Introduction
Recently, I prepared to implement a virtual serial port driver in Linux; however, since graduation, I have been engaged in bare-metal driver development, and thus I have gradually forgotten about device drivers in Linux. To achieve this functionality, I have searched for a lot of information online, but most of it only explains the theory or directly posts the code. For those who have not been exposed to Linux drivers or beginners, it can be quite challenging to understand. Therefore, I plan to share my thoughts, combining the materials I have organized over the past few days and my understanding, along with relevant code, hoping to contribute a little to those in need.
Bare-Metal and Device Drivers
The distinction between bare-metal drivers and device drivers has been mentioned earlier, so let me briefly explain the difference. Device drivers, as the name implies, are meant to “drive the device to act.” Here, bare-metal drivers should also fall under the category of device drivers, but due to the author’s habit, I refer to drivers without an operating system as bare-metal drivers, hence the distinction. In the absence of an operating system, we can define interfaces based on the characteristics of the hardware devices, such as defining Drv_SerialSend() and Drv_SerialRecv() for the serial port, and Drv_TimeSet() and Drv_TimeGet() for the RTC (Real-Time Clock). However, when there is an operating system, the architecture of the driver should be defined by the operating system, and we must design the driver according to the corresponding architecture so that the driver can be better integrated into the operating system kernel.
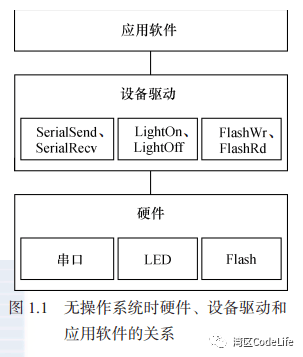
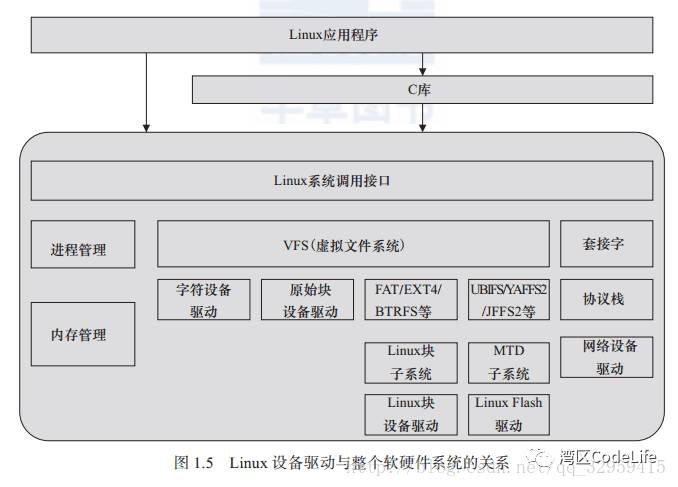
From the images, we can see that having an operating system not only does not simplify the driver but actually complicates it further. Why can’t we, like in bare-metal drivers, directly call the function interface needed for any operation? For example, when writing data to Flash, we can directly call Drv_FlashWrite(), and when sending data to the serial port, we can directly call Drv_SerialSend(). Wouldn’t that be more direct and simpler? It sounds quite reasonable; compared to accessing the driver interface indirectly through system call interfaces and the file system, directly calling driver functions seems more efficient. However, existence itself is reasonable, and the designers of such a driver architecture must have their reasons. Let’s first look at a diagram. 