Author: Raja Sekar
Translator: Aladdin
Editor: Cai Fangfang
The author, Raja Sekar, has over three years of experience using Spark. He believes that Spark’s DataFrame is excellent and can solve most analytical workload problems, but there are still some scenarios where using RDD is more convenient. Thus, he conceived the idea of re-implementing Spark using a native language to see what performance and resource management efficiency could be achieved after the rewrite. Ultimately, he chose Rust, which has recently gained popularity. The rewritten FastSpark not only runs faster than Spark but also saves a significant amount of memory. The author’s next goal is straightforward: to serve as an alternative to Apache Spark.
It all started with my research on various distributed schedulers and distributed computing frameworks, with Spark being one of them. With over three years of experience using Spark, I have gained a certain understanding of its internal principles. Spark’s tremendous success is not only due to its speed and efficiency but also because it provides a very intuitive API. This is also why pandas is so popular. Otherwise, if performance were the only consideration, people could choose other better alternatives like Flink, Naiad, or HPC frameworks like OpenMP.
Spark is a general-purpose distributed framework, and RDD is very suitable for handling unstructured data or complex tasks. However, the current focus of Spark is on DataFrames and SQL, which are more popular than RDDs. DataFrames perform better than RDDs. RDD is the foundation of the Spark ecosystem, so why do DataFrames achieve better performance? Is it due to query optimization? For the simplest query, you can define the best data and computation flow using RDD, but DataFrame may still outperform your defined query. The secret lies in the Tungsten engine. Spark’s performance mainly relies on memory. When handling typical tasks, the JVM quickly consumes all resources. Therefore, Spark uses “sun.misc.Unsafe” to manage raw memory directly. The result is that the DataFrame API is not as flexible as RDD. They can only handle fixed predefined data types, so you cannot freely use data structures or objects in the data flow. In practice, DataFrames can solve most analytical workloads, but there are still scenarios where using RDD is more convenient.
Thus, I had the idea of re-implementing Spark using a native language to see what performance and resource management efficiency could be achieved. Spark has undergone years of optimization, so I do not expect a significant difference in performance; if there is, it is likely in memory usage. Additionally, I hope it can be as general-purpose as Spark. I decided to use Rust for the implementation because I did not have many other options. Although C++ is also very suitable for this, I prefer Rust’s simplicity, and Rust is similar to Scala in many ways. If you look at the example code in the codebase, you will see how similar it is to typical Scala Spark code. I implemented a very basic version that supports some RDD operations and transformations. However, I have not yet implemented file reading and writing, so for now, you need to manually write code to read files.
FastSpark project open-source link:
https://github.com/rajasekarv/native_spark
Performance benchmark tests used a 1.2TB CSV file.
-
Utilized 5 GCloud nodes (1 master and 4 workers);
-
Machine type: n1-standard-8 (8 vCPUs, 30GB memory).
This is a simple reduceBy operation, reference code: FastSpark and Spark.
-
FastSpark took: 19 minutes 35 seconds
-
Apache Spark took: 1 hour 2 minutes
This result is quite surprising. I did not expect any difference in running speed; I was more curious about memory usage. Since the tasks run on distributed processes, I could not measure CPU usage time, so I measured the CPU usage of the execution nodes during the program’s runtime.
