
Due to changes in the public account’s push rules, please click “Read” and add a “Star” to get exciting technical shares instantly
Source from the internet, infringement will be deleted
1. Try to Use the Newest C++ Standards Whenever Possible
By 2022, C++ has been around for over 40 years. The new C++ standards actually simplify many frustrating details and provide modern approaches to improve C++ code, but it is not easy for developers to realize this.
Take memory management as an example, which is often criticized in C++. For many years, object allocation was done using the new keyword, and developers had to remember to call delete somewhere in the code. “Modern C++” solves this problem and promotes the use of smart pointers.
2. Use Namespaces to Modularize Code
Modern C++ libraries widely use namespaces to modularize codebases, utilizing a “Namespace-by-feature” approach, dividing namespaces by functionality to reflect feature sets, grouping everything related to a single feature (and only that feature) into a single namespace. This results in high cohesion and modularity for namespaces, with minimal coupling, tightly coupled projects being grouped together.
Boost is the best example of feature-based grouping, containing thousands of namespaces, each used for grouping specific features.
3. Abstraction
Data abstraction is one of the most fundamental and important features of object-oriented programming in C++. Abstraction means showing only the essential information while hiding the details; data abstraction refers to providing only the basic information about data to the outside world while hiding the background details or implementation.
Although many books, online resources, conference speakers, and experts recommend this best practice, it is still often ignored in many projects, with many class details not being hidden.
4. The Smaller the Class, the Better
Classes with multiple lines of code should be divided into smaller classes.
Refactoring a large class requires a lot of patience and may even require recreating everything from scratch. Here are some refactoring suggestions:
-
The logic in BigClass must be divided into smaller classes. These smaller classes may eventually become private classes nested within the original God Class, with instances of the God Class consisting of instances of the smaller nested classes. -
The division of smaller classes should be driven by multiple responsibilities handled by the God Class. To determine these responsibilities, it usually requires looking for a subset of methods that are strongly coupled with a subset of fields. -
If the logic contained in BigClass exceeds its state, a good option is to define one or several static classes that contain only pure static methods without static fields. Pure static methods are functions that compute results based solely on input parameters without reading or allocating any static or instance fields. The main advantage of pure static methods is ease of testing. -
First attempt to maintain the interface of BigClass and delegate calls to the newly extracted classes. Ultimately, BigClass should be a pure interface without its own logic, which can be retained for convenience or discarded in favor of using only the new classes. -
Unit tests can help: write tests for each method before extracting methods to ensure functionality is not broken.
5. Provide the Minimum Number of Methods for Each Class
A class with more than 20 methods may be difficult to understand and maintain.
A class with many methods may be a symptom of having too many responsibilities.
Perhaps the class being faced controls too many other classes in the system and has exceeded its intended logic, becoming a god object.
6. Strengthen Low Coupling
Low coupling is an ideal state where fewer changes in the application can implement a certain change in the program. In the long run, it can significantly reduce the time, effort, and costs required to modify or add new features.
Low coupling can be achieved by using abstract classes or generic classes and methods.
7. Strengthen High Cohesion
The Single Responsibility Principle states that a class should not have more than one reason to change; such classes are called cohesive classes. A higher LCOM value usually indicates poorer class cohesion. There are several LCOM metrics with a range of [0-1]. LCOM HS (HS stands for Henderson-Sellers) has a range of [0-2]. An LCOM HS value greater than 1 requires caution. Here’s how to calculate the LCOM metric:
LCOM = 1 — (sum(MF)/M*F) LCOM HS = (M — sum(MF)/F)(M-1)
Where…
-
M is the number of methods in the class (including static methods and instance methods, it also includes constructors, property getters/setters, event add/remove methods). -
F is the number of instance fields in the class. -
MF is the number of methods accessing a specific instance field. -
Sum(MF) is the sum of MF for all instance fields of the class.
The basic idea behind these formulas can be stated as follows: If all methods of a class use all its instance fields, then this class is fully cohesive, meaning sum(MF)=M*F, and then LCOM = 0 and LCOMHS = 0.
LCOMHS values greater than 1 require caution.
8. Comment Only What the Code Cannot Express
Parrot-like code comments do not provide any additional value to the reader. The codebase is often filled with noisy comments and incorrect comments, prompting programmers to ignore all comments or take active measures to hide them.
9. Avoid Duplicate Code Whenever Possible
It is well known that the existence of duplicate code negatively impacts software development and maintenance. In fact, a major drawback is that when changing instances of duplicate code to fix bugs or add new features, all corresponding code must be changed at the same time.
