Introduction

1. Introduction to Large Language Models
1. Introduction to Large Language Models
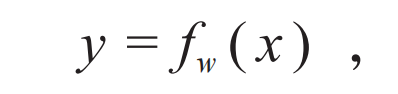

Figure 1: The language model studied by Claude Shannon in his paper on the source coding theorem.
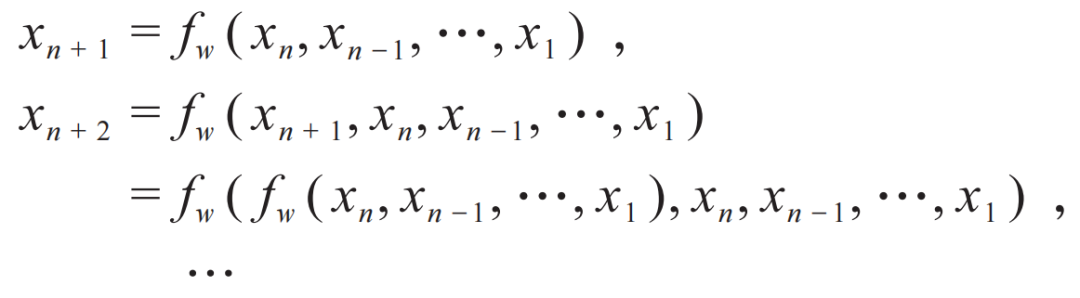
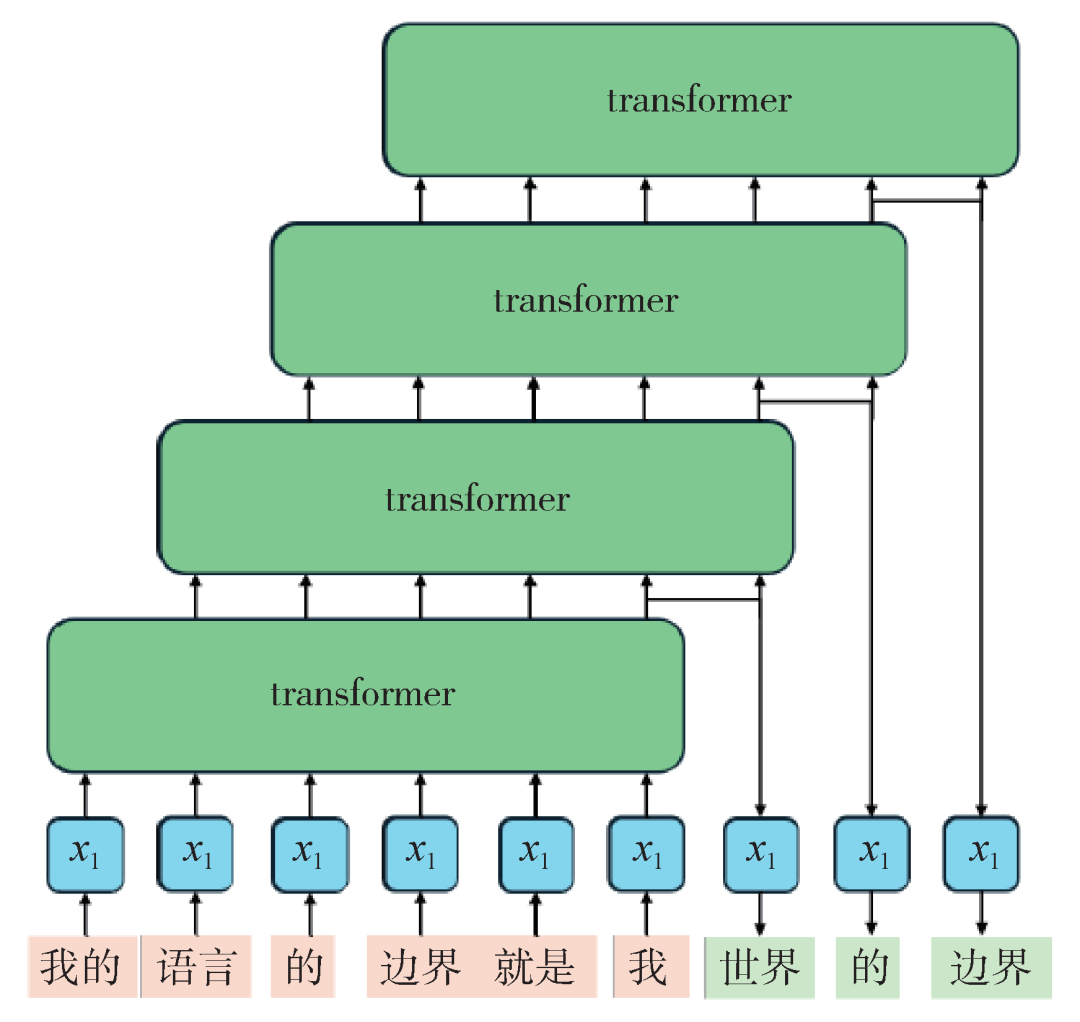
Figure 2: Schematic diagram of large language models. The input content (pink) undergoes calculations to predict the next word (green), iterating this process.
