Introduction to HTTP
1. HTTP Versions
Since the invention of the HTTP protocol, it has undergone several version modifications, namely <span>HTTP/0.9</span>, <span>HTTP/1</span><span>.0</span>, <span>HTTP/1.1</span> and <span>HTTP/2</span>. Currently, the main version in use is <span>HTTP/1.1</span>, which is the focus of this article.
2. TCP/IP Protocol
Before learning about the HTTP protocol, let’s first understand the TCP/IP protocol. It forms the foundation of HTTP; a solid foundation ensures a sturdy structure!
In your work, you may often hear about the OSI seven-layer network structure and the TCP/IP four-layer network structure, but what are they? Have you ever been confused by them in your daily work?
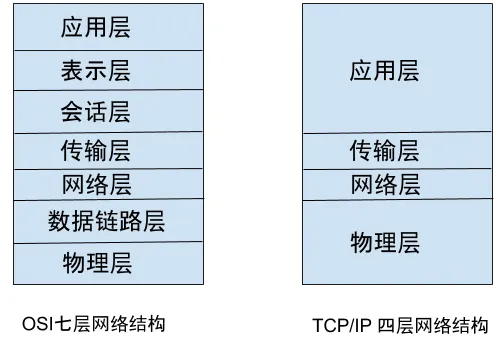
On the left is the well-known network structure model designated by the International Organization for Standardization (ISO). However, in practice, what we use is the TCP/IP four-layer network structure on the right.
<span>When ISO designated the network standards,</span>the<span>TCP/IP</span>protocol had already become the de facto standard, leading to a peculiar phenomenon. The international association established the standard, but no one uses it~~
Next, let’s briefly discuss the function of each layer in the TCP/IP four-layer structure.
Application Layer: This layer consists of protocols used by upper-layer applications. For example, <span>HTTP</span>, <span>FTP</span>, <span>SMTP</span>, etc.
Transport Layer: The three layers from the physical layer to the transport layer are responsible for establishing network connections and sending data. They do not concern themselves with what protocol the application layer uses. The protocols used at the transport layer are <span>TCP</span> and <span>UDP</span>.
Network Layer: This layer is responsible for selecting <span>routing paths</span>. There are many paths from the same origin to the same destination, and the network layer is responsible for choosing a path for data transmission.
Physical Layer: This layer is responsible for data transmission. This is the lowest layer, managed by the network card. The network card converts data into high/low voltage levels and then sends it through the network cable.
Now, let’s illustrate this process with a practical example:
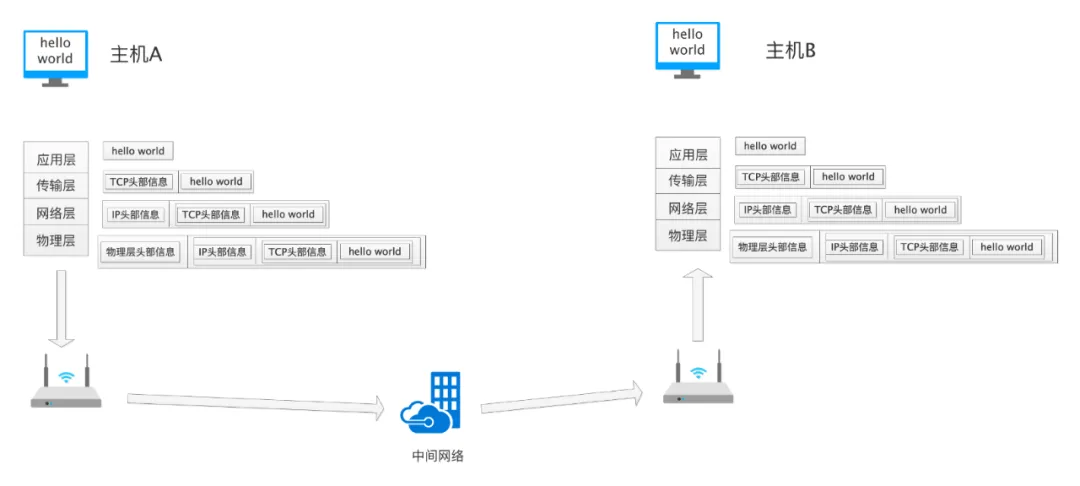
The image above shows the process of Host A sending “hello world” to Host B. After a user makes a request, the data travels from the application layer to the physical layer, with each layer adding additional information specific to that layer; at the receiving end, each layer removes its additional information and passes the remaining data to the upper layer for processing.
Doesn’t it resemble an onion, with layers upon layers…
The application layer encapsulates the information “hello world” using its protocol, then calls the interface of the transport layer, and so on, until the data is passed to the physical layer. Each layer adds its unique identifier. The physical layer ultimately converts the data to be sent (including the actual “hello world” that the application layer intended to send and the identifiers added by each layer) into high and low voltage levels for transmission. Upon receiving the data, the receiving end performs a reverse parsing process, and finally, Host B receives “hello world”.
The above is a simplified description, but the overall principle is as such~ Don’t be confused by the concepts of each layer. These layers are artificially divided concepts, created for convenience when coding. You only need to define the interface for each layer, and the upper layer can call the interface of the lower layer without needing to concern itself with the specific implementation. This is also a principle in software design.
3. HTTP Protocol
Having briefly discussed the network structure, these concepts are the foundation of HTTP operation. Now, let’s talk about the main focus of this article: the content related to the HTTP protocol.
