
AI chips can be categorized based on their application scenarios into cloud AI training and inference, edge AI inference, and terminal AI inference. In our article on the Top 10 Domestic AI Chips, we listed the cloud AI training and inference chips from 10 domestic AI chip companies. This article will focus on edge and terminal AI chips.
Although edge AI chips are not as powerful and technologically advanced as cloud AI chips, they have unique advantages that are irreplaceable, as follows:
1. Data security and privacy protection — If personal and commercial data can be processed locally without needing to be transmitted to the cloud, the risk of sensitive data being stolen or leaked can be reduced.
2. Usability in poor network conditions — Some applications may lack network connectivity, or the network quality may be poor or slow. In such cases, edge AI chips can “process” data on-site, enabling many functions and tasks that were previously impossible. For example, AI chips integrated with vision processing units (VPUs) can efficiently analyze and preprocess digital images. Cameras equipped with these AI chips can perform real-time data analysis, only transmitting relevant data to the cloud while ignoring unnecessary data, thus reducing storage and bandwidth requirements.
3. Reduced power consumption — The power consumption of edge AI chips is significantly lower than that of cloud AI chips, allowing for AI computations to be performed with extremely low power in many battery-powered devices.
4. Low-latency data transmission — Executing AI processing directly on devices using edge AI chips can reduce data latency to the nanosecond level, which is crucial for the instant collection, processing, and execution of data. For example, autonomous vehicles must collect and process vast amounts of data from computer vision systems to identify objects while also gathering information from sensors to control vehicle operation functions. This data processing must immediately translate into driving decisions (such as steering, braking, or accelerating) to ensure safe operation.
5. Low-cost deployment — Edge and terminal devices typically have large installation volumes, and the AI chips embedded in such devices need to have lower power consumption and costs than cloud AI chips to enable widespread deployment of AI functionalities.
According to a report by Deloitte on edge AI chips, the market size for AI chips (including edge and cloud) is expected to grow from approximately $6 billion in 2018 to $90 billion by 2025, with a compound annual growth rate of 45% during this period. The consulting firm estimates that in 2020, the number of AI chips or AI acceleration cores used in edge and terminal devices will be about 750 million, equivalent to approximately $2.6 billion. By 2024, the shipment of edge AI chips is expected to increase to 1.5 billion units, with an annual growth rate of at least 20%, far exceeding the overall growth rate of the global semiconductor market (around 9%).
Where are edge AI chips primarily applied in edge devices and terminals? The following image shows the main application carriers of edge AI, including consumer electronics like smartphones, enterprise-level and industrial devices, telecommunications equipment, data centers, and enterprise-level servers.
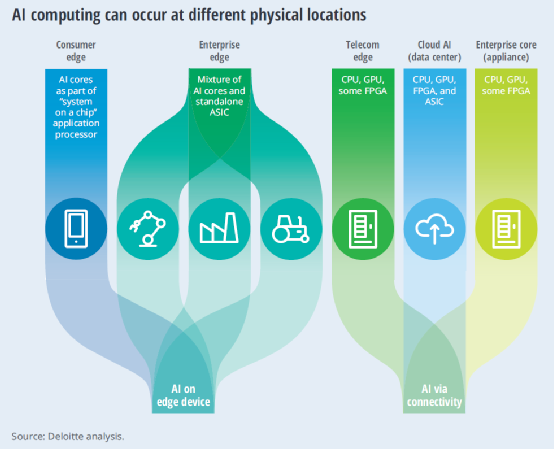
Currently, edge AI chips are mainly found in consumer electronics, with high-performance smartphones accounting for 70% of the consumer application edge AI chip market. Of course, within lightweight smartphones, edge AI may not exist as a separate chip but rather as an AI processor IP integrated into the smartphone’s main application processor (AP). Most mainstream smartphones have some degree of AI functionality, such as screen unlocking, facial recognition, image processing, and photography effects. However, while smartphone shipments are high, the AI functionalities integrated into APs are controlled by only a few major players (Apple, Samsung, Huawei, and mobile AP suppliers like Qualcomm, MediaTek, and UNISOC), leaving most AI chip startups far behind.
However, edge AI chips are increasingly being applied in non-consumer devices and scenarios, such as smart security, ADAS/autonomous driving, smart home, wearable smart devices, and AI applications in commercial and industrial settings (smart transportation, smart cities, factory machine vision, robotics, and AGVs). These emerging AIoT and industrial IoT application scenarios present more opportunities for numerous edge AI chip design companies, and venture capitalists have sensed the huge business opportunities here. Therefore, both globally and domestically, more and more AI chip startups are receiving funding. (For more information on the funding status of domestic AI chip startups, please pay attention to the subsequent research and analysis reports on domestic AI chip manufacturers published by AspenCore).
Top 15 Domestic Edge/Terminal AI Chips
The AspenCore analyst team has selected 15 domestic edge/terminal AI chips from 15 domestic AI chip manufacturers, and we invite everyone to vote for their favorite domestic edge AI chip at the end of the article. These companies include: Rockchip, Allwinner, Qingwei Intelligent, Coolchip, Yizhi Electronics, Shishi Technology, Jiutian Ruixin, Hangzhou Guoxin, Zhichun Technology, Aixin Yuanzhi, Shiqing Technology, Qiying Tailun, Shencong Intelligent, Lingxi Technology, and Shany Semiconductor.
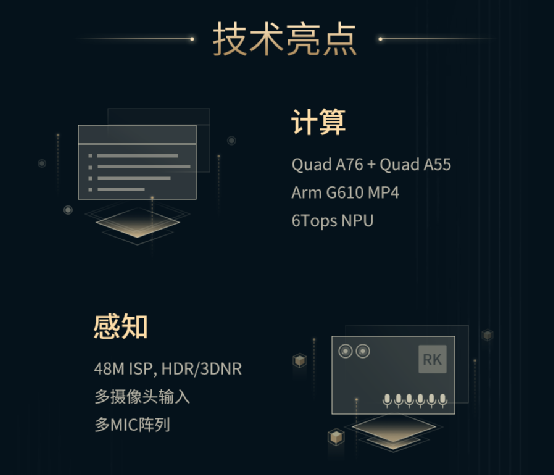
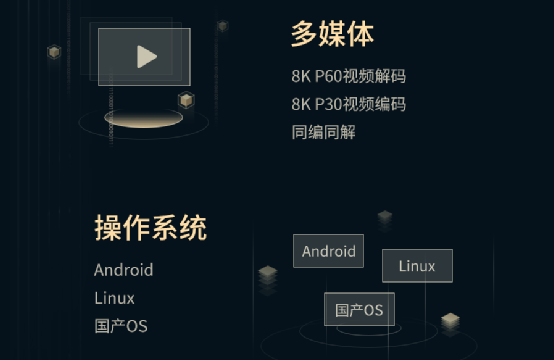
Rockchip RK3588 AIoT Chip