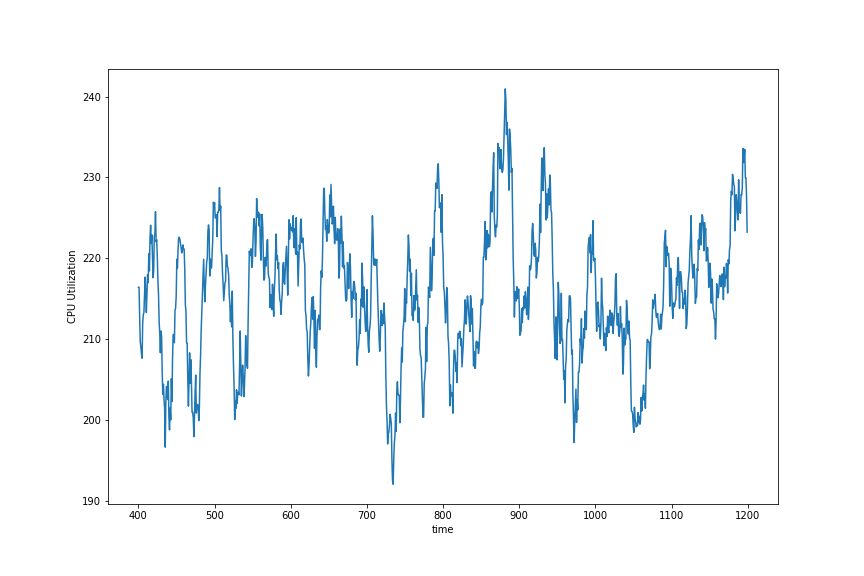
FastSpark
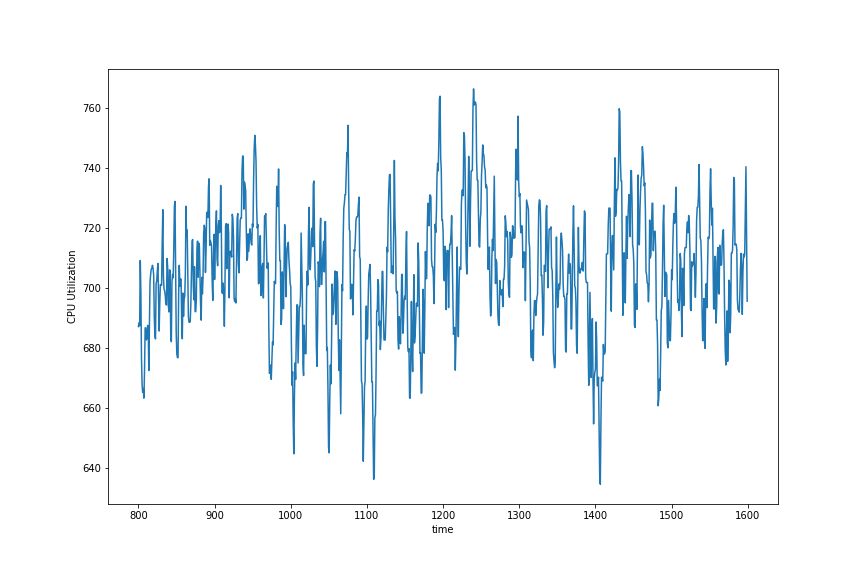
Apache Spark
As can be seen, FastSpark performed a large number of I/O operations, with a CPU usage of about 28%, while Spark’s CPU usage remained at 100%. iotop showed that FastSpark saturated I/O completely during execution, while Spark only used a little over half.
On the execution nodes, FastSpark’s peak memory utilization did not exceed 150MB, while Spark reached 5-6GB and fluctuated within that range. This huge difference may be due to JVM object allocation, which is a very expensive operation. My initial implementation version was more than twice as slow as the current version. After removing some cloning and boxing, there was a significant performance improvement.
The same logic implemented in Rust is more than twice as fast as FastSpark RDD. Performance analysis shows that the aforementioned FastSpark program spent 75% of its runtime on allocation and system calls, mainly because the Rust implementation version boxed a large amount of data with dynamic dispatch.
Below are the results of running four different implementation versions locally (processing 10GB of data). The files are in CSV format and stored on a hard drive (yes, my hard drive is slow), focusing mainly on user time.
Basic Rust version:
real 6m05.203s
user 1m02.049s
sys 0m8.572sFastSpark version:
real 6m32.884s
user 1m48.904s
sys 0m4.489sApache Spark RDD version:
real 10m14.646s
user 14m45.452s
sys 0m9.021sApache Spark DataFrame version:
real 8m23.422s
user 10m34.975s
sys 0m8.882sCPU Intensive Tasks
Spark’s analytical tasks almost always require a lot of CPU because we often use compressed files like Parquet or Avro. Below are the results of reading a Parquet file (generated from a 10GB CSV file, about 800MB) and performing the same operations.