3.1 Overview of HTTP Protocol
Let’s first take a look at the overview diagram of the HTTP protocol, as shown below:
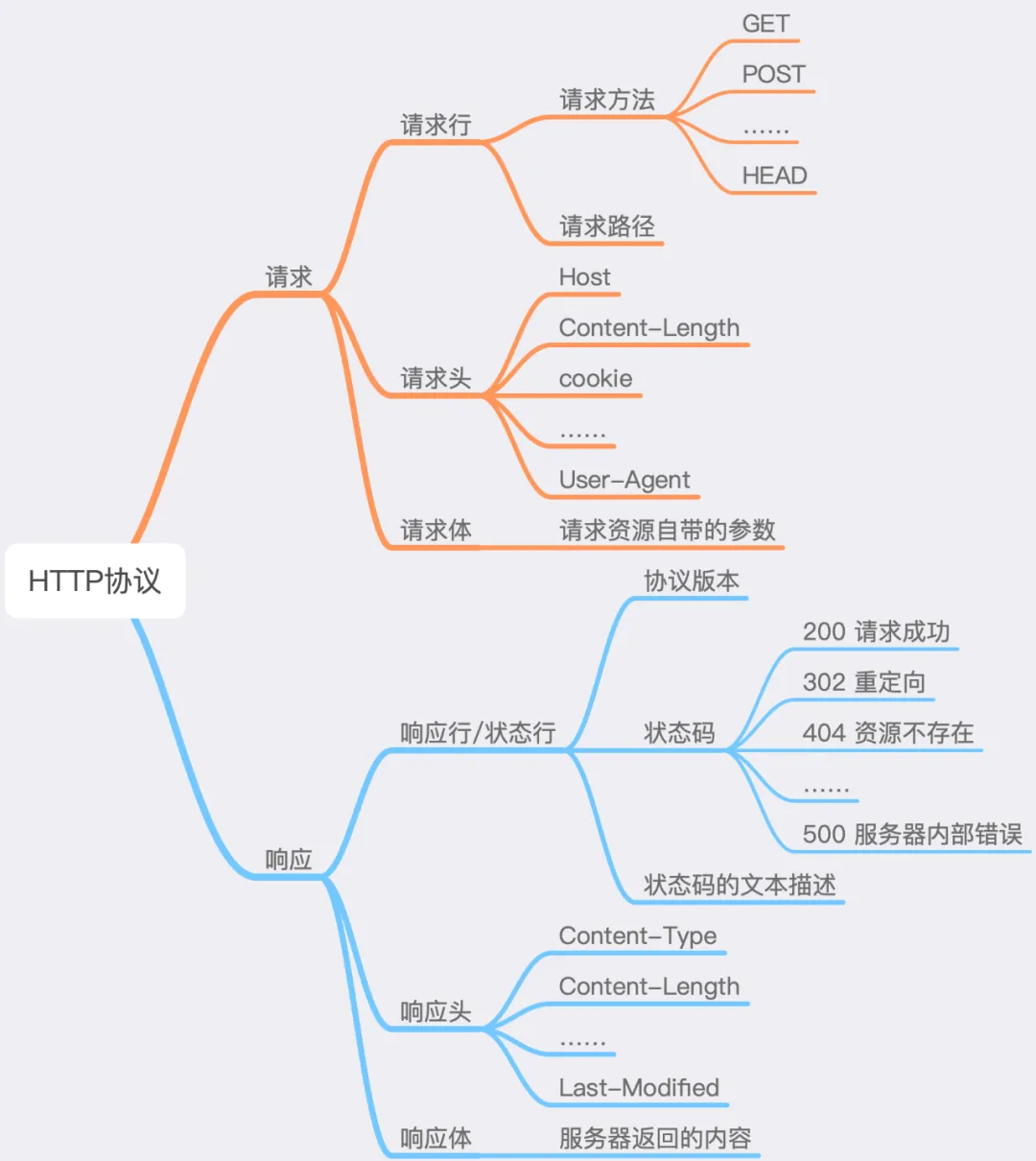
3.2 HTTP Protocol Structure

In the diagram, the <span>HTTP</span> protocol is divided into three parts, with a blank line separating the header from the body.
HTTP is a <span>Request-Response</span> protocol.

-
The client sends an HTTP request (request); -
The server receives the request, processes it, and returns a response (response); -
The client receives the response and performs further processing.
Next, let’s learn about the structure of the HTTP request and response messages.
3.3 HTTP Request Message

We can see that the <span>HTTP</span> request message is divided into three parts:
-
Request Line -
Request Header -
Request Body
3.3.1 Request Line
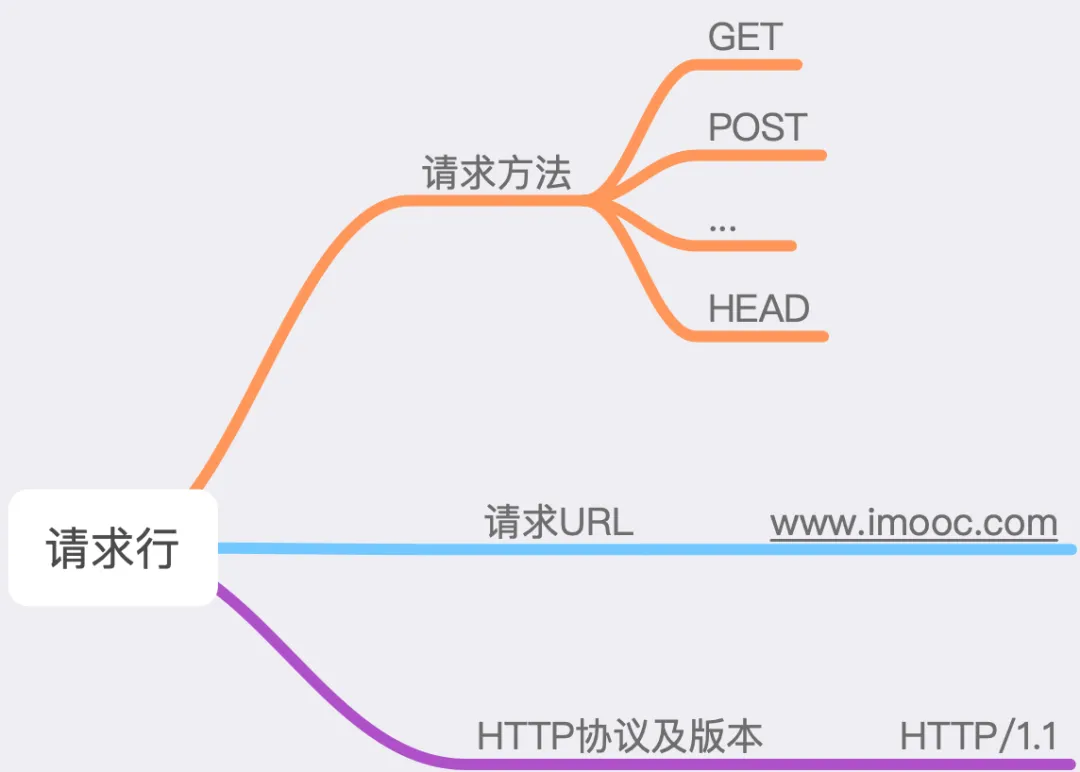
The request line consists of three parts: the request method, the requested <span>URL</span>, and the request body.
