Author: lochsh
Translator: Ma Kewei
Editor: Wang Wenjing
As an emerging programming language, Rust is heavily influenced by functional programming languages such as Haskell and OCaml, making its syntax similar to C++, but its semantics are entirely different. Rust is a statically typed language with complete type inference, unlike C++ which has partial type inference. It can match C++ in speed while ensuring memory safety.
The Story of Indexing
Before diving into Rust, let’s start with an example. Imagine you are a worker tasked with installing gas pipes for a new house. Your boss wants you to connect the gas line from the basement to the main gas line on the street, but when you go downstairs, you find a small problem: there is no basement in the house. So, what do you do? Do you do nothing, or do you foolishly try to connect the gas main to the air intake of the air conditioning unit in the next office? Regardless, when you report back to your boss that the task is complete, you might find yourself facing criminal negligence charges amidst the rubble of a gas explosion.
This is what can happen in certain programming languages. In C, it might be an array, and in C++, it could be a vector. When the program tries to access the -1st element, anything can happen: perhaps the results vary with each search, leading you to be unaware of the underlying issue. This is known as undefined behavior, which cannot be entirely eliminated because low-level hardware operations are inherently unsafe. These operations might be warned against by compilers in other programming languages, but not in C/C++.
In the absence of guaranteed memory safety, undefined behavior is highly likely to occur. The HeartBleed vulnerability, a well-known SSL security flaw, arose from a lack of memory safety protections; similarly, the infamous Android vulnerability Stagefright was caused by undefined behavior due to integer overflow in C++.
Memory safety is not only crucial for preventing vulnerabilities; it is also vital for the correct operation and reliability of applications. The importance of reliability lies in ensuring that programs do not crash unexpectedly. As for accuracy, the author has a friend who once worked at a rocket flight simulation software company. They discovered that passing the same initialization data but using different filenames led to different results because some uninitialized memory was read, causing the simulator to use garbage values based on the different filenames, rendering their project useless.
Why not use memory-safe languages like Python or Java? Python and Java use automatic garbage collection to avoid memory errors, such as:
-
Use-After-Free: Accessing memory that has already been freed.
-
Double Free: Freeing the same memory area twice, leading to undefined behavior.
-
Memory Leak: Memory that is not reclaimed, reducing the available memory in the system.
Automatic garbage collection runs as part of the JVM or Python interpreter, continuously searching for unused modules during program execution to free their corresponding memory or resources. However, this comes at a significant cost; garbage collection is not only slow but also consumes a lot of memory, and you can never know when your program will pause to reclaim garbage.
Memory safety in Python and Java sacrifices runtime speed. C/C++ sacrifices memory safety for speed.
This uncontrollable garbage collection makes Python and Java unsuitable for real-time software, as you must ensure your program can complete its execution within a certain timeframe. This is not a competition of speed but a guarantee that your software can run quickly every time.
Of course, C/C++ is popular for other reasons: they have been around long enough for people to become accustomed to them. However, they are also sought after for their speed and the reliability of their results. Unfortunately, such speed comes at the cost of memory safety. Worse still, many real-time software applications also require a focus on safety, such as control software in vehicles or medical robots. Yet, these applications still use these unsafe languages.
For a long time, developers have faced a dilemma: choose speed and unpredictability or memory safety and predictability. Rust completely overturns this, which is why it is so exciting.
Design Goals of Rust
-
No worries about data concurrency: As long as different parts of the program may run at different times or out of order, concurrency is possible. Data concurrency is a well-known danger in multithreaded programs, which we will describe in detail later.
-
Zero-cost abstractions: The conveniences and expressiveness provided by the programming language do not incur additional overhead and do not reduce program execution speed.
-
Memory safety without garbage collection: We have understood the definitions of memory safety and garbage collection, and next, we will elaborate on how Rust balances speed and safety.
Achieving Memory Safety Without Garbage Collection
Rust’s memory safety guarantees can be described as simple yet complex. It is simple because it consists of a few very easy-to-understand rules.
In Rust, every object has exactly one owner, ensuring that any resource can only have one binding. To avoid restrictions, we can use references under strict rules. References in Rust are often referred to as “borrowing.”
The borrowing rules are as follows:
-
The scope of any borrow cannot exceed that of its owner.
-
You cannot have a mutable reference while having an immutable reference, but multiple mutable references are allowed.
