
Empowering every device in the world with its own intelligence
Source: Quantum Bit, Author: Wang Xinyi, Original link:
Running Large Models Smoothly on Raspberry Pi! Empowering Terminals with Autonomous Learning and Memory Capabilities | Interview with RockAI CEO Liu Fanping
In early 2022, before OpenAI released ChatGPT, RockAI had already chosen to bet on anon-Transformer route.
This choice, which seemed non-mainstream at the time, is now gradually showing its foresight.
The large models they developed can now run smoothly on micro devices likeRaspberry Pi, and the first batch of embodied intelligent robots equipped with the Yan architecture large model has already been launched.
As the AI computing power competition intensifies, their“low-power” and “collective intelligence” approach is gaining more attention.
In this issue of the“Large Model Innovative Architecture” themed interview,Quantum Bit invitedRockAI CEO Liu Fanping to discuss the story behind their choice of a non-Transformer architecture route and their technical vision for achieving AGI through architectural and algorithmic innovation.

△RockAI CEO Liu Fanping
The following is a整理 of the dialogue betweenQuantum Bit andRockAI CEO Liu Fanping:
Choosing Non-Transformer Against the Trend
Quantum Bit: Can you introduce the founding background of RockAI? Why did you choose to pursue a non-Transformer architecture?
Liu Fanping: RockAI was officially registered in June 2023, but we have been working on these things for many years, back when ChatGPT was not yet popular.
I first recognized many issues with the Transformer while researching the Attention mechanism in 2016 and 2017. When we started our business in early 2022, we firmly chose the non-Transformer route, mainly because we realized that Transformersconsume both computing power and data.
Before this, we had also explored optimization directions for the Transformer architecture, making improvements like linear Attention, but found that none of these solved the fundamental problems, so we simply abandoned it and went directly down thenon-Transformer path.
Quantum Bit: What were the envisioned application scenarios at that time?
Liu Fanping: Initially, we were actually working on asearch engine, which was able to provide direct answers instead of a bunch of web links. This was somewhat similar to the current models ofKimi orPerplexity, but we were doing it quite early.
At that time, we found that the Transformer could not meet our needs. Firstly, thehallucination problem was very serious, and we also wanted AI to achieve personalizedautonomous learning andmemory, both of which were basically impossible for Transformers at that time, and even now they still cannot achieve it.
Quantum Bit: Why did you transition from building a search engine to developing edge AI and collective intelligence?
Liu Fanping: It was actually a very natural choice and transition. A search engine helps users obtain information, but it has a shallow understanding of users, only able to understand them through their queries, clicks, and the results we provide.
This method has a limited impact onmemory andautonomous learning, remaining at a very shallow level of traditional machine learning user profiling. We wanted to go further and create more engagement between AI and users, so we thought aboutbringing devices into the picture.
We judged that AGI (Artificial General Intelligence) would have a strong correlation with devices, not just the internet model. A search engine is merely a tool towards AGI and does not become infrastructure; forartificial intelligence to become infrastructure, it must be associated with devices.
In fact, after GPT became popular at the end of 2022, many people did not understand why we wanted to develop a large model with a non-Transformer architecture. Even in 2023, many still did not understand, but now more and more people are beginning to see the possibilities beyond Transformers.
Quantum Bit: Can you explain what collective intelligence is?
Liu Fanping: We definecollective intelligence as several intelligent units with autonomous learning capabilities, which perceive the environment, self-organize, and collaborate to solve complex problems, achieving overall intelligence enhancement in a constantly changing environment. We also define four stages of collective intelligence:
The first stage isinnovative foundational architecture, which discards traditional architectures and develops innovative architectures and algorithms with low computing power requirements.
The second stage isdiversified hardware ecosystem, which builds cross-platform, low-power, multi-modal compatible models, enabling flexible deployment across various terminal devices.
The third stage isadaptive intelligent evolution, which endows intelligent units with autonomous learning capabilities, establishing a continuous evolution system for self-optimization and iteration.
The fourth stage iscollaborative collective intelligence, which constructs efficient information exchange and collaboration mechanisms among intelligent units, forming an intelligent ecosystem that is both independent and holistic.
