
ZEHPYR-7B is one of the next-generation large language models (LLMs) that has gained significant popularity in the AI community. The model was created by Hugging Face and is essentially a fine-tuned version of Mistral-7B trained on public datasets, optimized through knowledge distillation techniques. This model has achieved incredible results, surpassing many larger models across various tasks.
In recent studies, distillation has emerged as a valuable technique for enhancing the performance of open AI models across various tasks. However, it has not reached the same performance level as the original teacher model. Users have observed that these models often lack “intent alignment,” meaning they do not always act in ways that align with human preferences. Consequently, they tend to produce responses that do not accurately address user queries.
Quantifying intent alignment has always been a challenge, but recent efforts have led to the development of benchmarks like MT-Bench and AlpacaEval, specifically designed to assess this aspect. The scores produced by these benchmarks are closely related to human ratings of model outputs and validate a qualitative notion: proprietary models outperform open models trained with human feedback, which in turn outperform open models trained through distillation. This emphasizes the importance of collecting detailed human feedback for alignment, even in large-scale projects as seen with LLAMA2-CHAT.
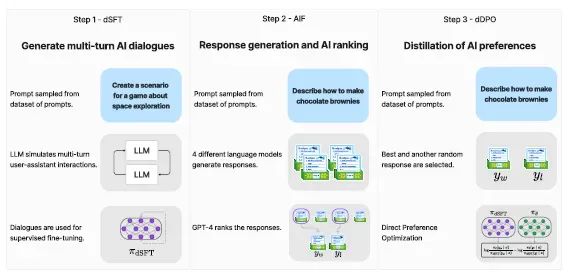
Validating this approach is the main goal behind ZEPHYR-7B, which is the aligned version of Mistral-7B. This process involves three key steps:
1. Large-scale dataset construction using a self-guided style, employing the UltraChat dataset, followed by distilled supervised fine-tuning (dSFT).
2. Collecting AI feedback (AIF) through a series of chat models and subsequent GPT-4 (UltraFeedback) scoring, which is then transformed into preference data.
3. Applying distilled direct preference optimization (dDPO) to the dSFT model using the collected feedback data.
The fine-tuning process behind ZEPHYR-7B is based on three fundamental techniques:
1. Distilled Supervised Fine-Tuning (dSFT): Starting from an original language model that needs training to generate responses to user prompts. This traditional step usually involves supervised fine-tuning (SFT) on a dataset containing high-quality instructions and responses. However, when a teacher language model is available, the model can directly generate instructions and responses, a process known as distilled supervised fine-tuning (dSFT).
2. AI Feedback (AIF) through Preferences: Enhancing language models using human feedback. Traditionally, human feedback is collected by assessing the quality of model responses. In the context of distillation, AI preferences from the teacher model are used to evaluate outputs generated by other models.
3. Refined Direct Preference Optimization (dDPO): Aims to refine the dSFT model by maximizing the likelihood of ranking preferred responses above less preferred ones. This is achieved through a preference model defined by a reward function that utilizes the student language model. Previously, methods using AI feedback primarily adopted reinforcement learning approaches, such as Proximal Policy Optimization (PPO), to optimize model parameters based on this reward function. These methods typically involve training the reward function first and then generating updates by sampling from the current policy.