Allwinner V535 Intelligent Driving Vision Processing Chip
The V535 is a new generation dedicated processor developed by Allwinner Technology, integrating image video processing and AI vision into a high-performance, high-integration, and high-stability industrial-grade chip. The V535 achieves multiple breakthrough innovations and optimizations based on customer needs, capable of real-time encoding and decoding of multiple images while supporting AI (such as vehicle and human) detection and recognition functions.

Core technologies include:
1. Efficient combination of computing power. The single-core A7 at 1.2GHz is paired with a maximum of 0.5T professional neural network processing unit, deeply optimizing system efficiency for typical AI application scenarios while providing complete AI middleware and supporting model conversion tools to quickly adapt to customer-owned or third-party algorithms, helping customers rapidly deploy AI products.
2. High integration and expandability. It integrates a professional-grade starlight-level image processor and H265/H264 codec, capable of processing real-time camera images at a maximum level of 5 million and multi-channel time-division encoding, while supporting the external expansion of various analog high-definition camera inputs and screen output interfaces, and supporting low-power sleep wake-up, meeting the functional expansion needs of automotive driving products.
3. High-quality assurance. After rigorous reliability testing experiments such as uHast, TCT, HTOL, PCT, HTSL, etc., it meets industrial-grade working temperature of -40~85 degrees, FDPPM<200PPM, with a chip lifespan of up to 10 years.
Main products and applications: Smart driving recorders and driving behavior detection products, including in-vehicle full-blind zone AI monitoring and warning devices, driver behavior detectors, etc.
Qingwei Intelligent TX510 Smart Vision Processing Chip
The TX510 is based on a reconfigurable neural network engine (RNE) and a reconfigurable general-purpose computing engine (RCE), supporting mainstream neural networks, and enabling functions such as facial recognition, gesture recognition, and target tracking. Its peak computing power is 2 Tops, with an embedded 3D engine and a custom low-power dual ISP engine.