Throughout this process, we hope to transition from the internet model to the physical world, allowing every interaction in the physical world to become data, which can better understand users, while AI’s learning from data can also feedback to users. We believe this is the most valuable aspect.
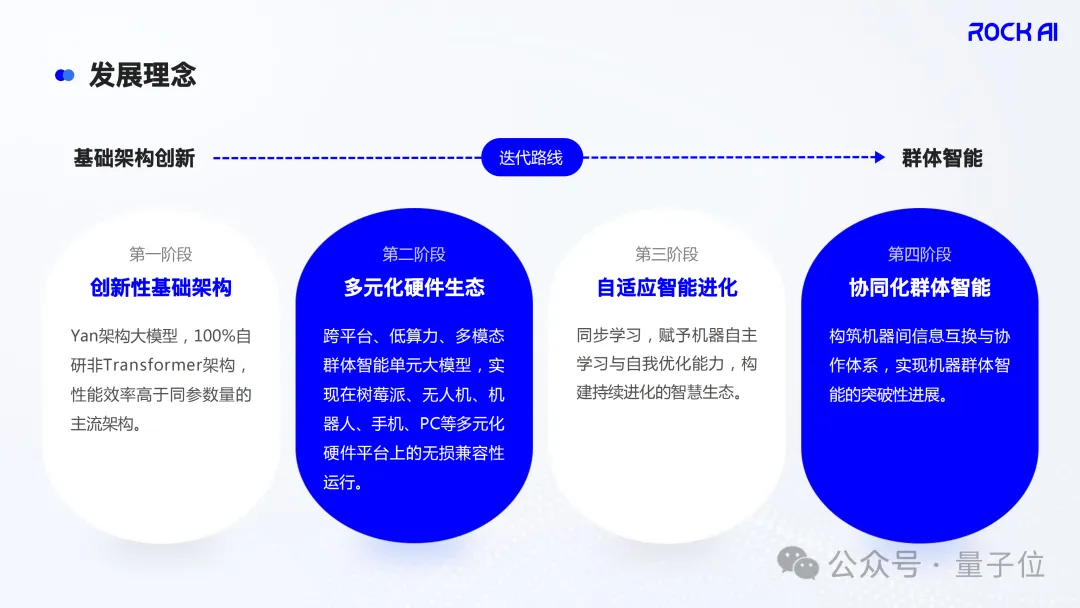
△RockAI’s collective intelligence development philosophy
MCSD and Brain-like Activation
Quantum Bit: Can you introduce the core technology MCSD of the Yan architecture large model?
Liu Fanping: Actually, MCSD is just one module of our model, which reducestime complexity andspace complexity.
For example, the Attention mechanism in Transformers is like the engine of a gasoline car, which is the core part. Many people are optimizing it, which is akin to turning the engine from naturally aspirated to turbocharged, butno matter how it is modified, it remains a gasoline engine.
Our MCSD is equivalent to transforming it into the motor of a new energy vehicle. The Attention mechanism establishes a large matrix to calculate the relationships between tokens, with a time complexity ofO(n²), resulting in significant performance loss.
Our MCSD can be understood as dynamically enhancing and attenuating the tokens in the input content.
For example, if I want to predict what the next token of the sentence “What is the temperature in Beijing today” is, whether it is a question mark or a period. The two characters “today” have little impact on whether the next token is a question mark or a period, so weattenuate it; while “how much” has a greater impact on the next token, so weenhance it.
This process only requires one calculation, reducing the computational complexity fromO(n²) toO(n), making inference faster and achieving a stable constant-level inference.

△MCSD: An Efficient Language Model with Diverse Fusion paper
Quantum Bit: Besides MCSD, what other core technologies does the Yan architecture large model have?
Liu Fanping: We also proposed abrain-like activation mechanism, which is a lateral extension based on MCSD. We internally refer to this brain-like activation mechanism as“Dynamic Neuron Selection Driven Algorithm”.
The human brain is dynamically activated. When driving, the visual cortex is highly activated; when resting, it is suppressed; during exams, the logical area is activated; and when recalling questions, the memory area is activated. However, in traditional Transformer architectures, even for simple calculations like 1+1, all neurons participate in the computation, which is very unreasonable.
MoE (Mixture of Experts) reduces the parameters involved in computation, but it defines the number of branches before model initialization, which is not truly dynamically activated.