3.3.2 Request Methods
<span>HTTP/1.1</span> supports various request methods (<span>method</span>), as shown in the image below:
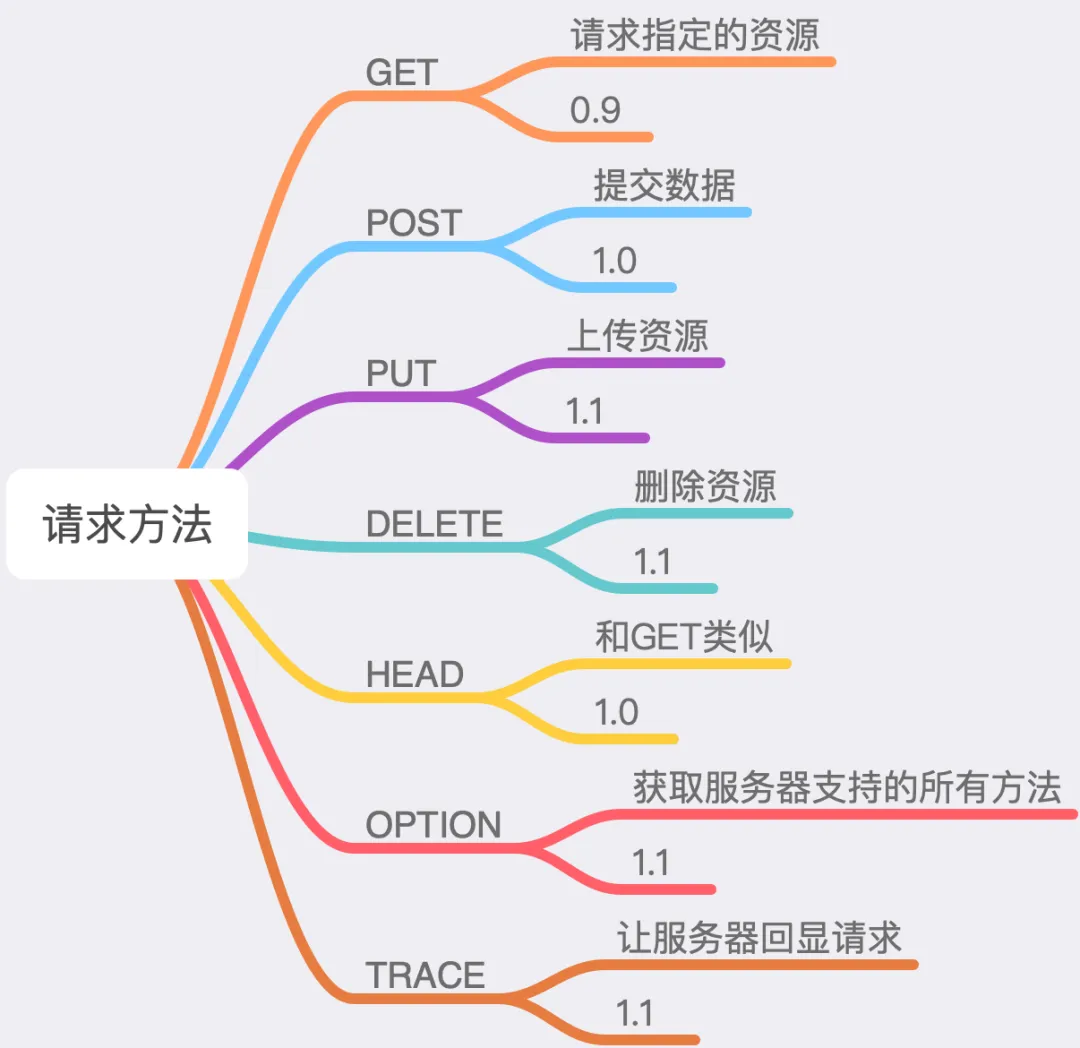
The numbers in the image indicate the minimum HTTP protocol version that supports that method. For example, from the image, we can see that <span>HTTP/0.9</span> only supports the <span>GET</span> method. In practice, the most commonly used methods are <span>GET</span> and <span>POST</span>. Let’s briefly discuss the differences between these two methods.
3.4 GET Method and POST Method
3.4.1 GET: Retrieve Resource
Generally, the GET request is used solely for data retrieval. For instance, we obtain information from a specified page and return a response.
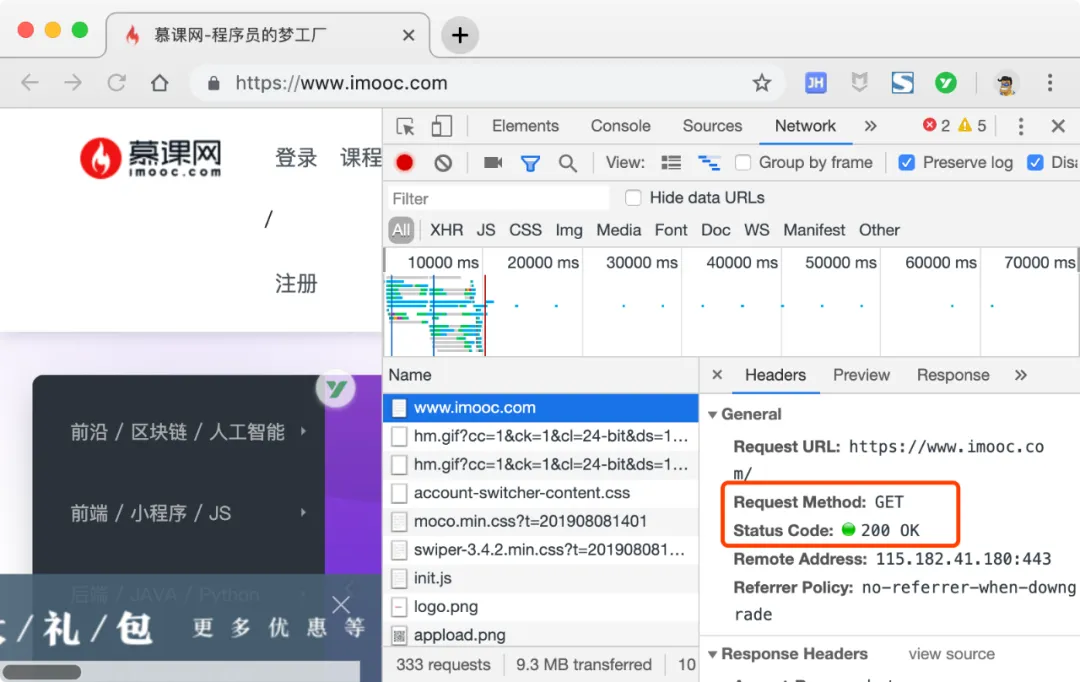
The image above shows us accessing the homepage of the Mooc website, where we can see that the <span>GET</span> method is being used.
