The build process of Zephyr is divided into two main stages: the configuration stage and the compilation stage. The configuration stage generates the necessary configuration items, while the compilation stage selects the source code to compile based on the configuration items and links them into the final executable file.
The configuration stage is driven by cmake, which mainly accomplishes the following through cmake commands and python scripts: DTS processing, conf/Kconfig file processing, and cmake processing to output control the compilation build’s makefile or ninja file. The entire process is shown in the figure below.
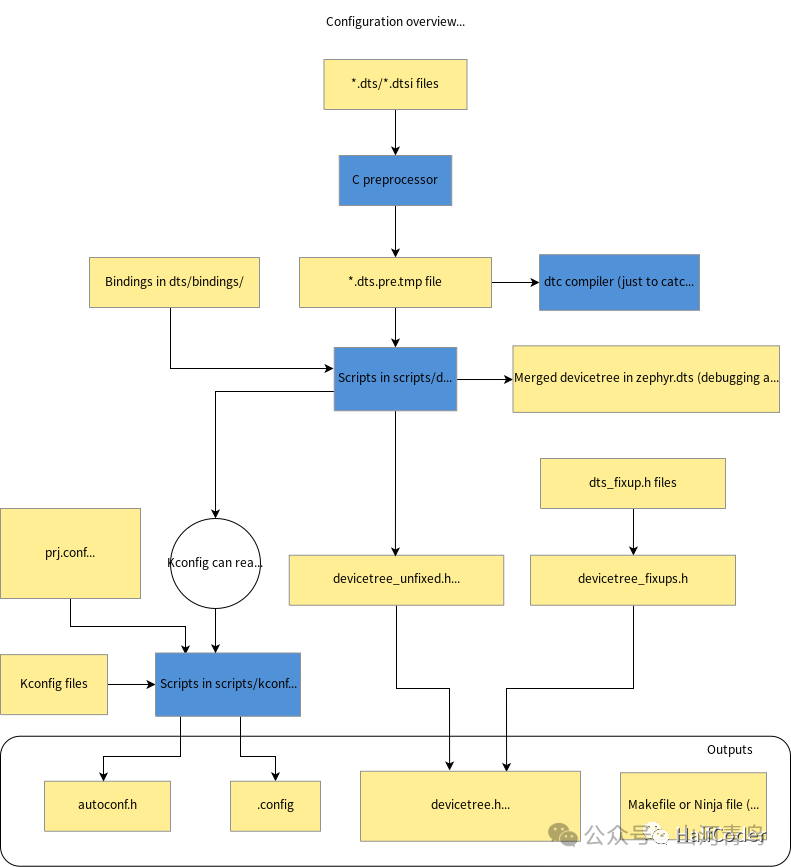
Let’s take a look at a configuration system in Zephyr. In the Zephyr system, the kernel, subsystems, drivers, and user code can all be flexibly configured at build time to trim or configure a program code that meets different functionalities for different platforms. The configuration system of Zephyr is similar to that of the Linux kernel, both using Kconfig for configuration. The entire building process of the Zephyr program can be divided into two stages: one is the configuration stage, and the other is the build stage. When using west to call cmake to generate the build system, the configuration stage begins its work.
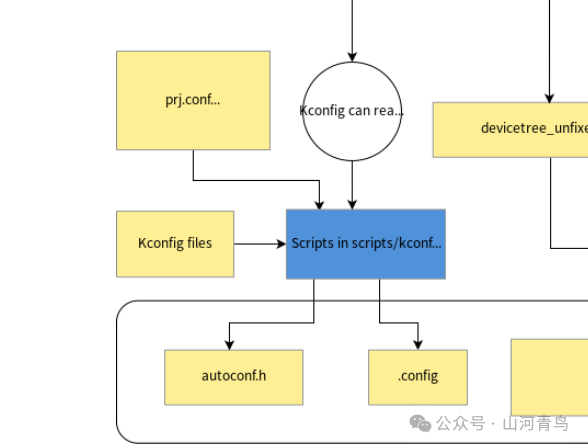
In the configuration stage, the device tree is first parsed by a script, and then the Kconfig script begins to work, generating the .config file and autoconf.h file through the Kconfig configuration files prj.conf and ${board}_defconfig. The .config file is mainly used for some configuration symbols that can be utilized in cmake files, while the autoconf.h file is primarily for macros that can be used in C source files.
