Skip to content
If you work in communication or IT, you cannot avoid networks, and the most important protocol in networking is TCP. Whether in practical work or in written exams and interviews, where can you go without TCP?
I have read the documents related to TCP in the RFC, and also looked at the source code related to TCP in Linux, as well as the TCP-related code in many frameworks, I have a bit of an understanding of TCP.
I have always wanted to find time to share knowledge related to TCP, and if anyone has questions, feel free to communicate with each other. In fact, once you thoroughly understand TCP, you will find that it is just that simple. Those TCP/IP network knowledge!
Consider the simplest case: communication between two hosts. At this time, you only need a network cable to connect the two, specifying their hardware interfaces, such as using USB, 10v voltage, 2.4GHz frequency, etc., this layer is the physical layer, and these specifications are the physical layer protocol.
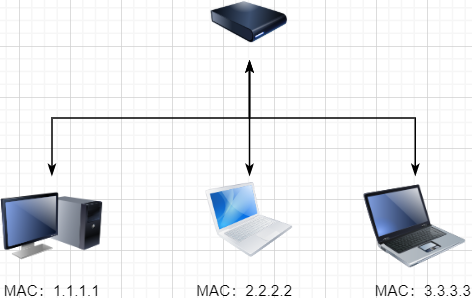
Of course, we are not satisfied with just connecting two computers, so we can use a switch to connect multiple computers, as shown below:
This connected network is called a local area network (LAN), which can also be called Ethernet (Ethernet is a type of LAN). In this network, we need to identify each machine, so that we can specify which machine to communicate with. This identifier is the hardware address MAC. The hardware address is determined permanently and uniquely when the machine is manufactured. In a LAN, when we want to communicate with another machine, we only need to know its hardware address, and the switch will send our message to the corresponding machine.
Here we can ignore how the underlying network cable interface sends and abstract the physical layer, creating a new layer above it, which is the data link layer.
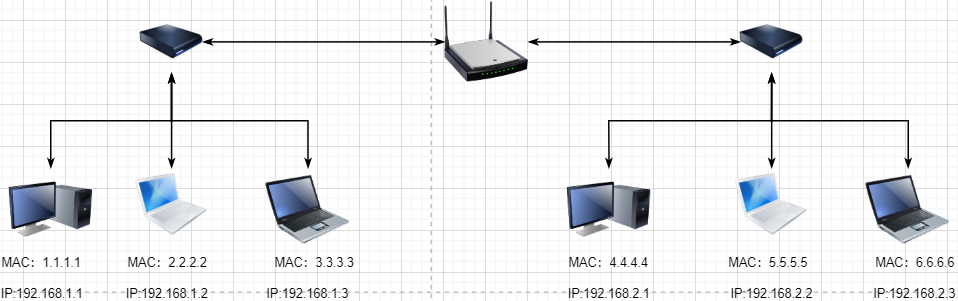
We are still not satisfied with the scale of the LAN and need to connect all LANs together, which requires the use of a router to connect two LANs:
However, if we still use hardware addresses as the unique identifier for communication objects, then as the network scale increases, it is unrealistic to remember all the machines’ hardware addresses; at the same time, a network object may frequently change devices, making the maintenance of the hardware address table more complex. Here, a new address is used to mark a network object: IP address.
To understand the IP address through a simple letter sending example.
I live in Beijing, and my friend A lives in Shanghai. I want to write a letter to friend A:
-
After finishing the letter, I will write my friend A’s address on it and put it in the Beijing post office (attach the target IP address to the information and send it to the router)
-
The post office will help me transport the letter to the local post office in Shanghai (the information will be routed to the router of the target IP LAN)
-
The local router in Shanghai will help me deliver the letter to friend A (communication within the LAN)
Therefore, the IP address here is a network access address (friend A’s address), and I only need to know the target IP address, and the router can bring the message to me. In the LAN, a dynamic mapping relationship between MAC address and IP address can be maintained, and the machine’s MAC address can be found for sending based on the destination IP address.
Thus, we do not need to manage how to choose the machine at the bottom layer; we only need to know the IP address to communicate with our target. This layer is the network layer. The core function of the network layer is to provide logical communication between hosts. In this way, all hosts in the network are logically connected, and the upper layer only needs to provide the target IP address and data, and the network layer can send the message to the corresponding host.
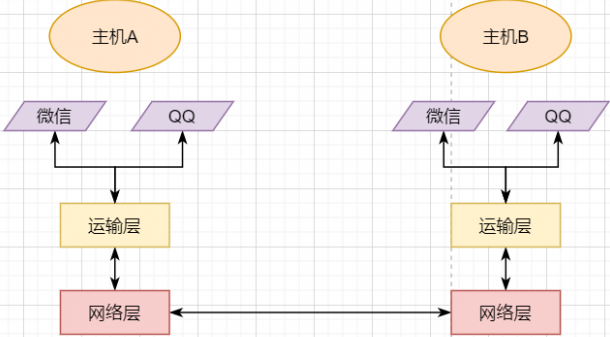
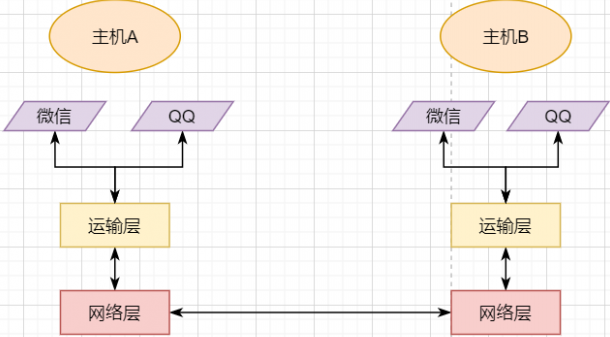
A host has multiple processes, and different network communications occur between processes, such as playing games with friends while chatting with a girlfriend on WeChat. My phone communicates simultaneously with two different machines. So when my phone receives data, how does it distinguish whether the data is from WeChat or from the game? Then we must add another layer above the network layer: transport layer:
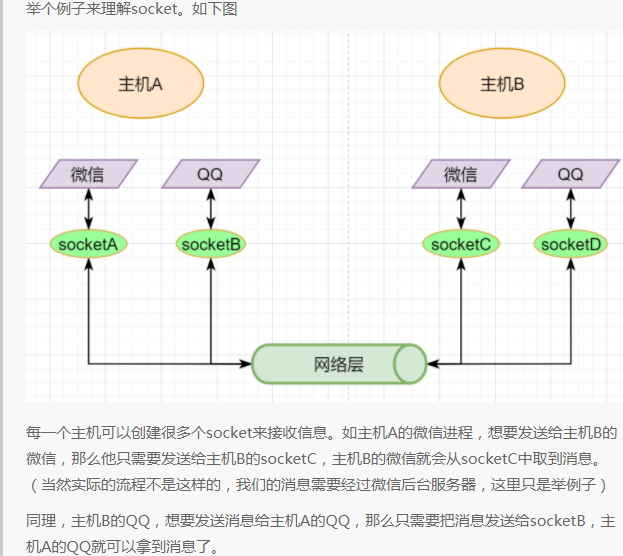
The transport layer uses socket to further split network information, allowing different application processes to independently make network requests without interfering with each other. This is the most essential characteristic of the transport layer:providing logical communication between processes. The processes here can be between hosts or within the same host, so in Android, socket communication is also a form of inter-process communication.