3.4.2 POST: Request Resource
The POST request is primarily used to submit data to a specified resource, and the server processes the received data. For example, when we fill in personal information on a registration page and submit it, a <span>POST</span> request is sent to the server with the information included in the request body, which the server then processes accordingly.
Although there are many request methods in the HTTP protocol, most of the time, the GET and POST methods suffice for our needs. These are the two methods I use most frequently in my work; I rarely use others…
3.4.3 Differences Between GET and POST
Having discussed so much, what exactly are the differences between the GET and POST methods? This is an unavoidable topic, and this question often arises in interviews. Perhaps when asked this question, we can mention a point or two, such as:
-
<span>GET</span>request parameters are passed via the <span>URL</span>, while <span>POST</span>request parameters are passed via the <span>Request Body</span>; -
<span>GET</span>has no limitation on the length of parameters compared to <span>POST</span>.
There are many similar answers, but is that the reality? I must tell you a harsh truth:<span>GET</span> and <span>POST</span> actually have no difference~
HTTP is an application layer protocol that uses <span>TCP/IP</span> at the lower level, so <span>GET</span> and <span>POST</span> are fundamentally the same, and they can perform identical tasks. Let’s refute the several reasons mentioned above one by one.
-
If you wish, <span>GET</span>requests can also have a <span>Request body</span>, and you can place request parameters in the <span>Request body</span>without any issues. Similarly, you can add request parameters in the <span>POST</span>request’s <span>URL</span>. When I first joined Weibo, I found that many <span>POST</span>requests included numerous parameters in their <span>URL</span>, which confused me. After researching extensively, I realized I had misunderstood this; it was quite embarrassing~ -
<span>GET</span>and <span>POST</span>parameter length issues are not dictated by HTTP but are determined by the browser and server, and have nothing to do with the HTTP protocol.
Browsers and servers limit parameter size to save memory. In
<span>Nginx</span>, this can be controlled through<span>large_client_header_buffers</span>to limit the length of request headers~
So, if both methods are essentially the same, why do we have two different methods?
Let’s highlight this: Some clients, such as <span>CURL</span>, when the <span>POST</span> data exceeds <span>1024</span> bytes, will perform the process in two steps:
-
Send a request to the server containing <span>Expect: 100-continue</span>, inquiring whether the server is willing to accept the data. -
The server responds with <span>100 continue</span>, and then <span>curl</span>sends the actual<span>POST</span>data to the server.
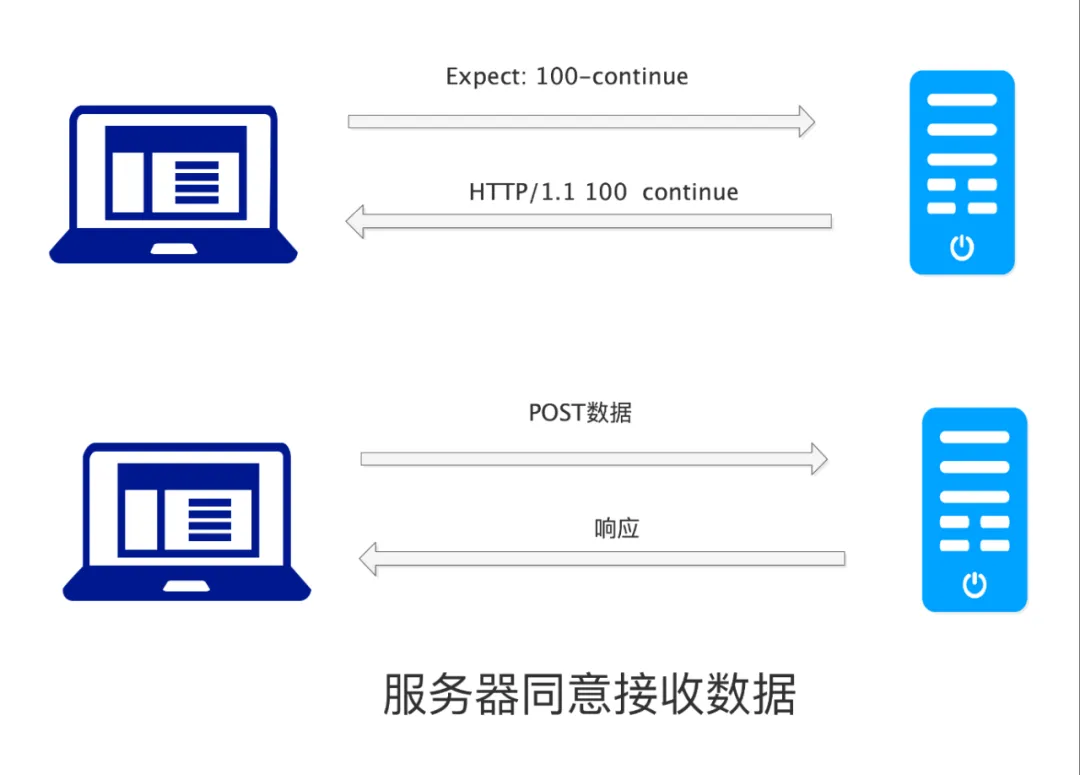
Of course, not all servers will return <span>100-continue</span>; some may return <span>417 Expectation Failed</span>, in which case the <span>POST</span> cannot continue.

At this point, do you understand the difference between
<span>GET</span>and<span>POST</span>?
3.5 Request URL
This part is the address of the resource we are requesting, and it works in conjunction with the <span>Host</span> attribute of the request header.
3.6 Protocol Version
This part indicates the version of the <span>HTTP</span> protocol currently in use. As mentioned earlier, different <span>HTTP</span> versions have different functionalities, so we must clearly state which version is being used for the current request.