The first rule prevents the occurrence of use-after-free, while the second rule eliminates the possibility of data races. Data races can leave memory in an unknown state, and they can be caused by three behaviors:
-
Two or more pointers accessing the same data simultaneously.
-
At least one pointer is used to write data.
-
No mechanism for synchronizing data access.
When the author was still an embedded engineer, the heap had not yet emerged, so a trap for dereferencing null pointers was set up in hardware, making many common memory issues seem less significant. Data races were the bugs the author feared the most; they are hard to trace, and when you modify a seemingly unimportant part of the code or when external conditions change slightly, the winner of the race can easily shift. The Therac-25 incident, for example, resulted in cancer patients receiving overdoses of radiation during treatment due to data races, leading to patient deaths or serious injuries.
The key to Rust’s innovation is its ability to enforce memory safety guarantees at compile time. These rules should not be new to anyone familiar with data races.
Unsafe Rust
As mentioned earlier, the possibility of undefined behavior cannot be entirely eliminated due to the inherent unsafety of underlying computer hardware. Rust allows unsafe operations in a module that contains unsafe code. C# and Ada also have similar mechanisms for disabling safety checks. Such a block is necessary when performing embedded programming operations or low-level system programming. Isolating potentially unsafe parts of the code is very useful, as it ensures that memory-related errors are confined to this module rather than any part of the entire program.
Unsafe modules do not disable borrowing checks; users can dereference raw pointers, access or modify mutable static variables within unsafe blocks, and the advantages of the ownership system still apply.
Revisiting Ownership
When discussing ownership, one cannot help but mention C++’s ownership mechanism.
C++’s ownership was greatly enhanced after the release of C++11, but it also paid a significant price in terms of backward compatibility issues. For the author, C++’s ownership is very redundant, as previously simple value semantics have been complicated. Nevertheless, optimizing a widely used language like C++ on a large scale is a remarkable achievement, but Rust was designed from the ground up with ownership as a core concept.
The C++ type system does not model the lifecycle of object models, so it cannot check for use-after-free issues at runtime. C++’s smart pointers are merely a library added to an old system, which can be misused in ways that Rust does not allow.
Here is a simplified version of some code the author wrote at work, which contains misuse issues.
#include <functional>
#include <memory>
#include <vector>
std::vector<DataValueCheck> createChecksFromStrings( std::unique_ptr<Data> data, std::vector<std::string> dataCheckStrs) {
auto createCheck = [&] { return DataValueCheck(checkStr, std::move(data)); };
std::vector<DataValueCheck> checks; std::transform( dataCheckStrs.begin(), dataCheckStrs.end(), std::back_inserter(checks), createCheck);
return checks;
}This code aims to define checks for certain data based on the strings in dataCheckStrs, such as values within a specific range, and then creates a vector of check objects by parsing these strings.
First, a lambda expression is created that captures by reference, indicated by &, and the object pointed to by this smart pointer (unique_ptr) is moved within this lambda, which is illegal.
Then, the checks constructed from the moved data fill the vector, but the problem is that it can only complete the first step. The unique_ptr and the object it points to represent a unique ownership relationship that cannot be copied. Therefore, after the first iteration of std::transform, the unique_ptr is likely to be emptied. The official statement is that it will be in a valid but unknown state, but based on the author’s experience with Clang, it usually gets emptied.
Subsequent use of this null pointer will lead to undefined behavior; the author received a null pointer error after running it, as most managed systems would report such an error for dereferencing a null pointer, since zero memory pages are typically preserved. But of course, this situation does not happen 100% of the time; this bug may theoretically be temporarily set aside, and then you are left with a sudden program crash.
The use of lambda here greatly contributes to this danger. The compiler can only see it as a function pointer at call time; it cannot check the lambda like a standard function.
To understand this bug in context, the data was initially stored using shared_ptr, which was fine. However, we mistakenly stored the data in unique_ptr, and when we tried to make changes, problems arose. It went unnoticed because the compiler did not report an error.
This is a real example of how C++’s memory safety issues have not been taken seriously; the author and the code reviewer did not notice this until just before a test. No matter how many years of programming experience you have, such bugs are unavoidable! Not even the compiler can save you. This calls for better tools, not just for our sanity but also for public safety, which is a matter of professional ethics.
Next, let’s look at how the same issue manifests in Rust.