Now that application processes on different machines can communicate independently, we can develop various applications on computer networks: such as HTTP for web pages, FTP for file transfers, etc. This layer is called the application layer.
The application layer can also further split into the presentation layer and session layer, but their essential characteristics remain unchanged: fulfilling specific business requirements. Compared to the four layers below, they are not mandatory and can be classified into the application layer.
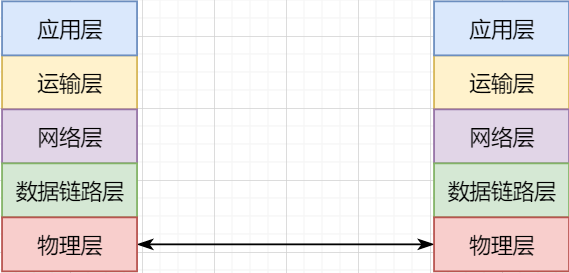
Finally, a brief summary of the network layer: with images and text: 16 illustrations explain network protocols
-
The lowest layer is the physical layer, responsible for direct communication between two machines;
-
The data link layer uses hardware addresses for addressing within the LAN, achieving LAN communication;
-
The network layer achieves logical communication between hosts through abstracting IP addresses;
-
The transport layer splits data based on the network layer, achieving independent network communication for application processes;
-
The application layer develops various functions based on the transport layer according to specific requirements.
It is important to note that layering is not a physical layering but a logical layering. By encapsulating the underlying logic, the upper layer can directly rely on the functions of the lower layer without worrying about specific implementations, simplifying development.
This layered thinking is also the responsibility chain design pattern, encapsulating different responsibilities layer by layer to facilitate development, maintenance, etc. The interceptor design pattern in okHttp is also this responsibility chain pattern.
This article mainly explains TCP, and here we need to add some knowledge about the transport layer.
Essence: Providing Process Communication
Below the transport layer, the network layer does not know which process the data packet belongs to; it only handles the receiving and sending of data packets. The transport layer is responsible for receiving data from different processes and handing it over to the network layer, while also splitting the data from the network layer for different processes. Aggregating from top to bottom to the network layer is called multiplexing, while splitting from bottom to top is called demultiplexing.
The performance of the transport layer is limited by the network layer. This is easy to understand, as the network layer is the lower layer support for the transport layer. Therefore, the transport layer cannot decide its bandwidth, delay, and other upper limits. However, more features can be developed based on the network layer: such as reliable transmission. The network layer is only responsible for trying to send data packets from one end to the other, without guaranteeing that the data can arrive intact.
Underlying Implementation: Socket
As mentioned earlier, the simplest transport layer protocol is to provide independent communication between processes, but the underlying implementation is independent communication between sockets. In the network layer, the IP address is a logical address of a host, while in the transport layer, the socket is a logical address of a process; of course, a process can have multiple sockets. Application processes can listen to sockets to receive messages received by those sockets.
The socket is not a tangible object but an object abstracted out by the transport layer. The transport layer introduces the concept of port to distinguish different sockets. A port can be understood as having many network communication ports on a host, each with a port number, and the number of ports is determined by the transport layer protocol.
Different transport layer protocols have different definitions of sockets. In the UDP protocol, a socket is defined using the target IP + target port number; in TCP, it is defined using the target IP + target port number + source IP + source port number. We only need to attach this information in the header of the transport layer packet, and the target host will know which socket we want to send to, and the process listening to that socket can receive the information.
Transport Layer Protocols
The protocols of the transport layer are the famous TCP and UDP. Among them, UDP is the most streamlined transport layer protocol, only implementing inter-process communication; while TCP, based on UDP, implements features such as reliable transmission, flow control, congestion control, and connection-oriented features, making it more complex.
Of course, in addition to these, there are many more excellent transport layer protocols, but the most widely used ones are TCP and UDP. UDP will also be summarized later.