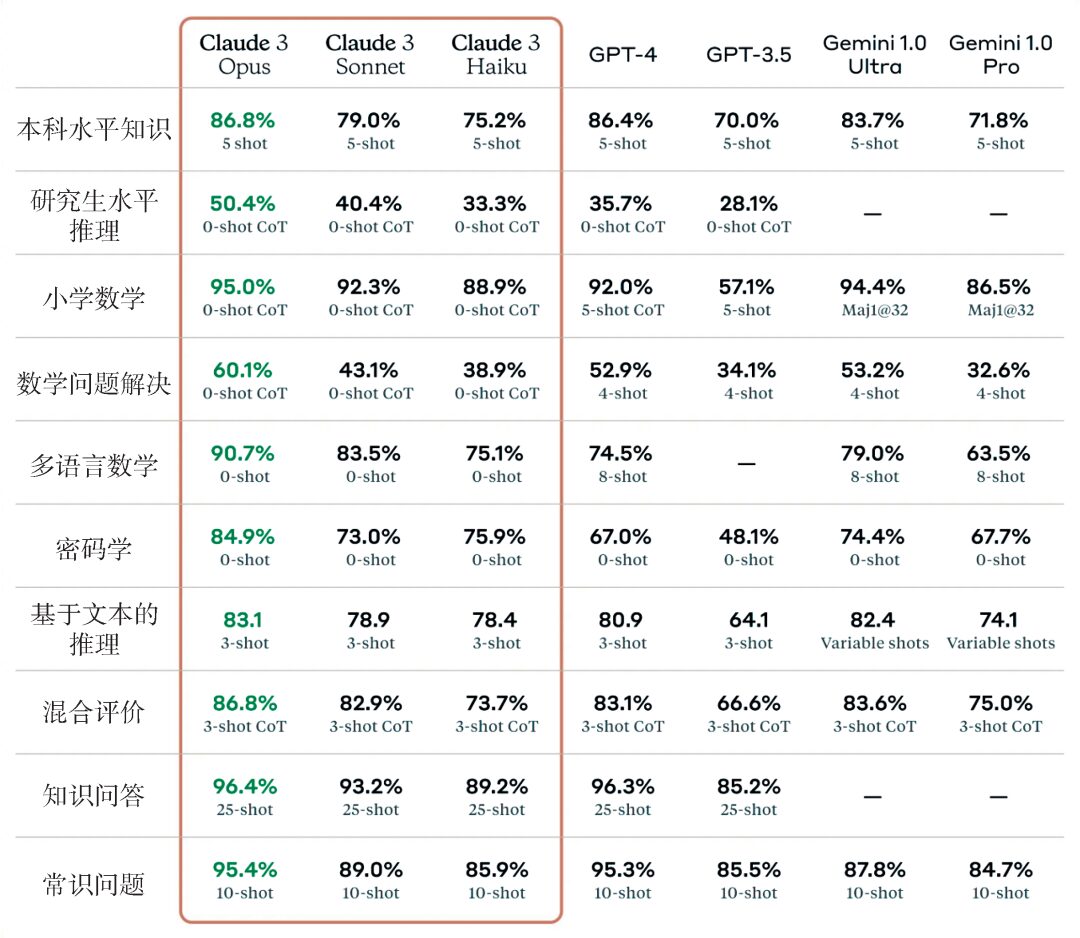
Figure 3: Evaluation results of the model Claude 3 released by the American AI company Anthropic in March 2024, where the three models Opus, Sonnet, and Haiku in the red box are different versions of Claude 3, with decreasing capabilities (image source: https://www.anthropic.com/news/claude-3-family)
2. Critical Points of Information Complexity
2. Critical Points of Information Complexity
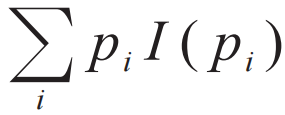 . If we require the information content of two unrelated messages i and a to be equal to the sum of their individual contents, this would require I(piqa)=I(pi)I(qa), from which we learn that I(pi) is a logarithmic function, which is the information entropy defined by Shannon. The amount of information contained in a message depends only on this probability and is unrelated to whether the message is conveyed through phone, text, or verbally. This reflects the particularly universal aspect of the concept of information. All human behaviors, as well as all physical processes, are accompanied by the propagation and evolution of information, or, to use a more precise term, we can refer to them as information dynamics (information dynamics) processes. For instance, the cosmic microwave background radiation observed today provides us with information about the early universe. The microwave background radiation originates from a moment in time when the universe became transparent. Before this moment, the universe was opaque, and photons would be scattered continuously, preventing us from receiving information from that time directly. From the perspective of information, we can say that at the moment the universe became transparent, a qualitative change occurred in information dynamics, transforming the information carried by photons from fleeting to capable of traversing billions of years. A similar qualitative change occurred at the “moment” of the emergence of human language (of course, this is not a specific moment but may be a long evolutionary process). Before the emergence of language, humans and other animals could communicate information, but the content of that information was too limited, and its use was confined to the present. In the long term, information could only be passed down across generations through genetic inheritance and variation. Therefore, an organism’s adaptation to a new environment could only occur through natural selection over a long time scale. The emergence of human language, or more accurately, the attainment of a universal level of language capable of describing various complex scenarios and thoughts, fundamentally changed this situation. Even in the era without written language, humans could accumulate valuable experiences through oral transmission, developing complex skills such as agriculture. If one person invented the wheel, all others would not need to invent the wheel again; they would only need to pass down the technology for making wheels. Today, compared to ten thousand years ago, the differences in genes and IQ can be largely neglected, but the ability to establish such complex social structures and create brilliant science, technology, and culture, from the perspective of information dynamics, is attributed to a new information carrier—language—and a new information dynamics process—human thought and communication. To summarize, the period from the emergence of life to the emergence of language can be termed the “DNA era,” during which the primary carrier of long-term effective information was DNA, and the decisive information dynamics process was genetic variation and natural selection. Since the emergence of language (about a hundred thousand years ago), we can refer to the era as the “human language era,” where the decisive information carrier is human language, and the key information dynamics process is the processing of language (through human brain thought and communication), recording and transmission.