Performance parameters of this chip are as follows:
-
Processor core — RISC32 core, supports a maximum frequency of 400MHz, with configurable main frequency;
-
AI engine based on reconfigurable design, supporting mainstream neural networks, with computing power reaching 2 Tops;
-
3D engine — Detection distance: 0.4—2 meters; depth map resolution: 640*480@30fps, 1920*1080@5fps; accuracy: ±1mm@70cm; response time: 30ms; supports monocular and binocular structured light;
-
Image signal processing ISP — Low-power custom engine, 3A (supports user-adjustable); signal-to-noise ratio enhancement >20dB, dynamic range >120dB;
-
Video encoding — Supports H.264 encoding, with a maximum encoding rate supporting 1080P @ 30fps;
-
Facial analysis performance — Facial recognition rate >90% (false recognition rate of one in ten million), single facial recognition time <100ms, detection frame rate 30 frames/second, comparison time for a database of 100,000 faces <50ms;
-
Software development support — SDK (Software Development Kit) includes rich functionality examples; supports RTOS systems; supports C and C++ programming, with easy code portability;
-
Physical parameters — Core voltage working voltage: 0.9V; interface voltage: 1.8V 3.3V; LPDDR2 voltage: 1.2V 1.8V; package BGA 256; process: TSMC28HPC+; package size: 7mmx7mm; pin pitch: 0.4mm; operating temperature range: -40℃— 85℃.
Main applications include: Facial payment in new retail scenarios, customer flow statistics, smart cabinets, as well as smart security, smart home, and smart wearable devices.
Coolchip AR9341
The AR9341 adopts heterogeneous computing (4-core CPU, single-core CEVA XM6 DSP, 4TOPS NPU), achieving a significant 2-5 times improvement in comprehensive processing capability compared to similar products in the industry. The AR9341 integrates Coolchip’s self-developed second-generation HiFi-ISP technology, achieving industry-leading levels in 2D noise reduction, 3D noise reduction, HDR, defogging, edge enhancement, etc., while internally integrating infrared thermal imaging image enhancement technology for broader adaptability.
As a highly integrated visual AI chip, the AR9341 integrates a 4K-grade ISP, H264/265 video encoding and decoding (9M@60fps) to ensure high-quality video output, with a 100% performance improvement over the previous generation of Coolchip products. In product tests, the ISP and video encoder can interact with AI algorithms and make adaptive adjustments, further enhancing the operational efficiency of video encoding. Under the same video quality conditions, the bitrate can be reduced by more than 50%.
The AR9341 also integrates a high-performance visual DSP, which can accommodate both deep learning and traditional CV algorithms, greatly enriching the application scenarios of AI vision.

As Coolchip’s second-generation ultra-high-definition visual AI chip, AR9341 is suitable for application fields including high-end smart IPCs, automotive auxiliary driving, edge computing boxes, smart robots, etc.
Yizhi Electronics SV823 Terminal Inference AI SoC Chip
The SV823 series AI chip integrates a self-developed NPU, providing high-performance image processing and encoding/decoding capabilities, mainly applied in intelligent security scenarios. This series of chips adopts intelligent H.265+ encoding technology to reduce encoding bitrate, effectively saving hard disk space; and integrates professional security-grade ISP, supporting 2-3 frame wide dynamic fusion technology and adaptive noise reduction technology, performing excellently in backlight and low-light environments, allowing cameras to see rich details.