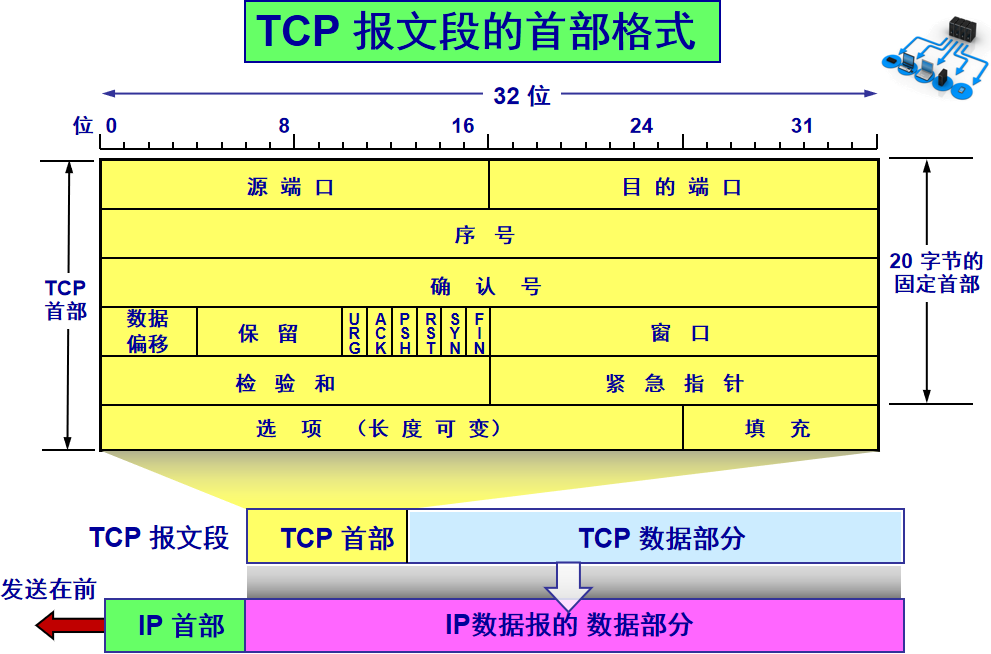
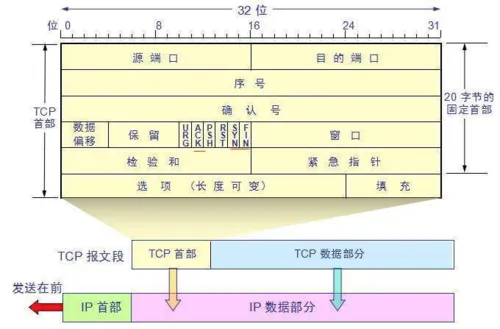
The TCP protocol is represented in the packet by attaching a TCP header before the data transmitted from the application layer. Let’s take a look at the overall structure of this header:
This image is from a university teacher’s courseware, very useful, so I have kept it for study. The bottom part represents the relationship between packets, and the TCP data part is the data transmitted from the application layer.
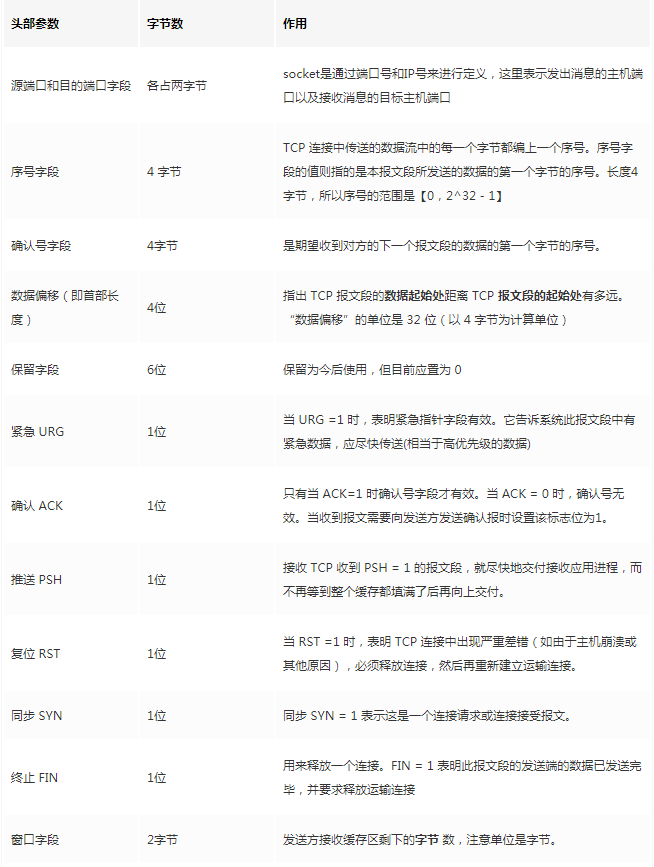
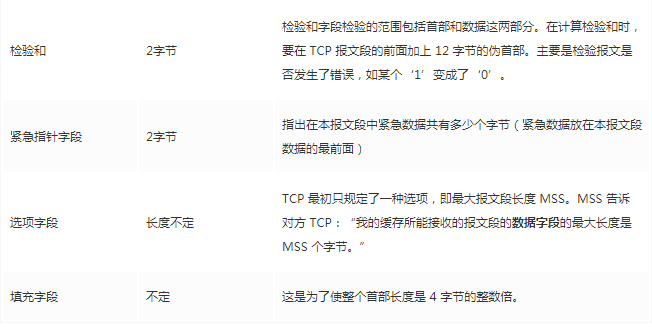
The fixed length of the TCP header is 20 bytes, and there are 4 additional bytes that are optional. There is a lot of content, but some of it is familiar to us: source port, destination port. Huh? Isn’t a socket still required to locate using IP? The IP address is attached at the network layer. Other contents will be explained slowly later. As a summary article, here is a reference table for review:
The option field includes the following other options:
After explaining the following content, looking back at these fields will become familiar.
