Date : December 25, 2021
Total Words : 4255 words
Author’s Note:
A Brief Introduction
What is a Compiler?
|
|
|
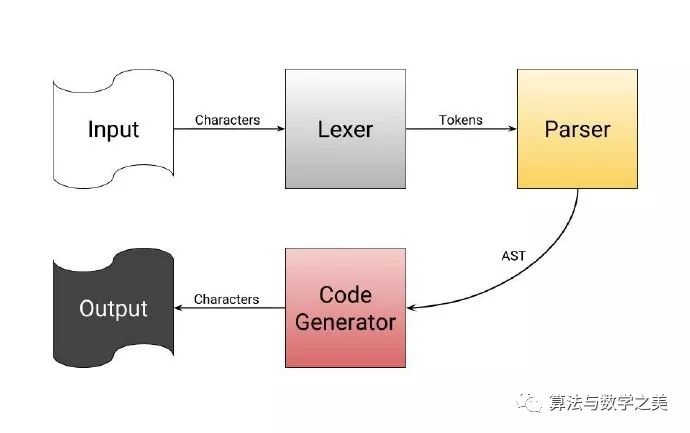
What Does a Compiler Do?
-
Read individual tokens from the source code you provide. -
Classify these tokens into words, numbers, symbols, and operators. -
Use pattern matching to identify operators from the classified tokens, clarify what operations those operators want to perform, and produce an operator tree (expression tree). -
The final step traverses all operators in the expression tree to produce the corresponding binary data.
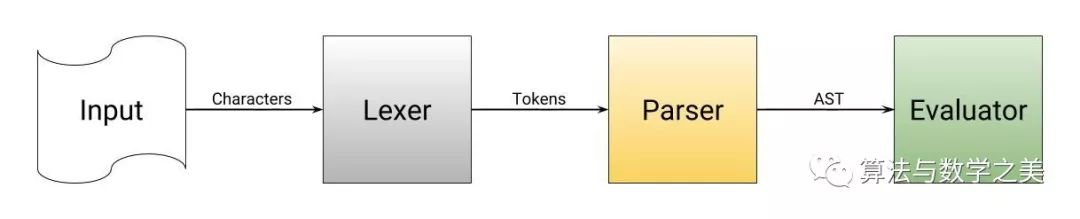
What is an Interpreter?
1. Lexical Analysis
<span>2+2</span> – in fact, this expression only has three tokens: one number:<span>2</span>, one plus sign, and another number:<span>2</span>.<span>12+3</span>: it will read the characters <span>1</span>, <span>2</span>, <span>+</span>, and <span>3</span>. We have split these characters, but now we must combine them; this is one of the main tasks of the tokenizer. For example, we have two separate characters <span>1</span> and <span>2</span>, but we need to put them together and parse them as an integer. As for <span>+</span>, it also needs to be recognized as a plus sign, not its character value – the character value is 43.|
|
|
2. Parsing
<span>int a = 3</span> and <span>a: int = 3</span> differ in how the parser processes them. The parser determines how the syntax is structured externally. It ensures that parentheses and braces are balanced in number, each statement ends with a semicolon, and each function has a name. When tokens do not conform to the expected patterns, the parser knows that the order of the tokens is incorrect.<span>12+3</span> :|