. If we require the information content of two unrelated messages i and a to be equal to the sum of their individual contents, this would require I(piqa)=I(pi)I(qa), from which we learn that I(pi) is a logarithmic function, which is the information entropy defined by Shannon. The amount of information contained in a message depends only on this probability and is unrelated to whether the message is conveyed through phone, text, or verbally. This reflects the particularly universal aspect of the concept of information. All human behaviors, as well as all physical processes, are accompanied by the propagation and evolution of information, or, to use a more precise term, we can refer to them as information dynamics (information dynamics) processes. For instance, the cosmic microwave background radiation observed today provides us with information about the early universe. The microwave background radiation originates from a moment in time when the universe became transparent. Before this moment, the universe was opaque, and photons would be scattered continuously, preventing us from receiving information from that time directly. From the perspective of information, we can say that at the moment the universe became transparent, a qualitative change occurred in information dynamics, transforming the information carried by photons from fleeting to capable of traversing billions of years. A similar qualitative change occurred at the “moment” of the emergence of human language (of course, this is not a specific moment but may be a long evolutionary process). Before the emergence of language, humans and other animals could communicate information, but the content of that information was too limited, and its use was confined to the present. In the long term, information could only be passed down across generations through genetic inheritance and variation. Therefore, an organism’s adaptation to a new environment could only occur through natural selection over a long time scale. The emergence of human language, or more accurately, the attainment of a universal level of language capable of describing various complex scenarios and thoughts, fundamentally changed this situation. Even in the era without written language, humans could accumulate valuable experiences through oral transmission, developing complex skills such as agriculture. If one person invented the wheel, all others would not need to invent the wheel again; they would only need to pass down the technology for making wheels. Today, compared to ten thousand years ago, the differences in genes and IQ can be largely neglected, but the ability to establish such complex social structures and create brilliant science, technology, and culture, from the perspective of information dynamics, is attributed to a new information carrier—language—and a new information dynamics process—human thought and communication. To summarize, the period from the emergence of life to the emergence of language can be termed the “DNA era,” during which the primary carrier of long-term effective information was DNA, and the decisive information dynamics process was genetic variation and natural selection. Since the emergence of language (about a hundred thousand years ago), we can refer to the era as the “human language era,” where the decisive information carrier is human language, and the key information dynamics process is the processing of language (through human brain thought and communication), recording and transmission.