3.7 Request Header
What is a request header? Let’s illustrate with an example:
After school, Teacher Wang says to Xiao Ming, “Xiao Ming, tomorrow at 8 a.m., you will go to the west gate of the school to welcome a new student, Xiao Li, who is wearing a white T-shirt and is 180 cm tall…”
In this case, welcoming Xiao Li is the HTTP message, while tomorrow at 8 a.m., the west gate of the school, wearing a white T-shirt, height 180 are additional details akin to the HTTP request header, which are extra information added to accomplish the task.
Both HTTP requests and responses contain headers, which can be classified as follows:
-
General Header Fields -
Request Header Fields -
Response Header Fields -
Entity Header Fields
Each type of header has various options; we will first introduce the first two types of message headers, and the remaining two will be covered when we learn about <span>response messages</span>.
3.8 General Header
The general header can be used in both <span>Request</span> and <span>Response</span>. Some common ones include:
| Header Field | Function |
|---|---|
| Date | Date-related information of the message |
| Cache-Control | Control caching |
| Connection | Manage connections |
Here, let’s focus on the <span>Connection</span> option. This option is used for managing <span>HTTP</span> connections, formatted as follows:
<span>Connection: keep-aliveConnection: close</span>3.9 Keep-Alive
HTTP is based on a <span>Request-Response</span> model, where the client waits for the server to respond after sending a request, and then disconnects from the server, concluding the request. Since HTTP is transmitted over <span>TCP/IP</span>, establishing a connection requires a three-way handshake and disconnection requires a four-way handshake. If there are numerous HTTP requests, each requiring a <span>three-way handshake</span> and a <span>four-way handshake</span>, it can be very time-consuming.

To address this issue, HTTP introduced the <span>keep-alive</span> mechanism. The so-called <span>keep-alive</span> allows multiple requests to be sent after the client and server establish a connection through a three-way handshake, followed by a four-way handshake for disconnection.
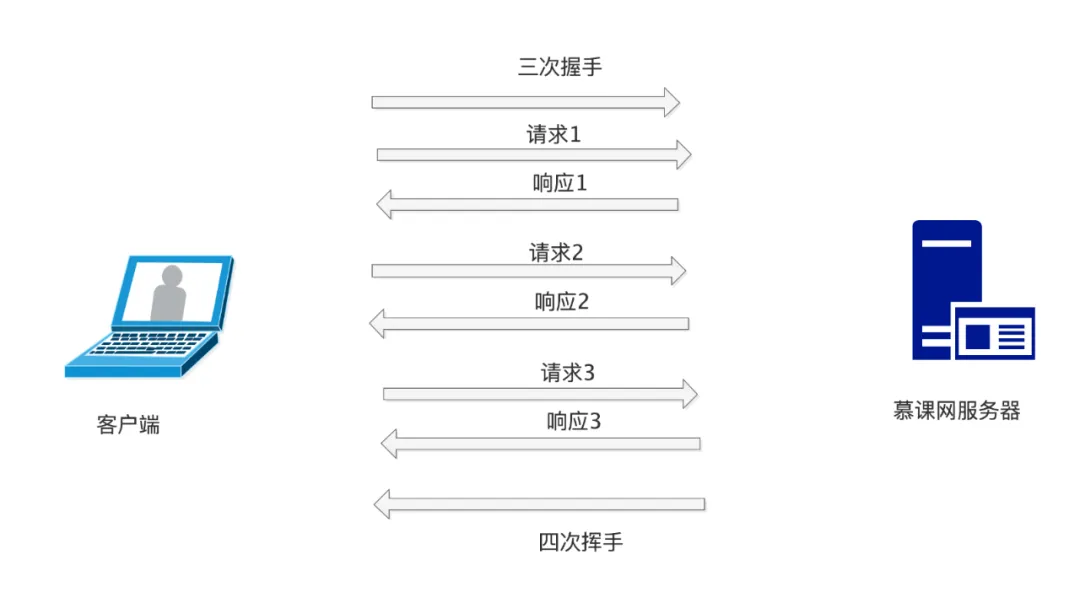
This way, we can save many handshake and disconnection steps, enhancing server performance.
The <span>connection</span> in the HTTP header completes this function. When we set <span>Connection: keep-alive</span>, it maintains the link until a certain request sets <span>Connection: close</span>. This significantly improves HTTP performance.
3.10 Request Header Fields
Request header fields are used to send additional information during an HTTP request, facilitating the server’s understanding of the request content. There are many request header fields; let’s learn a few common ones:
| Field Name | Function |
|---|---|
| Host | The server where the requested resource is located |
| If-Match | A flag used to determine if the resource meets certain conditions |
| If-Modified-Since | Send the resource when it has been updated since the content of this field |
| If-Unmodified-Since | Opposite function of <span>If-Modified-Since</span> |
| Referer | The address of the source of the current request |
| User-Agent | The type of client, such as <span>Chrome</span>, <span>IE</span>, <span>CURL</span>, etc. |
| Cookie | Information sent to the server during the request |
3.10.1 Host Field
This field indicates the domain name of the current request’s server. For instance, when we access the homepage of the Mooc website, we can see that the <span>Host</span> field is set to <span>www.imooc.com</span>.
<span>Host: www.imooc.com</span>3.10.2 If Series
We have listed three <span>If</span> series header fields. The HTTP protocol has several other <span>If</span> fields, with similar overall functions. From their names, we can see that these headers carry a conditional nature, performing actions only if certain conditions are met. These three options are designed to make HTTP more efficient and save network bandwidth.
When the server sends a response, it may include an <span>ETag</span> flag. When the client retrieves the resource again, it can include the <span>If-Match</span> field, with its value being the <span>ETag</span> returned by the server. If the server detects that the corresponding resource has changed, it will return the new resource and generate a new <span>ETag</span> to return to the client. If the resource has not changed, the server will return <span>304 Not Modified</span>, thus saving bandwidth.
<span>If-Modified-Since</span> and <span>If-Unmodified-Since</span> serve similar functions, but they compare the timestamps of the returned content.
3.10.3 Referer Field
This field indicates where the request originated. For example, when we navigate from the homepage of the Mooc website to the free course, we can find the <span>Referer</span> as follows:
<span>Referer: https://www.imooc.com/</span>This indicates that we came from the homepage of the Mooc website; this field is very effective for preventing hotlinking of images.