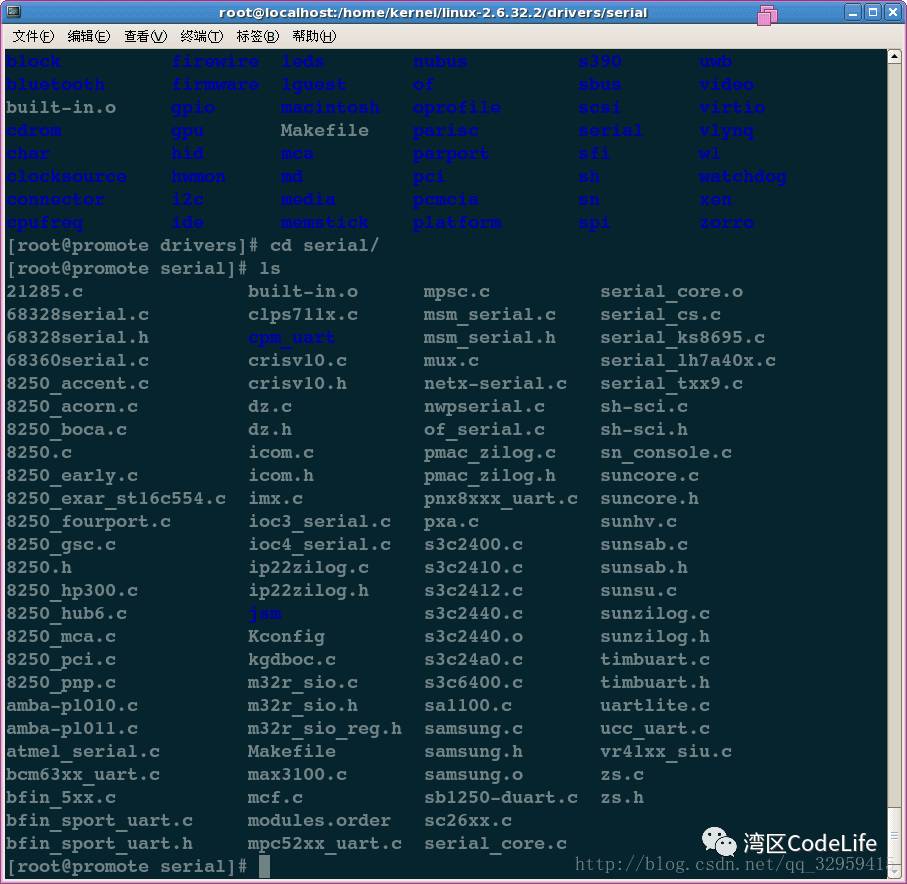 We can see that in the drivers/serial directory, the serial devices supported by the Linux 2.6 kernel are listed. Just the S3C series from Samsung has several types, and the reason for this distinction is certainly due to Samsung’s modifications in the processor design structure, the architecture of the serial devices, the driver circuit, access methods, etc. Imagine if Samsung differentiated these devices in the naming of drivers, naming the corresponding driver interfaces according to processor types, such as Drv_S3c2440SerialSend(), Drv_S3c2410SerialSend(), Drv_S3c6410SerialSend(); at this point, an application engineer on the S2C2440 processor writes a serial port application in a way that directly accesses the driver interface. One day, due to business needs, it is required to implement the same functionality on the S3C6410 processor. Initially, it seems like a simple porting task, but later it is discovered that all the underlying driver function names have changed, requiring the engineer to change all instances of Drv_S3c2440SerialSend() to Drv_S3c6410SerialSend(), and all related initialization, sending, receiving, etc., must be modified. This would be a very headache-inducing task. Another example is if our device is equipped with multiple different Flash storage devices; in this case, a simple Drv_FlashWrite() is clearly not enough. Different Flash storage devices have different operating methods, and to use these storage devices correctly, the underlying driver must distinguish and provide different function interfaces, and the upper application must understand these different driver interfaces to know which type of Flash storage device is being operated on. In contrast, when there is an operating system, in Linux, the upper application only needs to access any device through the read() and write() functions. Even if there are different processors or devices, as long as the parameters passed in (file name/device name) are correct, access to different devices can be completed. The upper application engineer does not need to consider what the underlying driver interfaces look like; their impression is that no matter how many different types of Flash storage devices are equipped, a single read() function can access all storage devices. Moreover, even if the processor is changed, the serial port application program implemented on the S2C2440 processor can also be directly used on the S3C6410 processor because the operating system and file system provide a unified interface to the upper layer, so the upper application does not need to care about what modifications have been made in the underlying layer. In fact, the operating system creates complexity for device drivers to provide convenience for upper-layer applications. Drivers are designed according to the driver framework and unified interface provided by the operating system, allowing upper-layer applications to access drivers through the unified system calls provided by the operating system. Anyone familiar with Linux knows that in Linux, everything is a file. We can access any device through the read() and write() functions, which provides great convenience for upper-layer applications.