The most common cause of duplicate code is copy/paste operations, where similar source code appears in two or more places. Many articles, books, and websites warn against this practice, but sometimes it is not easy to put these recommendations into practice, and developers still opt for the simple solution: copy/paste.
Using appropriate tools can easily detect duplicate code from copy/paste operations; however, in some cases, cloned code can be difficult to detect.
10. Immutability Aids Multithreading Programming
Essentially, if an object’s state does not change after it is created, then that object is immutable. If an instance of a class is immutable, then that class is immutable.
Immutable objects greatly simplify concurrent programming, which is an important reason for using them. Think about why writing proper multithreaded programs is a daunting task? Because synchronizing thread access to resources (objects or other operating system resources) is very challenging. Why is synchronizing these accesses difficult? Because it is hard to ensure that multiple threads do not cause race conditions during multiple read and write accesses to multiple objects. What if there were no write accesses? In other words, what if the state of the object being accessed by the thread did not change? Then synchronization would no longer be necessary!
Another benefit of immutable classes is that they never violate the Liskov Substitution Principle (LSP); here’s the definition of LSP from Wikipedia:
The concept of Liskov’s behavioral subtypes defines the concept of substitutability of mutable objects, meaning that if S is a subtype of T, then objects of type T in a program can be replaced with objects of type S without changing any expected properties of that program (e.g., correctness).
If there are no public fields, no methods to change their internal data, and derived class methods cannot change their internal data, then the reference object class is immutable. Because the value is immutable, the same object can be referenced in all cases without the need for copy constructors or assignment operators. For this reason, it is recommended to make copy constructors and assignment operators private, or inherit from boost::noncopyable, or use the new C++ 11 feature of “explicitly defaulting and deleting special member functions”[2].
