
Compiled by: Ling Min, Hezi Cola
Since its debut on May 2, the Mojo programming language from Modular has generated significant interest among developers, with over 120,000 developers registering to use the Mojo Playground and 190,000 actively participating in discussions on Discord and GitHub. Jeremy Howard, co-founder of Fast.ai and data scientist, stated, “Mojo may be the biggest programming language advancement in decades.”
On September 7, Modular announced the official release of Mojo: Mojo is now available for local download—initially for Linux, with Mac and Windows versions coming soon.
Modular was founded by Chris Lattner, co-creator of LLVM and the Swift programming language, and recently secured $100 million (approximately 700 million RMB) in funding. Chris Lattner stated that the total funding round reached $130 million, which will be used for product expansion, hardware support, and further development of the self-developed AI programming language Mojo.
Mojo Playground provides only a simple language demonstration, while the local Mojo toolchain will help developers accomplish much more. The local developer tools will unlock all Mojo features, including a complete set of compiler functionalities and IDE tools, allowing developers to easily build and iterate on Mojo applications.
Mojo: A New Programming Language for AI Developers
Mojo is a new programming language designed for AI developers. Over time, it will gradually evolve into a superset of Python. Mojo already supports seamless integration with any Python code and offers an extensible programming model to support various critical performance systems, including accelerators commonly found in AI scenarios (such as GPUs).
Mojo can effectively meet developer needs, guiding them to gradually adopt new features to achieve high-performance experiences when necessary. Specifically, the main benefits Mojo can bring to developers include:
-
One language for everything: Mojo can serve AI developers anytime and anywhere, combining the usability of Python with the system programming capabilities that previously forced developers to use C, C++, or CUDA. Developers can work on public codebases, simplifying the entire workflow from research to production.
-
Breaking Python’s performance limits: To date, Python is ubiquitous. However, for tasks requiring higher performance or specialized hardware, Python’s performance is often less than ideal. Mojo can unleash the performance potential of CPUs and well support external accelerators like GPUs and ASICs, providing performance comparable to C++ and CUDA.
-
Full interoperability with the Python ecosystem: Mojo offers comprehensive interoperability with the Python ecosystem, allowing it to seamlessly leverage Python library resources while utilizing Mojo’s own functionality and performance advantages. For example, developers can seamlessly mix NumPy and Matplotlib with their Mojo code.
-
Upgrading AI workloads: Mojo is tightly integrated with a modular AI engine, allowing developers to easily extend their AI workloads through custom operations, including preprocessing, postprocessing operations, and high-performance mathematical algorithms. Developers can also introduce kernel fusion, graph rewriting, sharp functions, and more.
By making simple changes to existing Python code, developers can achieve significant acceleration for high-computation workloads (up to 68,000 times faster). Currently, practical use cases for Mojo include:
-
Notable blogger Maxim Zaks has implemented several tree data structures using Mojo and published related blog posts (https://pub.aimind.so/a-high-level-introduction-to-fibytree-bd7f8775d815) and some preliminary benchmark results (https://pub.aimind.so/fibytree-vs-set-and-sortedset-7b4e6b56cac8).
-
GitHub user MadAlex1997 has built an implementation of N-dimensional arrays in Mojo (https://github.com/MadAlex1997/Mojo-Arrays).
Why is it 68,000 times faster than Python?
Mojo is a member of the Python family but has grand ambitions—to be fully compatible with the Python ecosystem, allowing developers to continue using their familiar tools. Mojo aims to gradually become a superset of Python by retaining Python’s dynamic features while adding new primitives for system programming.
Chris Lattner, co-founder of LLVM and the Swift programming language, and CEO of Modular, previously stated on Hacker News: “Our goal is not to make dynamic Python magically fast. While we are much faster with dynamic code (because we have a compiler instead of an interpreter), it does not rely on a ‘smart enough’ compiler to eliminate dynamicity.”
Initially, Mojo aimed to be 35,000 times faster than Python, but the team recently stated that Mojo combines the advantages of dynamic and static languages, achieving a performance boost of 68,000 times over Python.
The Mojo team has detailed in a series of blog posts how Mojo is 68,000 times faster than Python: in the first post, the team attempted to port code to Mojo, achieving about a 90-fold performance increase; in the second post, the team vectorized and parallelized the code, further increasing performance by 26,000 times; in the third post, the team demonstrated how to comprehensively exceed the 35,000-fold program acceleration target through new performance techniques.
Specifically, the Mojo team first accelerated the Python program by 89 times using simple ports; then, through targeted optimizations and leveraging modern CPU computational potential, they achieved a speedup of 26,000 times. The parallel strategy proposed by the Mojo team is that each CPU core should be responsible for processing an equal number of lines of code.