3.10.4 Cookie
Cookie-related questions often arise in interviews. So, what is a <span>Cookie</span>? Before explaining this, let’s understand a concept: the HTTP protocol is a stateless protocol. What does a stateless protocol mean? Let’s take a look at the following image:
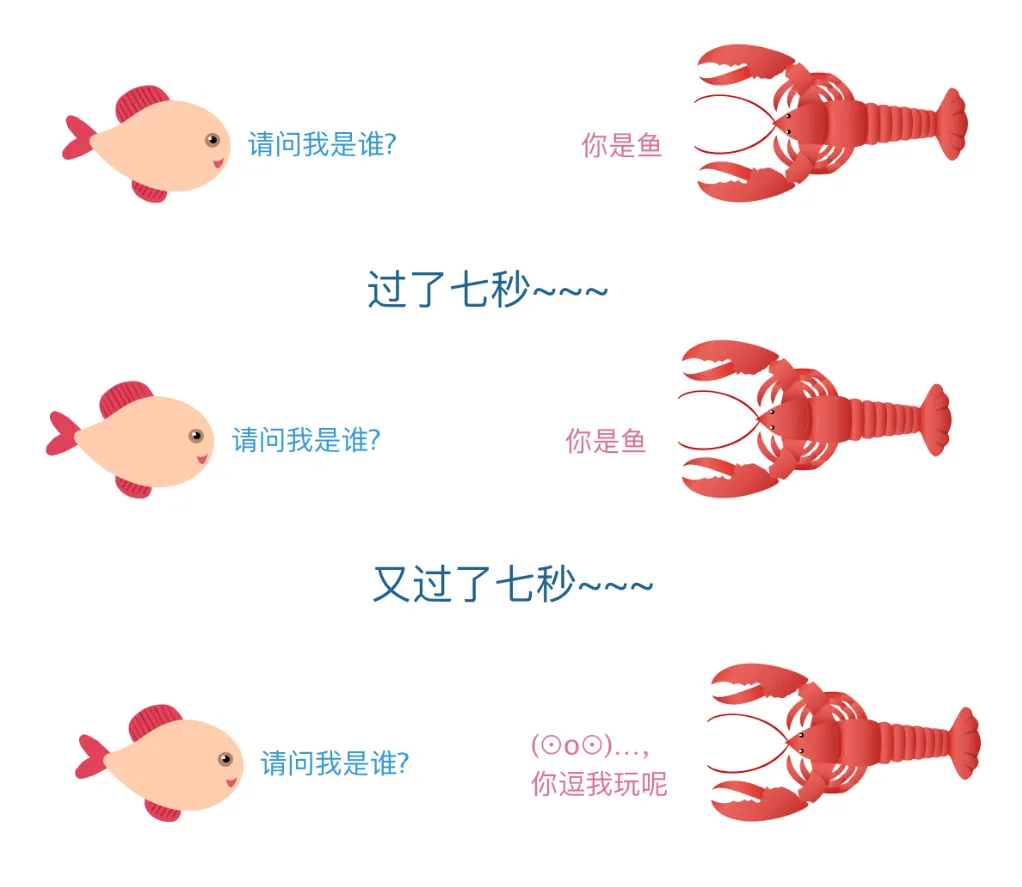
Legend has it that fish have a memory span of only seven seconds, allowing them to happily swim around every day, endlessly…
If we compare fish to the HTTP protocol, it would be the happiest protocol in the world because HTTP has no memory~~. The stateless nature of HTTP means that it does not retain any state information; each request is independent and has no relation to other requests.
For instance, when we log into the Mooc website on the first page, when we open the second page of the Mooc website, HTTP does not remember that we are already logged in.
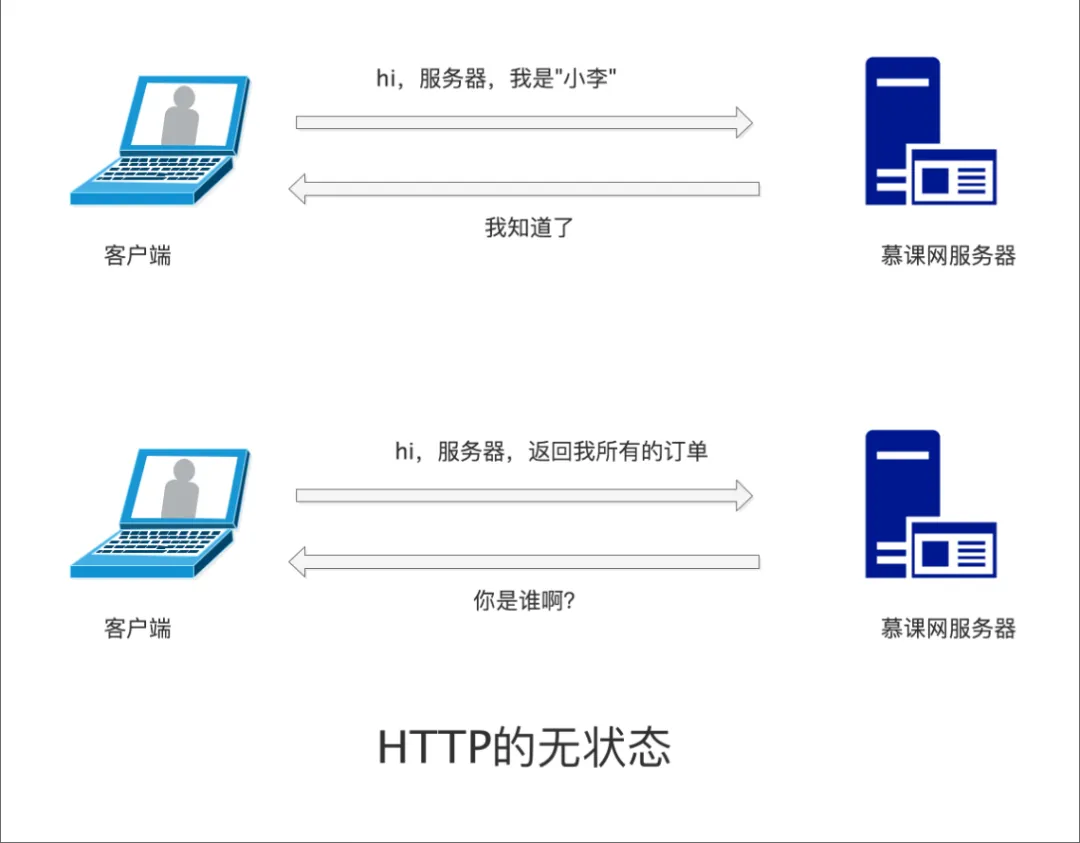
To solve this issue, HTTP introduced the <span>cookie</span> and <span>session</span> mechanisms. Each time an HTTP request is made, the <span>cookie</span> is included, allowing the server to identify the user in subsequent requests.