In Rust, such a bad move() is not allowed.
pub fn create_checks_from_strings( data: Box<Data>, data_check_strs: Vec<String>) -> Vec<DataValueCheck>{ let create_check = |check_str: &String| DataValueCheck::new(check_str, data); data_check_strs.iter().map(create_check).collect()}This is our first look at Rust code. It is important to note that by default, variables are immutable, but you can add the mut keyword before a variable to make it mutable, with mut being the opposite of const in C/C++.
The Box type indicates that we have allocated memory on the heap, and it is used here because unique_ptr can also allocate on the heap. Because of Rust’s rule that each object has exactly one owner, we do not need anything like unique_ptr. Next, a closure is created, and the higher-order function map is used to transform the strings, similar to C++, but without being verbose. However, when compiling, it will still throw an error, and here is the error message:
error[E0525]: expected a closure that implements the `FnMut` trait, but this closure only implements `FnOnce` --> bad_move.rs:1:8 | 6 | let create_check = |check_str: &String| DataValueCheck::new(check_str, data); | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^----^ | | | | | closure is `FnOnce` because it moves | | the variable `data` out of its environment | this closure implements `FnOnce`, not `FnMut` 7 | data_check_strs.iter().map(create_check).collect() | --- the requirement to implement `FnMut` derives from here error: aborting due to previous error For more information about this error, try `rustc --explain E0525.The Rust community has a wonderful aspect: it provides a wealth of learning resources and offers readable error messages. Users can even ask the compiler for more detailed information about errors, and the compiler will respond with a minimal example accompanied by an explanation.
When creating a closure, due to the rule of having exactly one owner, the data is moved within it. The compiler then infers that the closure can only run once: due to the lack of ownership, multiple runs are illegal. Consequently, the map function requires a callable function that can be called repeatedly and is in a mutable state, which is why the compiler fails.
This segment of code illustrates how powerful Rust’s type system is compared to C++, and it also highlights how different programming in a language that tracks object lifetimes is.
The error message in the example mentions traits. For instance: “missing a closure that implements the FnMut trait.” Traits are a language feature that tells the Rust compiler that a specific type has certain capabilities, and traits also embody Rust’s polymorphic mechanism.
Polymorphism
C++ supports various forms of polymorphism, which the author believes contributes to the richness of the language. Static polymorphism includes templates, functions, and operator overloading; dynamic polymorphism involves subclasses. However, these expressions also have significant drawbacks: tight coupling between subclasses and parent classes leads to excessive dependency of subclasses on parent classes, lacking independence; templates can be difficult to debug due to their lack of parameterization.
Rust’s traits define a behavior that specifies shared static and dynamic interfaces. Traits are similar to interfaces in other languages, but Rust only supports implementation (implements) without inheritance (extends), encouraging design based on composition rather than implementation inheritance, thereby reducing coupling.
Let’s look at a simple and interesting example:
trait Rateable { /// Rate fluff out of 10 /// Ratings above 10 for exceptionally soft bois fn fluff_rating(&self) -> f32;}
struct Alpaca { days_since_shearing: f32, age: f32}
impl Rateable for Alpaca { fn fluff_rating(&self) -> f32 { 10.0 * 365.0 / self.days_since_shearing }}First, we define a trait named Rateable, which requires the implementation of a function fluff_rating that returns a float. Next, we implement the Rateable trait on the Alpaca struct. Below is the same method defined for a Cat type.
enum Coat { Hairless, Short, Medium, Long}
struct Cat { coat: Coat, age: f32}
impl Rateable for Cat { fn fluff_rating(&self) -> f32 { match self.coat { Coat::Hairless => 0.0, Coat::Short => 5.0, Coat::Medium => 7.5, Coat::Long => 10.0 } }}In this example, the author uses another feature of Rust: pattern matching. It is similar to the switch statement in C, but semantically very different. In a switch block, cases can only be used for jumping, while pattern matching requires covering all possibilities to compile successfully, but the optional matching range and structure provide flexibility.
Here is a generic function that combines the implementations of these two types:
fn pet<T: Rateable>(boi: T) -> &str { match boi.fluff_rating() { 0.0...3.5 => "naked alien boi...but precious nonetheless", 3.5...6.5 => "increased floof...increased joy", 6.5...8.5 => "approaching maximum fluff", _ => "sublime. the softest boi!"}The angle brackets indicate type parameters, similar to C++, but unlike C++ templates, we can parameterize function arguments. The statement “this function only applies to Rateable types” is meaningful in Rust, but meaningless in C++. The consequence of this is not limited to readability. The trait bound on type parameters means that Rust’s compiler can perform type checking on the function only once, avoiding the need to check each specific implementation separately, thus shortening compile times and simplifying compile error messages.