Our approach is that when a user inputs a query, a neural network is dynamically constructed based on the needs, which istemporarily established, not pre-set.
To illustrate, MoE is like having five bridges built in advance over a river, and the user chooses one to cross; while we provide a bunch of tools (neurons) without pre-built bridges, and when the user needs to cross the river, these toolsdynamically create a bridge, which disappears once the problem is solved.
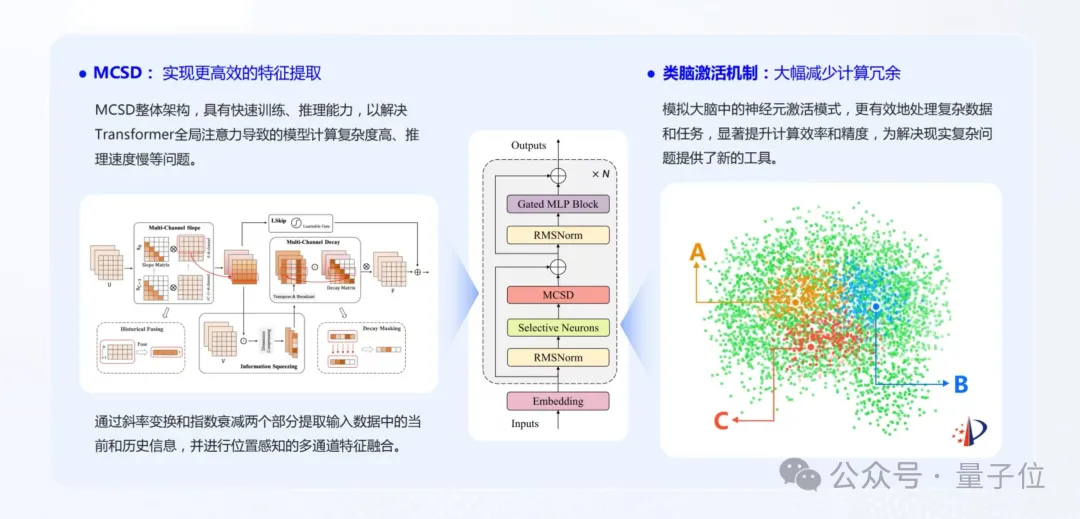
△Illustration of MCSD and brain-like activation mechanism
Quantum Bit: What new possibilities can a model with a computational complexity of O(n) provide in reality?
Liu Fanping: The most typical application ison-device applications. Many device manufacturers approach us because our model can run on their devices. If a Transformer architecture were to run on a Snapdragon 6 phone, the parameter count would need to be significantly reduced, while we can run it directly.
For low-end devices likeRaspberry Pi, we can also run it, which is very important for IoT devices. For drones, embodied intelligent robots, etc., if they need to be connected to the internet to converse, the user experience would be very poor. We can deploy the model on the device to achieveoffline intelligence, which is a significant advantage.
Quantum Bit: Can the reduction in computational complexity and the improvement in model performance be achieved simultaneously?
Liu Fanping: I believe it is possible. This is not just a gut feeling, but based on two reasons:
First, we have conducted many experiments and found that part of the O(n²) computational complexity of the standard Attention mechanism is wasted computing power;Second, from a neuroscience perspective, even simple organisms with few neurons can possess a certain level of intelligence.
We believe the key lies in the underlying algorithm. We are not only innovating the architecture but also innovating the foundational algorithms. As Hinton said, the backpropagation algorithm itself has problems. To further develop artificial intelligence, significant innovations in foundational algorithms are necessary.
The foundational algorithm determines the upper-level architecture; if the foundational algorithm is inadequate, the innovation at the architectural level will become increasingly limited.
Training-Inference Synchronization and Edge Revolution
Quantum Bit: Can you describe what the ultimate scenario of collective intelligence looks like?
Liu Fanping: The development of human society will certainly be accompanied by the emergence ofnew devices, and in the future, everyone may have a new device that may not be a phone, as the scenarios for phones are limited.
What this device will look like is unclear now, but I believe it will help you more in thephysical world and may not necessarily take the form of a robot. It will help solve most of your daily life problems, possess high privacy, be completely loyal to you, and not leak your privacy.
