last section header of the TEXT segment and increase its section length (in the section header)
—— Traverse each section header that has been infected by the virus and increase the corresponding offset according to the page length
—— Insert the actual virus code at the end of the .text section
—— After inserting the virus code, jump to the original host’s entry point to execute
3. Reverse Infect the Text Segment
Infect the front part of the .text section while allowing the host code to maintain the same virtual address. We will reverse extend the text segment. In modern Linux systems, the minimum virtual mapping address allowed is 0x1000, which is the limit length for us to reverse extend the text segment.
On a 64-bit system, the default virtual address of the text segment is usually 0x400000, which could leave the virus with a space of 0x3ff000 after subtracting the length of the ELF header. On a 32-bit system, the default virtual address of the text segment is usually 0x0804800, which could create a larger virus.
The implementation method for this goal is:
—— Increase the offset in the section table (in the ELF header) by the length of the virus (taking the next memory page alignment value modulo)
—— In the TEXT segment program header, decrease the virtual address (and physical address) according to the length of the virus (taking the next memory page alignment value modulo)
—— In the TEXT segment program header, increase the file length and memory length according to the length of the virus (taking the next memory page alignment value modulo)
—— According to the length of the virus (again taking modulo), traverse the offset of each program header and increase its value to greater than the text segment
—— Modify the entry point (in the ELF header) to the original text segment virtual address – the length of the virus (again taking modulo)
—— According to the length of the virus (again taking modulo), increase the program header offset (in the ELF header)
—— Insert the virus entity at the starting position of the text segment
For learning tutorials on assembly language, please reply to the public account: Assembly
▼ Click Read the Original to see more wonderful articles.