Meanwhile, the SV823 is equipped with Yizhi’s second-generation self-developed NPU, providing 1.0T intelligent computing power, supporting mainstream frameworks like Caffe, TensorFlow, and PyTorch, effectively reducing the maximum bandwidth consumption by 50% compared to the previous generation, allowing for efficient utilization of AI computing power, combined with deep learning AI algorithms to achieve human-vehicle detection, facial recognition, license plate recognition, high-altitude throwing, electric vehicle recognition, pet recognition, crying detection, gesture recognition, keyword recognition, etc., fully supporting the landing of applications in intelligent security, smart communities, smart homes, and smart offices.
In addition, the SV823 series can integrate 1 Gb / 2 Gb DDR3L, with high integration, adopting a streamlined QFN128 package, suitable for smart network cameras, smart facial access control intercoms, smart USB cameras, video conferencing, etc.
Shishi Technology Speck Series “Sensor-Compute Integrated” Dynamic Vision Intelligent SoC
The SynSense Shishi Technology “Sensor-Compute Integrated” dynamic vision intelligent SoC — Speck serves as a full-stack solution targeting edge endpoints, achieving intelligent visual sensor integration with brain-like technology while significantly reducing solution costs. There are few alternative technological solutions, allowing for the introduction of brain-like technology solutions into numerous application scenarios, empowering edge endpoint application areas.
Real-time visual edge computing dedicated dynamic vision intelligent SoC-Speck, integrates SynSense’s unique DYNAP-CNN AI computing core + DVS sensor array within a single SoC chip, based on brain-like perception and computation, and pure asynchronous digital circuit design, enabling pixel-level large-scale dynamic data stream real-time processing, providing a complete solution for sub-milliwatt level visual edge AI computation.
Performance parameters of this chip are as follows:
-
Number of neurons: 300,000 to 1 million
-
Integration level: 19,800 neurons/mm2
-
Power consumption: can be less than 1mW
-
Advanced algorithms: enhancement of deep learning networks, rich support for sCNN algorithms
-
Ultra-low latency: end-to-end response <5mS, response recognition speed improvement by 10-100 times
-
Ultra-low power consumption: event-triggered computation, always-on, power consumption reduced by 100-1000 times
-
Privacy protection: visual application processing based on pixel data, better protecting privacy

SynSense’s brain-like technology spans brain-like perception and brain-like computation, applicable for real-time visual processing, biological signal, body signal real-time monitoring processing, as well as speech recognition and processing. Main applications: targeting edge-side perception and computation, suitable for gesture control, behavior detection, fall detection, high-speed obstacle avoidance, etc., primarily applicable in smart homes, smart toys, smart transportation, smart cockpits, drones, etc.
Jiutian Ruixin ADA200 “Sensor-Compute Integrated” Chip
Jiutian Ruixin’s independently innovative “sensor-compute integrated” chip architecture consists of ASP (analog feature preprocessing) + ADA (analog-digital hybrid signal in-memory computation based on 6T SRAM). ASP resembles the analog version of DSP (digital signal processing), allowing for direct signal feature analysis and extraction at the analog signal end; this can effectively extract useful signals before ADC, removing redundant signals, significantly reducing the workload of ADC, thus achieving low power consumption and high-efficiency computation. ADA200 is a multi-sensor chip fusion processing chip based on this sensor-compute integrated chip architecture, capable of fusion processing of sound, vision, and other temporal signal class sensors under ultra-low power consumption (below 1mW), widely applicable in smartphones, wearables, smart homes, industrial, medical, and other scenarios requiring low power consumption and high energy efficiency.

Performance parameters of this chip: energy efficiency ratio reaches 20TOPs/W; peak power consumption < 1mW, suitable for power-sensitive applications; analog-digital hybrid signal in-memory computation architecture can achieve true unsigned 8X8 bit operations, ensuring high precision while meeting computing power demands; extremely simplified peripheral circuits ensure chip area <3*3mm, suitable for applications sensitive to volume in wearables.
Main applications: Industrial field — sound anomaly triggering under AON wake-up; security field — human shape detection triggering under AON; consumer field — face wake-up in personal devices (smartphones, smartwatches), image recognition; XR eye tracking, visual recognition; robotics, autonomous driving field: visual assistance systems.
Hangzhou Guoxin GX8002 Low-Power AI Voice Interaction Chip
GX8002, in addition to the built-in upgraded second-generation neural network processor gxNPU V200, also features a self-developed hardware VAD module. Unlike traditional VAD, the self-developed VAD by Guoxin has a strong filtering capability, accurately recognizing the signal of human voice initiation in various complex environments, and the operation of VAD does not rely on the CPU, thus achieving ultra-low power consumption. The GX8002 features ultra-low power consumption, low cost, and small size, perfectly combining AI voice interaction with smart wearables.