However, this approach is only feasible when the cross-line workloads are the same; splitting the workload to ensure that each thread worker gets a set of code lines only works if the workload is balanced. The Mandelbrot set does not exhibit this property. Splitting the workload in this way can lead to load imbalance issues because one pixel in the Mandelbrot set may complete in a single iteration, while another pixel may undergo MAX_ITERS iterations. This means that the number of iterations for each line is not equal, leading to some threads that complete calculations early being idle, which is detrimental to fully exploiting performance potential.
To demonstrate this imbalance issue, the Mojo team plotted the total number of iterations executed by each line in the Mandelbrot set. As shown in the figure below, some lines require fewer than 1,000 iterations before escaping, while others may require over 800,000 iterations.
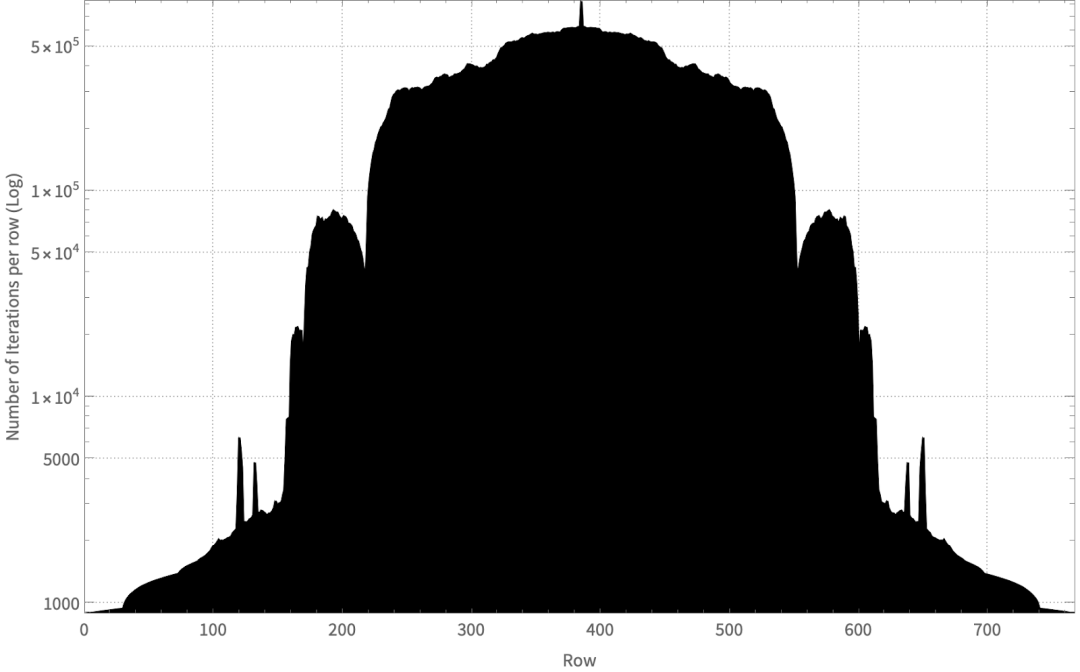
The total number of iterations executed by each line (shown in a logarithmic coordinate system) is not evenly distributed. Some lines (for example, those in the central part of the image) may require over 800,000 iterations, while the lines at the ends may only require around 800 iterations.
If a fixed number of continuous lines is assigned to each thread, it can lead to a situation where all threads are waiting until a certain group of code lines (assigned to a specific core) completes execution. There are many ways to solve this problem, but the simplest is, of course, excessive splitting. This means that each thread does not receive a set of evenly distributed lines but instead establishes a workload pool and creates corresponding work items for each line. Each thread then continuously picks up these work items from the thread pool in a loop.
The good news is that Mojo has a high-performance concurrent runtime, so we do not need to create a thread pool or design a loop for picking up/executing tasks ourselves. Mojo’s runtime provides many advanced features to fully utilize such multi-core systems.
fn compute_row(y:Int):
let cy = min_y + h * scale_y
@parameter
fn compute_vector[simd_width:Int](w:Int):
let cx = min_x + iota[DType.float64, simd_width]() * scale_x
output.simd_store[simd_width](Index(h,w),
mandelbrot_kernel(ComplexSIMD[DType.float64,
simd_width](cx,cy))
vectorize[num_ports * simd_width, compute_vector](width)
with Runtime(num_cores()) as rt:
let partition_factor = 16 # Is autotuned.