/ TCP Byte Stream Orientation Feature /
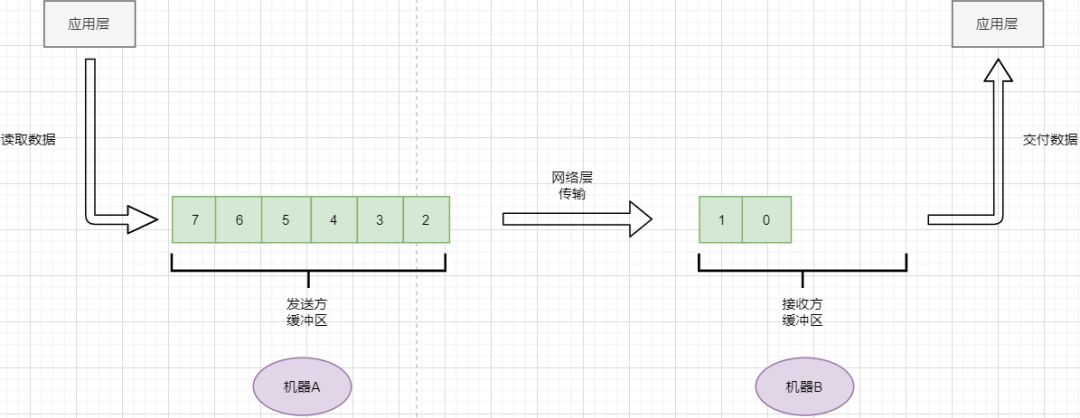
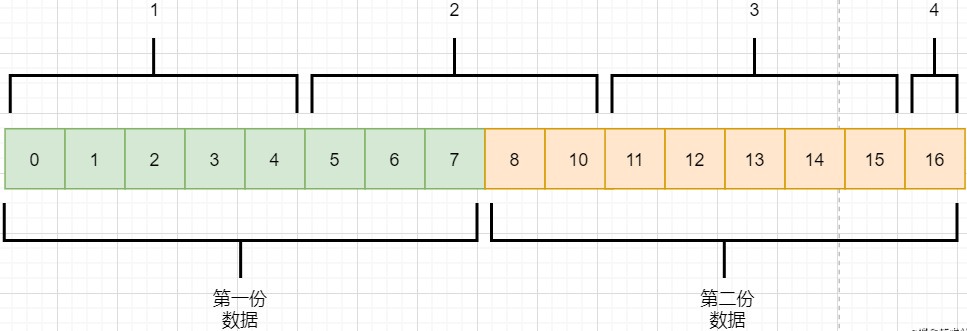
TCP does not directly send the data transmitted from the application layer by simply adding a header; instead, it treats the data as a byte stream, numbering them, and then sending them in parts. This is the byte stream-oriented feature of TCP:
-
TCP reads data from the application layer in a stream manner and stores it in its sending buffer while numbering these bytes.
-
TCP selects an appropriate amount of bytes from the sending buffer to form a TCP packet and sends it to the target through the network layer.
-
The target reads the bytes and stores them in its receiving buffer, delivering them to the application layer at the appropriate time.
The advantage of being byte stream-oriented is that it does not require storing excessively large data at once, which would occupy too much memory. The downside is that it cannot know the meaning of these bytes; for example, when the application layer sends an audio file and a text file, TCP sees them as a stream of bytes with no meaning, which can lead to packet sticking and unpacking issues, which will be discussed later.
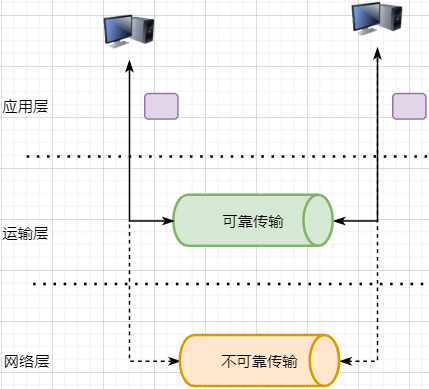
/ Reliable Transmission Principle /
As mentioned earlier, TCP is a reliable transmission protocol, meaning that once it is given a data packet, it will definitely send it to the target address intact, unless the network fails. It implements the following network model:
For the application layer, it is a reliable transmission bottom support service; while the transport layer uses the unreliable transmission of the network layer. Although protocols can be used at the network layer and even the data link layer to ensure the reliability of data transmission, this would make the network design more complex, and efficiency would decrease. Placing the guarantee of data transmission reliability at the transport layer is more appropriate.
The key points of the reliable transmission principle are summarized as follows:sliding window, timeout retransmission, cumulative acknowledgment, selective acknowledgment, continuousARQ.
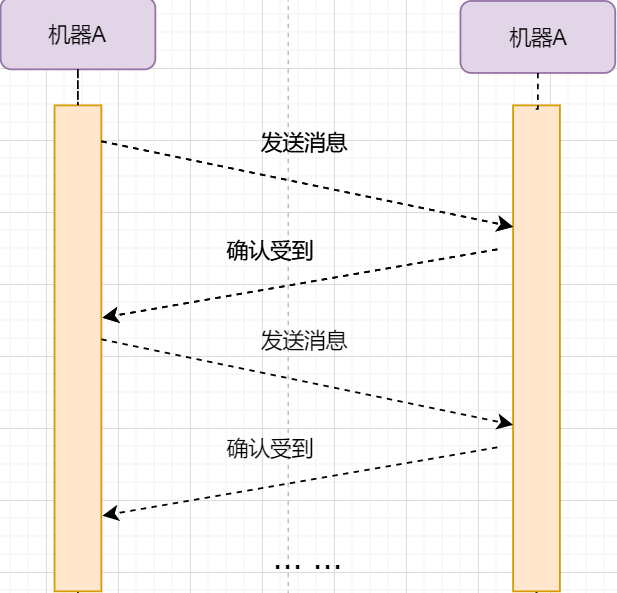
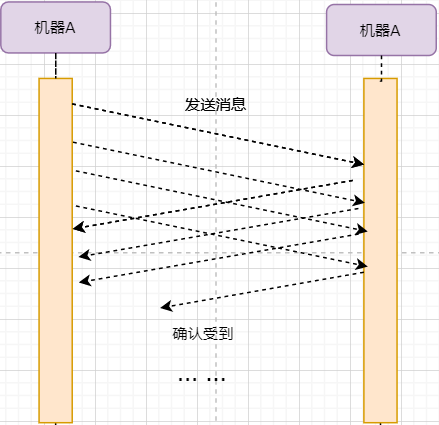
Stop-and-Wait Protocol
To achieve reliable transmission, the simplest method is: I send a data packet to you, then you reply to me that you received it, and I continue to send the next data packet. The transmission model is as follows:
This “one come one go” method to ensure reliable transmission is called stop-and-wait protocol. I wonder if you remember that the TCP header has an ack field; when it is set to 1, it indicates that this packet is a confirmation of receipt.
Now consider a situation: packet loss. The unreliable network environment means that every time a data packet is sent, it may be lost. If machine A sends a data packet and it gets lost, machine B will never receive it, and machine A will always be waiting. The solution to this problem is: timeout retransmission. When machine A sends a data packet, it starts timing; if the time is up and no confirmation reply is received, it can be assumed that a packet loss has occurred, and it will send again, which is retransmission.