More importantly, these devices will have autonomous learning capabilities. For example, if you tell it to make fried rice, it may not know how to do it yet, but it will learn how to do it in the physical world. Devices will also be interconnected, creating asociety of humans and machines and asociety of machines and machines beyond human society.
However, this does not mean that silicon-based life will emerge; rather, it is a process of serving human society. I am a pragmatist and do not fantasize about very sci-fi scenarios. In a future society, as long as humans exist, it will be a society that serves humans, not so sci-fi, but it will certainly make thinking and action simpler and more efficient for people.
Quantum Bit: Which stage are we currently in among the four stages of collective intelligence?
Liu Fanping: The first stage,“innovative foundational architecture”, has been fully realized. The second stage,“diversified hardware ecosystem”, which needs to be compatible with a wide range of devices, has also been achieved.
We are now transitioning to the third stage,“adaptive intelligent evolution”, as the technologies for autonomous learning and memory have not yet been officially released. Once they are available, we will fully enter the third stage. The fourth stage is“collaborative collective intelligence”, so we are currently in the transition from the second stage to the third stage.
Quantum Bit: What are the thresholds for the third stage of adaptive intelligent evolution, and what is the biggest challenge?
Liu Fanping: The two key thresholds for“adaptive intelligent evolution” areautonomous learning andmemory capabilities. The biggest challenge is“training-inference synchronization”, which means training and inference occur simultaneously.
This challenge is very high; it is not something that DeepSeek or OpenAI can easily achieve. What they are doing is still more about optimizing Transformers, whileno one in the industry has done training-inference synchronization.
Recently, Google published a paper titled“Titans: Learning to Memorize at Test Time”, which is also an exploration of memory capabilities, but it is not enough, while we are already on the path of implementing autonomous learning and memory capabilities.

△“Titans: Learning to Memorize at Test Time” paper
Our technical planning has two aspects:First, from the architectural level, we improve the memory process through the brain-like activation mechanism to allow each neuron to remember more; Second, foundational algorithm innovation, especially optimizing the backpropagation algorithm.
Inference seems easy now; a single GPU device can accomplish it, but training is very difficult, mainly due to the backpropagation algorithm. If both training and inference algorithms have low requirements, then training-inference synchronization can be done directly on terminal devices, obtaining data for training through interactions with the physical world, which is the ideal state.
Quantum Bit: When do you expect the third stage of adaptive intelligent evolution and the fourth stage of collaborative collective intelligence to be realized?
Liu Fanping: We expect to achieve the third stage within the nextone to two years, not too long.
We have already seen some effects internally; we demonstrated this capability at the World Artificial Intelligence Conference last June, but that was still a laboratory version and not commercialized.
The fourth stage, “collaborative collective intelligence,” will take longer because it involves communication between devices. Although we have done a lot of research in this area, there are indeed obstacles, andwe expect to see significant progress in 2 to 3 years.
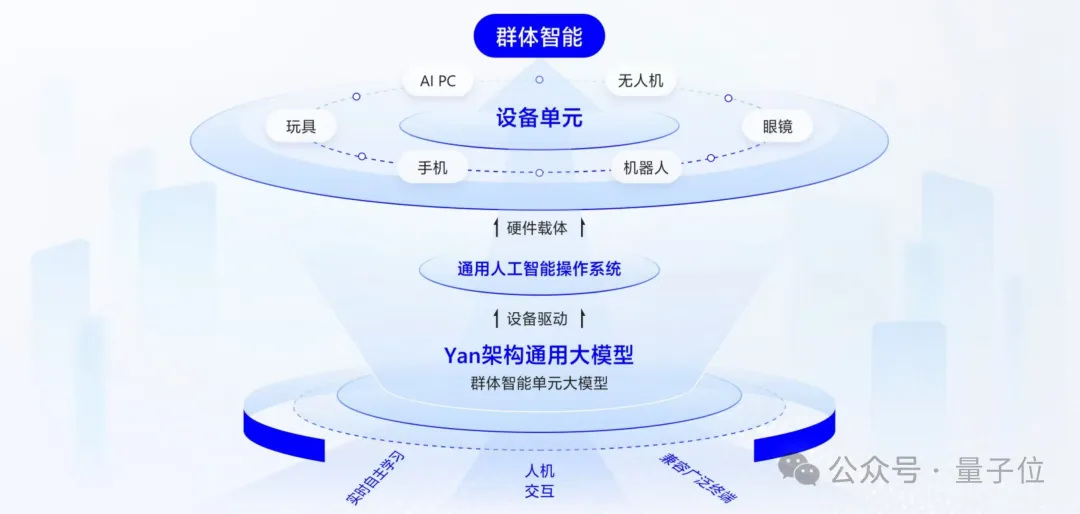
△Illustration of collective intelligence
Quantum Bit: Is the challenge of collaboration among multiple models on different devices significant for achieving collective intelligence?