|
|
<span>expr</span> parser since it relates directly to everything at the top level. The only valid input must be any number, plus, or minus, followed by any number.<span>expr</span> requires an <span>additive_expr</span>, which mainly appears in addition and subtraction expressions.<span>additive_expr</span> first needs a <span>term</span> (a number), followed by a plus or minus, and finally another <span>term</span>.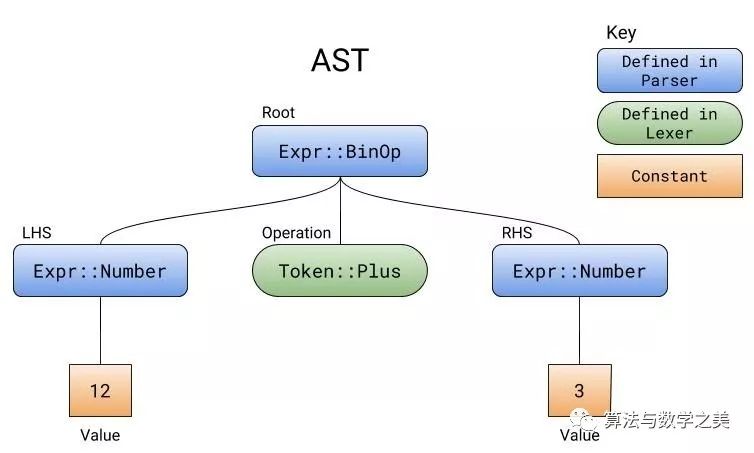
<span>// BEGIN PARSER //</span> and <span>// END PARSER //</span>.|
|
|
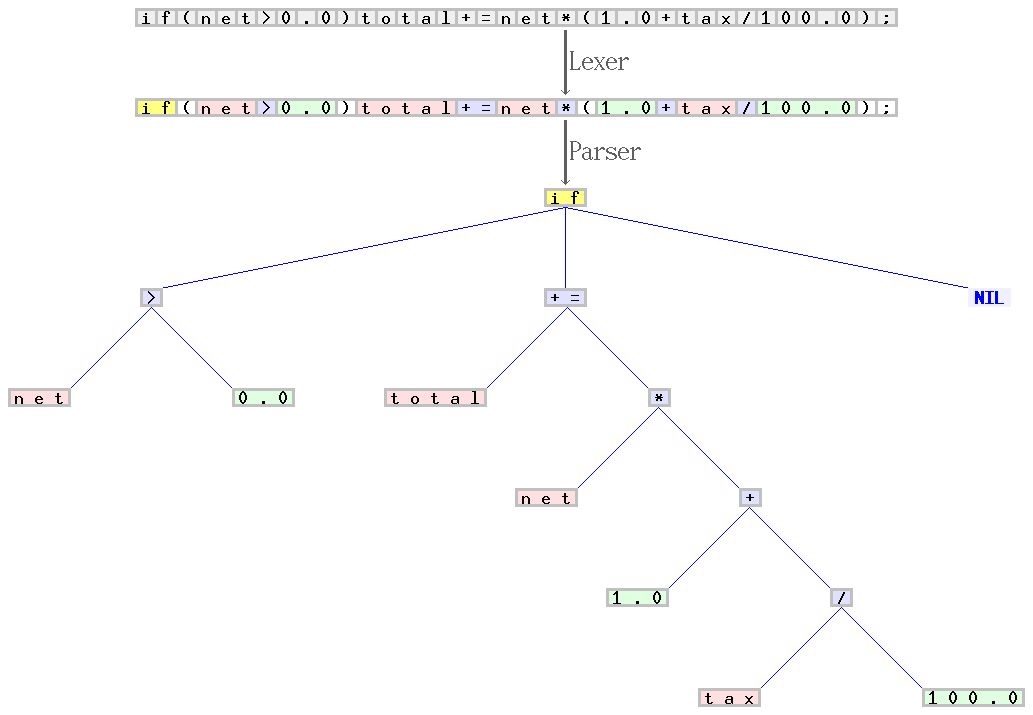
A parser designed for C language syntax (also known as a lexical analyzer) and parser example. From the character sequence beginning with “if(net>0.0)total+=net(1.0+tax/100.0);”, the scanner forms a series of tokens and categorizes them as identifiers, reserved words, numbers, or operators. The latter sequence is converted into a syntax tree by the parser, which is then processed in stages by other parts of the compiler. The scanner and parser handle the rules and context-free parts of C syntax, respectively. Quoted from: Jochen Burghardt. Source.
3. Code Generation
<span>-O</span> )<span>.s</span><span> or </span><code><span>.asm</span><span>). Then this file is passed to the assembler, which is the compiler for assembly language, which generates the corresponding binary code. After that, this binary code is written to a new object file (</span><code><span>.o</span><span>). </span>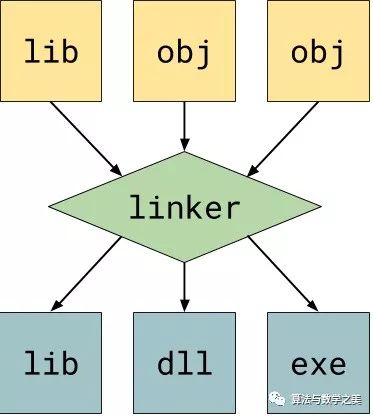
Conclusion
— THE END —