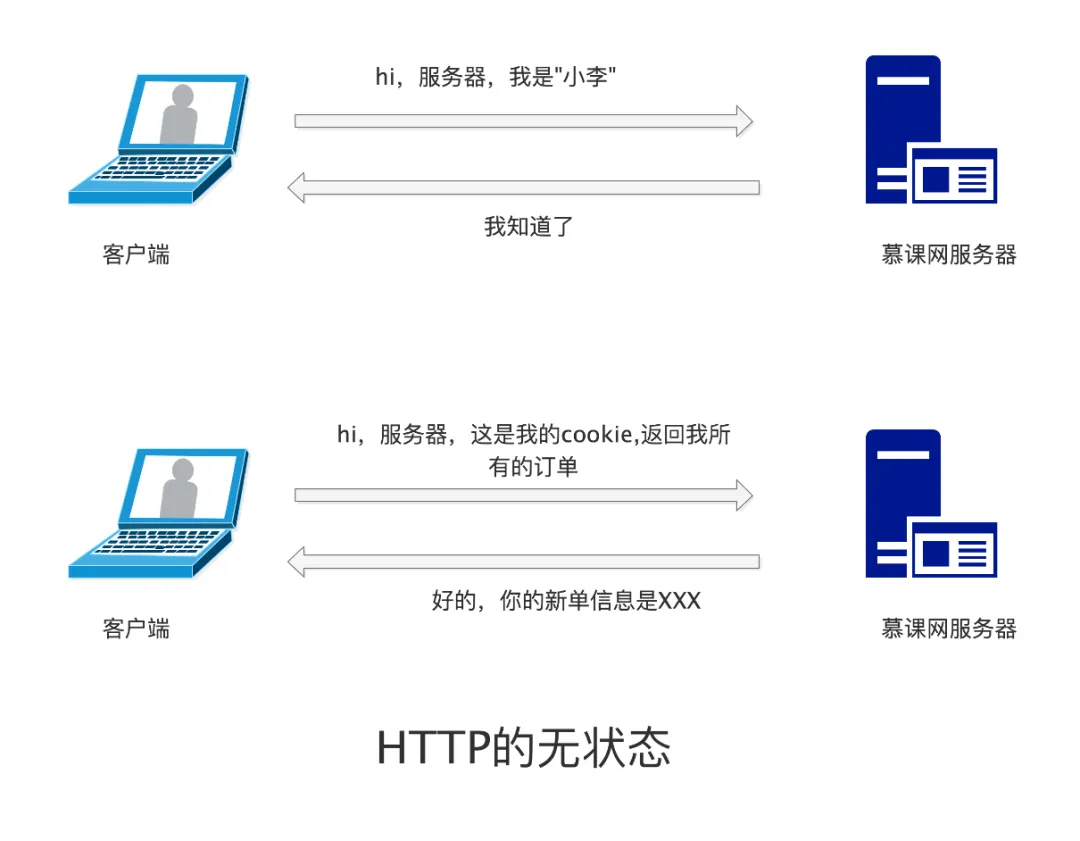
However, since <span>cookie</span> is client-stored information, it can easily be tampered with. Therefore, HTTP introduced the <span>session</span> mechanism. <span>session</span> is server-stored information, serving a similar purpose to <span>cookie</span>, both used to retain state information.
Now that we have explained the concept of <span>Cookie</span>, is it easier to understand?
An HTTP cookie (web cookie, browser cookie) is a small piece of data that a server sends to the user’s web browser. The browser may store it and send it back with the next request to the same server. Typically, it’s used to tell if two requests came from the same browser — keeping a user logged-in, for example. It remembers stateful information for the stateless HTTP protocol.
— This explanation is sourced from MDN regarding Cookies.
Here, I will translate it with my limited English level:
<span>Cookie is a piece of data sent from the server to the client. The client can store this data and include it in subsequent requests. Typically, cookies are used for user login and similar operations. Cookies make the stateless HTTP stateful.</span>3.10.5 Request Body
This is where the actual work happens; the content here is custom for each request~~. For instance, when we register, typically when we click the register button, a <span>POST</span> request is sent, and the request body includes our name, password, email, and other personal information.
3.11 HTTP Response Message

As we can see, the response message is also divided into three parts:
-
Status Line -
Response Header -
Response Body
3.11.2 Status Line
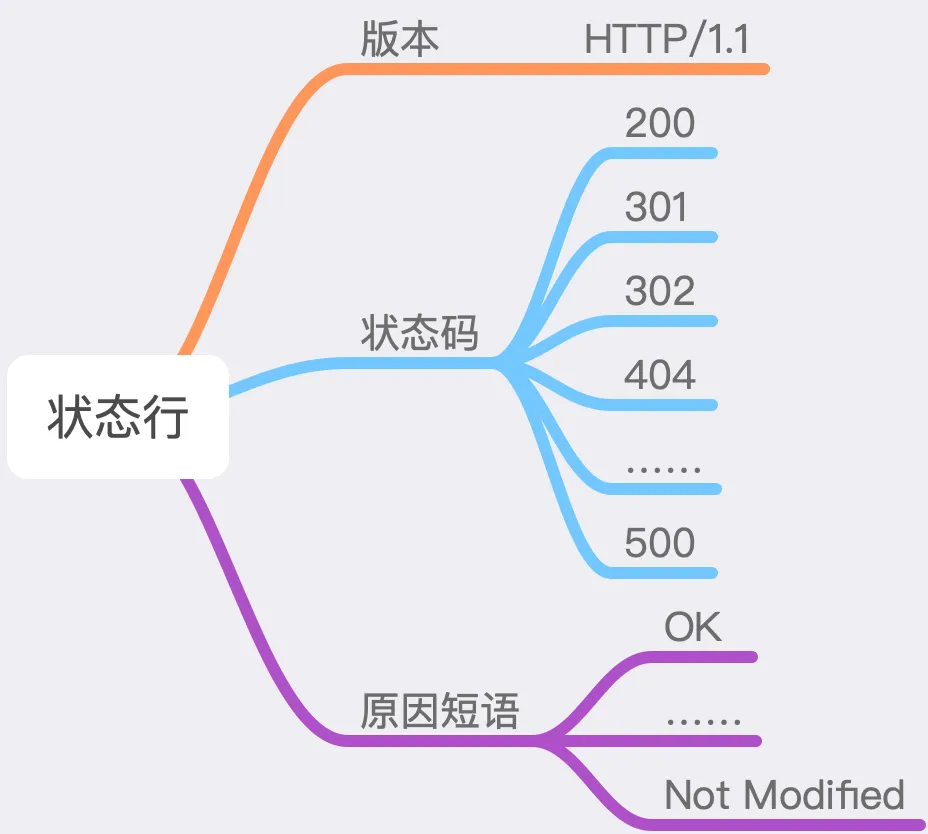
The status line consists of three parts: the <span>HTTP</span> version, status code, and reason phrase.
