Introduction: The Wonderful Collision of C++ and Neural Networks
In today’s digital age, artificial intelligence is like a magical force, quietly yet profoundly integrated into every aspect of our lives. When you open an e-commerce app, the precisely recommended products seem to read your mind; during your drive, intelligent navigation plans the optimal route in real-time, avoiding congestion; and in medical imaging diagnostics, it can keenly capture signs of illness, assisting doctors in accurate judgment. Behind this, neural networks play an immense role, simulating the way human brain neurons work, processing vast amounts of data, uncovering hidden information, and enabling intelligent decision-making.
In the field of neural network development, C++ is a low-key yet powerful “behind-the-scenes hero.” Although Python is favored in the early stages of neural network construction due to its rich libraries and concise syntax, allowing developers to quickly bring ideas to practice, when projects move towards large-scale data processing with stringent performance requirements, especially in the critical stages of model deployment and optimization, C++’s advantages become evident. It operates close to the hardware level, managing resources with ease and achieving high operational efficiency, maximizing the potential of neural networks and injecting continuous power into intelligent applications, allowing innovative ideas to take root in reality. Now, let us unveil the mysteries of neural network model evaluation and performance analysis in C++.
1. Basics of Neural Networks

(1) Neurons – The Basic Unit of the Network
Neurons are the cornerstone of neural networks, intricately constructed yet powerful. Imagine it as a tiny data processor composed of core components: inputs, weights, activation functions, and outputs. When external data flows in, these input values are multiplied by their corresponding weights, which act as “gatekeepers” determining the importance of the data. For example, in image recognition, certain features of the image pixels may correspond to higher weights as they play a crucial role in determining the object’s category. Subsequently, all weighted inputs are summed up and fed into the activation function for “refinement.” The activation function is the “finishing touch” of the neuron, introducing non-linear factors that allow the neuron to go beyond simple linear operations, endowing the network with powerful expressive capabilities to handle complex and variable data patterns. Common activation functions include Sigmoid and ReLU, as illustrated by the following simple pseudocode:
class Neuron {
public:
double output; // Output value of the neuron
std::vector<double> inputs; // Input values received by the neuron</double>
std::vector<double> weights; // Corresponding weights for inputs</double>
// Activation function, e.g., Sigmoid function
double sigmoid(double x) {
return 1.0 / (1.0 + std::exp(-x));
}
void forward() {
double sum = 0.0;
for(size_t i = 0; i < inputs.size(); ++i) {
sum += inputs[i] * weights[i];
}
output = sigmoid(sum);
}
};Through this code, we can clearly see how the neuron receives inputs, performs weighted summation, and transforms through the activation function, outputting the final result and embarking on a fascinating data processing journey of neural networks.
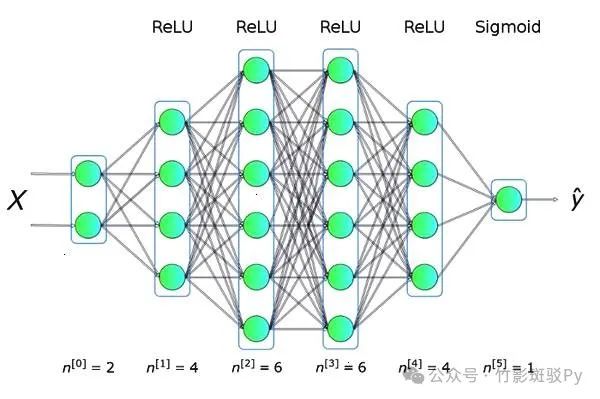
(2) Layer by Layer: The Architecture of Neural Networks
Neural networks resemble a meticulously constructed “data edifice,” consisting of an input layer, hidden layers, and an output layer stacked in an orderly fashion. The input layer is like an open door, welcoming various types of raw data from the outside, such as pixel values of images or character encodings of text, serving as the source of data for the entire network. The hidden layers act as the “central nervous system” of the edifice, hidden behind the scenes yet crucial, responsible for deeply analyzing input data and extracting features. It is composed of numerous interwoven neurons, progressively uncovering the intrinsic patterns of the data, with different layers focusing on different levels of feature extraction, from simple lines and textures to complex object contours and semantic understanding. The output layer serves as the “display window” of the edifice, presenting the final results processed by the network to the outside world, whether it is category labels in image recognition or specific values in prediction tasks, all output from here.
Further exploration reveals that each member of the neural network family has its own characteristics. Feedforward neural networks are the most straightforward, with information flowing unidirectionally like an arrow from the input layer through hidden layers to the output layer, with no intention of turning back, commonly used for basic tasks such as data classification and regression prediction. Convolutional Neural Networks (CNNs) are like “image masters,” excelling in the image domain with the magical convolutional kernels of convolutional layers. They can precisely capture local features of images by sliding convolutional kernels over the image, akin to examining the image piece by piece with a magnifying glass, and then cleverly compressing data through pooling layers to reduce redundant information, greatly enhancing processing efficiency, performing exceptionally in tasks such as image recognition and object detection. Recurrent Neural Networks (RNNs) are like poets with “memory,” specifically designed for handling sequential data. They build a recurrent structure internally, allowing neurons to retain past information, grasping the meaning of current vocabulary by considering the context of previous words. However, they can easily fall into the gradient vanishing or explosion dilemma when handling long sequences. Fortunately, Long Short-Term Memory networks (LSTMs) have emerged, carefully regulating information retention and updating through input, forget, and output gate mechanisms, enabling the network to handle complex sequential tasks such as long texts and time series more adeptly.
2. Practical Implementation of Neural Networks in C++
Powerful Tools and Libraries for C++
In the field of neural network development using C++, numerous powerful libraries serve as “magical weapons” to assist developers in overcoming obstacles. TensorFlow, as one of the leaders, has its core code meticulously crafted in C++, seamlessly integrating into C++ projects. It provides developers with a highly flexible architecture, whether building basic multilayer perceptrons or complex cutting-edge models like Inception and ResNet, all can be easily managed. With its visualization component, TensorBoard, the changes in parameters and accuracy trends during model training are clear at a glance, as if providing developers with “x-ray vision” to accurately grasp training dynamics.
Caffe is known for its efficiency, especially excelling in image processing. It adopts a design where layers are the abstract units, with a clear and intuitive logic, constructing models layer by layer from data input layers, convolutional layers, pooling layers to fully connected layers, making it as convenient as building blocks. For developers familiar with traditional image processing workflows, it is easy to get started. Moreover, Caffe has outstanding advantages in mobile deployment, allowing neural network models to easily reside in resource-constrained environments such as smartphones and embedded devices, expanding the boundaries of intelligent applications.
There is also Torch, which has deep roots in scientific computing and machine learning, boasting a rich heritage. Its extensive model library covers everything from classic neural networks to the latest research achievements, allowing developers to “learn from the masters” as needed. Its dynamic computational characteristics shine during debugging, with code modifications providing immediate feedback, akin to having a real-time conversation with the model, quickly locating issues and accelerating development iterations. These libraries each have their strengths, allowing developers to choose based on project needs, thus embarking on a smooth journey of neural network construction.