However, retransmission can lead to another problem: if the original data packet was not lost but simply took longer to arrive, machine B will receive two data packets. How does machine B distinguish whether these two data packets belong to the same data or different data? This requires the previously mentioned method: numbering the data bytes. This way, the receiver can determine whether the data is new or a retransmission based on the byte number.
In the TCP header, there are two fields: sequence number and acknowledgment number, which indicate the number of the first byte of data sent by the sender and the number of the first byte of data the receiver expects next. As mentioned earlier, TCP is byte stream-oriented, but it does not send one byte at a time; instead, it takes a whole segment at once. The length of the segment is affected by various factors, such as the size of the buffer and the frame size limited by the data link layer.
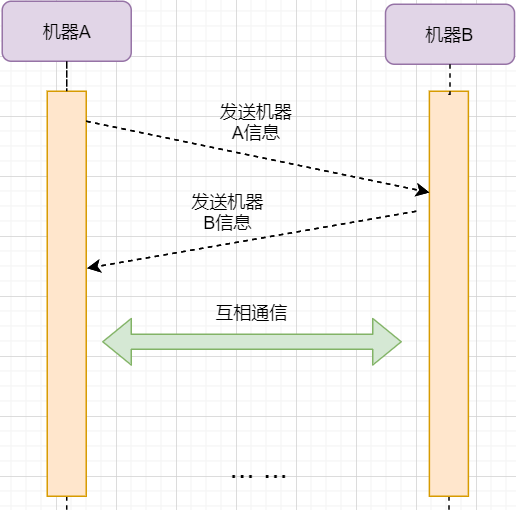
Continuous ARQ Protocol
The stop-and-wait protocol can satisfy reliable transmission, but it has a fatal flaw: inefficiency. After sending a data packet, the sender enters a wait state during which it does nothing, wasting resources. The solution is to continuously send data packets. The model is as follows:
The biggest difference from stop-and-wait is that it will continuously send data, and the receiver will continuously receive data and confirm replies one by one. This greatly improves efficiency. However, it also brings some additional problems:
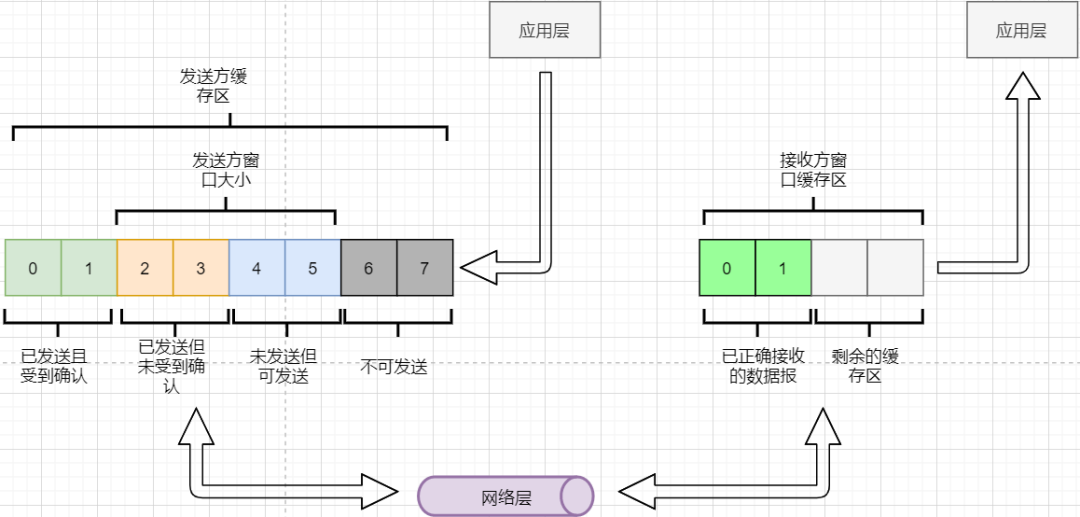
Can the sender send indefinitely until all data in the buffer is sent? No, because it needs to consider the receiving buffer and the ability to read data of the receiver. If sending too fast causes the receiver to be unable to accept, it will only lead to frequent retransmissions, wasting network resources. Therefore, the range of data that the sender can send must consider the receiving buffer of the receiver. This is the flow control of TCP. The solution is: sliding window. The basic model is as follows:
-
The sender needs to set its own send window size based on the size of the receiver’s buffer; data within the window is considered sendable, while data outside the window is not.
-
When the data within the window receives a confirmation reply, the entire window moves forward until all data is sent.
In the TCP header, there is a window size field that indicates the remaining buffer size of the receiver, allowing the sender to adjust its sending window size. Through the sliding window, TCP’s flow control can be achieved to avoid sending too fast, leading to excessive data loss.
The second problem brought by continuous ARQ is that the network is flooded with acknowledgment packets equal to the number of data packets sent, because every sent data packet must have a confirmation reply. The method to improve network efficiency is: cumulative acknowledgment. The receiver does not need to reply to each packet individually; instead, it can accumulate a certain amount of data packets and inform the sender that all data prior to this packet has been received. For example, if it receives 1234, the receiver only needs to tell the sender that it has received 4, meaning the sender knows that 1234 has all been received.
The third problem is: how to handle packet loss situations. In the stop-and-wait protocol, it is simple; just a timeout retransmission solves it. However, in continuous ARQ, it is not so straightforward. For example, if the receiver receives 123 and 567, six bytes, but byte number 4 is lost. According to the cumulative acknowledgment idea, it can only send acknowledgment for 3, and 567 must be discarded because the sender will retransmit. This follows the GBN (go-back-n) idea.
However, we find that we only need to retransmit 4, which is very wasteful of resources, so there is the Selective Acknowledgment (SACK). In the options field of the TCP packet, it can set the received packet segments, each segment requiring two boundaries for determination. This way, the sender can only retransmit the lost data based on this options field.
Summary of Reliable Transmission
At this point, the principles of reliable transmission in TCP have been introduced. Finally, a brief summary:
-
Ensuring that every data packet arrives at the receiver through continuous ARQ protocol and sending-confirmation reply mode.
-
Using the method of numbering bytes to mark whether each data is a retransmission or new data.
-
Using timeout retransmission to solve the problem of data packets being lost in the network.
-
Implementing flow control through sliding windows.