Liu Fanping: Yes, it is very significant, and this is precisely the issue our laboratory team is researching.
Collaborative learning is very difficult; it first requires a collaborative mechanism and language. Human communication can occur through language, but machine communication is likely not in the form of language because language communication has a time cost, and language is a concrete expression, not abstract.
Machine collaboration must be conducted in a more precise manner, and we have not yet found a good way. We are researchingcommunication modes between machines, includingneuron exchange methods.
For example, if my model knows which neurons are activated while driving, can those neurons be transplanted to another model that does not drive? After transplantation, that model can drive directly without training, achievingability transfer.
Similarly, when two models need to complete a task together, how can they work together seamlessly? This requiresreal-time synchronized text, visual, and voice interactions.
Currently, interactions with large models are not real-time synchronized; when a user inputs text, the model waits for the complete input to finish before thinking and then outputs. However, in human communication, the other party starts thinking as soon as you begin speaking.
Quantum Bit: What is the essential difference between this and traditional interactions with smart speakers?
Liu Fanping: Traditional smart speakers areone-way command interactions; for example, if you ask Baidu to play music, it just plays. Our model, however, begins reasoning about what song you want to hear as soon as you say, “Help me play a song,” even before you finish the sentence, understanding your intent and preparing the result, making the device feel more like a person rather than a tool.
This requirescompletely different technical implementations. Traditional multimodal models are oftentrained separately; first, the natural language model is trained, then the audio and video models, and finally aligned.
Our approach is more like teaching a baby; it does not learn text first, then audio, and then visual, butlearns simultaneously, which results in a completely different understanding of the world, changing the learning model of large models.
For example, when teaching a child to recognize letters, when you point to a letter and say, “This is A,” the sound and visual input are given to them simultaneously. After repeating this several times, the child quickly learns to recognize the letter. Real-time learning does not require massive data; it only needs few-shot learning, while traditional large models require a large number of sample inputs to learn.
Current large models, due toarchitectural issues andbackpropagation limitations, lead tostrong dependence on data and computing power. Real-time models will greatly reduce the data requirements.
A person does not need to see a trillion tokens of data from infancy to college graduation, while current large models require tens of terabytes of tokens for training, highlighting the flaws in existing methods.
Quantum Bit: Has RockAI already freed itself from the need for massive data?
Liu Fanping: We have freed ourselves from part of it, but not completely. We hope to completely solve this problem based on autonomous learning and memory capabilities.
We have made progress in human-computer interaction, but because autonomous learning and memory capabilities have not yet been productized, the differences in interaction experience with other products are not yet very noticeable externally, but the route is completely different.
Quantum Bit: On which terminal devices can we currently achieve compatibility? How does it differ from other small open-source models?
Liu Fanping: For inference, most terminals can be compatible, including Raspberry Pi. For training, we have tested that at least anIntel i7 level processor is required.
In terms of compatibility, we should be at the forefront; at least byMay 2024, we will have achieved inference on Raspberry Pi and publicly opened the experience at the World Artificial Intelligence Conference in 2024. As of now, no other company has been able to achieve this level.
We differ significantly from those small open-source models. They adapt to devices by reducing the parameter count, while we do not achieve on-device training by sacrificing model parameters, as that approach is not meaningful.
△Illustration of Raspberry Pi
Quantum Bit: What practical changes will this wide hardware adaptation bring to our lives?