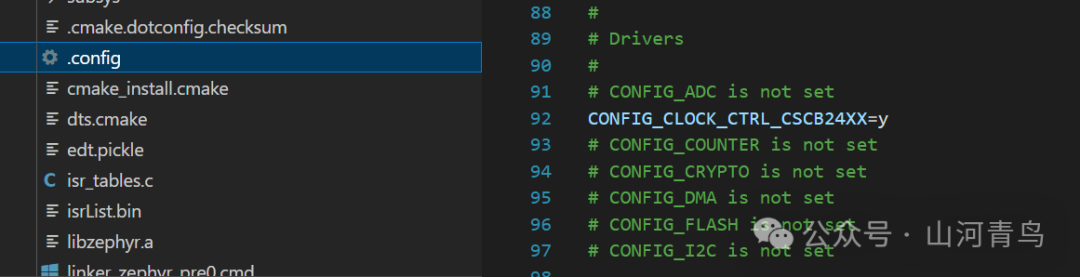
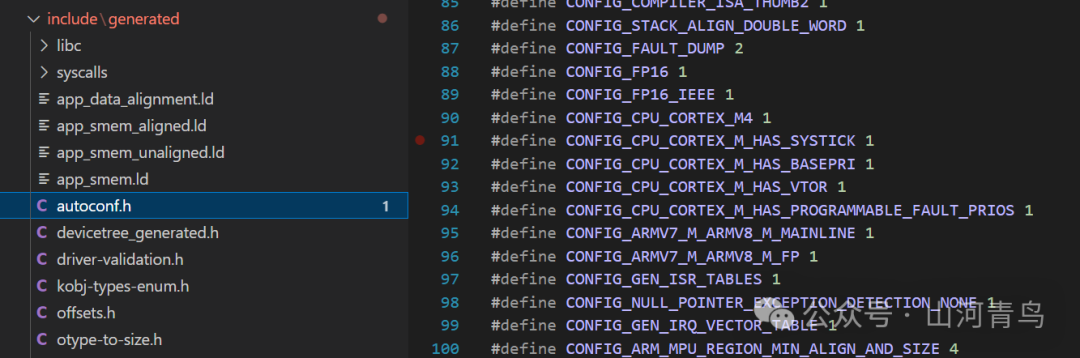
As shown in the figure, the autoconf.h contains some familiar macros in C code. By including this header file in the code, these configuration macros can be utilized.
Kconfig stands for kernel configuration. Kconfig is a configuration system in the Linux kernel, based on text files, allowing users to conveniently select specific features and drivers to compile into the kernel. menuconfig is a terminal-based configuration tool that provides a graphical way to configure Kconfig.
The Kconfig parser: Kconfig can be considered a syntax or rule that requires a parser to interpret its syntax. In Zephyr, the kconfiglib.py in Python is used to parse the entire system of Zephyr. In Kconfig, different compilation logics can be set to trim the Zephyr system to achieve the required functionality.
After the build is completed, the following command can be used:
west build -t menuconfigThis generates a GUI interface as shown below, where the Zephyr kernel or its own chip modules can be configured.
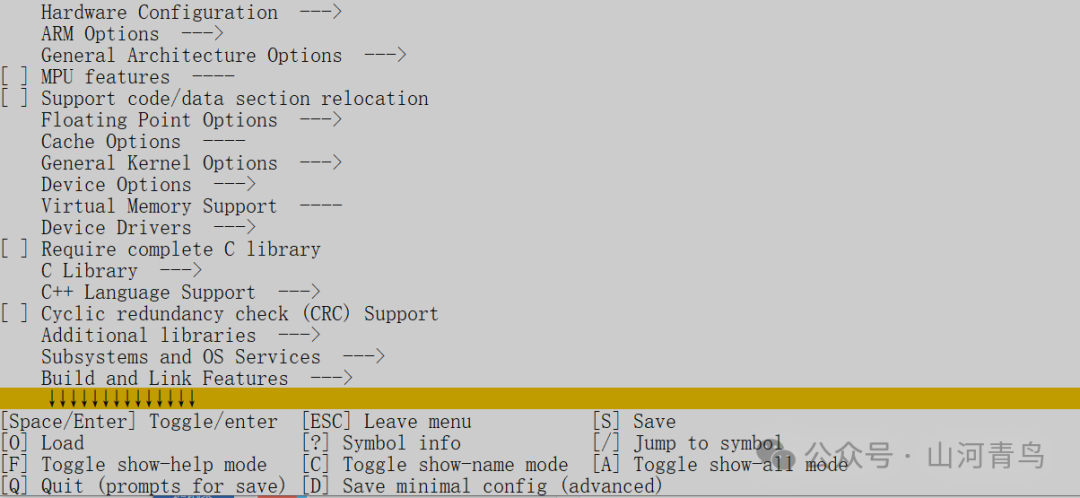
Another command that can be used is:
west build -t guiconfigBy invoking Python scripts, the following interface can be obtained, allowing for GUI configuration of various peripherals.
In the app, there is a prj.conf file that can configure whether to enable peripherals. This is also a script in Zephyr. As shown in the figure, prj.conf and Kconfig files generate autoconf.h and .config files through Python scripts.