parallelize[compute_row](rt, height, partition_factor * num_cores())
The program’s performance can be evaluated when split into 2, 4, 8, 16, and 32 parts, with the corresponding results as follows:
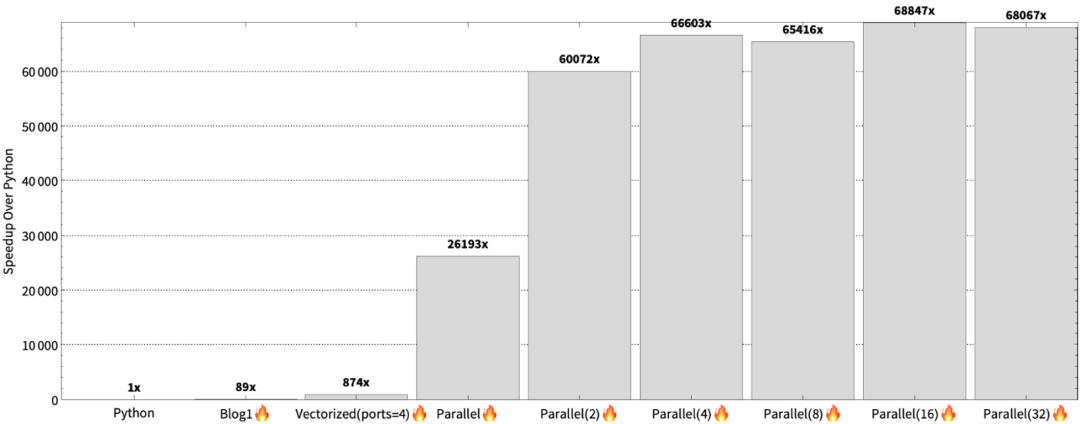
At this point, the Mojo team achieved a 2.3 times acceleration over the parallel version, reaching 78 times the performance of the vectorized implementation. So, will further dividing within each line lead to even better performance? If a single line is large, perhaps. However, the maximum single line length in the Mojo team’s example is only 4096. Additionally, the pixels within the same line are often more correlated. At this point, single instruction multiple data (SIMD) is more suitable, avoiding wasted work in the vector channels.
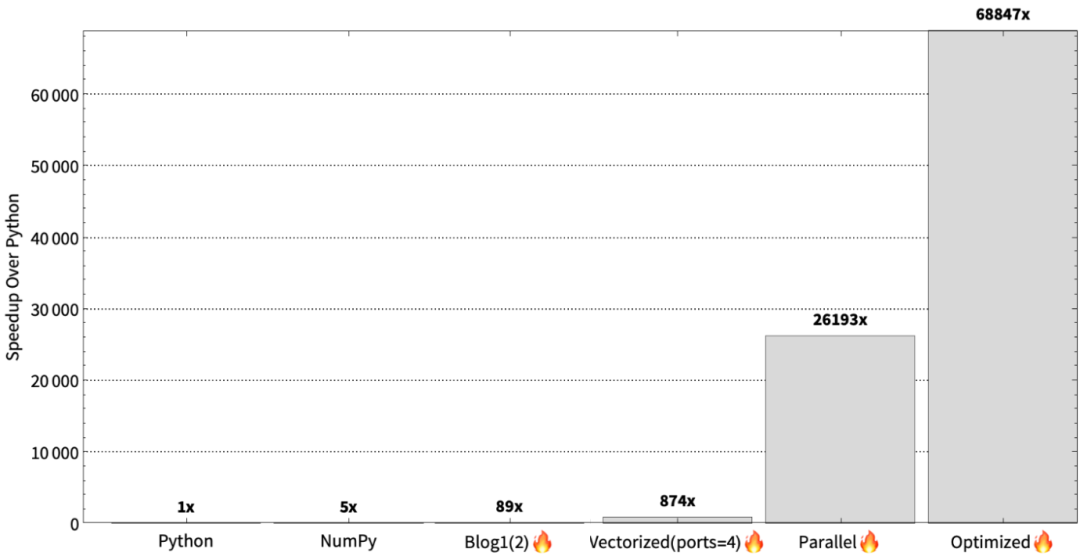
Reflecting on the entire journey, the Mojo team first achieved a 26,000-fold performance increase on Python code, then reached a final result of 68,847 times speedup through oversubscription, ultimately achieving a 68,000-fold speedup over Python; after applying oversubscription, performance improved by another factor of 1 over the previous parallel version.
How to Use Mojo?
Currently, developers can download Mojo to their local machines. Modular states that Mojo is far more than just a compiler.
Mojo Toolbox
The first version of the Mojo SDK provides everything needed for easy Mojo program development, including the following tool options:
-
Mojo Driver: Provides a shell for read-eval-print-loop (REPL), allowing developers to build and run Mojo programs, package Mojo modules, generate documentation, and format code.
-
Extension for Visual Studio Code (VS Code): Supports various productivity features such as syntax highlighting, code completion, etc.
-
Jupyter Kernel: Supports building and running Mojo notebooks, including using Python code.
-
Debugging support (coming soon): Enter and inspect running Mojo programs, even mixing C++ with Mojo stack frames. The initial version of the SDK will support x86/Linux systems, with further updates expanding to other operating systems, hardware, and tool functionalities.