Figure 4: Comparison of the information input, processing, and output complexities between large language models (LLM) and previous machines (such as AlphaGo, Google). The dashed line represents human levels.
3. The Fast and Slow of AI
3. The Fast and Slow of AI
3.1 Human Cognitive Systems
So, is System 2 a completely independent cognitive system from System 1? Not necessarily. For example, if we want to calculate 9 times 9, we can directly recall the answer 81 from memory without thinking, which is a task for System 1. However, if we want to calculate 999 times 999, we cannot rely solely on memory; we must begin invoking System 2 to think. We might break it down into the following steps:
(1) Use 999=1000-1 to transform the problem into calculating (1000−1)×(1000−1);
(2) Expand this expression using the distributive property;
(3) Calculate 1000×1000, 1000×1, and 1×1;
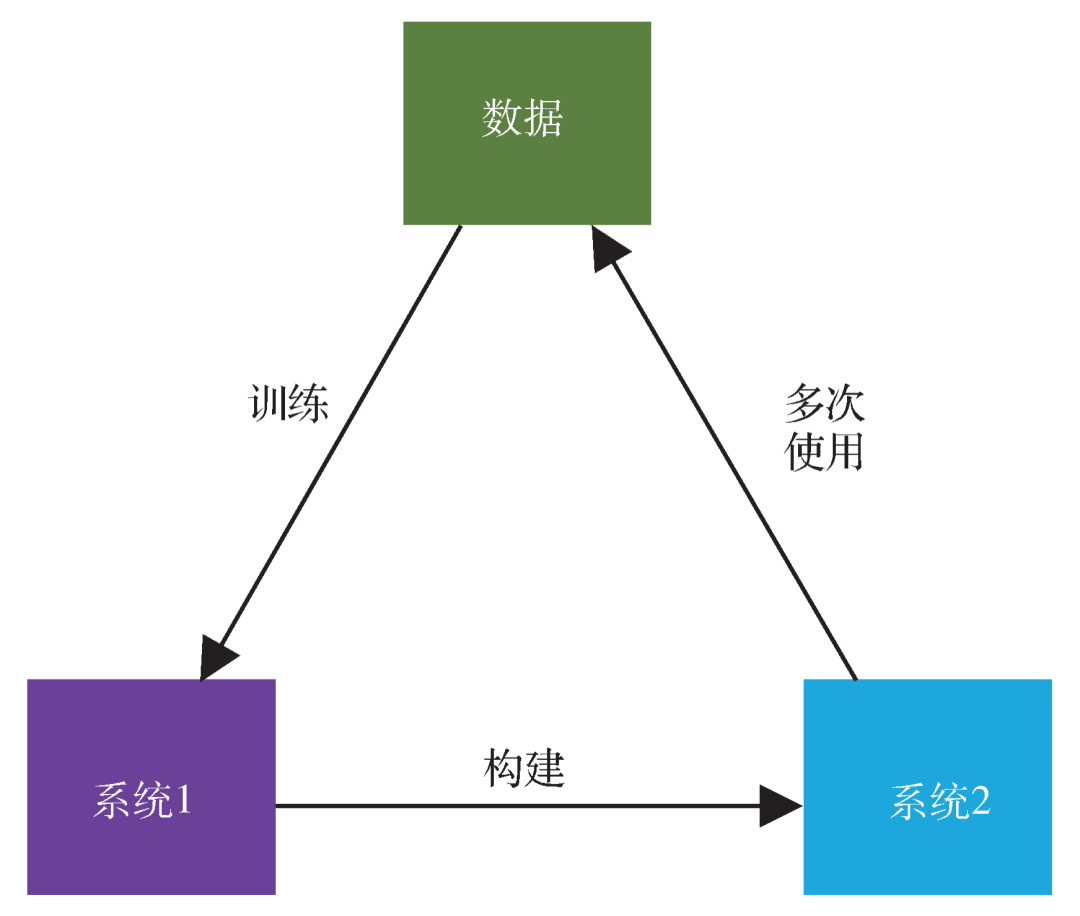
Figure 6: The relationship between human System 1 and System 2. System 2 is a network of System 1, and the data (experience) generated by using System 2 will, in turn, train System 1.