Zephyr also has the concept of a device tree, where DTS stands for device tree. This concept is derived from the device tree in Linux. The device tree can be simply understood as a way to configure and modify hardware-related data, such as several I2Cs and the register addresses of each I2C controller, independently of the kernel according to the structure of the device tree. Here, it is necessary to understand the syntax knowledge of the device tree. Once the device tree file is available, how does the kernel code read this information for board-level initialization? Linux’s approach is to compile it into a DTB file, which is parsed during kernel startup to obtain hardware data one by one. The design premise of the Zephyr system is resource-constrained small systems, where a large amount of parsing work is done at the build compile stage. By using scripts, data from the device tree files are converted into header files, using various macros as replacements, which are then called by the kernel API. The DTS build process is shown in the figure below:
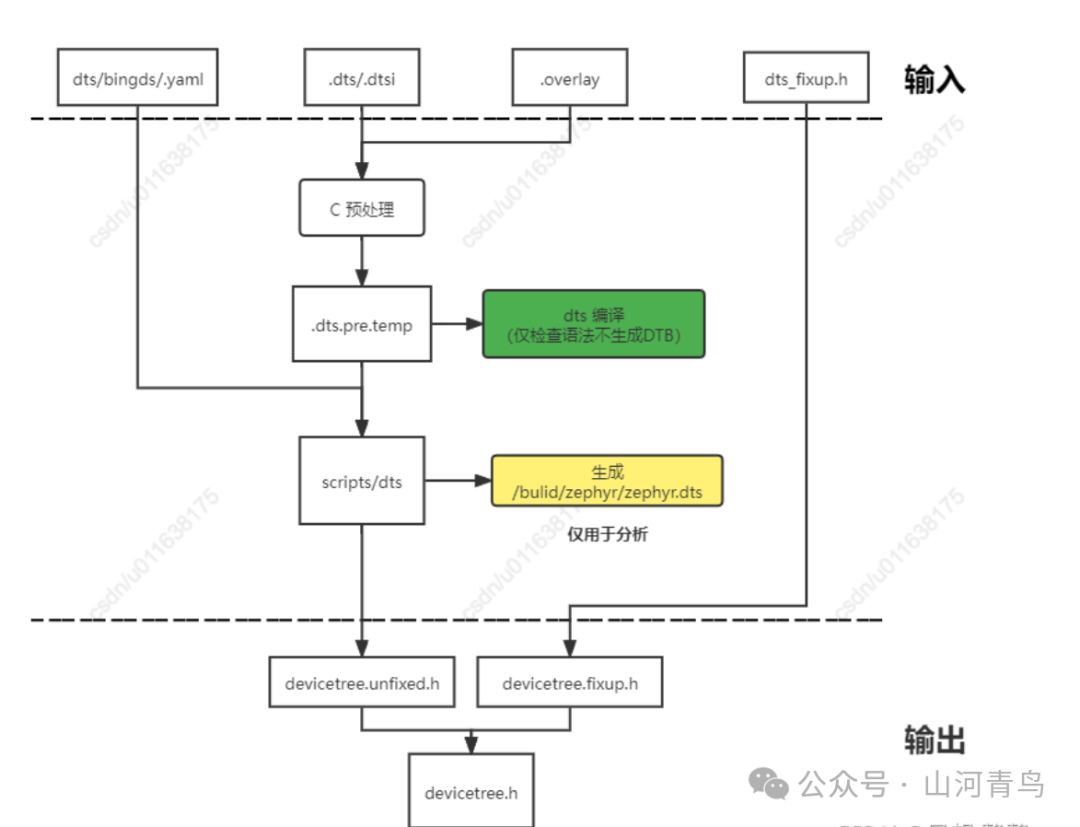
It is important to note:
-
Every supported board has its own default .dts/.dtsi files to describe hardware, usually located in the boards/// path.
-
.overlay is also a DTS file, used to extend or modify the default configuration. The main usage scenarios include:
-
Using .overlay files in application project directories to modify board-level default configurations, affecting only this application project. This allows users to extend or modify the device tree for a specific application without altering the original kernel code.
-
In the zephyr/Shields directory, certain board-level extensions .dts/.dtsi and .overlay files are preprocessed and merged into a .dts.pre.temp file, which undergoes device tree syntax checks during compilation, providing error messages.
-
The .dts.pre.temp file matches each node to the corresponding binds file (specifics will be analyzed in later DTS binds analysis).
-
The .dts.pre.temp file generates the zephyr.dts file through a script, serving as the final product of the device tree file, allowing users to easily check the correctness of the device tree configuration (the subsequent conversion to header files uses various macros, making it less intuitive to read compared to device tree files).
-
The .dts.pre.temp file outputs the devicetree.unfixed.h header file through a script, which converts the information of each device tree node into macro replacements.
-
The devicetree.fixup.h file is no longer recommended for use due to historical reasons.
-
What is ultimately provided to the kernel user is devicetree.h, which contains devicetree.unfixed.h and APIs for data retrieval.
Device tree bindings describe the requirements for node content and provide semantic information about valid node content. Zephyr device tree bindings are custom-format YAML files (Zephyr does not use the dt-schema tool used by the Linux kernel), which serve the purpose of matching each node in the device tree to the corresponding binding file during the configuration stage. When this operation is correct, the build system uses the information from the binding files to validate node content and generate macros for the nodes.
To illustrate with an example:
/* This is a node information in a device tree file */bar-device { compatible = "foo-company,bar-device"; num-foos = <3>;}; // This is the corresponding binds file for this node // Matched through the compatible attribute // Constrains the relevant information for the node bar-devicecompatible: "foo-company,bar-device"properties: num-foos:type: int // Constrains the data type as int required: true // Constrains that this node must have num-foos, otherwise it will cause an error during the build