We can see that in the drivers/serial directory, the serial devices supported by the Linux 2.6 kernel are listed. Just the S3C series from Samsung has several types, and the reason for this distinction is certainly due to Samsung’s modifications in the processor design structure, the architecture of the serial devices, the driver circuit, access methods, etc. Imagine if Samsung differentiated these devices in the naming of drivers, naming the corresponding driver interfaces according to processor types, such as Drv_S3c2440SerialSend(), Drv_S3c2410SerialSend(), Drv_S3c6410SerialSend(); at this point, an application engineer on the S2C2440 processor writes a serial port application in a way that directly accesses the driver interface. One day, due to business needs, it is required to implement the same functionality on the S3C6410 processor. Initially, it seems like a simple porting task, but later it is discovered that all the underlying driver function names have changed, requiring the engineer to change all instances of Drv_S3c2440SerialSend() to Drv_S3c6410SerialSend(), and all related initialization, sending, receiving, etc., must be modified. This would be a very headache-inducing task. Another example is if our device is equipped with multiple different Flash storage devices; in this case, a simple Drv_FlashWrite() is clearly not enough. Different Flash storage devices have different operating methods, and to use these storage devices correctly, the underlying driver must distinguish and provide different function interfaces, and the upper application must understand these different driver interfaces to know which type of Flash storage device is being operated on. In contrast, when there is an operating system, in Linux, the upper application only needs to access any device through the read() and write() functions. Even if there are different processors or devices, as long as the parameters passed in (file name/device name) are correct, access to different devices can be completed. The upper application engineer does not need to consider what the underlying driver interfaces look like; their impression is that no matter how many different types of Flash storage devices are equipped, a single read() function can access all storage devices. Moreover, even if the processor is changed, the serial port application program implemented on the S2C2440 processor can also be directly used on the S3C6410 processor because the operating system and file system provide a unified interface to the upper layer, so the upper application does not need to care about what modifications have been made in the underlying layer. In fact, the operating system creates complexity for device drivers to provide convenience for upper-layer applications. Drivers are designed according to the driver framework and unified interface provided by the operating system, allowing upper-layer applications to access drivers through the unified system calls provided by the operating system. Anyone familiar with Linux knows that in Linux, everything is a file. We can access any device through the read() and write() functions, which provides great convenience for upper-layer applications.
Driver Architecture in Linux