-
Improving the efficiency of acknowledgment replies and retransmissions through cumulative acknowledgment + selective acknowledgment.
Of course, this is just the tip of the iceberg of reliable transmission; if interested, you can study further (and chat with the interviewer is almost the same [dog head]).
Congestion control considers another problem: avoiding excessive network congestion leading to severe packet loss and reduced network efficiency.
Taking real traffic as an example:
The number of cars that can travel on a highway at the same time is limited. During holidays, serious traffic jams occur. In TCP, if packets time out, retransmission will occur, leading to more cars coming in, which causes more congestion, ultimately resulting in: packet loss – retransmission – packet loss – retransmission. Eventually, the entire network collapses.
The congestion control here is not the same as flow control; flow control is a means of congestion control: to avoid congestion, it is necessary to control the flow. The purpose of congestion control is to limit the amount of data sent by each host to avoid a decrease in network congestion efficiency. This is akin to limiting travel based on license plate numbers in places like Guangzhou; otherwise, everyone will be stuck in traffic, and no one can move.
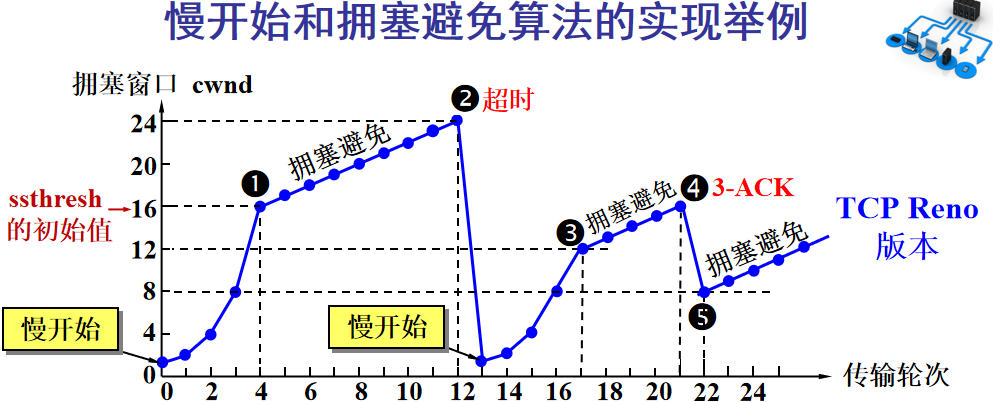
The key points of congestion control are four: slow start, fast recovery, fast retransmission, congestion avoidance. Here, I will also sacrifice a university teacher’s PPT image:
The Y-axis represents the size of the sender’s window, and the X-axis represents the rounds of sending (not byte numbers).
-
At the beginning, a small value is set for the window, and then it doubles each round. This is slow start.
-
When the window value reaches the ssthresh value, which is a window limit value that needs to be set based on real-time network conditions, it starts congestion avoidance, increasing the window value by 1 each round to slowly probe the network’s bottom line.
-
If data times out, it indicates a high possibility of congestion, and it goes back to slow start, repeating the above steps.
-
If three identical acknowledgment replies are received, it indicates that the network situation is not good, and the ssthresh value is set to half of the original, continuing congestion avoidance. This part is called fast recovery.
-
If packet loss information is received, the lost packet should be retransmitted as soon as possible; this is fast retransmission.
-
Of course, the final upper limit of the window cannot increase indefinitely; it cannot exceed the size of the receiver’s buffer.
Through this algorithm, a significant degree of network congestion can be avoided.
In addition, routers can inform the sender when the cache is about to be full, rather than waiting for a timeout to process; this is called Active Queue Management (AQM). There are many other methods, but the algorithms above are key.
This section discusses the well-known TCP three-way handshake and four-way handshake. After the previous content, this section is already easy to understand.
TCP is connection-oriented, so what is a connection? The connection here is not a physical connection but a record between the two parties of communication. TCP is a full-duplex communication, meaning data can be sent mutually, so both parties need to record each other’s information. According to the previous principles of reliable transmission, both parties in TCP communication need to prepare a receiving buffer to receive each other’s data, remember each other’s sockets to know how to send data, and remember each other’s buffers to adjust their window size, etc. These records constitute a connection.
In the transport layer section, it was mentioned that the address for communication between transport layer parties is defined using sockets, and TCP is no exception. Each TCP connection can only have two objects, meaning two sockets, and cannot have three. Therefore, the definition of a socket requires four key factors: source IP, source port number, target IP, and target port number to avoid confusion.
If TCP and UDP were to define sockets using only target IP + target port number, multiple senders could simultaneously send to the same target socket. In this case, TCP would not be able to distinguish whether these data came from different senders, leading to errors.
Since it is a connection, there are two key points: establishing a connection and disconnecting a connection.