Traits can also be used dynamically, although sometimes necessary, it is not recommended as it increases runtime overhead, which is why the author does not elaborate on it in this article. Another significant aspect of traits is their interoperability; for example, the Display and Add traits in the standard library. Implementing the Add trait means you can overload the + operator, while implementing the Display trait means you can format output for display.
Rust’s Tools
There is no standard for managing dependencies in C/C++, although there are many tools available to help, but their reputations are not great. Basic Makefiles are very flexible for build systems but are a maintenance nightmare. CMake reduces maintenance burdens but is less flexible and can be quite frustrating.
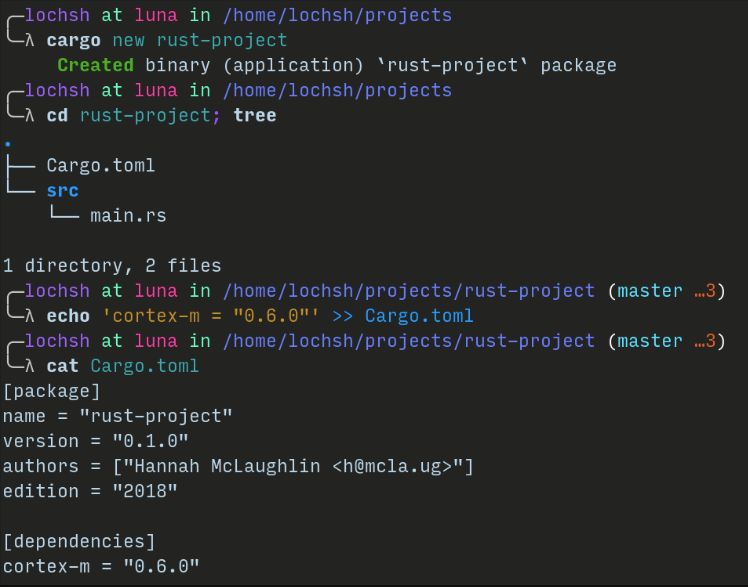
Rust excels in this area; Cargo is the only tool in the Rust community used for managing packages and dependencies, as well as building and running projects. Its status is similar to Pipenv and Poetry in Python. The official installation package comes with Cargo, which is so useful that it is regrettable that C/C++ does not have a similar tool.
Should We All Switch to Rust?
This question has no standard answer; it entirely depends on the user’s application scenario, which is common to any programming language. Rust has successful cases in various areas: including Microsoft’s Azure IoT project, Mozilla supports Rust and will use it in parts of the Firefox browser, and many others are using Rust. Rust has matured and can be used in production, but for some applications, it may still not be mature enough or lack support libraries.
1. Embedded: In embedded environments, the experience of using Rust is entirely defined by what users choose to do with it. Cortex-M is already resource mature and can be used in production, while RISC-V has a toolchain that is still developing and not yet mature.
x86 and arm8 architectures are also developing well, including Raspberry Pi. Older architectures like PIC and AVR still have some shortcomings, but the author believes that for most new projects, there should be no major issues.
Cross-compilation support is also available for all LLVM (Low-Level Virtual Machine) targets, as Rust uses LLVM as its compiler backend.
Another area where Rust lacks in embedded systems is production-grade RTOS, and the development of HAL is also quite sparse. This may not be a big deal for many projects, but it remains a barrier for others. In the coming years, these barriers may continue to increase.
2. Asynchronous: The language’s asynchronous support is still in development, and the syntax for async/await has not yet been finalized.
3. Interoperability: Regarding interoperability with other languages, Rust has a C foreign function interface (FFI). Whether it is callbacks from C++ to Rust functions or using Rust objects as callbacks, this step is necessary. This is quite common in many languages, and it is mentioned here because merging Rust into existing C++ projects can be somewhat troublesome, as users need to add a C language layer between Rust and C++, which undoubtedly brings many issues.
In Conclusion
If starting a project from scratch at work, the author would absolutely choose the Rust programming language. Hopefully, Rust can become a more reliable, safer, and more enjoyable future programming language.
Original link:
https://mcla.ug/blog/rust-a-future-for-real-time-and-safety-critical-software.html

Click to see fewer bugs👇