How to Strengthen Checks on These Best Practices?
CppDepend[3] provides a code query language called CQLinq[4] that allows querying the codebase like a database. Developers, designers, and architects can customize queries to easily find situations prone to bugs.
With CQLinq, it is possible to define very advanced queries by combining data from code metrics, dependencies, API usage, and other models to match situations prone to bugs.
For example, after analyzing clang source code, large classes can be detected:
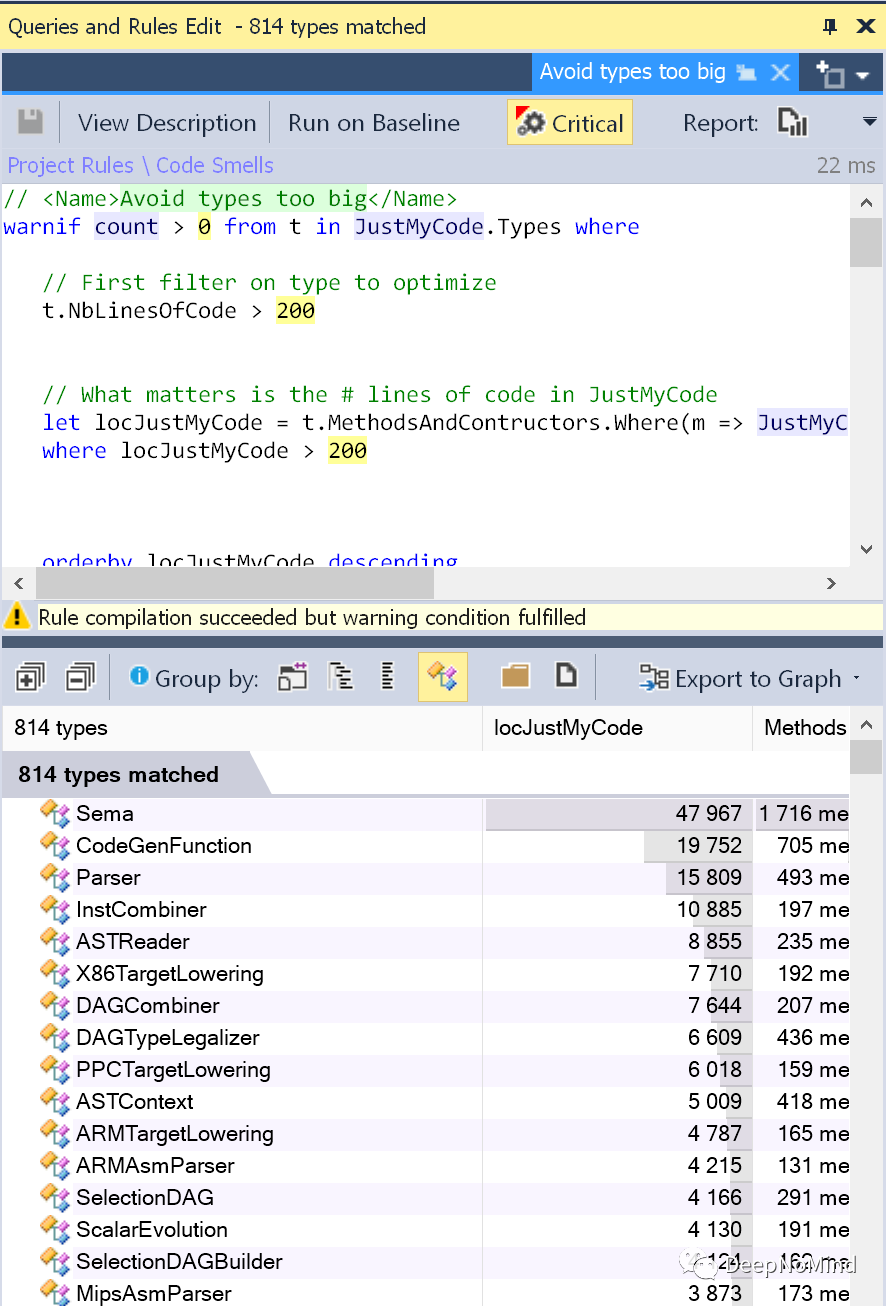
Classes with a large number of methods can be detected:
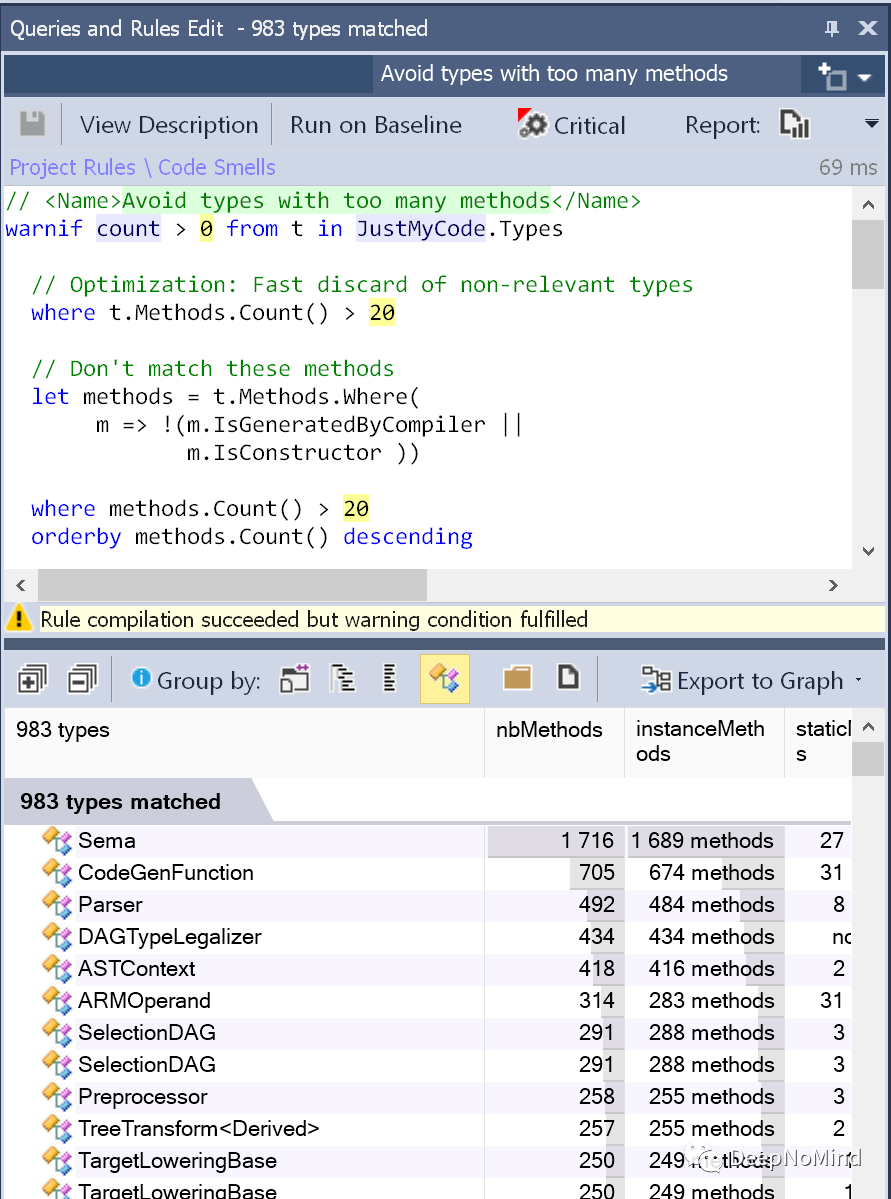
Or classes with poor cohesion can be detected:
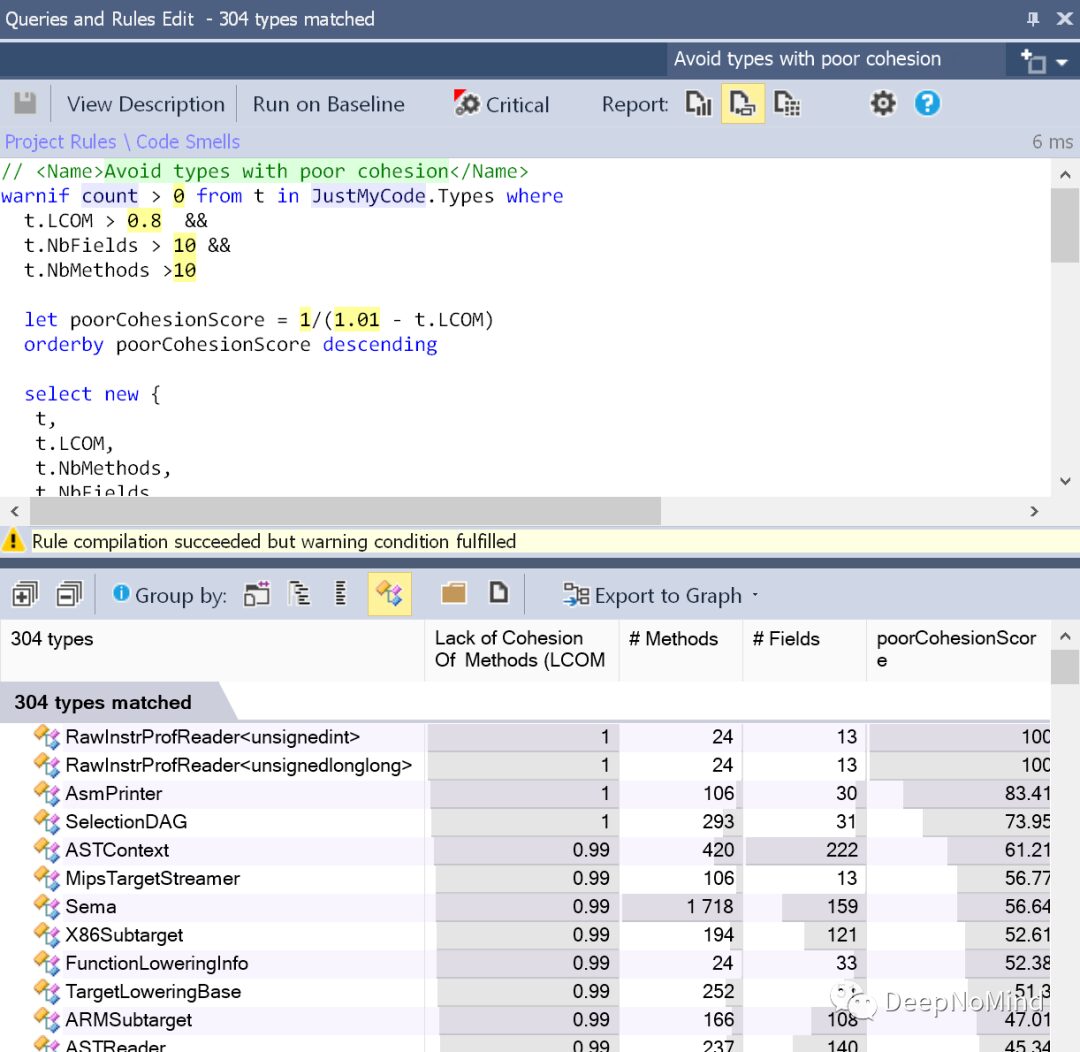
If you are over 18 years old and find learning C difficult? Want to try another programming language? Then I recommend you learn Python, currently, a Python zero-based course worth 499 yuan is available for free, limited to 10 spots!
▲ Scan the QR code - Get it for free