Product performance indicators: The standby power consumption of GX8002 is only 70uW, while the operating power consumption is about 0.7mW, with an average power consumption of about 300uW; it supports voice wake-up capabilities on wearables and other devices, with a comprehensive wake-up rate exceeding 95% and a false wake-up rate of less than 1 time within 24 hours. Additionally, with the capabilities of the NPU, GX8002 can also be applied in various fields such as AI voice noise reduction, AI voiceprint recognition, AI sound event detection, AI image detection, etc., demonstrating strong scalability.
Market applications: GX8002 is a newly released AI voice interaction chip targeting the smart wearable market, and it has already been adopted in mass production by several brands of TWS headphones such as QCY, Edifier, Baidu, and iFlytek. The smart wearable market has developed rapidly in recent years, with main forms including TWS headphones, smart glasses, smart watches, and wristbands.
Zhichun Technology WTM2101 Storage-Compute Integrated SoC Chip
WTM2101 is Zhichun Technology’s first storage-compute integrated SoC chip, integrating an AI accelerator (NPU) based on in-memory computing technology (Computing-in-flash) and RISC-V CPU, enabling AI neural network inference computations at ultra-low power consumption, with computing power dozens of times higher than existing wearable computing engines, particularly suitable for intelligent voice and smart health services in wearable devices.

This chip’s package uses WLCSP (2.7×3.1mm2); power consumption: 5uA-3mA; AI computing power: 50Gops; maximum model parameters: 1.8M. Zhichun Technology’s storage-compute integrated module is based on high-density non-volatile memory, supporting up to 1.8M parameters for 8-bit quantization deep learning algorithms, capable of running 2-3 high-performance models simultaneously.
The advantages of this chip and its AI applications include: utilizing storage-compute integrated technology to achieve NN VAD and recognition of hundreds of voice command words; ultra-low power consumption for NN environmental noise reduction algorithms, health monitoring and analysis algorithms; typical working power consumption remains at the microwatt level; adopting an extremely compact WLCSP of 2.6×3.2mm, allowing for communication and control through any or several of I2C/I2S/SPI/UART interfaces; providing analog and PDM codec and bypass output for audio input, facilitating system integration and expanding sound channels.
Shiqing Technology Timesformer Intelligent Processor AT1611
The Timesformer intelligent processor AT1611 is based on the RISC-V instruction set, designed for various voice and visual algorithm needs at the edge with a DSA architecture, friendly to support DSP-type algorithms like acoustic front-end and CV, while efficiently supporting various mainstream neural network models and operators, characterized by high application adaptability, cost-effectiveness, and energy efficiency.