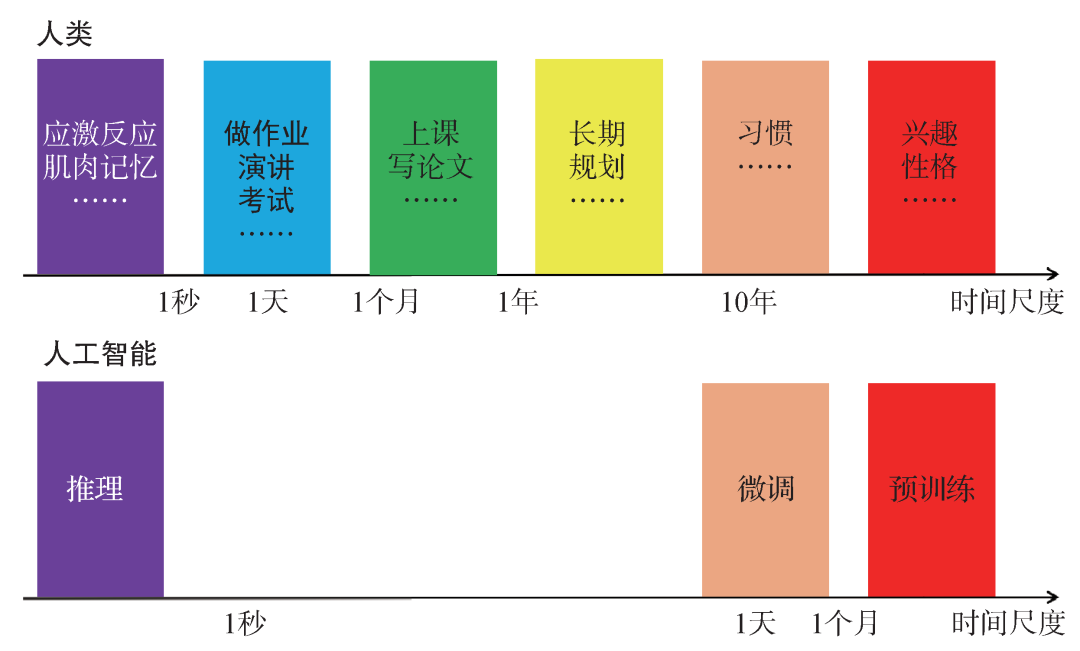
Figure 7: Comparison of time scales for humans and artificial intelligence. The System 2 of humans encompasses a range of time scales from 1 second to several decades, allowing cognitive time scales to be adjusted for different tasks. In contrast, there is a gap between AI’s fast behaviors (inference) and slow behaviors (fine-tuning and pretraining), and fine-tuning and pretraining require human intervention to complete.