3.11.3 HTTP Version
The current HTTP version number in use, such as <span>HTTP/1.1</span>
3.11.4 Status Code and Reason Phrase

The status code is a number designed for computers, while the reason phrase is a human-readable text corresponding to the status code. In the <span>HTTP</span> protocol, status codes are categorized into five groups, totaling around 60 types. Below are a few commonly encountered ones:
-
200: This is frequently encountered, indicating that the current request was successful; -
301: Indicates that the requested resource has been permanently moved to another location; the response’s <span>Location</span>header should contain the new address of the resource, and the client should retrieve the resource from the new address; -
302: Indicates that the requested resource has been temporarily moved to another location; the response’s <span>Location</span>header should contain the new address; -
304: If the request header includes options such as <span>If-Modified-Since</span>, and the server finds that the current requested resource does not meet the<span>If-Modified-Since</span>requirements, it will return<span>304</span>, indicating that the resource has not changed and does not need to be requested again; -
404: This is likely the most familiar status code, indicating that the current resource does not exist; -
413: When the <span>POST</span>data is too large,<span>Nginx</span>will return this status code, with the reason phrase being<span>Request Entity Too Large</span>; -
500: This error indicates that the server encountered an error, such as a <span>bug</span>in our code.
3.11.5 Response Header
We discussed general header fields and request header fields in the request header section; now let’s look at the remaining two types of header fields.
3.11.6 Response Header Fields
Response header fields are used in the message returned from the server to the client, and there are many of them. Let’s cover a few common ones.
| Field Name | Function |
|---|---|
| Accept-Ranges | Indicates whether the server supports range requests |
| Location | Used in conjunction with <span>301</span> and <span>302</span> status codes to indicate that the resource location has changed |
| Etag | Resource identifier |
3.11.6.1 Accept-Ranges
This field indicates whether the server supports range requests, and its value indicates the unit of the range request.
Format:
<span>1) Accept-Ranges: bytes2) Accept-Ranges: none</span>3.11.6.2 Etag
The server calculates a value for the returned content, such as the <span>MD5</span> of the returned file, which identifies the current returned content. The client can use this value in conjunction with the <span>If-Match</span> request header to effectively reduce network bandwidth.
3.11.7 Entity Header Fields
Entity header fields can be used in both request and response messages to indicate certain characteristics of the entity.
| Field Name | Function |
|---|---|
| Content-Length | Indicates the size of the entity in bytes |
| Content-Range | Used for range requests |
| Content-Type | Indicates the type of the entity |
| Last-Modified | Last modification time |
3.11.7.1 Content-Type
This field indicates the type of the entity, which can vary widely.
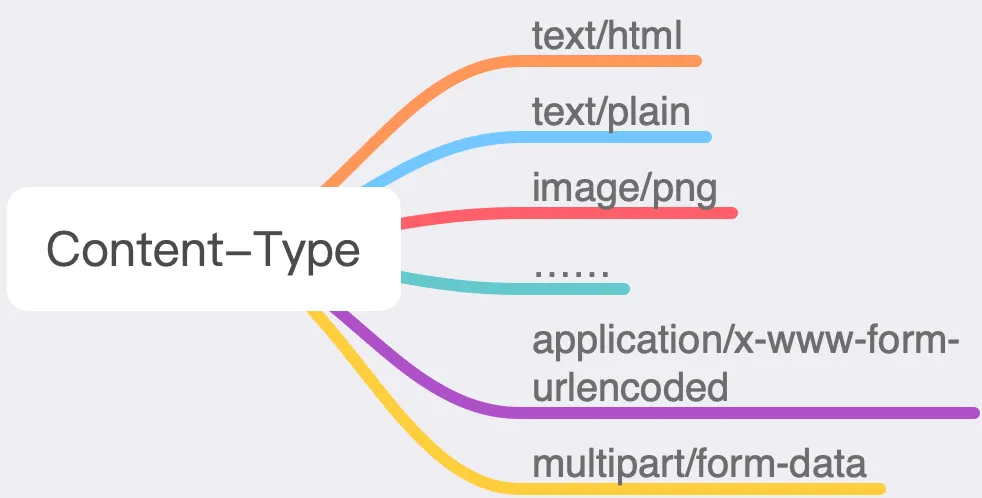
However, we typically use only a few of them:
-
application/x-www-form-urlencoded: The default encoding method for <span>GET</span>and <span>POST</span>requests, where all data is transformed into key-value pairs, such as <span>key1=value1&key2=value2</span>. -
multipart/form-data: This format must be used when uploading resources.
3.11.7.2 Content-Length
The value of this field represents the length of the entity, measured in bytes.
3.11.7.3 Content-Range
This field is used in conjunction with the <span>Range</span> request for functions like resumable downloads. For instance, during downloading, multiple processes can be used to download different parts of a file, which are then combined into one file, speeding up the download process.
This
<span>entity</span>can be quite perplexing; in English, it is called<span>Entity</span>. My personal understanding is that it refers to the<span>body</span>data of the request or response.
3.11.8 Response Body
This part is the main body of the response~~
Source: 5G Communication
Reviewed by: Zhao Lixin