Establishing a Connection
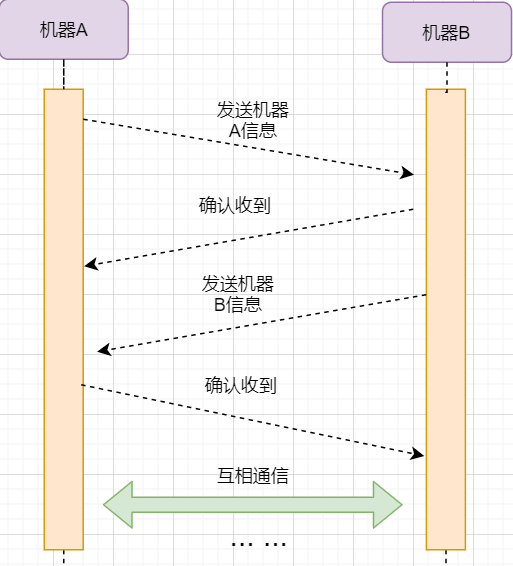
The purpose of establishing a connection is to exchange information between parties and remember each other’s information. Therefore, both parties need to send their information to each other:
However, the previous principles of reliable transmission tell us that data transmission in the network is unreliable, and we need a confirmation reply from the other party to ensure that the message reaches correctly. As shown in the following image:
The acknowledgment of receipt from machine B and the information sent from machine B can be merged to reduce the number of messages; moreover, the message sent from machine B to machine A itself represents that machine B has already received the message, so the final example image is:
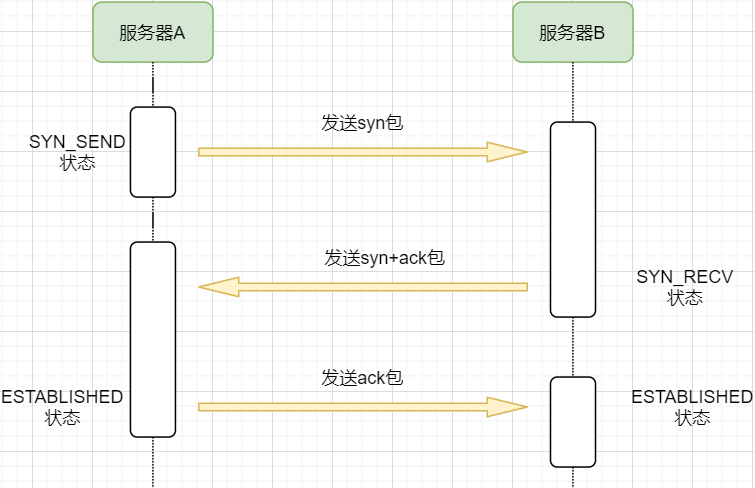
The steps are as follows:
-
Machine A sends a SYN packet to machine B requesting to establish a TCP connection, attaching its receiving buffer information, etc. Machine A enters the SYN_SEND state, indicating that the request has been sent and is waiting for a reply;
-
Machine B receives the request, records the information from machine A, creates its own receiving buffer, and sends a combined SYN+ACK packet back to machine A while entering the SYN_RECV state, indicating that it is ready and waiting for machine A’s reply before it can send data to A;
-
Machine A receives the reply, records machine B’s information, sends an ACK message, and enters the ESTABLISHED state, indicating that it is fully prepared for sending and receiving;
-
Machine B receives the ACK data and enters the ESTABLISHED state.
The three messages sent are called the three-way handshake.
Disconnecting a Connection
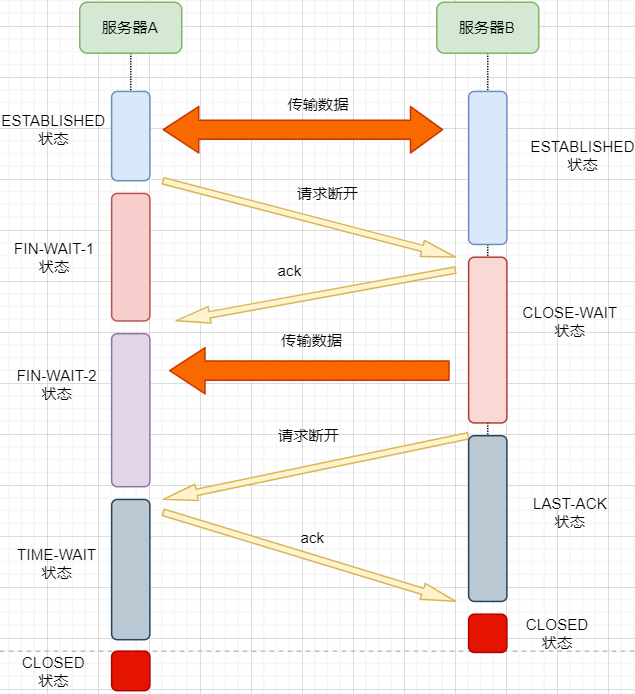
Disconnecting a connection is similar to the three-way handshake; let’s directly look at the image:
1. After machine A finishes sending data, it requests to disconnect from machine B, entering the FIN_WAIT_1 state, indicating that the data has been sent and the FIN packet has been sent (FIN flag is 1);
2. After machine B receives the FIN packet, it replies with an ACK packet indicating that it has received it. However, machine B may still have data to send; it enters the CLOSE_WAIT state, indicating that the other party has finished sending and requested to close the connection. It can close the connection after finishing its own sending;
3. After machine B finishes sending data, it sends a FIN packet to machine A, entering the LAST_ACK state, indicating that it is waiting for an ACK packet to close the connection;
4. After machine A receives the FIN packet, it knows that machine B has also finished sending and replies with an ACK packet, entering the TIME_WAIT state.
The TIME_WAIT state is quite special. When machine A receives the FIN packet from machine B, ideally, it can directly close the connection; however:
-
We know that the network is unstable, and some data sent by machine B may not have arrived yet (slower than the FIN packet);
-
At the same time, the ACK packet sent as a reply may be lost, causing machine B to retransmit the FIN packet;
If machine A closes the connection immediately, it may lead to incomplete data and machine B being unable to release the connection. Therefore, machine A needs to wait for 2 maximum segment lifetimes (MSL) to ensure that no residual packets are left in the network before closing the connection.
5. Finally, after waiting for the two maximum segment lifetimes, machine B receives the ACK packet, and both sides close the connection, entering the CLOSED state.
The process of the two sides sending four messages to disconnect the connection is called the four-way handshake.
Now, the questions of why the handshake is three times and the four-way handshake is four times, whether it must be three times/four times, and why it is necessary to wait for 2 MSL before closing the connection, etc., are all resolved.
Besides TCP, the transport layer protocol also includes the famous UDP. If TCP stands out for its comprehensive and stable features, then UDP is the minimalist approach that throws punches randomly.
UDP only implements the minimum functionality of the transport layer: inter-process communication. For data transmitted from the application layer, UDP simply adds a header and hands it over to the network layer. The UDP header is very simple, consisting of three parts:
-
Source port, destination port: port numbers are used to distinguish different processes of the host.
-
Checksum: used to verify that the data packet has not encountered errors during transmission, such as a 1 turning into a 0.
-
Length: the length of the packet.
Therefore, UDP’s functionality is limited to two: verifying whether the data packet has errors and distinguishing different inter-process communications.
However, although TCP has many features, it also comes at a corresponding cost. For example, the connection-oriented feature incurs overhead during connection establishment and disconnection; the congestion control feature limits the upper limit of transmission, etc. Below are the pros and cons of UDP:
Disadvantages of UDP
-
Cannot guarantee that messages arrive intact and correctly; UDP is an unreliable transmission protocol;
-
Lacks congestion control, which can lead to competing for resources and cause network systems to collapse.