4. Towards System 2: AI Agents
4. Towards System 2: AI Agents
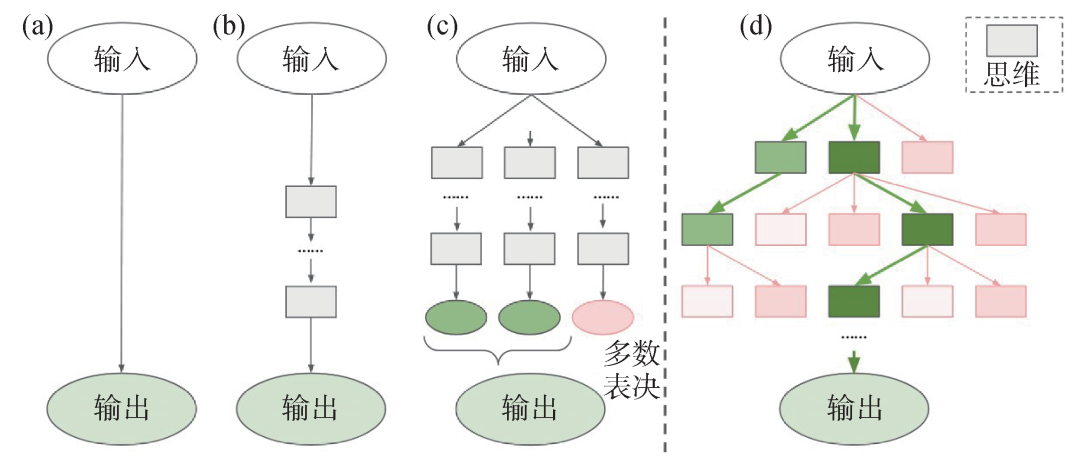
Figure 8: Different ways of invoking large models (a) directly outputting the answer to a given problem; (b) chain-of-thought prompting; (c) multiple chains of thought doing a majority vote; (d) tree of thoughts[7]
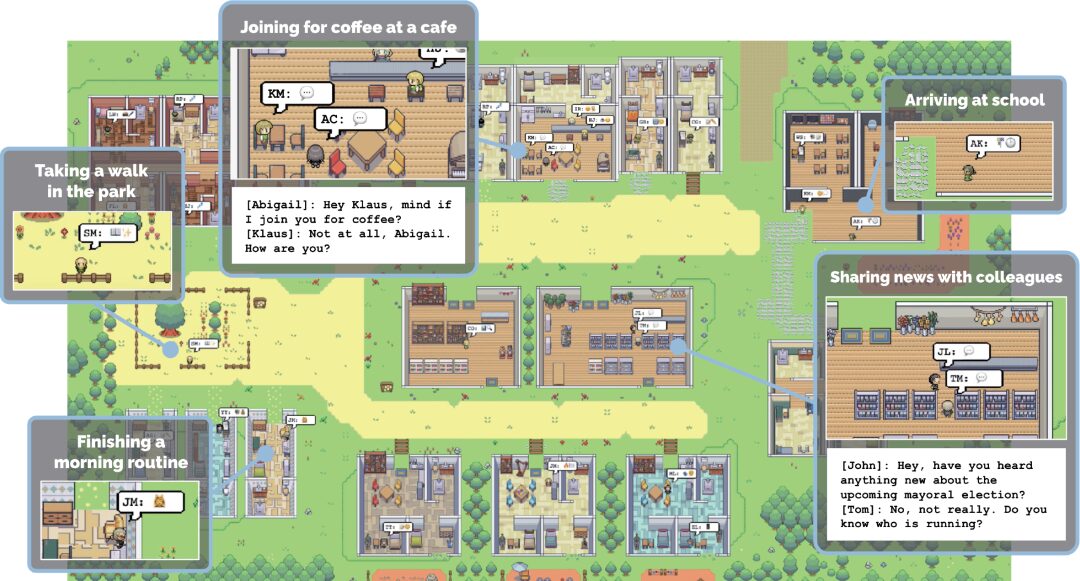
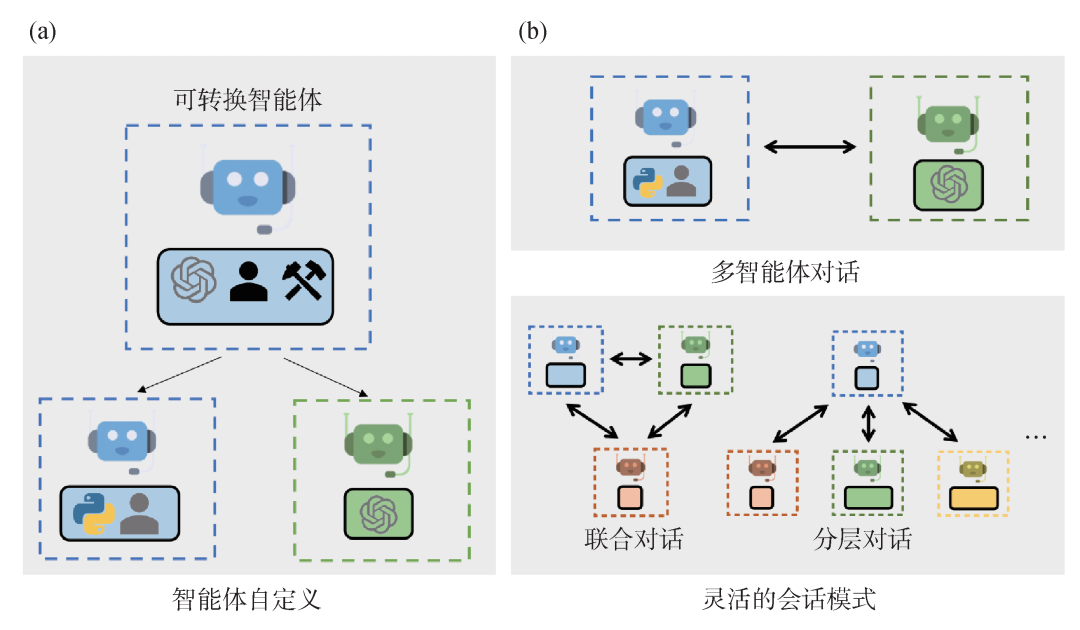
Figure 10: AutoGen demonstration[11] (a) AutoGen’s agents can include large models or other tools, and human input; (b) Agents in AutoGen can solve problems through dialogue.