FastSpark version:
real 1m31.327s
user 4m50.342s
sys 0m1.922sNow it becomes CPU intensive, spending all CPU time on decompression and hashing operations.
Spark DataFrame version:
real 0m55.227s
user 2m03.311s
sys 0m2.343sThis is the optimization result provided by the DataFrame API. The code is the same as before, just replacing CSV with Parquet format. However, it is important to note that the code generated by Spark SQL only selects the required columns, while FastSpark iterates through all rows using get_row_iter.
I wrote a piece of code to read files, selecting only the required columns, so let’s see the results. Please refer to the code here.
FastSpark (selecting only required columns):
real 0m13.582s
user 0m34.753s
sys 0m0.556sThis speed is quite fast. It is still I/O intensive. Additionally, it only used about 400MB of memory, while Spark DataFrame used 2-3GB. This is one of the reasons I prefer the RDD API, as we can have more flexible control over the data flow. While abstraction is fine for most applications, sometimes we need to accomplish certain tasks, and a well-performing underlying API is more suitable.
In fact, this could make FastSpark DataFrame more powerful and general than Apache Spark DataFrame. Unlike Spark, FastSpark DataFrame can support arbitrary data types and can join columns with different data types by implementing custom hashing for data types. However, the FastSpark DataFrame has not been open-sourced yet, as it is still in the experimental stage. I tend to choose a design similar to pandas, which is not only flexible but also high-performing. If possible, it could also interoperate with Python objects, but it would be different from PySpark.
This workflow is very simple and has been run on very large datasets, so I chose it. Of course, this may also be my personal preference. If possible, I encourage readers to run the code themselves and provide me with feedback on the results. Spark has undergone many optimizations, especially in shuffle, where my implementation (very simple) is much slower than Spark. Additionally, executing CPU-intensive tasks using FastSpark is usually faster.
Main Goals:
-
To serve as an alternative to Apache Spark. This means the user-side API should remain consistent.
-
To perform better in integration with Python than PySpark.
Completed:
-
The project is at a very early POC stage, supporting only a few RDD operations and transformations.
-
The distributed scheduler has been implemented, but it is still far from production-ready and is very fragile. Fault tolerance and caching have not been completed, but should be done soon.
Future Plans:
-
A general file reader will be completed soon. The file interface is different from Spark’s. Supporting HDFS will require a lot of work, but supporting other file systems should be straightforward. One of the main goals of this project is to make it a complete alternative to Apache Spark (at least supporting non-JVM languages like Python and R), so I will try to maintain user-side API compatibility.
-
Since the code is experimental, there are many hard-coded elements. Supporting configuration and deployment will be the next priority.
-
The shuffle operation is implemented very simply, and the performance is poor; this needs improvement.
Original link:
Reply with the keyword “Join Group” to join the InfoQ reader group, share your thoughts with InfoQ readers, and interact closely with the editors (I heard there is a learning package worth 4999 available!). Come join us!
Conference Recommendations
[AICon Beijing 2019 Countdown: Last 3 Days] What are the latest practical cases of technologies such as machine learning, NLP, and knowledge graphs? We have invited over 50 top AI technology experts from AWS, Microsoft, BAT, Huawei, and more to share insights in fields like intelligent finance, e-commerce, logistics, and AI chips. Click “Read Original” to view the schedule, or contact: 18514549229.
Some exciting topics:
[Ant Financial] Financial Knowledge Graph in Ant’s Business Exploration and Platform Practice
[Cainiao Network] The Technological Evolution of Artificial Intelligence in Smart Transportation and Logistics
[Alibaba Mama] Industrial-Grade Deep Learning in Alibaba Advertising: Practice, Innovation, and Latest Progress
[Microsoft Xiaoice] Building Personalized Conversational Robots and Their Practice in Voice Scenarios
[Baidu] AI Production Era: Innovations and Applications of NLP Technology
Today’s Recommended Article

KubeEdge Source Code Analysis: Overall Architecture

Click to see fewer bugs👇