Liu Fanping: There will be many changes, especially after the productization of autonomous learning and memory capabilities, itcan achieve a highly personalized interaction experience. The AI that interacts with you will be completely personalized, understanding everything about you and providing very targeted suggestions. Unlike current large models, which give similar answers to the same questions.
For example, if you are a tech media person with your own writing style, and you want a mainstream large model to help you write, it requires a lot of prompt adjustments. However, once edge devices can achieve high personalization, the model on your device will understand your style very well, writing according to your wishes and style without additional tuning, while being very private and secure.
We also do not want to achieve personalization through long context combined with historical dialogues, as this method is not sustainable.
For instance, in a family setting, an edge device with multimodal capabilities can learn your usual habits when hosting guests, naturally knowing what to do in such scenarios without needing specific instructions.
It will become increasingly attuned to your preferences, understanding you better, and increasing your engagement, providing acompletely personalized experience, rather than everyone using the same product and receiving similar outputs and feedback.
Quantum Bit: Will the training-inference parallel architecture be a major direction for the future? To what extent will it impact embodied intelligence and human-computer interaction?
Liu Fanping: I believe it will have a significant impact, and the impact will be very large. We have talked with many representative manufacturers of embodied intelligent robots in China, and currently, embodied intelligence has a major problem.
We believe that embodied intelligent robots are trapped in avicious cycle: machines cannot be sold, manufacturing costs cannot be reduced; if costs cannot be reduced, machines cannot be sold. The core issue is that the machines do not possess true intelligence, which prevents them from being sold at a good price, failing to establish a positive cycle to lower marginal costs, especially manufacturing costs.
The problem is not that cloud-based large models are inadequate, but thatcloud-based large models are not suitable for embodied intelligence manufacturers. What truly suits embodied intelligence is a model where training and inference can be synchronized.Robots provide personalized services, and embodied intelligence manufacturers cannot rely on presets to meet all user needs.
Even if the hardware is excellent, it is not the decisive factor for user purchases; users will only buy if the intelligence is good enough.
A robot costing hundreds of thousands of yuan that can only walk at home will not sell. However, if it can understand the layout of the home and perform various chores, it will be different. These general cloud-based large models cannot achieve this because each family has different needs, each scenario is different, and each robot is different.
In the future, the brain of the robot will definitely be strongly bound to the robot, establishing a one-to-one relationship, unlike the current one-to-many relationship between cloud-based large models and robots.
This is similar to the human brain; while similar at birth, they become increasingly different. Each person’s growth environment and learning experiences influence their brain’s decision-making. Similarly, the commands for the action of drinking water from different people’s brains will not be identical, as everyone uses different bodies; the brain and body operate in tandem.
Embodied intelligence will also be the same; the brain will be strongly bound to the machine, even if the machines are manufactured to the same specifications, each family situation will differ, and usage methods will vary. Cloud-based large models cannot complete this process; future embodied intelligence will definitely be driven and disrupted by training-inference synchronized edge model technology.
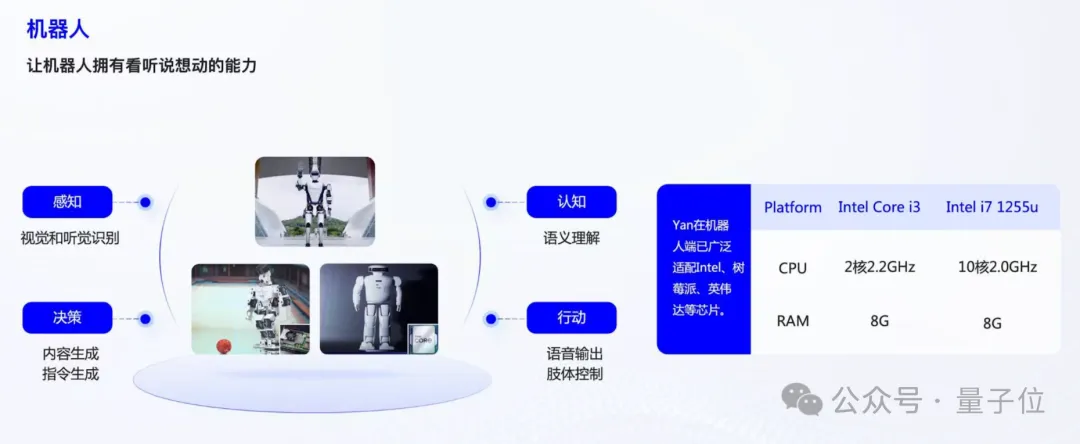
△Application of Yan architecture large model in embodied intelligent robots
Quantum Bit: Are there many companies currently working on training-inference parallelism?