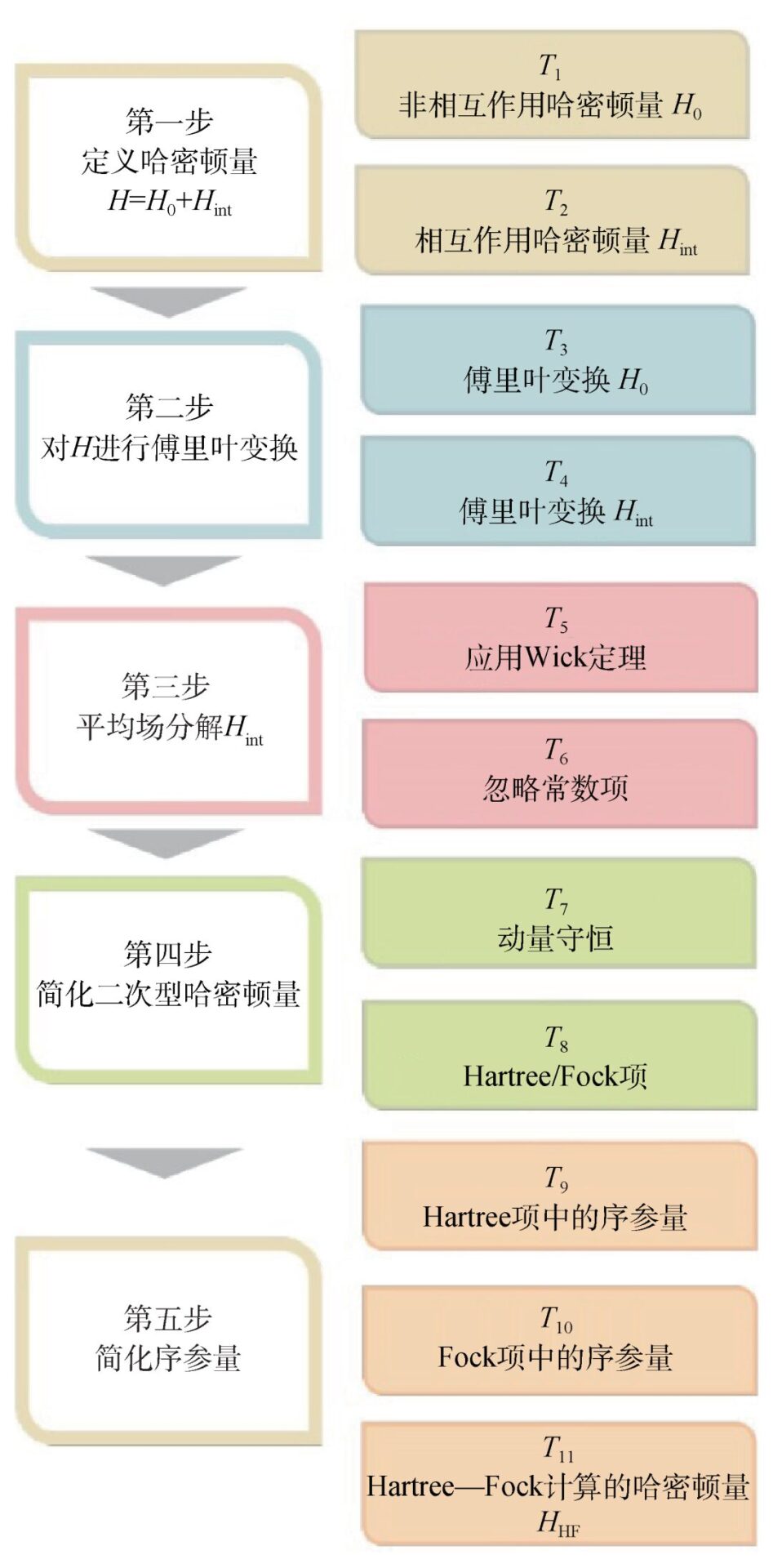
5. Summary and Outlook
5. Summary and Outlook
In the next 5-10 years, the development of artificial intelligence will profoundly impact various aspects of human society, potentially leading to transformative changes. Among these impacts, the influence on scientific research and other innovative work may be one of the most profound changes. How to apply artificial intelligence to assist scientific research is a question worthy of deep thought and exploration.