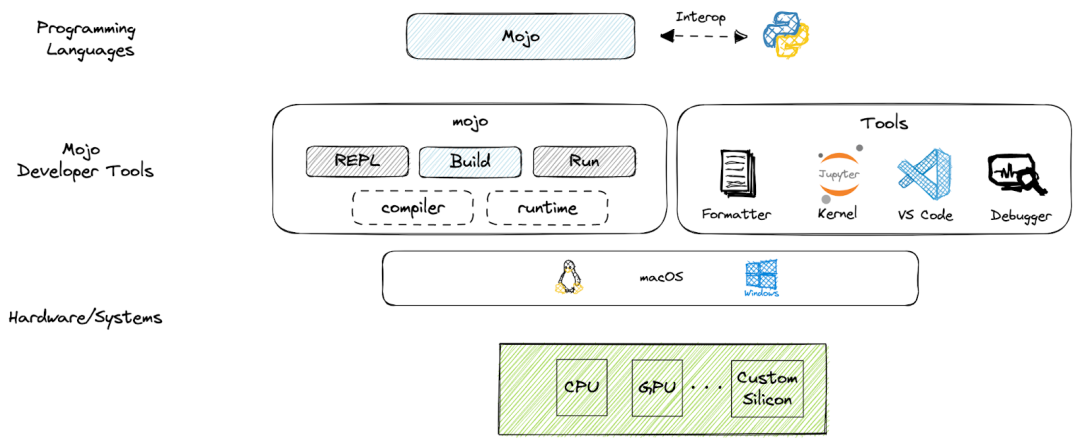
Example View of Mojo SDK
Mojo Driver
Like Python, developers can run Mojo commands in the REPL for programming. Below is an example of calculating Euclidean distance in Mojo:
$ Mojo
Welcome to Mojo! 🔥
Expressions are delimited by a blank line.
Type `:Mojo help` for further assistance.
1> %%python
2. import numpy as np
3. n = 10000000
4. anp = np.random.rand(n)
5. bnp = np.random.rand(n)
6> from tensor import Tensor
7. let n: Int = 10000000
8. var a = Tensor[DType.float64](n)
9. var b = Tensor[DType.float64](n)
10. for i in range(n):
11. a[i] = anp[i].to_float64()
12. b[i] = bnp[i].to_float64()
13> from math import sqrt
14. def Mojo_naive_dist(a: Tensor[DType.float64], b: Tensor[DType.float64]) -> Float64:
15. var s: Float64 = 0.0
16. n = a.num_elements()
17. for i in range(n):
18. dist = a[i] - b[i]
19. s += dist*dist
20. return sqrt(s)
23> fn Mojo_fn_dist(a: Tensor[DType.float64], b: Tensor[DType.float64]) -> Float64:
24. var s: Float64 = 0.0
25. let n = a.num_elements()
26. for i in range(n):
27. let dist = a[i] - b[i]
28. s += dist*dist
29. return sqrt(s)
30.
31> let naive_dist = Mojo_naive_dist(a, b)
32. let fn_dist = Mojo_fn_dist(a, b)
33. print(fn_dist)
34.
1290.8521425092235
35. print(naive_dist)
36.
1290.8521425092235
Additionally, Mojo allows developers to build statically compiled executables for deployment without any dependencies. For example, developers can compile and run the hello.🔥 program from the example library as follows:
$ Mojo build hello.🔥
$ ./hello
Hello Mojo 🔥!
9
6
3
$ ls -lGtranh hello*
-rw-r--r-- 1 0 817 Sep 3 23:59 hello.🔥
-rwxr-xr-x 1 0 22K Sep 3 23:59 hello
This statically compiled 22 kB binary is very cool, made possible by Mojo’s compact dependency management mechanism.
Visual Studio Code Extension
VS Code is currently one of the most popular IDEs globally. Mojo has released an official extension on the Visual Studio Marketplace that provides direct support. This allows developers to easily access Mojo support for syntax highlighting, diagnostics and fixes, definitions and references, hover help, formatting, and code completion in their production workflow.
Jupyter Integration
Jupyter provides a powerful environment for interactive development. Mojo includes a Jupyter kernel that allows developers to use Jupyter notebooks directly. The team has shared all notebooks from the Mojo Playground on GitHub (https://github.com/modularml/mojo/tree/main/examples/notebooks), and more details can be found in the README file.
Debugging Support (Coming Soon)
In the upcoming new version, the team will add an interactive debugging experience in VS Code through the LLDB command-line interface. Moreover, Mojo’s debugger will seamlessly operate on mixed Mojo/C/C++ code within the same debugging session, further enhancing developers’ capabilities when dealing with highly specialized code.
Reference Links:
https://www.modular.com/blog/mojo-its-finally-here
https://www.modular.com/blog/mojo-a-journey-to-68-000x-speedup-over-python-part-3