As mentioned earlier, when there is an operating system, drivers should be designed according to the driver architecture provided by the operating system. So what should the driver architecture in Linux look like? First, in conjunction with what we discussed earlier, the upper user space in Linux can access devices in the form of files; we should have such questions: why can we access devices when accessing files? How are files and devices bound together? The upper application calls the same read() and write() functions; how does the operating system know which driver’s read and write functions are specifically being called? I will explain these questions one by one later. In Linux, devices can be divided into three categories: character devices, block devices, and network devices. Character Devices: A type of device that can be accessed serially like a byte stream, where access to the device can only be done sequentially by byte, and random access is not allowed; character devices do not have a request buffer, so all access requests must be executed sequentially. For example, a keyboard cannot respond to the next input before the current input is complete. Block Devices: These have request buffers and can read any length from any location, allowing for random access. For example, hard disks allow random access to any sector and any length. Network Devices: Network devices are oriented toward data packets, while character devices are oriented toward character streams. Network devices, like character devices, do not support random access and have no buffers. Switches, routers, etc., are all network devices that process data in the form of packets. The three types of devices have slightly different driver architectures, and here we will take character devices as an example to describe the driver architecture in Linux. 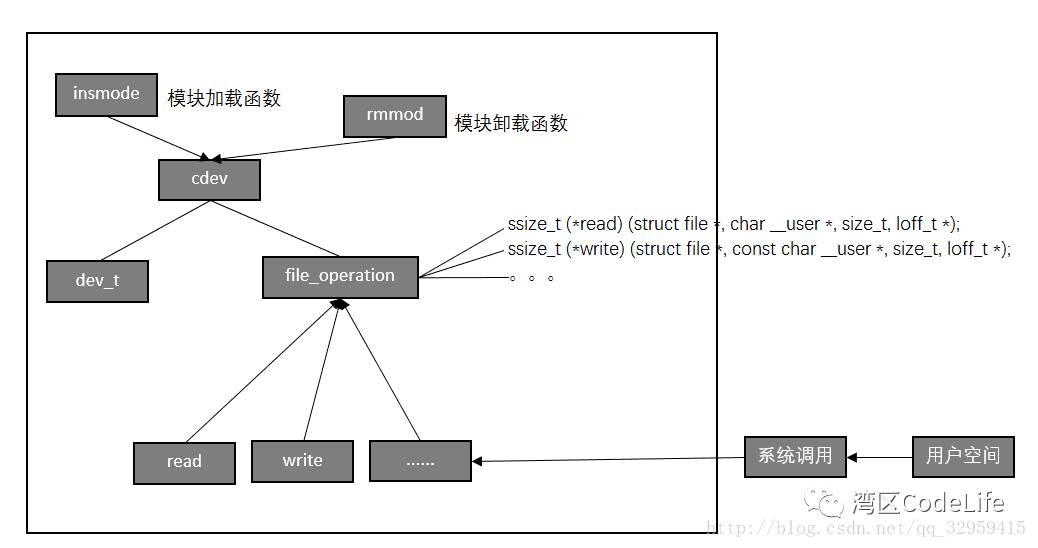 In the diagram, ssize_t (read) (struct file , char __user , size_t, loff_t ); ssize_t (write) (struct file , const char __user , size_t, loff_t ) and other functions are similar to the previously mentioned Drv_FlashRead(), Drv_FlashWrite() functions. The Linux kernel uniformly “maps” these functions into the file_operation structure, allowing the upper layer to use unified system calls such as read() and write() through the operating system and file system. Therefore, when there is an operating system, the underlying driver still needs to implement functions like Drv_FlashRead() and Drv_FlashWrite(), but with additional operations.
In the diagram, ssize_t (read) (struct file , char __user , size_t, loff_t ); ssize_t (write) (struct file , const char __user , size_t, loff_t ) and other functions are similar to the previously mentioned Drv_FlashRead(), Drv_FlashWrite() functions. The Linux kernel uniformly “maps” these functions into the file_operation structure, allowing the upper layer to use unified system calls such as read() and write() through the operating system and file system. Therefore, when there is an operating system, the underlying driver still needs to implement functions like Drv_FlashRead() and Drv_FlashWrite(), but with additional operations.
struct cdev
{
struct kobject kobj; /* embedded kobject object */
struct module *owner; /* belonging module */
const struct file_operations *ops; /* file operations structure */
struct list_head list; /* kernel list */
dev_t dev; /* device number */
unsigned int count;
};In the Linux 2.6 kernel, a structure like cdev is used to manage character devices. Here, I will briefly explain the members dev_t dev and const struct file_operations *ops; the others will be explained later. 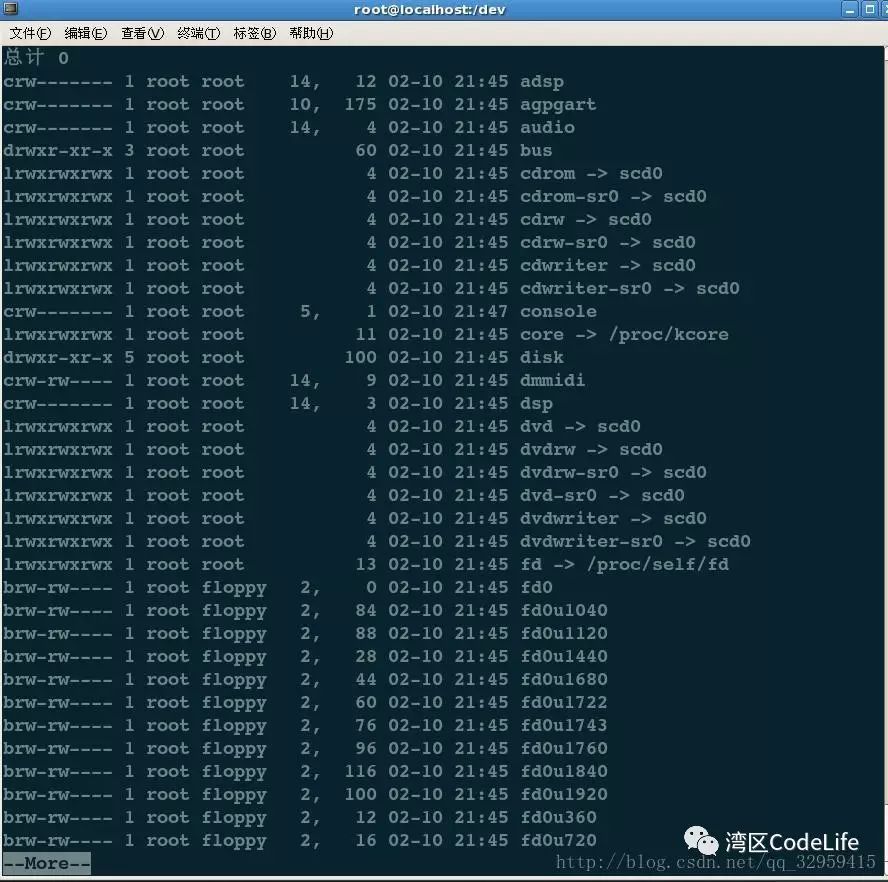 From the image, we can see that there are two columns of numbers before the time information; the left column represents the major device number, and the right column represents the minor device number. Upon closer examination of this image, we find that the minor device number for “scd0” is 4, while the major device number for “fd0u……” is the same, but the minor device numbers differ. Thus, a simple explanation can be made: the Linux kernel uses the major device number to determine the driver for a certain type of device, while the minor device number identifies the specific device; or in other words, the major device number identifies a specific driver program, while the minor device number represents the various devices using that driver program.