Accompanying the Timesformer is TimesFlow, a “one-click” neural network deployment tool supporting various mainstream AI training frameworks such as TensorFlow, PyTorch, ONNX, etc., supporting various mainstream optimization methods for neural network models, such as post-training quantization, training-aware quantization, pruning, and distillation, providing rich functionality debugging and performance analysis tools.
Performance indicators of AT1611:
-
TM500 main control processor based on RV32IMCF instruction set, 300M main frequency, supporting floating-point operations and DSP extension instructions;
-
100G high energy efficiency artificial intelligence computing power, supporting various mainstream neural network models and operators;
-
Rich on-chip storage resources: 1MB high-speed SRAM + 8M/16M PSRAM + 4M/8M Flash supporting XIP;
-
4+2 channel microphone interface, supporting analog and digital microphones, supporting stereo voice output, built-in 0.5W amplifier;
-
Complete system security solution;
-
Rich peripheral interfaces;
Main applications of this chip include: omnidirectional microphones, such as conference treasures, pick-up devices; voice intercoms, such as wireless doorbells, intercoms; voice recognition and control, etc.
Shencong Intelligent AI Dedicated Voice Chip TH1520
The TH1520 is an AI dedicated dual-core enhanced low-power DSP chip, integrating the full-link intelligent dialogue technology from Sibilichi and modular packaging. The TH1520 adapts to commonly used dual-microphone and four-microphone arrays for voice control devices, achieving efficient recognition and rapid response in far-field and complex sound field environments, with a false wake-up rate of no more than 1 time per 48 hours. Its power consumption is extremely low, with power consumption in the always-on listening phase as low as milliwatt level, and typical working scene power consumption only requires tens of milliwatts, with peak power consumption in extreme scenarios around a hundred milliwatts.
Additionally, the TH1520 has high customization capabilities, allowing for the customization of wake-up words, synthesized voices, selection of broadcast tones, and adjustment of speech rates, enhancing the interactivity. It can simultaneously support voiceprint recognition and dialect recognition. The TH1520 also features dual-mode hybrid interaction, full-duplex interaction, nearby wake-up, and multi-module collaboration, showcasing advanced natural interaction capabilities.
Performance indicators are as follows:
1. Chip features
(1) Dual-core enhanced DSP, including a custom instruction set;
(2) Flexibly configurable low-power modes;
(3) Dedicated AI voice recognition engine;
(4) Large-capacity on-chip static storage;
(5) Multi-channel audio codec, supporting up to 6 + 2 channel voice synchronous acquisition;
(6) Supports all standard audio formats, with a wide range of sampling rates;
(7) Supports mainstream interfaces: USB/SPI/UART/I2C/I2S/GPIO.
2. Algorithm features
(1) Supports up to 6+2 channel voice synchronous acquisition, with inter-channel delay less than 10ns;
(2) Voice endpoint detection, recall rate: >99%, accuracy: >90%;
(3) Voice noise reduction, eliminating steady-state and short-term steady noise, SNR gain: >15dB;
(4) Supports up to 6 mic + 2 ref voice echo cancellation, SNR gain: >40dB;
(5) Beamforming, target signal enhancement, and interference suppression, SNR gain: >15dB;
(6) Voice listening and target voice wake-up, recall rate: >95%, false wake-up rate: <1 time/48 hours;
(7) Voiceprint verification and recognition, recall rate/accuracy: >95%/>97%;
(8) Local voice recognition, wake-up recognition rate >95%.
Main applications:
This product has been implemented in three major scenarios: smart home appliances, smart office, and smart automotive fields, confirming deep cooperation with more than thirty industry-leading companies such as Midea, Hisense, Yunmi, Yadi, and Dingdingpai.
1. In the smart home direction, Shencong Intelligent’s chip solutions have covered the entire series of products including TVs, air conditioners, refrigerators, washing machines, range hoods, steam ovens, water heaters, bathroom heaters, smart mirrors, TV boxes, projectors, smart control centers, smart panels, smart speakers, heating tables, tea bar machines, smart drying racks, sweeping machines, air conditioning companions, smart sockets, smart voice remote controls, voice elevators, and smart building intercoms.
2. In the smart automotive direction, it has supported dual-zone schemes, four-zone schemes, smart screens, driving recorders, smart alarms, and external voice controllers.
3. In the smart office direction, the implemented products mainly include conference speakers, video conference soundbars, smart cloud platforms, smart commercial displays, smart tablets, smart terminals, and smart ticket machines.
Aixin Yuanzhi AX630A
The AX630A is a high-performance, high-quality, and high-energy efficiency SoC chip, whose miniaturized package and low power consumption characteristics provide a superior AI experience. Its product specifications are as follows:
-
CPU: Quad A53
-
NPU: 32Tops@int4, 8Tops@int8
-
ISP: 4K@60fps
-
Encoding/Decoding formats: H.264, H.265, video encoding 4K@60fps, video decoding 4K@120fps
-
Ethernet: Supports dual RGMII/RMII interface modes for Ethernet
-
Video output: Supports HDMI v2.0, supports 4K@60fps

Main applications: AI cameras, smart boxes, smart sports cameras, smart traffic cameras, smart automotive vision systems, AI industrial cameras, AI accelerator cards, smart vision centers, etc.
Lingxi Technology Brain-like Chip KA200
The KA200 brain-like chip developed by Lingxi Technology can simultaneously support neural network models from computer science and neuroscience, as well as support hybrid neural network computing models that fuse both, efficiently supporting convolutional pulse neural networks and new brain-like algorithms. The KA200 adopts a heterogeneous fusion multi-core and storage-compute integrated chip architecture, integrating 250,000 neurons and 25 million synapses (dense mode) on a single chip, and can expand to support 2 million neurons and 2 billion synapses for integrated computation (sparse mode), highly optimizing the execution efficiency of neural network connectivity sparsity, event sparsity, and brain simulation. Compared to typical von Neumann architecture chips, it can achieve over a hundred times improvement in computing efficiency.