Advantages of UDP
-
Faster efficiency; does not require establishing connections and congestion control.
-
Can connect more clients; without connection state, it does not need to create buffers for each client.
-
Smaller packet header size, lower overhead; the fixed header of TCP is 20 bytes, while UDP is only 8 bytes; a smaller header means a larger proportion of data.
-
In scenarios that require high efficiency and allow for some error, such as live streaming, it is acceptable for not every data packet to arrive completely; in this case, the reliable features of TCP become a burden, and the streamlined UDP is a more suitable choice.
-
Can perform broadcasting; since UDP is connectionless, it can simultaneously send packets to multiple processes.
Applicable Scenarios for UDP
UDP is suitable for scenarios that require high customization of the transmission model, allow for packet loss, require high efficiency, and need broadcasting; for example:
Chunked Transfer
We can see that the transport layer does not send the entire data packet directly with a header; instead, it splits it into multiple packets for separate transmission. Why does it do this?
Some readers might think: the data link layer limits the data length to only 1460. Why does the data link layer impose such a restriction? The fundamental reason is that the network is unstable. If the packet is too long, it is very likely to suddenly interrupt during transmission, and at that point, the entire data must be retransmitted, which reduces efficiency. By splitting the data into multiple packets, if one packet is lost, only that packet needs to be retransmitted.
But should the splitting be as fine as possible? If the data field length in a packet is too low, it will make the header occupy too much, and the header will become the largest burden in network transmission. For example, if 1000 bytes are sent, and each packet header is 40 bytes, splitting into 10 packets would require transmitting 400 bytes in headers; however, if split into 1000 packets, it would require transmitting 40000 bytes in headers, which drastically reduces efficiency.
Routing Conversion
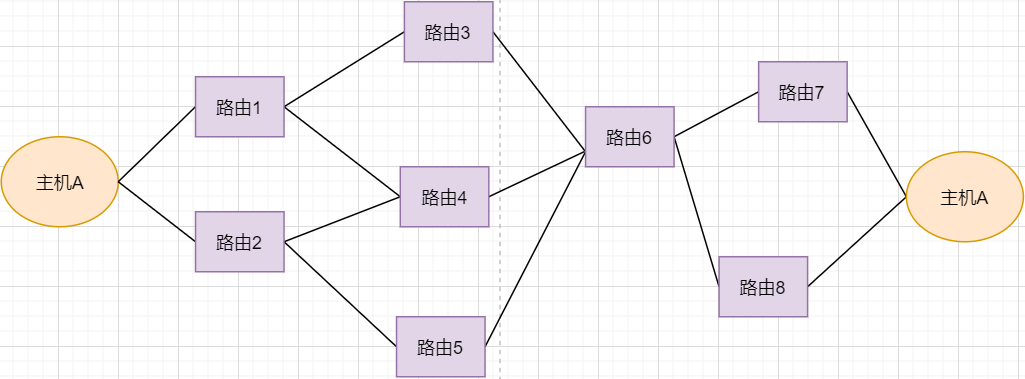
First, let’s look at the image:
-
Under normal circumstances, the data packet from host A can be transmitted through paths 1-3-6-7.
-
If router 3 fails, it can be transmitted through 1-4-6-7.
-
If router 4 also fails, it can only be transmitted through 2-5-6-7.
-
If router 5 fails, the line will be interrupted.
As we can see, using routing forwarding improves the fault tolerance of the network. The fundamental reason remains that the network is unstable. Even if several routers fail, the network can still function smoothly. However, if the core router 6 fails, it directly results in host A and host B being unable to communicate, so it is necessary to avoid the existence of such core routers.
Another benefit of using routing is load balancing. If a line is too congested, data can be transmitted from other routes to improve efficiency.
Packet Sticking and Unpacking
In the byte stream-oriented section, it was mentioned that TCP does not understand the meaning of these data streams. It only knows to take the data stream from the application layer, cut it into packets, and send them to the target object. If the application layer transmits two data packets, it is likely to encounter the following situation:
-
The application layer needs to send two pieces of data to the target process, one audio and one text.
-
TCP only knows that it has received a stream and splits the stream into four segments for sending.
-
The second packet’s data may contain mixed data from both files, which is called packet sticking.
-
The target process’s application layer needs to split this data into the correct two files, which is called unpacking.
Both packet sticking and unpacking are problems that the application layer needs to solve, which can be done by adding special bytes at the end of each file, such as newline characters; or controlling each packet to only contain data from one file, padding with 0 if insufficient, etc.
Malicious Attacks
The connection-oriented feature of TCP may be exploited by malicious individuals to attack servers.
As we know, when we send a SYN packet to a host to request to create a connection, the server creates a buffer for us and then returns a SYN+ACK packet to us; if we forge the IP and port and send massive requests to a server, it will create a large number of half-established TCP connections, causing the server to be unable to respond normally to user requests, ultimately leading to server paralysis.
The solution can be to limit the number of connections created by an IP, allow half-established TCP connections to close themselves within a shorter time, delay the allocation of memory in the receiving buffer, and so on.
Long Connections
Every request we make to the server requires creating a TCP connection, and once the server returns data, it closes the connection. If there are a large number of requests in a short time, frequently creating and closing TCP connections is a waste of resources. Therefore, we can keep TCP connections open during this period to make requests and improve efficiency.
It is necessary to pay attention to the maintenance time and creation conditions of long connections to prevent malicious exploitation that creates a large number of long connections, exhausting server resources.
In the past, when I studied, I felt that these things were somewhat useless, seemingly only for exams. In fact, when not applied, it is difficult to have a deeper understanding of this knowledge. For example, now when I look at the above summary, much of it is just superficial understanding, not knowing the true meaning behind it.
However, as I study more broadly and deeply, I will have a deeper understanding of this knowledge. There are moments when I feel: oh, that thing is used like this, that thing is like this, it turns out learning is indeed useful.
Now, I might not feel anything after learning, but when I use it or learn about related applications, there will be an epiphany, and I will gain a lot instantly.
Reviewed by: Zhao Lixin