From the image, we can see that there are two columns of numbers before the time information; the left column represents the major device number, and the right column represents the minor device number. Upon closer examination of this image, we find that the minor device number for “scd0” is 4, while the major device number for “fd0u……” is the same, but the minor device numbers differ. Thus, a simple explanation can be made: the Linux kernel uses the major device number to determine the driver for a certain type of device, while the minor device number identifies the specific device; or in other words, the major device number identifies a specific driver program, while the minor device number represents the various devices using that driver program.
#if defined(DJGPP) || defined(__CYGWIN32__)
#ifdef KERNEL
typedef unsigned long u_long;
typedef unsigned int u_int;
typedef unsigned short u_short;
typedef u_long ino_t;
typedef u_long dev_t;
typedef void * caddr_t;
#ifdef DOS
typedef unsigned __int64 u_quad_t;
#else
typedef unsigned long long u_quad_t;
#endifIn Linux, dev_t is defined as unsigned long, which is 32 bits, with 12 bits for the major device number and 20 bits for the minor device number. When we write drivers, we will bind the device name (corresponding to the upper layer file name) with the device number, so that when the upper application operates on the device (file), the kernel can know which driver to call based on the device number.
/*
* NOTE:
* read, write, poll, fsync, readv, writev, unlocked_ioctl and compat_ioctl
* can be called without the big kernel lock held in all filesystems.
*/struct file_operations
{
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*aio_read) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
ssize_t (*aio_write) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
int (*readdir) (struct file *, void *, filldir_t);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, struct dentry *, int datasync);
int (*aio_fsync) (struct kiocb *, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
int (*check_flags)(int);
int (*flock) (struct file *, int, struct file_lock *);
ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t *, size_t, unsigned int);
ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *, size_t, unsigned int);
int (*setlease)(struct file *, long, struct file_lock **);
};From this structure, we can see functions like llseek(), read(), write(), etc., which correspond to the system calls we often use in user space, such as *llseek(), read(), write(), or fseek(), fread(), fwrite(), etc. (in reality, library functions ultimately access devices through system calls). Up to this point, we can understand that in the Linux kernel, the main work of drivers has two parts: first, allocating major and minor device numbers and binding the device name (file name) with the major and minor device numbers; second, filling the file_operations structure, i.e., implementing the corresponding function entities in the structure. This is quite different from bare-metal drivers, where only the corresponding interface functions are implemented. For now, I will stop here! Tomorrow I will explain the driver implementation process through examples.