Based on the theory of “brain-like computing completeness”, Lingxi Technology has developed brain-like software LynOS, supporting efficient graph optimization and fully automated compilation for deep learning, high-performance computing, machine learning, and brain-like computing algorithms, supporting the fusion of multiple algorithm models for rapid deployment of application algorithms. The self-developed training framework for deep pulse neural networks and brain simulation platform supports various brain-like neuron models, synapse models, and online learning mechanisms, efficiently supporting the dynamic simulation of biological brain neuron dynamics.
The KA200 is manufactured using a 12nm process, integrating 250,000 neurons and 25 million synapses on a single chip, and integrates 30 brain-like computing cores, supporting mixed precision computing.
Main applications: Brain science and brain simulation fields; brain-like product spatiotemporal fusion computing characteristics will have a disruptive impact on video acquisition/analysis, potentially changing the existing video surveillance processing model and providing better solutions; high-speed dynamic industrial internet market; intelligent robotics applications in multi-modal complex environments; autonomous driving with high uncertainty applications.
Qiying Tailun Intelligent Voice AI Chip CI1122

The intelligent voice AI chip CI1122 features the following functional characteristics:
-
Brain neural network processor core (BNPU): A hardware processor based on deep neural networks (DNN), enabling local collection, computation, and decision-making of voice data without relying on the network, with low latency and protecting user privacy.
-
Voice recognition: Quickly and accurately converting voice into corresponding text, achieving a recognition rate of over 97% at 5 meters in home environments, with a response time as fast as 0.2S, supporting recognition of Chinese, English, and some dialects.
-
Voiceprint recognition: Identifying individuals by listening to their voice and automatically extracting speaker voice features.
-
Natural language processing: Recognizing natural language and semantics, providing quick responses.
-
Microphone voice enhancement: Supporting single and dual microphone voice enhancement, with 360-degree omnidirectional pickup, capable of suppressing background noise outside the target voice direction, ensuring accurate voice recognition in noisy environments.
-
Echo cancellation: Achieving voice wake-up interruption functionality, with echo suppression exceeding 25dB, suitable for speakers, TVs, and other voice devices.
-
Sound source localization: Utilizing microphone arrays to determine the direction of sound sources. Currently capable of achieving 180° sound source localization with an error range of ±15°.
-
Voice synthesis: Converting text information into sound information. Currently offering over 10 voice options with natural and smooth tones.
-
Local command word self-learning: Supporting autonomous learning of voice models. In offline mode, users can customize wake-up words and command words by inputting their voice, achieving personalized self-service customization to better fit user habits.
The specifications of CI1122 are shown in the table below:
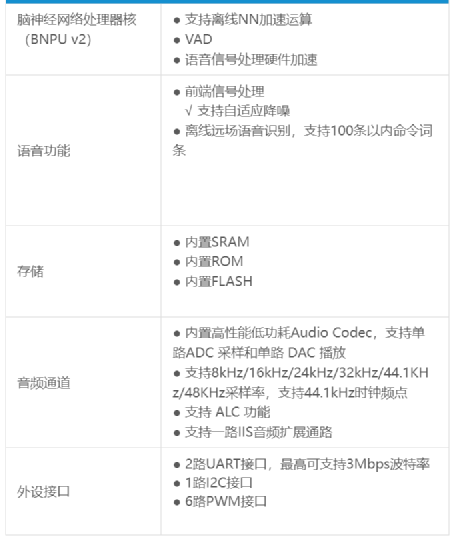
Based on this chip, the intelligent voice application solutions are suitable for smart home, home appliances, and lighting fields. In addition, its solution supports various communication data interfaces such as WiFi, BLE, Zigbee, etc., achieving recognition at distances of up to 10 meters in home environments, with recognition rates exceeding 95%.
Shany Semiconductor Zincite HEXA01
Shany Semiconductor has developed the PLRAM based on bidirectional Fowler-Nordheim tunneling, a new type of memristor technology that physically mimics the operation of neurons and synapses, enhancing AI computing power at the edge and endpoints in the IoT ecosystem. Moreover, due to the integrated characteristics of the storage-compute integrated chip itself, it can achieve the simplest embedded systems in a single chip, significantly reducing the cost of AI modules.

The Zincite HEXA01 is the company’s first product to integrate a PLRAM memristor array, capable of supporting various neural network models and widely applicable for smart control in home appliances and IoT devices. This AI chip from Shany is suitable for markets such as smartphones, smart travel, IoT, AR&VR, and data centers.
Author: Gu Zhengshu
EET Electronic Engineering Magazine Original