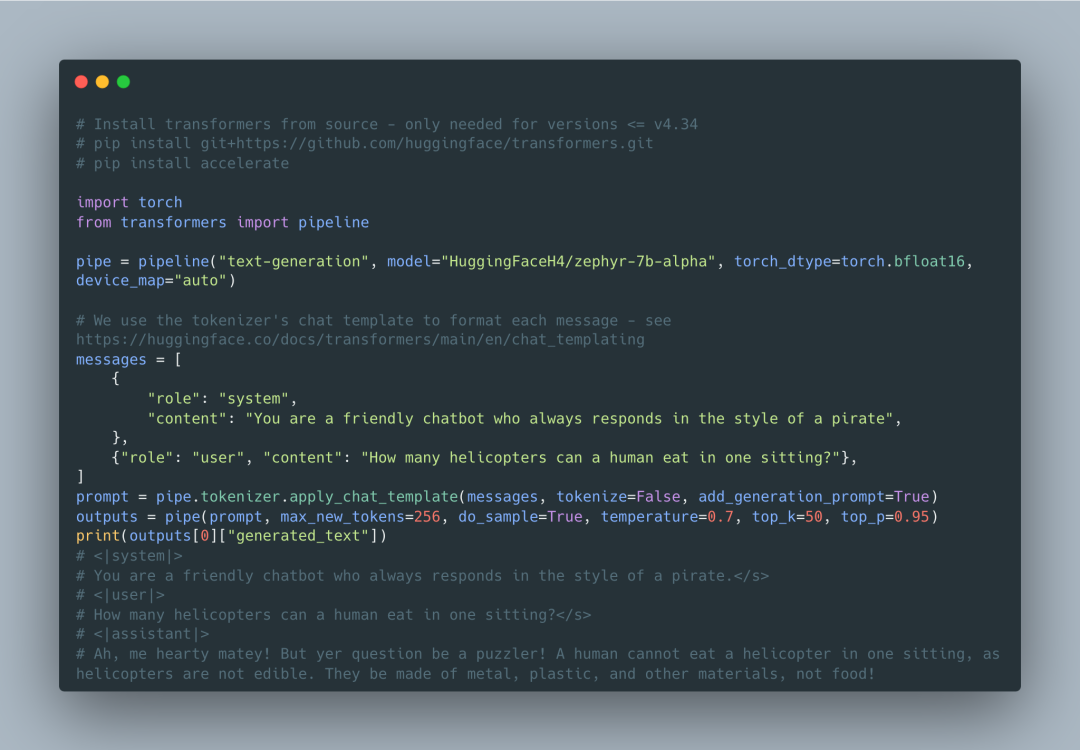
Using ZEPHYR-7B
ZEPHYR-7B can be accessed through Hugging Face’s transformers library with a very simple interface. Executing ZEPHYR-7B only requires calling the library’s pipeline() function.
Results
Hugging Face’s primary evaluation of ZEPHYR-7B focuses on single-turn and multi-turn chat benchmarks that measure the model’s ability to follow instructions and respond to complex prompts across different domains.
1. MT-Bench: This multi-turn benchmark contains 160 questions across 8 different knowledge domains. In MT-Bench, the model faces the challenge of answering an initial question and subsequently providing follow-up responses to a predefined question. The quality of each model’s responses is evaluated by GPT-4 on a scale of 1 to 10. The final score is derived from the average rating over two rounds.
2. AlpacaEval: On the other hand, AlpacaEval is a single-turn benchmark where the model’s task is to generate responses to 805 questions covering various topics, primarily focusing on their usefulness. GPT-4 also evaluates these model responses. However, the final metric is the pairwise win rate compared to a baseline model.
In addition to these benchmarks, Hugging Face also evaluated the performance of ZEPHYR-7B on the Open LLM leaderboard. This leaderboard aims to assess the performance of language models through four multi-class classification tasks, including ARC, HellaSwag, MMLU, and Truthful QA. Each task presents unique challenges and requires the model to excel in classification accuracy.
The results are quite impressive:
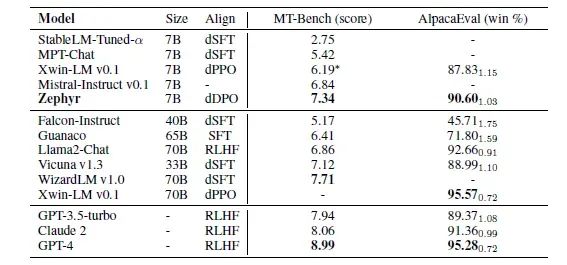
ZEPHYR-7B represents a significant validation that small, high-performance LLMs indeed have a place for highly specialized tasks.
Original article: https://pub.towardsai.net/inside-zephyr-7b-huggingfaces-hyper-optimized-llm-that-continues-to-ouperform-larger-models-3136f6935ef5