Author Biography


Registration link: https://pattern.swarma.org/study_group_issue/480
References
[1] Shannon’s Source Coding Theorem. https://web.archive.org/web/20090216231139/; http://plan9.belllabs.com//cm//ms//what//shannonday//shannon1948.pdf
[2] Vaswani A, Shazeer N, Parmar N et al. Attention Is All You Need. 2023, arXiv:1706.03762
[3] Qi Xiaoliang. The Dawn of Artificial Intelligence: Looking at ChatGPT from the Perspective of Information Dynamics. https://mp.weixin.qq.com/s/DJRSqwo0cWGOAgZM4As-OQ
[4] Kahneman D. Thinking, Fast and Slow. Macmillan, 2011
[5] Steven P. Psychon. Bull. Rev., 2014, 21(5): 1112
[6] Wei J et al. Chain-of-thought Prompting Elicits Reasoning in Large Language Models. In: Advances in Neural Information Processing Systems 35, 2022
[7] Yao SY et al. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. In: Advances in Neural Information Processing Systems 36, 2024
[8] Besta M et al. Graph of Thoughts: Solving Elaborate Problems with Large Language Models. In: Proceedings of the AAAI Conference on Artificial Intelligence, 2024, 38(16): 17682
[9] Park JS et al. Generative Agents: Interactive Simulacra of Human Behavior. 2023, arXiv:2304.03442
[10] Yang H, Yue SF, He YZ. Auto-gpt for Online Decision Making: Benchmarks and Additional Opinions. 2023, arXiv:2306.02224
[11] Wu QY et al. AutoGen: Enabling Next-gen LLM Applications via Multiagent Conversation Framework. 2023, arXiv:2308. 08155
[12] Pan HN et al. Quantum Many-Body Physics Calculations with Large Language Models. 2024, arXiv:2403.03154
[13] Andrew Ng. What’s next for AI agentic workflows. https://www.youtube.com/watch?v=sal78ACtGTc
References can be scrolled up and down for viewing
AI By Complexity Reading Group Recruitment
With large models, multimodal, and multi-agent systems emerging one after another, various neural network variants are showcasing their strengths on the AI stage. The exploration of emergence, hierarchy, robustness, nonlinearity, evolution, and other issues in the field of complex systems is also ongoing. Excellent AI systems and innovative neural networks often possess characteristics of excellent complex systems to some extent. Therefore, how developing complex systems theoretical methods can guide the design of future AI is becoming a topic of great concern.
The AI By Complexity reading group was jointly initiated by Assistant Professor You Yizhuang from the University of California, San Diego, Associate Professor Liu Yu from Beijing Normal University, PhD student Zhang Zhang from the School of Systems Science at Beijing Normal University, Mu Yun, and Master student Yang Mingzhe, PhD student Tian Yang from Tsinghua University, to explore how to measure the “goodness” of complex systems? How to understand the mechanisms of complex systems? Can these understandings inspire us to design better AI models? Essentially helping us design better AI systems. The reading group started on June 10 and is held every Monday evening from 20:00 to 22:00. Friends engaged in related research fields or interested in AI+Complexity are welcome to sign up for the reading group exchange!

AI+Science Reading Group

Post-ChatGPT Reading Group

Click “Read Original” to register for the reading group