Liu Fanping: No, currently, we are the only company truly working on training-inference parallelism.
Quantum Bit: Which companies has RockAI established partnerships with? Are there any exciting landing scenarios you can share?
Liu Fanping: It is not convenient to disclose specific company names, but there will be PC manufacturers deploying our large model offline on their products for direct mass production use.
There are also collaborations with embodied intelligence manufacturers, andthey have already shipped, as they are very keen on our model’s offline deployment capabilities.
Quantum Bit: What do you think the future relationship between edge and cloud models will be? Will one dominate or will they coexist and collaborate?
Liu Fanping: I believe thatin the long run, they will coexist, but the market for cloud-based large models will definitely shrink.
What we refer to as edge large models may differ from many people’s definitions in the industry. Currently, many people define edge large models as simply quantifying and pruning Transformers to run on edge devices, which is meaningless.
We believe that edge large models are like the human brain; there is no such thing as a cloud brain; the brain exists in the terminal, and every device possesses its own intelligence, which is our vision. Cloud-based large models cannot endow every device with its own intelligence, which is a fatal flaw.
Cloud-based large models can solve macro problems, such as extremely complex issues in human society that require supercomputers, which is very meaningful. However, for high-frequency problems in ordinary people’s lives, such as having a robot take meeting minutes or fetch water, cloud-based large models are unnecessary, and they cannot achieve this either.
Moreover, cloud-based large models cannot achieve personalization. It is impossible to deploy 8 billion models for 8 billion people globally; having 10 models would be impressive. But when devices possess autonomous learning, memory, and interaction capabilities, that will mark a new breakthrough in artificial intelligence.
Quantum Bit: Will we still need collaboration between edge and cloud in the future, or will edge directly solve most problems?
Liu Fanping: There will be collaboration, but not in the current understanding of collaboration. Our edge large models aredecentralized, with no central node, while cloud-based large models inherently have a central node.
Future edge-cloud collaboration may resemble human collaboration. In a company, the department leader and colleagues hold a meeting, where she is the central node, needing to synchronize her intentions with others. When she returns home, her parents may give her some reminders, making them the central node.
In this process, the central node is constantly changing, not fixed or unique; this kind of edge-cloud collaboration is essentially a process of continuously aligning collective thoughts. Watching a TV news program can also be understood as a form of edge-cloud collaboration, synchronizing information for everyone to align.
Future edge-cloud collaboration will no longer be based on the current concept of “edge capabilities being limited, thus needing cloud support.”
Quantum Bit: Where do you think the key turning points in AI development will occur in the next five years?
Liu Fanping:First, I believe there will be significant changes in foundational algorithms and architectures. Many may not want to believe this because they have invested heavily in Transformers. However, I believe that there will be major changes in foundational algorithms and architectures in the coming years.
Second, edge AI will gradually be accepted and understood, which is an important carrier for achieving AGI. The demand for computing power and data will certainly decrease. Computing power is a big pit; I do not believe we truly need that much computing power.
New foundational algorithms and edge AI will be accepted by more and more people.Finally, in 5 to 10 years, collective intelligence will gradually become popular, and its value will far exceed the intelligence generated by simply stacking computing power.
Why? Because collective intelligence will accelerate the exponential growth of intelligent society, just as the productivity breakthroughs during the Industrial Revolution can also be understood as a breakthrough in collective intelligence, where new technologies and tools make collaboration between people and between machines more efficient.
Currently, collaboration between machines is still very weak; phones and computers do not truly collaborate; they merely transfer files or make calls across devices. True collaboration requires solving problems together, which needs collective intelligence to achieve.
I believe that society will undergo significant changes in the next five years, and ordinary people, even professionals, may need to put in considerable effort to adapt. There is already a similar trend; we are currently in a slow uphill phase, but in the future, it will shift from a gradual climb to a direct ascent.
Paper: https://arxiv.org/abs/2406.12230
